パブリック クラウドにおける TiDB のベスト プラクティス
パブリック クラウド インフラストラクチャは、TiDB の導入と管理のための選択肢としてますます人気が高まっています。ただし、TiDB をパブリック クラウドに展開するには、パフォーマンスのチューニング、コストの最適化、信頼性、スケーラビリティなど、いくつかの重要な要素を慎重に検討する必要があります。
このドキュメントでは、 Raft Engineの専用ディスクの使用、KV RocksDB でのコンパクション I/O フローの削減、クロス AZ トラフィックのコストの最適化、Google Cloud ライブ マイグレーション イベントの軽減など、パブリック クラウドに TiDB をデプロイするためのさまざまな重要なベスト プラクティスについて説明します。大規模なクラスター内の PDサーバーを微調整します。これらのベスト プラクティスに従うことで、パブリック クラウド上での TiDB 導入のパフォーマンス、コスト効率、信頼性、拡張性を最大化できます。
Raft Engineには専用ディスクを使用する
TiKV のRaft Engineは、従来のデータベースの先行書き込みログ (WAL) と同様の重要な役割を果たします。最適なパフォーマンスと安定性を実現するには、TiDB をパブリック クラウドに展開するときにRaft Engineに専用のディスクを割り当てることが重要です。次のiostat書き込みの多いワークロードを伴う TiKV ノードの I/O 特性を示しています。
Device r/s rkB/s w/s wkB/s f/s aqu-sz %util
sdb 1649.00 209030.67 1293.33 304644.00 13.33 5.09 48.37
sdd 1033.00 4132.00 1141.33 31685.33 571.00 0.94 100.00
デバイスsdbは KV RocksDB に使用され、デバイスsddはRaft Engineログの復元に使用されます。 sddデバイスの 1 秒あたりに完了したフラッシュ リクエストの数を表すf/s値よりも大幅に大きいことに注意してください。 Raft Engineでは、バッチ内の書き込みが同期としてマークされると、バッチ リーダーは書き込み後にfdatasync()を呼び出し、バッファされたデータがstorageにフラッシュされることを保証します。 Raft Engineに専用ディスクを使用することで、TiKV はリクエストの平均キュー長を短縮し、最適で安定した書き込みレイテンシーを確保します。
さまざまなクラウド プロバイダーが、IOPS や MBPS などのさまざまなパフォーマンス特性を持つさまざまなディスク タイプを提供しています。したがって、ワークロードに基づいて、適切なクラウド プロバイダー、ディスク タイプ、ディスク サイズを選択することが重要です。
パブリック クラウド上のRaft Engineに適切なディスクを選択する
このセクションでは、さまざまなパブリック クラウド上でRaft Engineに適切なディスクを選択するためのベスト プラクティスについて概説します。パフォーマンス要件に応じて、2 種類の推奨ディスクが用意されています。
ミドルレンジディスク
以下は、さまざまなパブリック クラウドに推奨されるミドルレンジ ディスクです。
AWS ではGP3が推奨されます。 gp3 ボリュームは、ボリューム サイズに関係なく、3000 IOPS と 125 MB/秒のスループットの無料割り当てを提供します。通常、 Raft Engineにはこれで十分です。
Google Cloud では、 PD-SSDが推奨されます。 IOPS と MBPS は、割り当てられたディスク サイズによって異なります。パフォーマンス要件を満たすために、 Raft Engineに 200 GB を割り当てることをお勧めします。 Raft Engine はそれほど大きなスペースを必要としませんが、最適なパフォーマンスを保証します。
Azure ではプレミアムSSD v2が推奨されます。 AWS gp3 と同様に、Premium SSD v2 は、ボリューム サイズに関係なく、3000 IOPS と 125 MB/秒のスループットの無料割り当てを提供します。通常、これはRaft Engineには十分です。
ハイエンドディスク
Raft Engineのレイテンシーがさらに低いことが期待される場合は、ハイエンド ディスクの使用を検討してください。以下は、さまざまなパブリック クラウドに推奨されるハイエンド ディスクです。
AWS ではio2が推奨されます。ディスク サイズと IOPS は、特定の要件に応じてプロビジョニングできます。
Google Cloud では、 pd-エクストリームが推奨されます。ディスク サイズ、IOPS、MBPS をプロビジョニングできますが、これは 64 個を超える CPU コアを備えたインスタンスでのみ使用できます。
Azure ではウルトラディスクが推奨されます。ディスク サイズ、IOPS、MBPS は、特定の要件に応じてプロビジョニングできます。
例 1: AWS でソーシャル ネットワーク ワークロードを実行する
AWS は、20 GB GP3ボリュームに対して 3000 IOPS と 125 MBPS/秒を提供します。
書き込み集中型のソーシャル ネットワーク アプリケーションのワークロードに AWS 上の専用の 20 GB GP3 Raft Engineディスクを使用すると、次のような改善が見られますが、推定コストは 0.4% しか増加しません。
- QPS (1 秒あたりのクエリ数) が 17.5% 増加
- 挿入ステートメントの平均レイテンシーが 18.7% 減少
- 挿入ステートメントの p99レイテンシーが 45.6% 減少しました。
例 2: Azure で TPC-C/Sysbench ワークロードを実行する
Azure 上のRaft Engineに専用の 32 GB ウルトラディスクを使用すると、次の改善が見られます。
- Sysbench
oltp_read_writeワークロード: QPS が 17.8% 増加し、平均レイテンシーが 15.6% 減少しました。 - TPC-C ワークロード: QPS が 27.6% 増加し、平均レイテンシーが 23.1% 減少しました。
例 3: TiKV マニフェストのRaft Engine用に Google Cloud に専用の pd-ssd ディスクを接続する
次の TiKV 構成例は、追加の 512 GB PD-SSDディスクをTiDB Operatorによってデプロイされた Google Cloud 上のクラスタに接続する方法を示しています。この特定のディスクにRaft Engineログを保存するようにraft-engine.dir構成されています。
tikv:
config: |
[raft-engine]
dir = "/var/lib/raft-pv-ssd/raft-engine"
enable = true
enable-log-recycle = true
requests:
storage: 4Ti
storageClassName: pd-ssd
storageVolumes:
- mountPath: /var/lib/raft-pv-ssd
name: raft-pv-ssd
storageSize: 512Gi
KV RocksDB のコンパクション I/O フローを削減する
TiKV のstorageエンジンとして、ユーザー データの保存にロックスDBが使用されます。クラウド EBS でプロビジョニングされた IO スループットは通常、コストを考慮して制限されているため、RocksDB では高い書き込み増幅が発生し、ディスク スループットがワークロードのボトルネックになる可能性があります。その結果、保留中の圧縮バイトの合計数が時間の経過とともに増加し、フロー制御がトリガーされます。これは、TiKV にはフォアグラウンド書き込みフローに対応するのに十分なディスク帯域幅が不足していることを示しています。
ディスク スループットの制限によって引き起こされるボトルネックを軽減するには、RocksDB の圧縮レベルを上げ、ディスク スループットを下げることでパフォーマンスを向上させることができます。たとえば、次の例を参照して、デフォルトのカラムファミリーのすべての圧縮レベルをzstdに増やすことができます。
[rocksdb.defaultcf]
compression-per-level = ["zstd", "zstd", "zstd", "zstd", "zstd", "zstd", "zstd"]
クロス AZ ネットワーク トラフィックのコストを最適化する
TiDB を複数のアベイラビリティ ゾーン (AZ) にまたがって展開すると、AZ 間のデータ転送料金によりコストが増加する可能性があります。コストを最適化するには、クロス AZ ネットワーク トラフィックを削減することが重要です。
クロス AZ 読み取りトラフィックを削減するには、 Follower Read機能有効にします。これにより、TiDB が同じアベイラビリティ ゾーン内のレプリカを優先的に選択できるようになります。この機能を有効にするには、変数tidb_replica_readをclosest-replicasまたはclosest-adaptiveに設定します。
TiKV インスタンスでのクロス AZ 書き込みトラフィックを削減するには、ネットワーク経由で送信する前にデータを圧縮する gRPC 圧縮機能を有効にします。次の設定例は、TiKV の gzip gRPC 圧縮を有効にする方法を示しています。
server_configs:
tikv:
server.grpc-compression-type: gzip
TiFlash MPP タスクのデータ シャッフルによって発生するネットワーク トラフィックを削減するには、複数のTiFlashインスタンスを同じアベイラビリティ ゾーン (AZ) にデプロイすることをお勧めします。 v6.6.0 以降、デフォルトで圧縮交換が有効になり、MPP データ シャッフルによって発生するネットワーク トラフィックが軽減されます。
Google Cloud でのライブ マイグレーション メンテナンス イベントを軽減する
Google Cloud のライブマイグレーション機能により、ダウンタイムを発生させることなく VM をホスト間でシームレスに移行できます。ただし、これらの移行イベントは、頻度は低いものの、TiDB クラスター内で実行されている VM を含む VM のパフォーマンスに大きな影響を与える可能性があります。このようなイベントが発生すると、影響を受ける VM のパフォーマンスが低下し、TiDB クラスターでのクエリの処理時間が長くなる可能性があります。
Google Cloud によって開始されたライブ マイグレーション イベントを検出し、これらのイベントによるパフォーマンスへの影響を軽減するために、TiDB は Google のメタデータに基づいてスクリプトを見ているを提供します例 。このスクリプトを TiDB、TiKV、および PD ノードにデプロイして、メンテナンス イベントを検出できます。メンテナンス イベントが検出されると、中断を最小限に抑え、クラスターの動作を最適化するために、次のように適切なアクションが自動的に実行されます。
- TiDB: TiDB ノードを遮断し、TiDB ポッドを削除することで、TiDB ノードをオフラインにします。これは、TiDB インスタンスのノード プールが自動スケールに設定されており、TiDB 専用であることを前提としています。ノード上で実行されている他のポッドで中断が発生する可能性があり、封鎖されたノードはオートスケーラーによって再利用されることが予想されます。
- TiKV: メンテナンス中に、影響を受ける TiKV ストアのリーダーを排除します。
- PD: 現在の PD インスタンスが PD リーダーである場合、リーダーを辞任します。
この監視スクリプトは、Kubernetes 環境で TiDB の管理機能を強化するTiDB Operator使用してデプロイされた TiDB クラスター用に特別に設計されていることに注意することが重要です。
監視スクリプトを利用し、メンテナンス イベント中に必要なアクションを実行することで、TiDB クラスタは Google Cloud でのライブ マイグレーション イベントをより適切に処理し、クエリ処理と応答時間への影響を最小限に抑えながら、よりスムーズな操作を保証できます。
高い QPS を備えた大規模 TiDB クラスター向けに PD を調整する
TiDB クラスターでは、TSO (Timestamp Oracle) の提供やリクエストの処理などの重要なタスクを処理するために、単一のアクティブな配置Driver(PD)サーバーが使用されます。ただし、単一のアクティブな PDサーバーに依存すると、TiDB クラスターのスケーラビリティが制限される可能性があります。
PD制限の症状
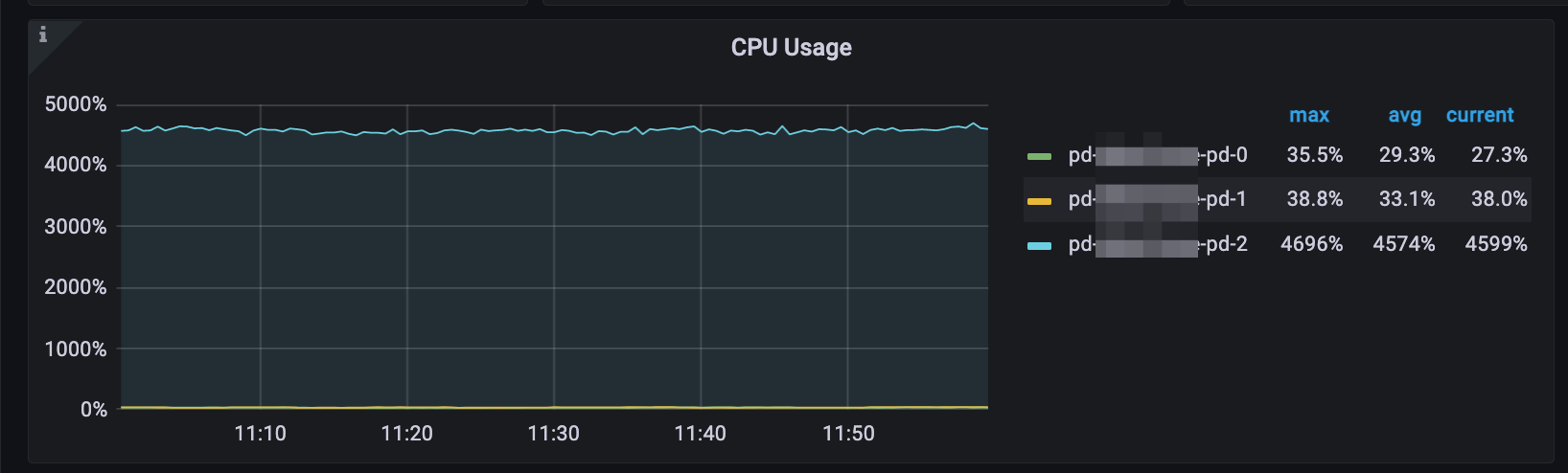
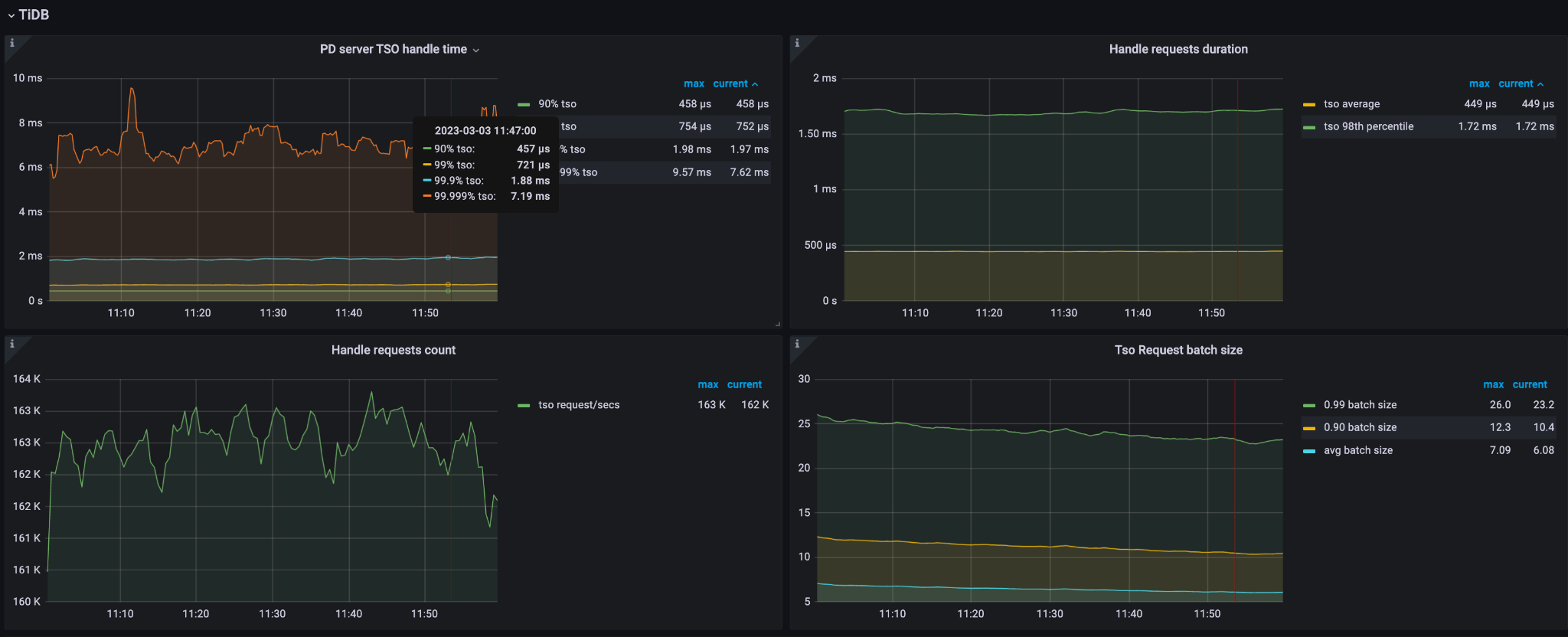
次の図は、それぞれ 56 個の CPU を搭載した 3 台の PD サーバーで構成される大規模 TiDB クラスターの症状を示しています。これらの図から、1 秒あたりのクエリ (QPS) が 100 万を超え、1 秒あたりの TSO (Timestamp Oracle) リクエストが 162,000 を超えると、CPU 使用率が約 4,600% に達することがわかります。この高い CPU 使用率は、PD リーダーに重大な負荷がかかっており、利用可能な CPU リソースが不足していることを示しています。
PD パフォーマンスを調整する
PDサーバーの CPU 使用率が高い問題に対処するには、次のチューニング調整を行うことができます。
PD構成を調整する
tso-update-physical-interval : このパラメータは、PDサーバーが物理 TSO バッチを更新する間隔を制御します。間隔を短くすることで、PDサーバーはTSO バッチをより頻繁に割り当てることができるため、次の割り当てまでの待ち時間が短縮されます。
tso-update-physical-interval = "10ms" # default: 50ms
TiDB グローバル変数を調整する
PD 構成に加えて、TSO クライアントのバッチ待機機能を有効にすると、TSO クライアントの動作をさらに最適化できます。この機能を有効にするには、グローバル変数tidb_tso_client_batch_max_wait_timeをゼロ以外の値に設定します。
set global tidb_tso_client_batch_max_wait_time = 2; # default: 0
TiKV 構成を調整する
リージョンの数を減らし、システムのハートビートオーバーヘッドを軽減するには、TiKV 構成のリージョンサイズを96MBから256MBに増やすことをお勧めします。
[coprocessor]
region-split-size = "256MB"
チューニング後
調整後、次の効果が観察されます。
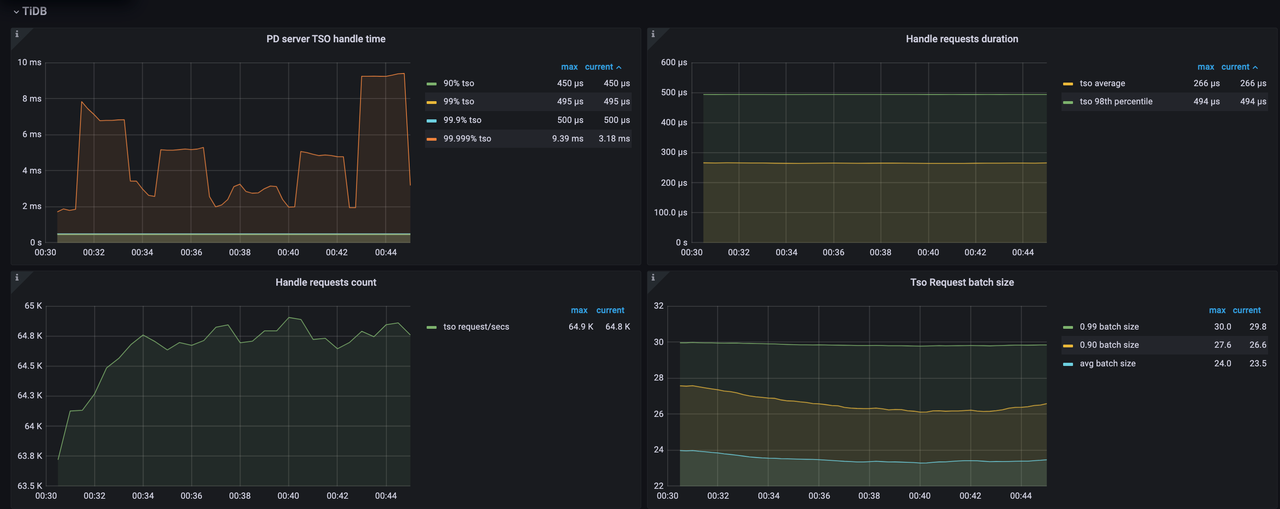
- 1 秒あたりの TSO リクエストは 64,800 に減少します。
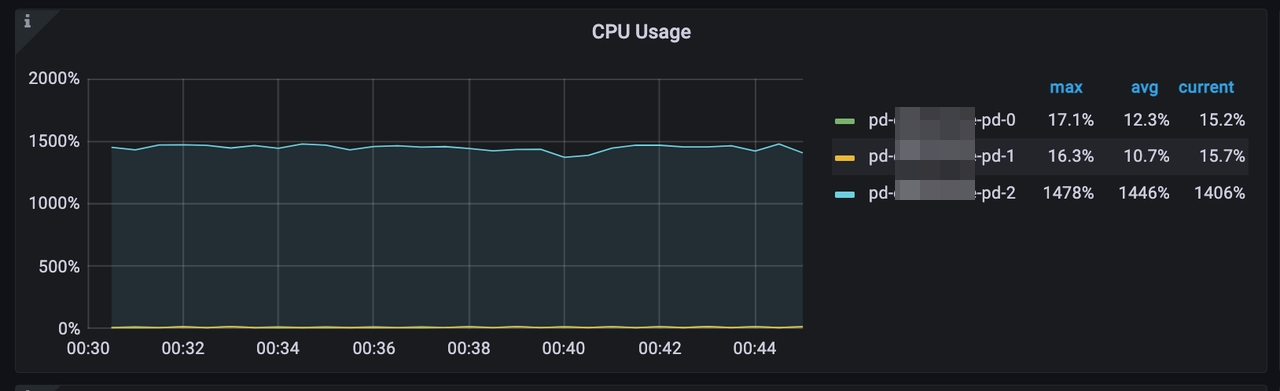
- CPU 使用率は約 4,600% から 1,400% に大幅に減少します。
- P999 値
PD server TSO handle timeは 2ms から 0.5ms に減少します。
これらの改善は、チューニング調整により、安定した TSO 処理パフォーマンスを維持しながら、PDサーバーの CPU 使用率を削減することに成功したことを示しています。