TiCDC の概要
TiCDCは、TiDB の増分データを複製するために使用されるツールです。具体的には、TiCDC は TiKV 変更ログをプルし、キャプチャされたデータを並べ替え、行ベースの増分データをダウンストリーム データベースにエクスポートします。
使用シナリオ
- 複数の TiDB クラスターにデータの高可用性と災害復旧ソリューションを提供し、災害時にプライマリ クラスターとセカンダリ クラスター間の最終的なデータの整合性を確保します。
- リアルタイムのデータ変更を同種システムにレプリケートして、監視、キャッシング、グローバル インデックス作成、データ分析、異種データベース間のプライマリ/セカンダリ レプリケーションなどのさまざまなシナリオにデータ ソースを提供します。
主な特長
主な機能
- 2 番目のレベルの RPO と分レベルの RTO を使用して、1 つの TiDB クラスターから別の TiDB クラスターに増分データをレプリケートします。
- TiCDC を使用してマルチアクティブ TiDB ソリューションを作成できることに基づいて、TiDB クラスター間で双方向にデータを複製します。
- TiDB クラスターから MySQL データベース (またはその他の MySQL 互換データベース) に、低レイテンシーで増分データをレプリケートします。
- TiDB クラスターから Kafka クラスターに増分データを複製します。推奨されるデータ形式にはCanal-JSONとアブロが含まれます。
- データベース、テーブル、DML、および DDL をフィルタリングする機能を使用してテーブルをレプリケートします。
- 単一障害点のない高可用性。 TiCDC ノードの動的な追加と削除をサポートします。
- オープン APIを通じてクラスター管理をサポートします。これには、タスク ステータスのクエリ、タスク構成の動的な変更、およびタスクの作成または削除が含まれます。
複製順序
すべての DDL または DML ステートメントについて、TiCDC はそれらを少なくとも 1 回出力します。
TiKV または TiCDC クラスターで障害が発生すると、TiCDC は同じ DDL/DML ステートメントを繰り返し送信する場合があります。重複する DDL/DML ステートメントの場合:
- MySQL シンクは、DDL ステートメントを繰り返し実行できます。
truncate tableなど、ダウンストリームで繰り返し実行できる DDL ステートメントの場合、ステートメントは正常に実行されます。create tableのように繰り返し実行できないものについては、実行は失敗し、TiCDC はエラーを無視してレプリケーションを続行します。 - カフカシンク
- Kafka シンクは、データ分散のためのさまざまな戦略を提供します。テーブル、主キー、またはタイムスタンプに基づいて、さまざまな Kafka パーティションにデータを分散できます。これにより、行の更新されたデータが同じパーティションに順番に送信されます。
- これらのすべての配布戦略は、解決済み TS メッセージをすべてのトピックとパーティションに定期的に送信します。これは、解決済み TS より前のすべてのメッセージがトピックとパーティションに送信されたことを示します。 Kafka コンシューマーは、解決済み TS を使用して、受信したメッセージを並べ替えることができます。
- Kafka シンクは重複したメッセージを送信することがありますが、これらの重複したメッセージは
Resolved Tsの制約には影響しません。たとえば、変更フィードが一時停止されてから再開された場合、Kafka シンクはmsg1、msg2、msg3、msg2、およびmsg3順番に送信する可能性があります。 Kafka コンシューマーからの重複メッセージをフィルタリングできます。
- MySQL シンクは、DDL ステートメントを繰り返し実行できます。
レプリケーションの一貫性
MySQL シンク
TiCDC は REDO ログを有効にして、データ レプリケーションの結果整合性を保証します。
TiCDC は、単一行の更新の順序がアップストリームの順序と一致することを保証します。
TiCDC は、ダウンストリーム トランザクションの実行順序がアップストリーム トランザクションの実行順序と同じであることを保証しません。
ノート:
v6.2 以降、シンク uri パラメータ
transaction-atomicityを使用して、単一テーブル トランザクションを分割するかどうかを制御できます。単一テーブル トランザクションを分割すると、大規模なトランザクションをレプリケートする際のレイテンシーとメモリ消費を大幅に削減できます。
TiCDCアーキテクチャ
TiDB のインクリメンタル データ レプリケーション ツールとして、TiCDC は PD の etcd を介して高可用性を実現します。複製プロセスは次のとおりです。
- 複数の TiCDC プロセスが TiKV ノードからデータの変更をプルします。
- TiKV から取得されたデータの変更は、内部でソートおよびマージされます。
- データの変更は、複数のレプリケーション タスク (変更フィード) を通じて、複数のダウンストリーム システムにレプリケートされます。
TiCDC のアーキテクチャを次の図に示します。
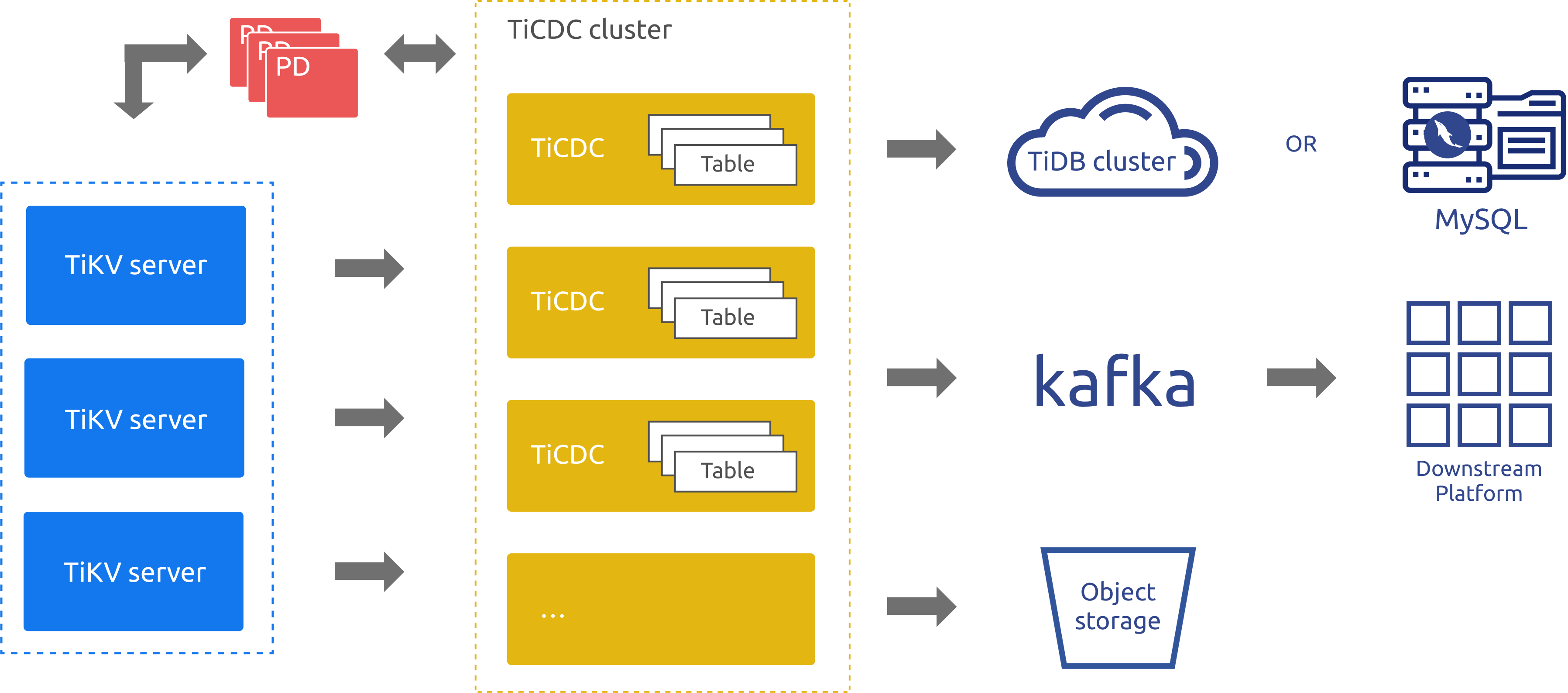
前のアーキテクチャ図のコンポーネントは、次のように説明されています。
- TiKV サーバー: TiDB クラスター内の TiKV ノード。データが変更されると、TiKV ノードは変更を変更ログ (KV 変更ログ) として TiCDC ノードに送信します。 TiCDC ノードは、変更ログが連続していないことを検出すると、TiKV ノードに変更ログを提供するよう積極的に要求します。
- TiCDC: TiCDC プロセスが実行される TiCDC ノード。各ノードは TiCDC プロセスを実行します。各プロセスは、TiKV ノードの 1 つ以上のテーブルからデータの変更を取得し、シンクコンポーネントを介してダウンストリーム システムに変更をレプリケートします。
- PD: TiDB クラスターのスケジューリング モジュール。このモジュールはクラスター データのスケジューリングを担当し、通常は 3 つの PD ノードで構成されます。 PD は、etcd クラスターを通じて高可用性を提供します。 etcd クラスターでは、TiCDC はそのメタデータ (ノードのステータス情報や変更フィードの構成など) を保存します。
前のアーキテクチャ図に示されているように、TiCDC は、TiDB、MySQL、および Kafka データベースへのデータの複製をサポートしています。
ベストプラクティス
TiCDC を使用して 2 つの TiDB クラスター間でデータをレプリケートし、クラスター間のネットワークレイテンシーが 100 ミリ秒を超える場合は、下流の TiDB クラスターが配置されているリージョン (IDC) に TiCDC をデプロイすることをお勧めします。
TiCDC は、少なくとも 1 つの有効なインデックスを持つテーブルのみを複製します。有効なインデックスは次のように定義されます。
- 主キー (
PRIMARY KEY) は有効なインデックスです。 - 一意のインデックス (
UNIQUE INDEX) は、インデックスのすべての列が null 非許容として明示的に定義され (NOT NULL)、インデックスに仮想生成列 (VIRTUAL GENERATED COLUMNS) がない場合に有効です。
- 主キー (
ディザスター リカバリー シナリオで TiCDC を使用するには、構成する必要がありますやり直しログ 。
大きな単一行 (1K を超える) を持つ幅の広いテーブルをレプリケートする場合は、
per-table-memory-quota=ticdcTotalMemory/(tableCount* 2) となるようにper-table-memory-quotaを構成することをお勧めします。ticdcTotalMemoryは TiCDC ノードのメモリで、tableCountは TiCDC ノードがレプリケートするターゲット テーブルの数です。
ノート:
v4.0.8 以降、TiCDC は、タスク構成を変更することにより、有効なインデックスなしでテーブルを複製することをサポートします。ただし、これにより、データの一貫性の保証がある程度損なわれます。詳細については、 有効なインデックスのないテーブルをレプリケートするを参照してください。
サポートされていないシナリオ
現在、次のシナリオはサポートされていません。
- RawKV のみを使用する TiKV クラスター。
- TiDB のDDL 操作
CREATE SEQUENCEとSEQUENCE関数 。アップストリームの TiDB がSEQUENCE使用する場合、TiCDC はアップストリームで実行されたSEQUENCEDDL 操作/関数を無視します。ただし、SEQUENCE関数を使用する DML 操作は正しくレプリケートできます。
TiCDC は、アップストリームでの大規模なトランザクションのシナリオに対して部分的なサポートのみを提供します。詳細については、 TiCDC は大規模なトランザクションの複製をサポートしていますか?リスクはありますか?を参照してください。