プライマリおよびセカンダリ クラスタに基づく DR ソリューション
プライマリ データベースとセカンダリ データベースに基づくディザスター リカバリー (DR) は、一般的なソリューションです。このソリューションでは、DR システムにプライマリ クラスタとセカンダリ クラスタがあります。プライマリ クラスタはユーザー リクエストを処理し、セカンダリ クラスタはプライマリ クラスタからデータをバックアップします。プライマリ クラスタに障害が発生すると、セカンダリ クラスタがサービスを引き継ぎ、バックアップ データを使用してサービスを提供し続けます。これにより、障害による中断が発生することなく、業務システムが正常に稼働し続けることが保証されます。
プライマリ/セカンダリ DR ソリューションには、次の利点があります。
- 高可用性: プライマリ/セカンダリアーキテクチャにより、システムの可用性が向上し、障害からの迅速な復旧が保証されます。
- 迅速な切り替え: プライマリ クラスタに障害が発生した場合、システムはセカンダリ クラスタにすばやく切り替えてサービスを提供し続けることができます。
- データの整合性: セカンダリ クラスターは、プライマリ クラスターのデータをほぼリアルタイムでバックアップします。このように、システムが障害のためにセカンダリ クラスタに切り替わるとき、データは基本的に最新です。
このドキュメントには次の内容が含まれます。
- 主クラスターと副クラスターをセットアップします。
- プライマリ クラスタからセカンダリ クラスタにデータをレプリケートします。
- クラスタを監視します。
- DR 切り替えを実行します。
一方、このドキュメントでは、セカンダリ クラスターでビジネス データをクエリする方法と、プライマリ クラスターとセカンダリ クラスターの間で双方向のレプリケーションを実行する方法についても説明します。
TiCDC に基づいてプライマリ クラスターとセカンダリ クラスターをセットアップする
アーキテクチャ
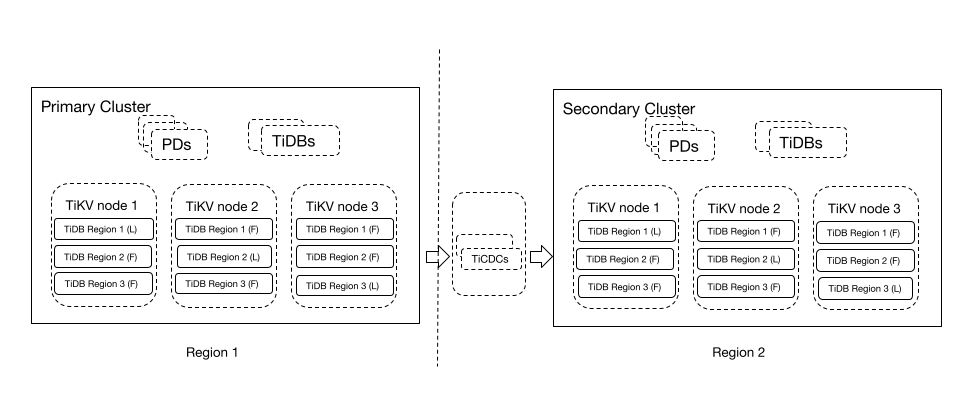
上記のアーキテクチャには、プライマリ クラスタとセカンダリ クラスタの 2 つの TiDB クラスタが含まれています。
- プライマリ クラスター: リージョン 1 で実行され、3 つのレプリカを持つアクティブなクラスター。このクラスターは、読み取りおよび書き込み要求を処理します。
- セカンダリ クラスター: リージョン 2 で実行され、TiCDC を介してプライマリ クラスターからデータをレプリケートするスタンバイ クラスター。
この DRアーキテクチャはシンプルで使いやすいです。地域的な障害に耐えることができる DR システムは、プライマリ クラスタの書き込みパフォーマンスが低下しないことを保証し、セカンダリ クラスタはレイテンシの影響を受けない読み取り専用ビジネスを処理できます。このソリューションの目標復旧時点 (RPO) は秒単位であり、目標復旧時間 (RTO) は数分またはそれ以下になる場合があります。これは、重要な本番システム用に多くのデータベース ベンダーが推奨するソリューションです。
ノート:
- TiKVの「リージョン」データの範囲を意味し、「地域」という用語は物理的な場所を意味します。この 2 つの用語は互換性がありません。
- セカンダリ クラスターにデータをレプリケートするために複数の変更フィードを実行したり、既にセカンダリ クラスターが存在する状態で別のセカンダリ クラスターを実行したりしないでください。そうしないと、セカンダリ クラスタのデータ トランザクションの整合性が保証されません。
プライマリ クラスタとセカンダリ クラスタをセットアップする
このドキュメントでは、TiDB のプライマリ クラスターとセカンダリ クラスターが 2 つの異なるリージョン (リージョン 1 とリージョン 2) にデプロイされます。プライマリ クラスタとセカンダリ クラスタの間に一定のネットワークレイテンシーがあるため、TiCDC はセカンダリ クラスタとともに展開されます。セカンダリ クラスターを使用して TiCDC をデプロイすると、ネットワークレイテンシーの影響を回避でき、最適なレプリケーション パフォーマンスの実現に役立ちます。このドキュメントで提供されている例の展開トポロジは次のとおりです (1 つのコンポーネントノードが 1 つのサーバーに展開されます)。
| リージョン | ホスト | クラスタ | 成分 |
|---|---|---|---|
| リージョン1 | 10.0.1.9 | 主要な | Monitor、Grafana、または AlterManager |
| リージョン2 | 10.0.1.11 | セカンダリ | Monitor、Grafana、または AlterManager |
| リージョン1 | 10.0.1.1/10.0.1.2/10.0.1.3 | 主要な | PD |
| リージョン2 | 10.1.1.1/10.1.1.2/10.1.1.3 | セカンダリ | PD |
| リージョン2 | 10.1.1.9/10.1.1.10 | 主要な | TiCDC |
| リージョン1 | 10.0.1.4/10.0.1.5 | 主要な | TiDB |
| リージョン2 | 10.1.1.4/10.1.1.5 | セカンダリ | TiDB |
| リージョン1 | 10.0.1.6/10.0.1.7/10.0.1.8 | 主要な | TiKV |
| リージョン2 | 10.1.1.6/10.1.1.7/10.1.1.8 | セカンダリ | TiKV |
サーバー構成については、次のドキュメントを参照してください。
TiDB のプライマリ クラスタとセカンダリ クラスタを展開する方法の詳細については、 TiDB クラスターをデプロイを参照してください。
TiCDC をデプロイするときは、セカンダリ クラスターと TiCDC を一緒にデプロイして管理し、それらの間のネットワークを接続する必要があることに注意してください。
TiCDC を既存の主クラスターにデプロイするには、 TiCDCをデプロイを参照してください。
新しいプライマリ クラスターと TiCDC を展開するには、次の展開テンプレートを使用し、必要に応じて構成パラメーターを変更します。
global: user: "tidb" ssh_port: 22 deploy_dir: "/tidb-deploy" data_dir: "/tidb-data" server_configs: {} pd_servers: - host: 10.0.1.1 - host: 10.0.1.2 - host: 10.0.1.3 tidb_servers: - host: 10.0.1.4 - host: 10.0.1.5 tikv_servers: - host: 10.0.1.6 - host: 10.0.1.7 - host: 10.0.1.8 monitoring_servers: - host: 10.0.1.9 grafana_servers: - host: 10.0.1.9 alertmanager_servers: - host: 10.0.1.9 cdc_servers: - host: 10.1.1.9 gc-ttl: 86400 data_dir: "/cdc-data" ticdc_cluster_id: "DR_TiCDC" - host: 10.1.1.10 gc-ttl: 86400 data_dir: "/cdc-data" ticdc_cluster_id: "DR_TiCDC"
プライマリ クラスタからセカンダリ クラスタにデータをレプリケートする
TiDB プライマリ クラスタとセカンダリ クラスタを設定したら、まずデータをプライマリ クラスタからセカンダリ クラスタに移行し、次にレプリケーション タスクを作成して、リアルタイムの変更データをプライマリ クラスタからセカンダリ クラスタにレプリケートします。
外部storageを選択
外部storageは、データを移行し、リアルタイムの変更データをレプリケートするときに使用されます。 Amazon S3 が推奨される選択肢です。 TiDB クラスターが自作のデータ センターにデプロイされている場合は、次の方法が推奨されます。
- MinIOをバックアップstorageシステムとして構築し、S3 プロトコルを使用してデータを MinIO にバックアップします。
- ネットワーク ファイル システム (NAS などの NFS) ディスクを br コマンドライン ツール、TiKV、および TiCDC インスタンスにマウントし、POSIX ファイル システム インターフェイスを使用して、対応する NFS ディレクトリにバックアップ データを書き込みます。
次の例では、MinIO をstorageシステムとして使用しており、参照のみを目的としています。リージョン 1 またはリージョン 2 に MinIO をデプロイするには、別のサーバーを準備する必要があることに注意してください。
wget https://dl.min.io/server/minio/release/linux-amd64/minio
chmod +x minio
# Configure access-key and access-secret-id to access MinIO
export HOST_IP='10.0.1.10' # Replace it with the IP address of MinIO
export MINIO_ROOT_USER='minio'
export MINIO_ROOT_PASSWORD='miniostorage'
# Create the redo and backup directories. `backup` and `redo` are bucket names.
mkdir -p data/redo
mkdir -p data/backup
# Start minio at port 6060
nohup ./minio server ./data --address :6060 &
上記のコマンドは、1 つのノードで MinIOサーバーを起動して、Amazon S3 サービスをシミュレートします。コマンドのパラメーターは次のように構成されます。
endpoint:http://10.0.1.10:6060/access-key:miniosecret-access-key:miniostoragebucket:redo/backup
リンクは次のとおりです。
s3://backup?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true
データを移行する
バックアップと復元機能を使用して、データを主クラスターから副クラスターに移行します。
GC を無効にします。増分移行中に新しく書き込まれたデータが削除されないようにするには、バックアップの前にアップストリーム クラスターの GC を無効にする必要があります。このように、履歴データは削除されません。
次のステートメントを実行して、GC を無効にします。
SET GLOBAL tidb_gc_enable=FALSE;変更が有効であることを確認するには、
tidb_gc_enableの値をクエリします。SELECT @@global.tidb_gc_enable;値が
0の場合、GC が無効になっていることを意味します。+-------------------------+ | @@global.tidb_gc_enable | +-------------------------+ | 0 | +-------------------------+ 1 row in set (0.00 sec)ノート:
本番クラスターでは、GC を無効にしてバックアップを実行すると、クラスターのパフォーマンスに影響を与える可能性があります。オフピーク時にデータをバックアップし、パフォーマンスの低下を避けるために
RATE_LIMITを適切な値に設定することをお勧めします。バックアップデータ。アップストリーム クラスタで
BACKUPステートメントを実行して、データをバックアップします。BACKUP DATABASE * TO '`s3://backup?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true`';+----------------------+----------+--------------------+---------------------+---------------------+ | Destination | Size | BackupTS | Queue Time | Execution Time | +----------------------+----------+--------------------+---------------------+---------------------+ | s3://backup | 10315858 | 431434047157698561 | 2022-02-25 19:57:59 | 2022-02-25 19:57:59 | +----------------------+----------+--------------------+---------------------+---------------------+ 1 row in set (2.11 sec)BACKUPステートメントが実行された後、TiDB はバックアップ データに関するメタデータを返します。バックアップされる前に生成されたデータであるため、BackupTSに注意してください。このドキュメントでは、増分移行の開始としてBackupTSが使用されます。データを復元します。セカンダリ クラスタで
RESTOREステートメントを実行して、データを復元します。RESTORE DATABASE * FROM '`s3://backup?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true`';+----------------------+----------+----------+---------------------+---------------------+ | Destination | Size | BackupTS | Queue Time | Execution Time | +----------------------+----------+----------+---------------------+---------------------+ | s3://backup | 10315858 | 0 | 2022-02-25 20:03:59 | 2022-02-25 20:03:59 | +----------------------+----------+----------+---------------------+---------------------+ 1 row in set (41.85 sec)
増分データをレプリケートする
前のセクションで説明したようにデータを移行した後、 BackupTSから開始して、主クラスターから副クラスターに増分データをレプリケートできます。
チェンジフィードを作成します。
changefeed 構成ファイルを作成します
changefeed.toml。[consistent] # eventual consistency: redo logs are used to ensure eventual consistency in disaster scenarios. level = "eventual" # The size of a single redo log, in MiB. The default value is 64, and the recommended value is less than 128. max-log-size = 64 # The interval for refreshing or uploading redo logs to Amazon S3, in milliseconds. The default value is 1000, and the recommended value range is 500-2000. flush-interval = 2000 # The path where redo logs are saved. storage = "s3://redo?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true"プライマリ クラスタで、次のコマンドを実行して、プライマリ クラスタからセカンダリ クラスタへの変更フィードを作成します。
tiup cdc cli changefeed create --server=http://10.1.1.9:8300 \ --sink-uri="mysql://{username}:{password}@10.1.1.4:4000" \ --changefeed-id="dr-primary-to-secondary" --start-ts="431434047157698561"changefeed 構成の詳細については、 TiCDC Changefeed構成を参照してください。
changefeed タスクが正しく実行されるかどうかを確認するには、
changefeed queryコマンドを実行します。クエリ結果には、タスク情報とタスク状態が含まれます。--simpleまたは-s引数を指定して、基本的な複製状態とチェックポイント情報のみを表示できます。この引数を指定しない場合、出力には詳細なタスク構成、複製状態、および複製テーブル情報が含まれます。tiup cdc cli changefeed query -s --server=http://10.1.1.9:8300 --changefeed-id="dr-primary-to-secondary"{ "state": "normal", "tso": 431434047157998561, # The TSO to which the changefeed has been replicated "checkpoint": "2020-08-27 10:12:19.579", # The physical time corresponding to the TSO "error": null }GC を有効にします。
TiCDC は、レプリケートされる前に履歴データがガベージ コレクションされないようにします。したがって、プライマリ クラスターからセカンダリ クラスターへの変更フィードを作成した後、次のステートメントを実行して GC を再度有効にすることができます。
次のステートメントを実行して、GC を有効にします。
SET GLOBAL tidb_gc_enable=TRUE;変更が有効であることを確認するには、
tidb_gc_enableの値をクエリします。SELECT @@global.tidb_gc_enable;値が
1の場合、GC が有効になっていることを意味します。+-------------------------+ | @@global.tidb_gc_enable | +-------------------------+ | 1 | +-------------------------+ 1 row in set (0.00 sec)
プライマリ クラスタとセカンダリ クラスタを監視する
現在、TiDB で利用できる DR ダッシュボードはありません。次のダッシュボードを使用して TiDB のプライマリ クラスタとセカンダリ クラスタのステータスを確認し、DR スイッチオーバーを実行するかどうかを決定できます。
DR 切り替えを実行する
このセクションでは、計画的な DR 切り替え、災害時の DR 切り替え、およびセカンダリ クラスターを再構築する手順を実行する方法について説明します。
計画的なプライマリおよびセカンダリ スイッチオーバー
重要なビジネス システムの信頼性をテストするために、定期的に DR ドリルを実施することが重要です。 DR ドリルの推奨手順は次のとおりです。シミュレートされたビジネス書き込みと、データベースにアクセスするためのプロキシ サービスの使用は考慮されていないため、手順は実際のアプリケーション シナリオとは異なる場合があることに注意してください。必要に応じて構成を変更できます。
プライマリ クラスタでビジネス書き込みを停止します。
書き込みがなくなったら、TiDB クラスターの最新の TSO (
Position) を照会します。mysql> show master status; +-------------+--------------------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +-------------+--------------------+--------------+------------------+-------------------+ | tidb-binlog | 438223974697009153 | | | | +-------------+--------------------+--------------+------------------+-------------------+ 1 row in set (0.33 sec)条件
TSO >= Positionを満たすまで changefeeddr-primary-to-secondaryをポーリングします。tiup cdc cli changefeed query -s --server=http://10.1.1.9:8300 --changefeed-id="dr-primary-to-secondary" { "state": "normal", "tso": 438224029039198209, # The TSO to which the changefeed has been replicated "checkpoint": "2022-12-22 14:53:25.307", # The physical time corresponding to the TSO "error": null }changefeed
dr-primary-to-secondaryを停止します。変更フィードを削除して一時停止できます。tiup cdc cli changefeed remove --server=http://10.1.1.9:8300 --changefeed-id="dr-primary-to-secondary"start-tsパラメータを指定せずに changefeeddr-secondary-to-primaryを作成します。 changefeed は、現在の時刻からデータの複製を開始します。ビジネス アプリケーションのデータベース アクセス構成を変更します。ビジネス アプリケーションを再起動して、セカンダリ クラスタにアクセスできるようにします。
業務アプリケーションが正常に動作しているか確認してください。
前の手順を繰り返すことで、以前のプライマリおよびセカンダリ クラスタ構成を復元できます。
災害時のプライマリとセカンダリの切り替え
主クラスタが配置されているリージョンで停電などの災害が発生した場合、主クラスタと副クラスタ間のレプリケーションが突然中断されることがあります。その結果、二次クラスタのデータは一次クラスタと一致しなくなります。
セカンダリ クラスタをトランザクションの一貫性のある状態に復元します。具体的には、リージョン 2 の任意の TiCDC ノードで次のコマンドを実行して、REDO ログをセカンダリ クラスターに適用します。
tiup cdc redo apply --storage "s3://redo?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true" --tmp-dir /tmp/redo --sink-uri "mysql://{username}:{password}@10.1.1.4:4000"このコマンドのパラメータの説明は次のとおりです。
--storage: Redo ログが Amazon S3 に保存されるパス--tmp-dir: Amazon S3 から REDO ログをダウンロードするためのキャッシュ ディレクトリ--sink-uri: 二次クラスターのアドレス
ビジネス アプリケーションのデータベース アクセス構成を変更します。ビジネス アプリケーションを再起動して、セカンダリ クラスタにアクセスできるようにします。
業務アプリケーションが正常に動作しているか確認してください。
プライマリ クラスタとセカンダリ クラスタを再構築する
主クラスタで発生した障害が解決した後、または主クラスタを一時的に復旧できない場合、TiDB クラスタは、主クラスタとして機能するのは副クラスタのみであるため、不安定になります。システムの信頼性を維持するには、DR クラスターを再構築する必要があります。
TiDB プライマリ クラスタとセカンダリ クラスタを再構築するには、新しいクラスタを展開して新しい DR システムを形成します。詳細については、次のドキュメントを参照してください。
- プライマリ クラスタとセカンダリ クラスタを設定する
- プライマリ クラスタからセカンダリ クラスタにデータをレプリケートする
- 前述の手順が完了したら、新しい主クラスターを作成します。 プライマリとセカンダリの切り替えを参照してください。
ノート:
プライマリ クラスタとセカンダリ クラスタ間のデータの不整合が解決された場合は、新しいクラスタを展開する代わりに、修復されたクラスタを使用して DR システムを再構築できます。
セカンダリ クラスタでビジネス データをクエリする
プライマリ/セカンダリ DR シナリオでは、セカンダリ クラスタを読み取り専用クラスタとして使用して、レイテンシの影響を受けないクエリを実行するのが一般的です。 TiDB は、プライマリ/セカンダリ DR ソリューションによってこの機能も提供します。
変更フィードを作成するときは、構成ファイルで同期点機能を有効にします。次に、changefeed は定期的に ( sync-point-intervalで) 2 次クラスターでSET GLOBAL tidb_external_ts = @@tidb_current_ts実行して、2 次クラスターにレプリケートされた一貫性のあるスナップショット ポイントを設定します。
セカンダリ クラスタからデータをクエリするには、ビジネス アプリケーションでSET GLOBAL|SESSION tidb_enable_external_ts_read = ON;を設定します。その後、プライマリ クラスタとトランザクション的に一貫性のあるデータを取得できます。
# Starting from v6.4.0, only the changefeed with the SYSTEM_VARIABLES_ADMIN or SUPER privilege can use the TiCDC Syncpoint feature.
enable-sync-point = true
# Specifies the interval at which Syncpoint aligns the primary and secondary snapshots. It also indicates the maximum latency at which you can read the complete transaction, for example, read the transaction data generated on the primary cluster two minutes ago from the secondary cluster.
# The format is in h m s. For example, "1h30m30s". The default value is "10m" and the minimum value is "30s".
sync-point-interval = "10m"
# Specifies how long the data is retained by Syncpoint in the downstream table. When this duration is exceeded, the data is cleaned up.
# The format is in h m s. For example, "24h30m30s". The default value is "24h".
sync-point-retention = "1h"
[consistent]
# eventual consistency: redo logs are used to ensure eventual consistency in disaster scenarios.
level = "eventual"
# The size of a single redo log, in MiB. The default value is 64, and the recommended value is less than 128.
max-log-size = 64
# Interval for refreshing or uploading redo logs to Amazon S3, in milliseconds. The default value is 1000, and the recommended value range is 500-2000.
flush-interval = 2000
# The path where redo logs are saved.
storage = "s3://redo?access-key=minio&secret-access-key=miniostorage&endpoint=http://10.0.1.10:6060&force-path-style=true"
ノート:
プライマリ/セカンダリ DRアーキテクチャでは、セカンダリ クラスターは 1 つの変更フィードからのデータのみをレプリケートできます。そうしないと、セカンダリ クラスタのデータ トランザクションの整合性が保証されません。
プライマリ クラスタとセカンダリ クラスタの間で双方向のレプリケーションを実行する
この DR シナリオでは、2 つのリージョンの TiDB クラスターが互いのディザスター リカバリー クラスターとして機能できます。ビジネス トラフィックは、リージョン構成に基づいて対応する TiDB クラスターに書き込まれ、2 つの TiDB クラスターが互いのデータをバックアップします。
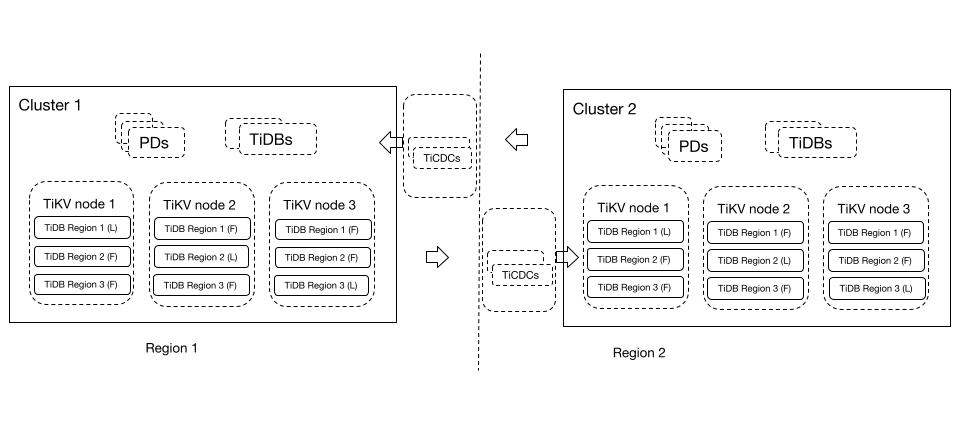
双方向レプリケーション機能により、2 つのリージョンの TiDB クラスターは互いのデータをレプリケートできます。この DR ソリューションは、データのセキュリティと信頼性を保証し、データベースの書き込みパフォーマンスも保証します。計画的な DR スイッチオーバーでは、新しい変更フィードを開始する前に実行中の変更フィードを停止する必要がないため、運用と保守が簡素化されます。
双方向の DR クラスターを構築するには、 TiCDC 双方向レプリケーションを参照してください。
トラブルシューティング
上記の手順で問題が発生した場合は、まずTiDB よくある質問で問題の解決策を見つけることができます。問題が解決しない場合は、GitHub で問題を報告できます。