毎日のチェック
TiDBは分散型データベースであるため、仕組みや監視項目が単体型データベースよりも複雑です。 TiDB をより便利な方法で操作および保守するために、このドキュメントでは主要なパフォーマンス指標をいくつか紹介します。
TiDB ダッシュボードの主な指標
v4.0 から、TiDB は新しい運用および保守管理ツールTiDB ダッシュボードを提供します。このツールは PDコンポーネントに統合されています。デフォルトのアドレスhttp://${pd-ip}:${pd_port}/dashboardで TiDB ダッシュボードにアクセスできます。
TiDB ダッシュボードは、TiDB データベースの操作と保守を簡素化します。 1 つのインターフェイスを介して、TiDB クラスター全体の実行ステータスを表示できます。以下は、いくつかのパフォーマンス指標の説明です。
インスタンス パネル
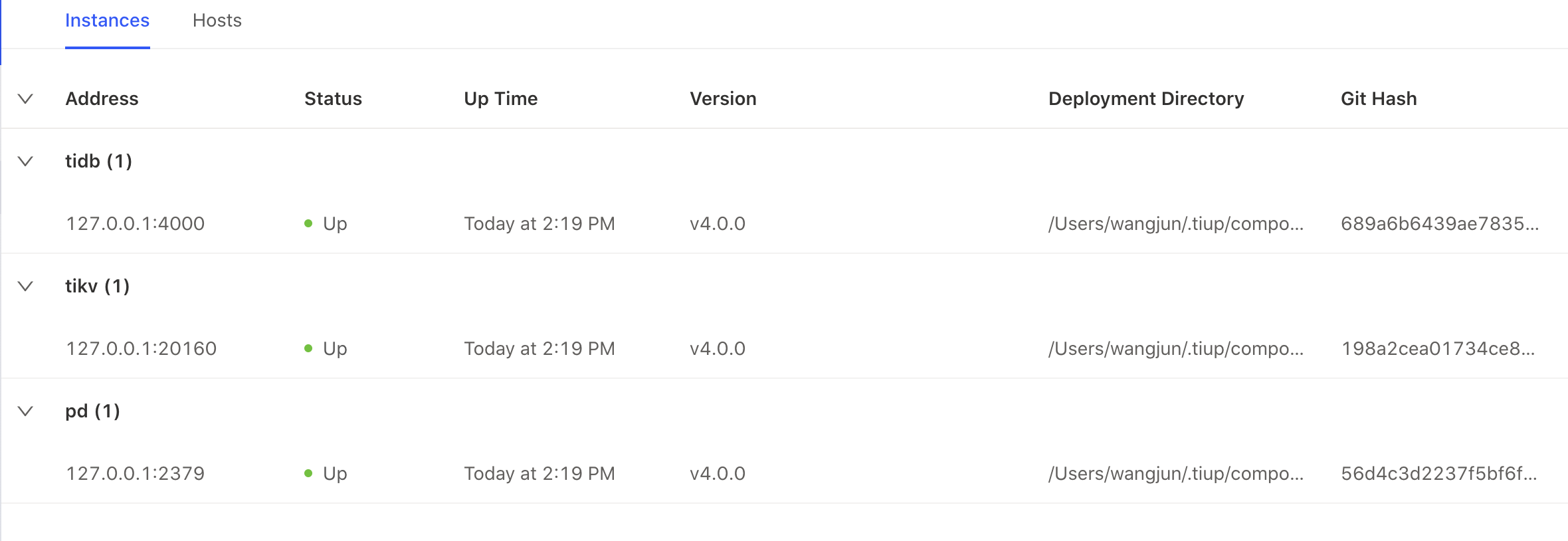
- ステータス: このインジケータは、ステータスが正常かどうかを確認するために使用されます。オンライン ノードの場合、これは無視できます。
- Up Time : 重要な指標。
Up Timeが変更されていることがわかった場合は、コンポーネントが再起動された理由を特定する必要があります。 - Version 、 Deployment Directory 、 Git Hash : これらの指標は、一貫性のない、または誤ったバージョン/展開ディレクトリを避けるためにチェックする必要があります。
ホスト パネル

CPU、メモリ、およびディスクの使用状況を表示できます。いずれかのリソースの使用率が 80% を超える場合は、それに応じて容量をスケールアウトすることをお勧めします。
SQL分析パネル
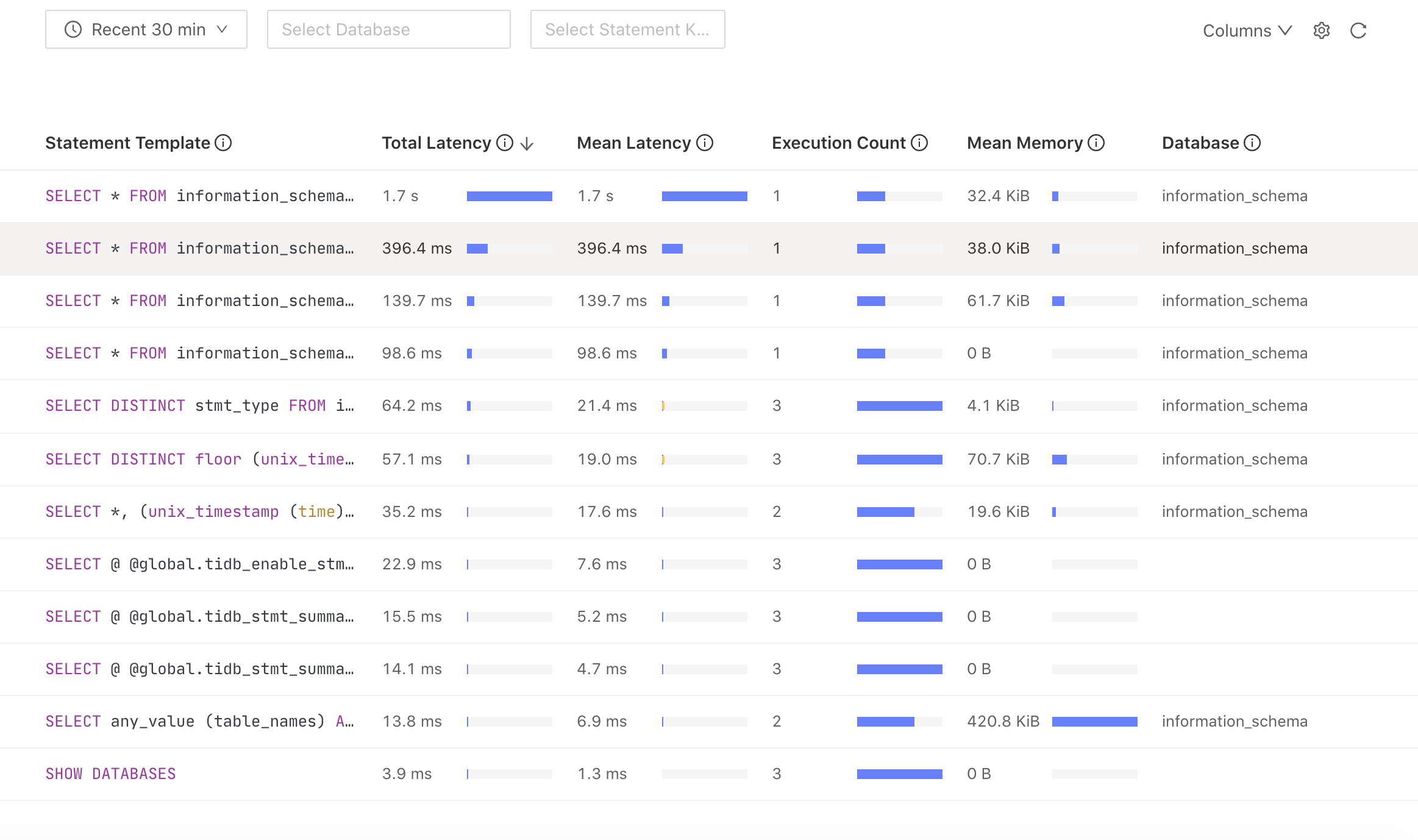
クラスターで実行された遅い SQL ステートメントを見つけることができます。次に、特定の SQL ステートメントを最適化できます。
リージョンパネル
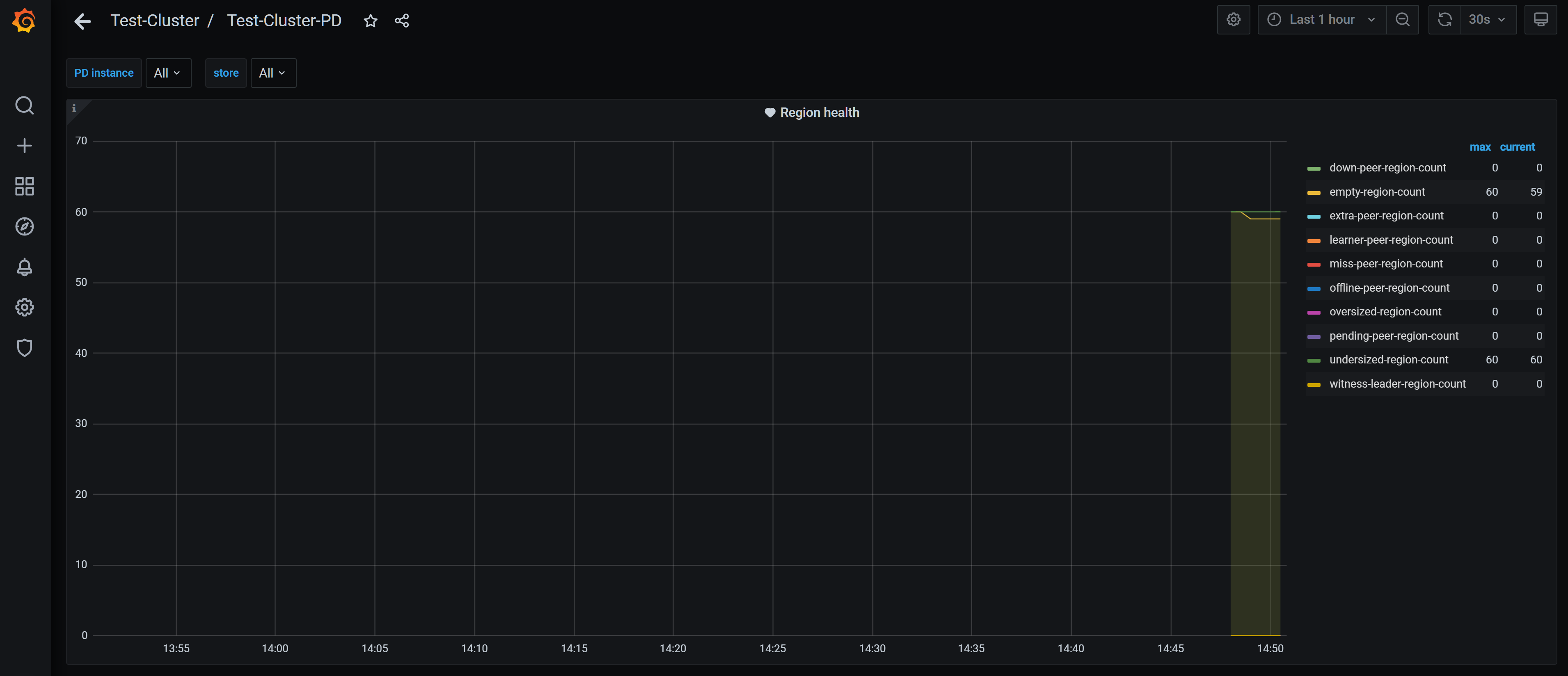
miss-peer-region-count: 十分なレプリカがないリージョンの数。この値は常に0より大きいとは限りません。extra-peer-region-count: 追加のレプリカを持つリージョンの数。これらのリージョンは、スケジューリング プロセス中に生成されます。empty-region-count:TRUNCATE TABLE/DROP TABLEステートメントの実行によって生成された空のリージョンの数。この数が大きい場合は、Region Merge有効にして、テーブル間でリージョンをマージすることを検討できます。pending-peer-region-count: Raftログが古いリージョンの数。スケジューリング プロセスでいくつかの保留中のピアが生成されるのは正常です。ただし、この値が一定時間(30 分以上)大きい場合は正常ではありません。down-peer-region-count: Raftリーダーによって報告された応答のないピアを持つリージョンの数。offline-peer-region-count: オフライン プロセス中のリージョンの数。
一般に、これらの値が0でないことは正常です。ただし、かなり長い間0ではないことは正常ではありません。
KV リクエスト期間
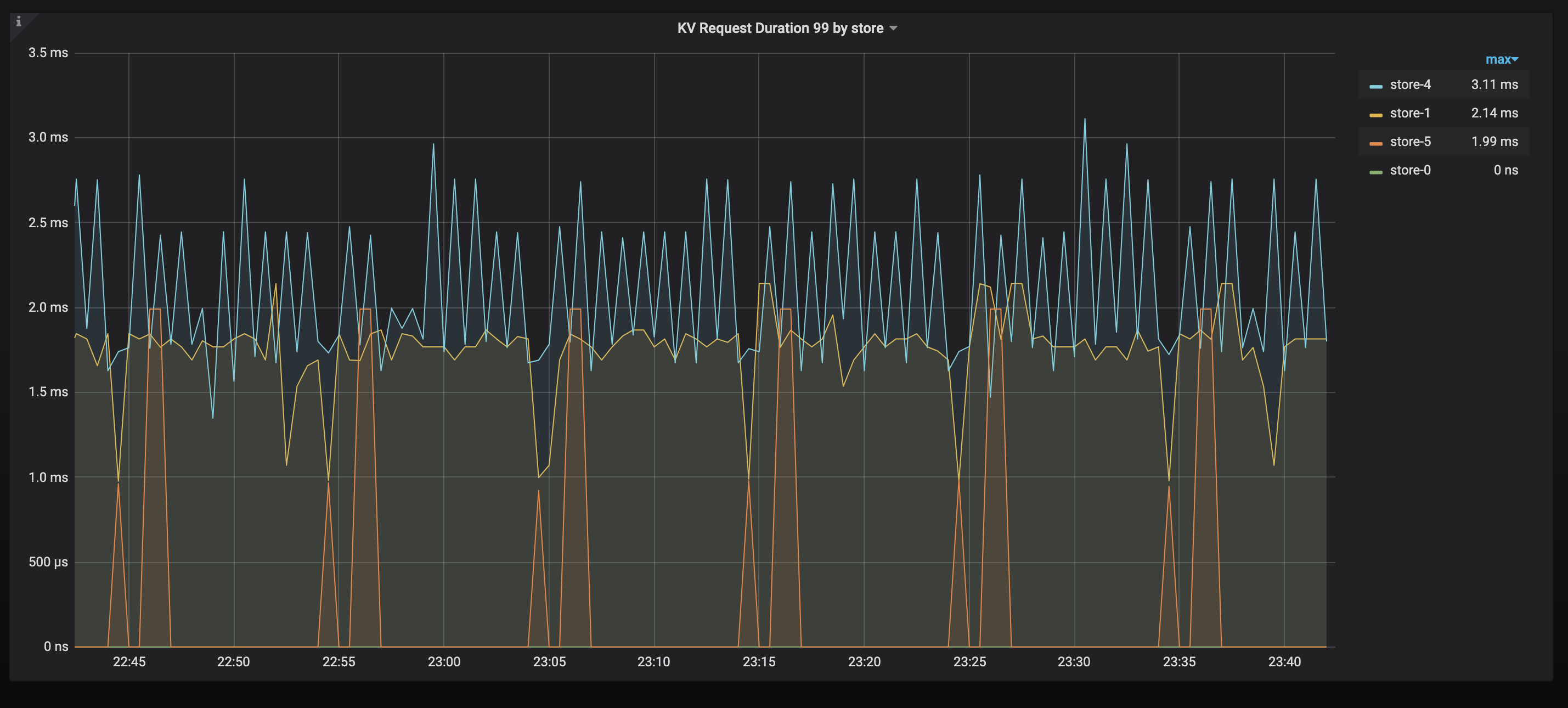
TiKV での KV 要求期間 99。継続時間が長いノードが見つかった場合は、ホット スポットがあるかどうか、またはパフォーマンスの低いノードがあるかどうかを確認します。
PD TSO 待機期間
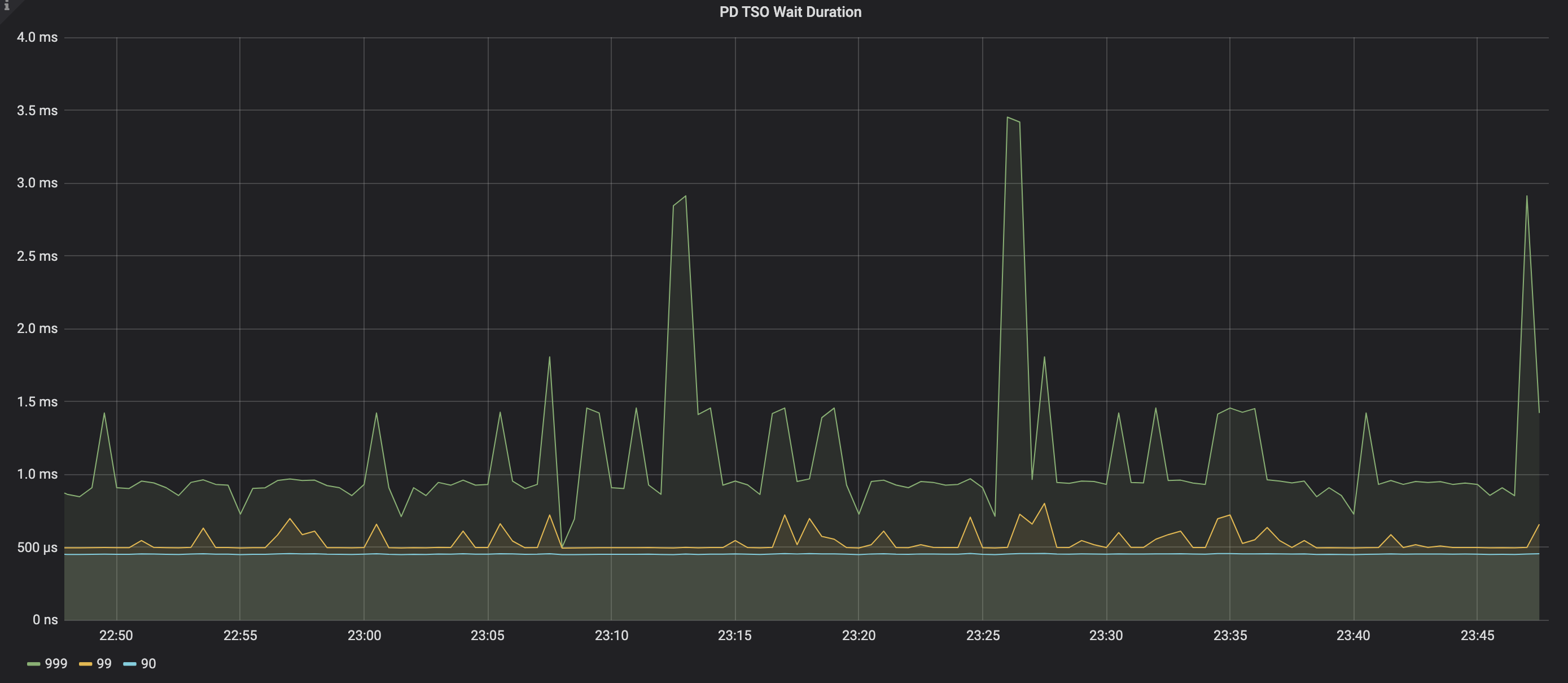
TiDB が PD から TSO を取得するのにかかる時間。待ち時間が長くなる理由は次のとおりです。
- TiDB から PD への高いネットワークレイテンシー。 ping コマンドを手動で実行して、ネットワークレイテンシーをテストできます。
- TiDBサーバーの負荷が高い。
- PDサーバーの負荷が高い。
概要パネル
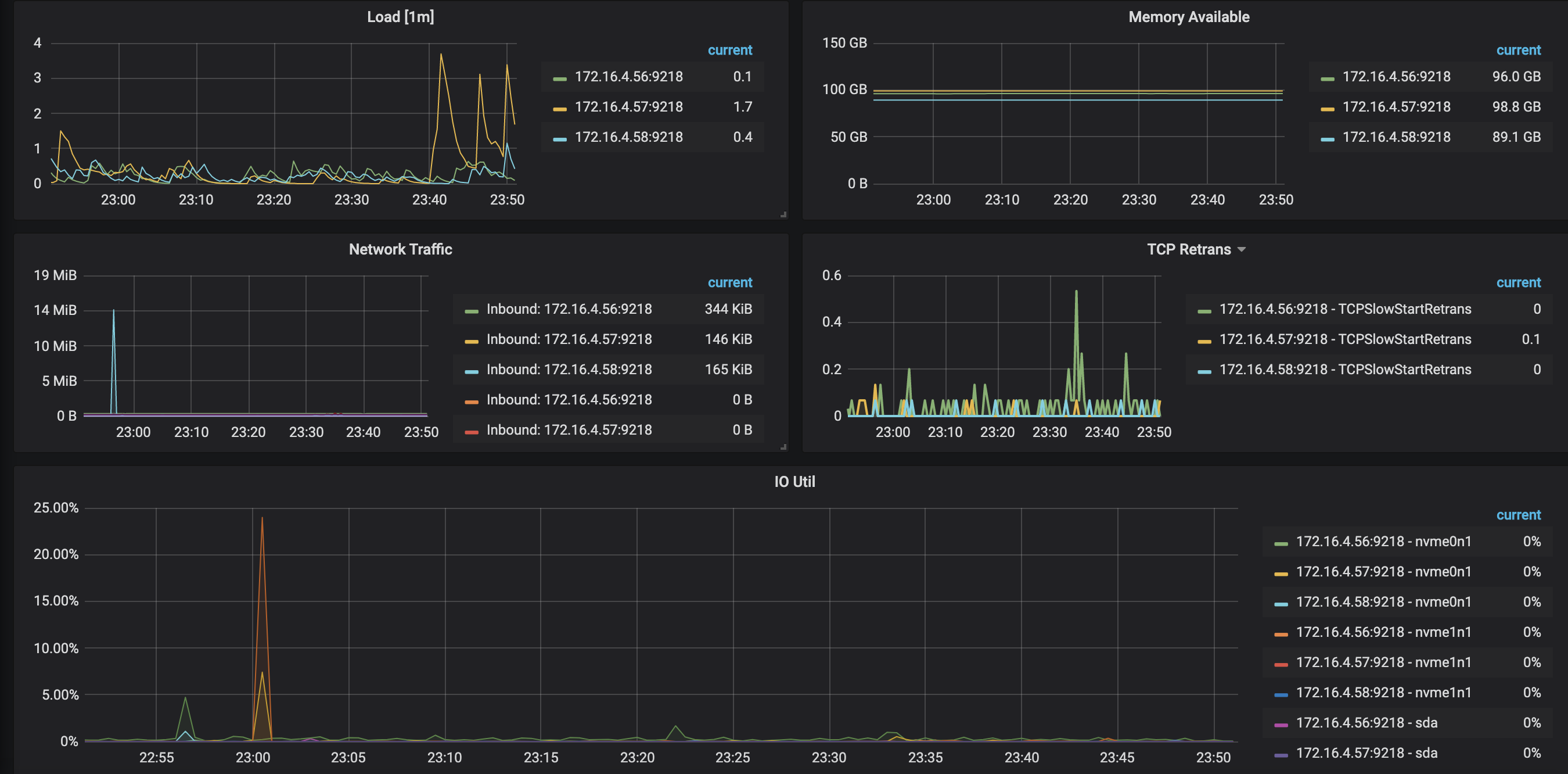
負荷、使用可能なメモリ、ネットワーク トラフィック、および I/O ユーティリティを表示できます。ボトルネックが見つかった場合は、容量をスケールアウトするか、クラスター トポロジ、SQL、およびクラスター パラメーターを最適化することをお勧めします。
例外
各 TiDB インスタンスでの SQL ステートメントの実行によってトリガーされたエラーを表示できます。これらには、構文エラーと主キーの競合が含まれます。
GC ステータス
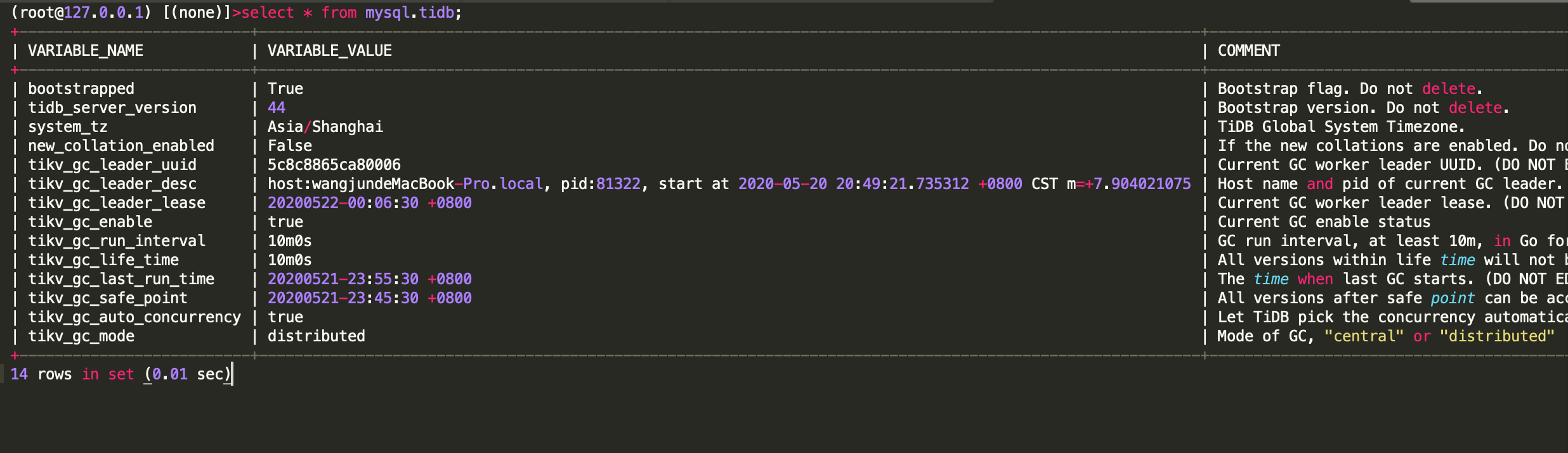
GC (ガベージ コレクション) の状態が正常かどうかは、最後の GC が発生した時刻を表示することで確認できます。 GC が異常であると、履歴データが過剰になり、アクセス効率が低下する可能性があります。