高度な同時書き込みのベスト プラクティス
このドキュメントでは、アプリケーション開発を容易にするのに役立つ TiDB での同時書き込み負荷の高いワークロードを処理するためのベスト プラクティスについて説明します。
対象者
このドキュメントは、TiDB の基本的な知識があることを前提としています。最初に、TiDB の基礎を説明する次の 3 つのブログ記事とTiDB のベスト プラクティスを読むことをお勧めします。
同時書き込みの多いシナリオ
クリアリングや決済などのアプリケーションでバッチ タスクを実行する場合、高度な同時書き込みシナリオがよく発生します。このシナリオには、次の機能があります。
- 膨大な量のデータ
- 履歴データを短時間でデータベースにインポートする必要性
- データベースから大量のデータを短時間で読み取る必要がある
これらの機能は、TiDB に次の課題をもたらします。
- 書き込みまたは読み取り容量は、直線的に拡張可能でなければなりません。
- データベースのパフォーマンスは安定しており、大量のデータが同時に書き込まれても低下しません。
分散データベースでは、すべてのノードの容量を最大限に活用し、1 つのノードがボトルネックにならないようにすることが重要です。
TiDB におけるデータ配布の原則
上記の課題に対処するには、TiDB のデータ セグメンテーションとスケジューリングの原則から始める必要があります。詳細については、 スケジューリングを参照してください。
TiDB はデータをリージョンに分割し、それぞれがデフォルトで 96M のサイズ制限を持つデータの範囲を表します。各リージョンには複数のレプリカがあり、レプリカの各グループはRaftグループと呼ばれます。 Raftグループでは、リージョンリーダーがデータ範囲内で読み取りおよび書き込みタスク (TiDB がサポートするフォロワー読み取り ) を実行します。リージョンリーダーは、配置Driver(PD) コンポーネントによってさまざまな物理ノードに自動的にスケジュールされ、読み取りと書き込みの負荷が均等に分散されます。
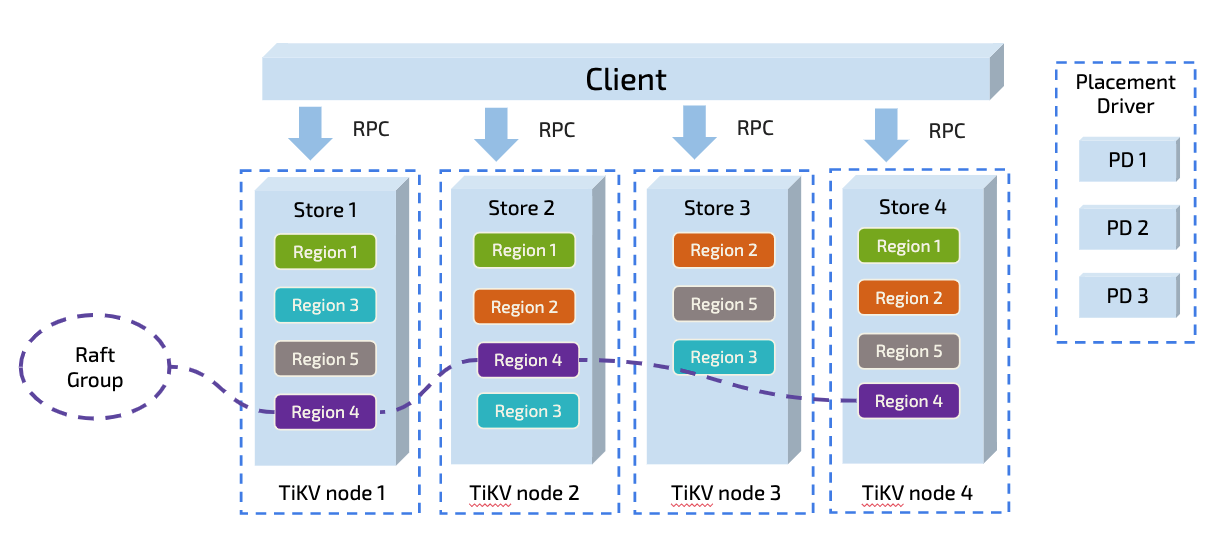
理論的には、アプリケーションに書き込みホットスポットがない場合、TiDB はそのアーキテクチャのおかげで、読み取りおよび書き込み容量を直線的にスケーリングできるだけでなく、分散リソースを最大限に活用することもできます。この観点から、TiDB は同時実行が多く、書き込みが集中するシナリオに特に適しています。
しかし、実際の状況はしばしば理論上の仮定とは異なります。
ノート:
アプリケーションに書き込みホットスポットがないということは、書き込みシナリオに
AUTO_INCREMENTの主キーまたは単調に増加するインデックスがないことを意味します。
ホットスポットケース
次のケースでは、ホットスポットがどのように生成されるかを説明します。以下の表を例に取ります。
CREATE TABLE IF NOT EXISTS TEST_HOTSPOT(
id BIGINT PRIMARY KEY,
age INT,
user_name VARCHAR(32),
email VARCHAR(128)
)
このテーブルは構造が単純です。主キーとしてのidに加えて、副次索引は存在しません。次のステートメントを実行して、このテーブルにデータを書き込みます。 idは乱数として離散的に生成されます。
SET SESSION cte_max_recursion_depth = 1000000;
INSERT INTO TEST_HOTSPOT
SELECT
n, -- ID
RAND()*80, -- Number between 0 and 80
CONCAT('user-',n),
CONCAT(
CHAR(65 + (RAND() * 25) USING ascii), -- Number between 65 and 65+25, converted to a character, A-Z
'-user-',
n,
'@example.com'
)
FROM
(WITH RECURSIVE nr(n) AS
(SELECT 1 -- Start CTE at 1
UNION ALL SELECT n + 1 -- increase n with 1 every loop
FROM nr WHERE n < 1000000 -- stop loop at 1_000_000
) SELECT n FROM nr
) a;
負荷は、上記のステートメントを短時間で集中的に実行することから生じます。
理論的には、上記の操作は TiDB のベスト プラクティスに準拠しているようで、アプリケーションにホットスポットは発生しません。 TiDB の分散容量は、適切なマシンで十分に使用できます。それが本当にベスト プラクティスに沿っているかどうかを検証するために、次のように説明されている実験的環境でテストが行われます。
クラスタ トポロジでは、2 つの TiDB ノード、3 つの PD ノード、および 6 つの TiKV ノードがデプロイされます。このテストはベンチマークではなく原理を明確にするためのものであるため、QPS パフォーマンスは無視します。
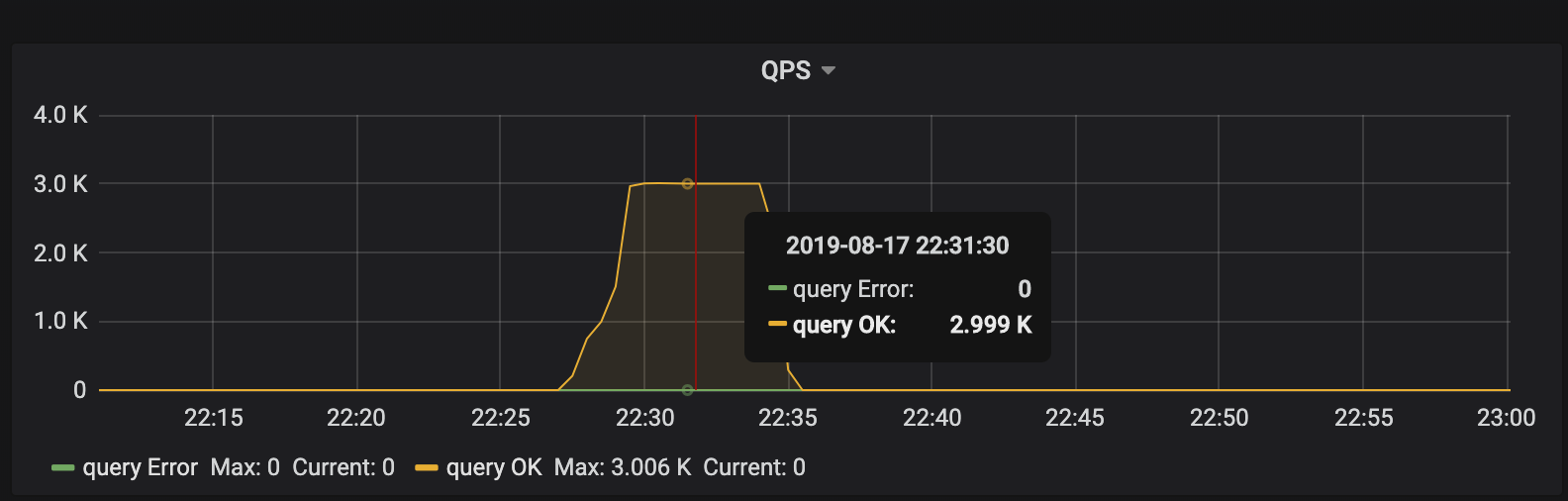
クライアントは短時間で「集中的な」書き込み要求を開始します。これは、TiDB が受け取る 3K QPS です。理論的には、負荷圧力は 6 つの TiKV ノードに均等に分散する必要があります。ただし、各 TiKV ノードの CPU 使用率から、負荷分散は不均一です。 tikv-3のノードは書き込みホットスポットです。
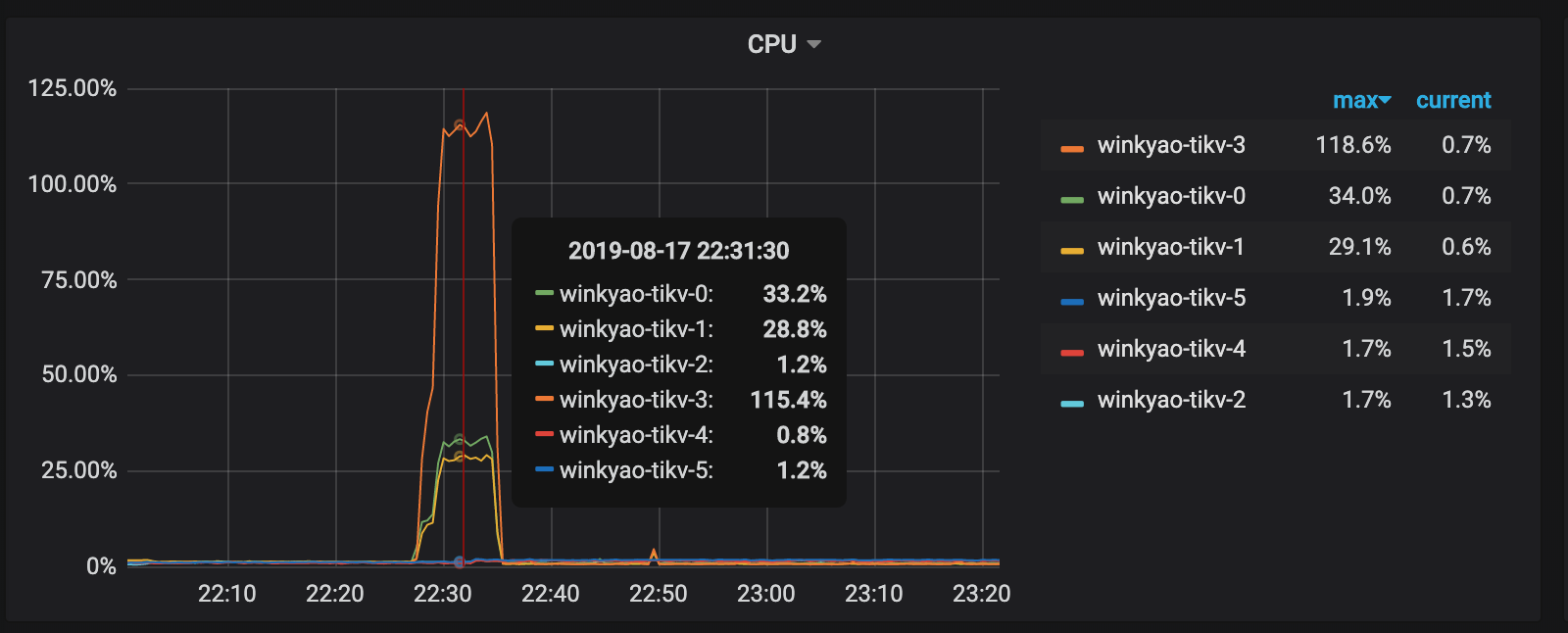
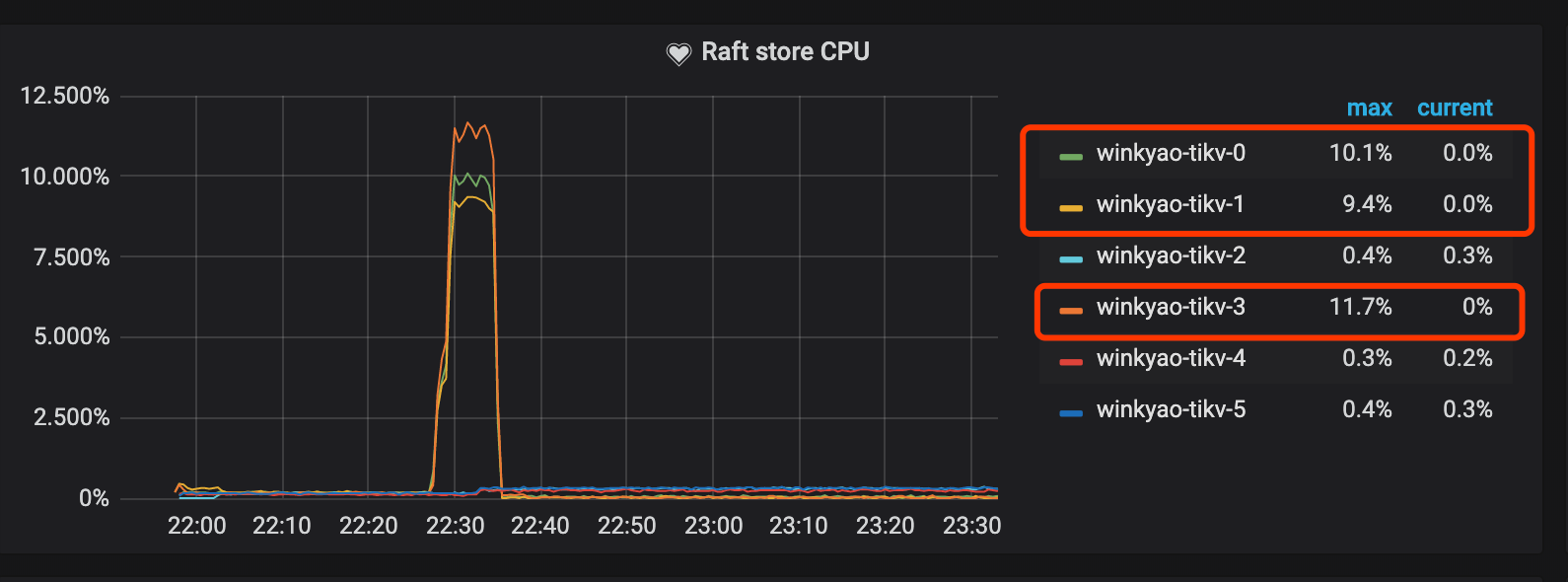
RaftストアCPUはraftstoreスレッドの CPU 使用率で、通常は書き込み負荷を表します。このシナリオでは、 tikv-3がこのRaftグループのリーダーです。 tikv-0とtikv-1はフォロワーです。他のノードの負荷はほとんど空です。
PD の監視メトリクスでも、ホットスポットが発生していることを確認できます。
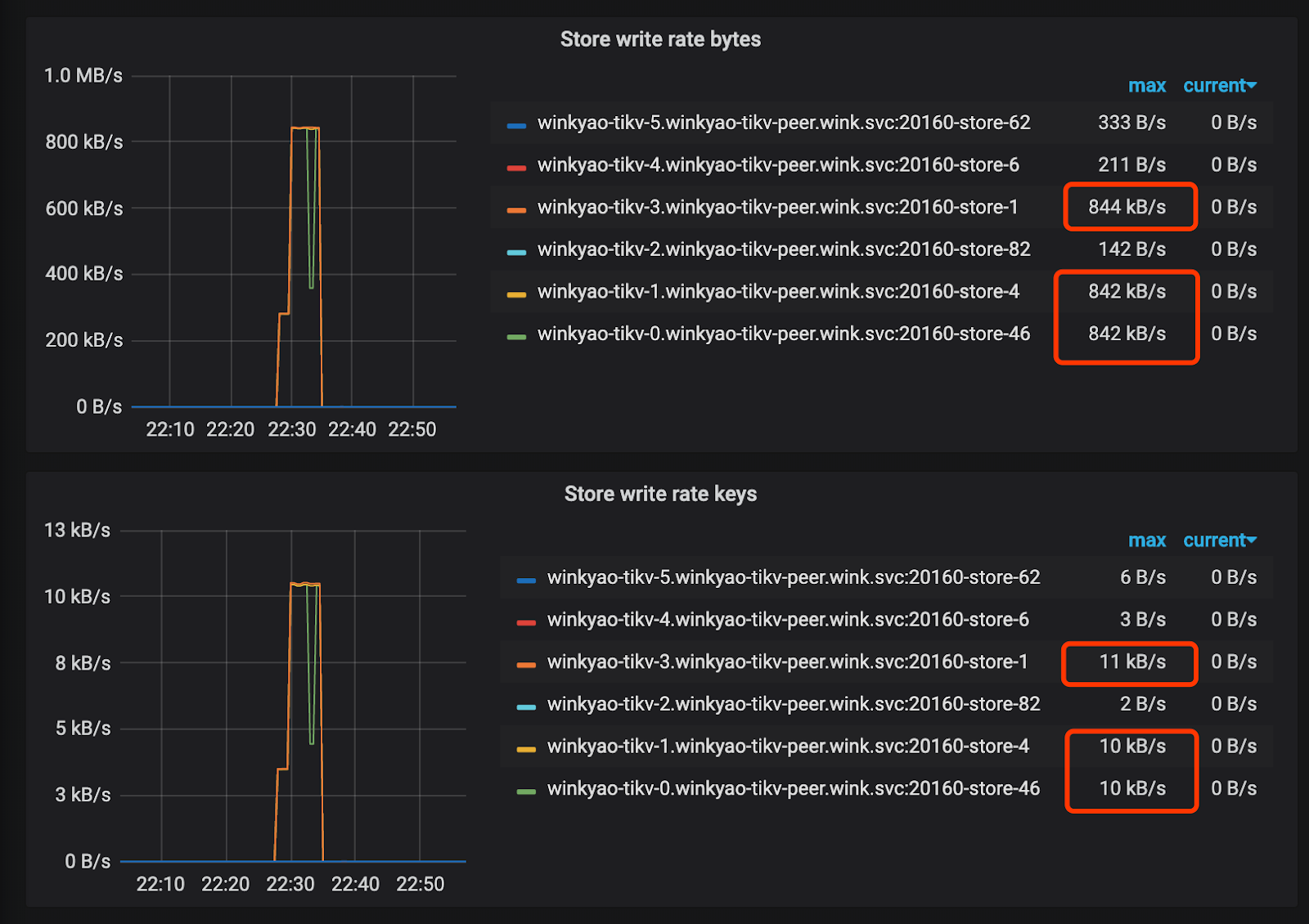
ホットスポットの原因
上記のテストでは、操作はベスト プラクティスで期待される理想的なパフォーマンスに達していません。これは、TiDB に新しく作成された各テーブルのデータを格納するために、デフォルトで 1 つのリージョンのみが分割され、次のデータ範囲があるためです。
[CommonPrefix + TableID, CommonPrefix + TableID + 1)
短期間に大量のデータが同じリージョンに継続的に書き込まれます。
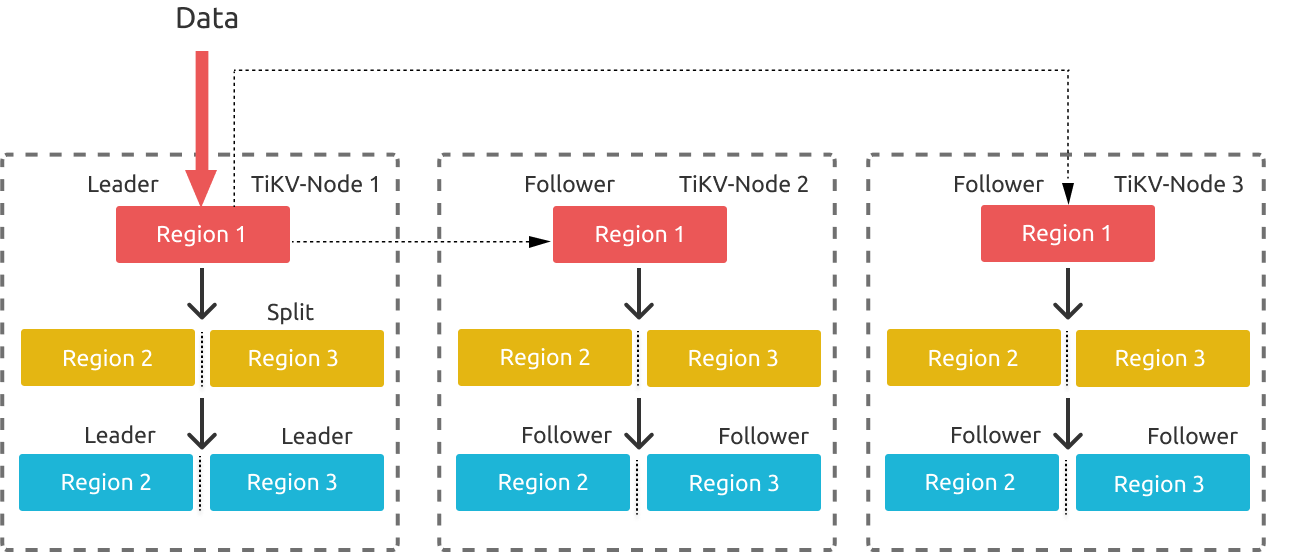
上の図は、リージョン分割プロセスを示しています。データが継続的に TiKV に書き込まれると、TiKV はリージョンを複数のリージョンに分割します。リーダーの選出は、分割されるリージョンリーダーが配置されている元のストアで開始されるため、新しく分割された 2 つのリージョンのリーダーが同じストアに残っている可能性があります。この分割プロセスは、新しく分割されたリージョン2 とリージョン3 でも発生する可能性があります。このようにして、書き込み圧力は TiKV ノード 1 に集中します。
連続書き込みプロセス中に、ノード 1 でホットスポットが発生していることを確認した後、PD は集中したリーダーを他のノードに均等に分散します。 TiKV ノードの数がリージョンレプリカの数より多い場合、TiKV はこれらのリージョンをアイドル ノードに移行しようとします。書き込みプロセス中のこれら 2 つの操作は、PD のモニタリング メトリックにも反映されます。
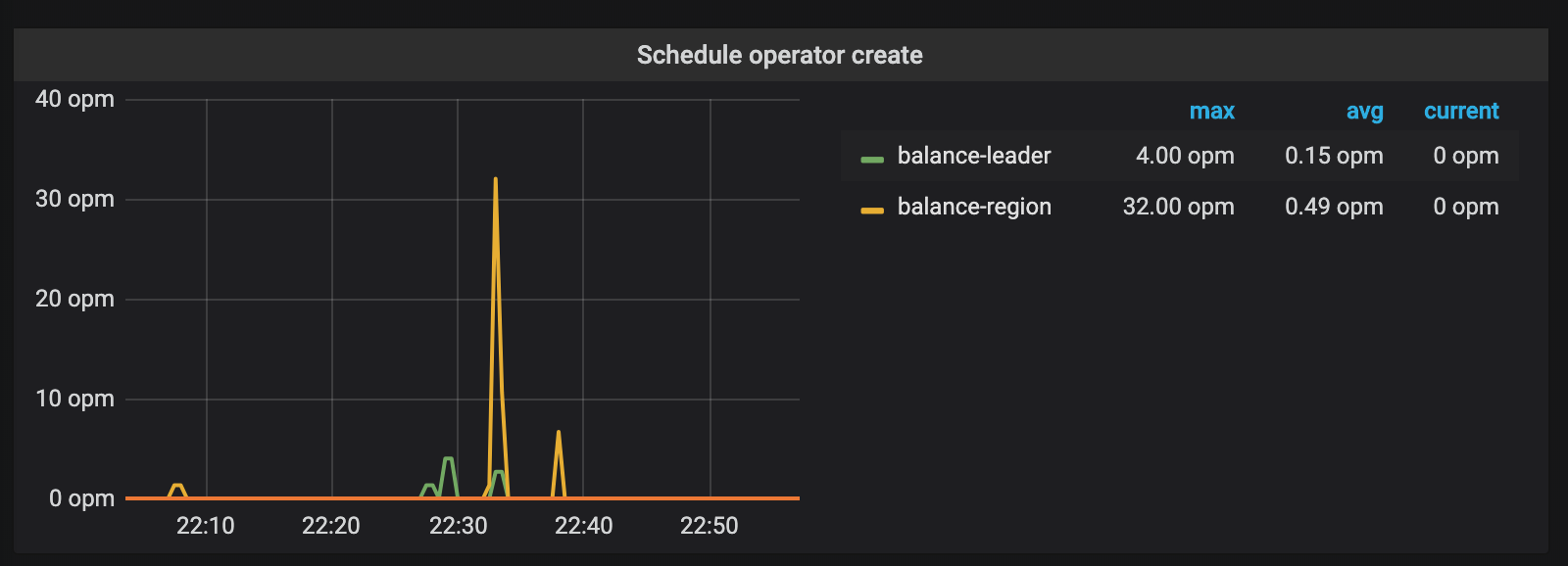
一定期間の継続的な書き込みの後、PD は TiKV クラスター全体を自動的にスケジュールして、圧力が均等に分散される状態にします。その時までに、クラスター全体の容量を完全に使用できます。
ほとんどの場合、ホットスポットを引き起こす上記のプロセスは正常であり、これはデータベースのリージョンウォームアップ フェーズです。ただし、同時書き込みが集中するシナリオでは、このフェーズを避ける必要があります。
ホットスポット ソリューション
理論的に期待される理想的なパフォーマンスを実現するには、リージョンを必要な数のリージョンに直接分割し、これらのリージョンをクラスター内の他のノードに事前にスケジュールすることで、ウォームアップ フェーズをスキップできます。
v3.0.x、v2.1.13、およびそれ以降のバージョンでは、TiDB は分割リージョンという新しい機能をサポートしています。この新機能により、次の新しい構文が提供されます。
SPLIT TABLE table_name [INDEX index_name] BETWEEN (lower_value) AND (upper_value) REGIONS region_num
SPLIT TABLE table_name [INDEX index_name] BY (value_list) [, (value_list)]
ただし、TiDB はこの事前分割操作を自動的に実行しません。その理由は、TiDB 内のデータ配布に関連しています。
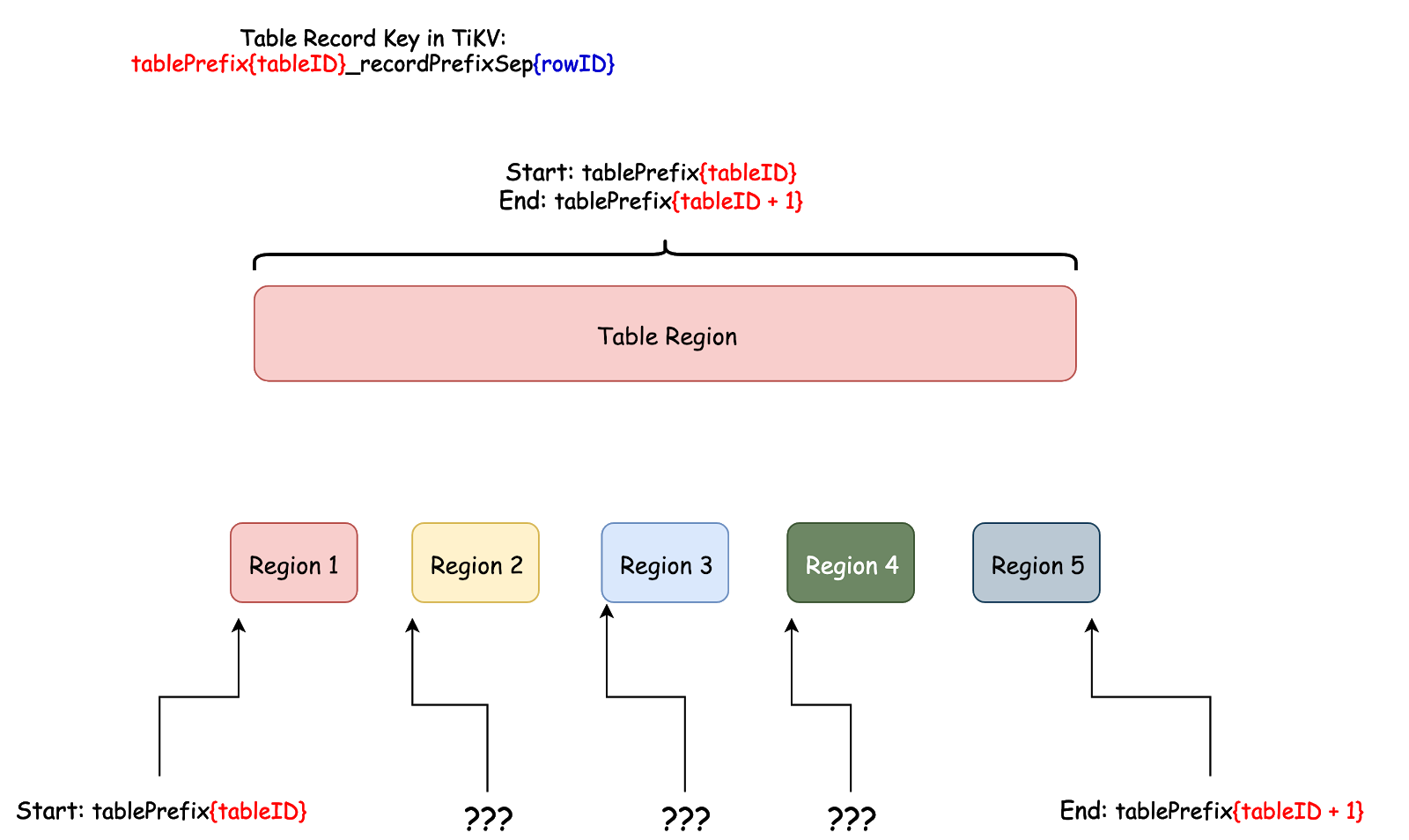
上記の図から、行のキーのエンコード規則によると、 rowIDが唯一の変数部分です。 TiDB では、 rowIDはInt64の整数です。ただし、リージョンの分割も実際の状況に基づく必要があるため、 Int64の整数範囲を目的の範囲数に均等に分割してから、これらの範囲を異なるノードに分散する必要はない場合があります。
rowIDの書き込みが完全に離散的である場合、上記の方法ではホットスポットは発生しません。行 ID またはインデックスに固定の範囲またはプレフィックスがある場合 (たとえば、データを[2000w, 5000w)の範囲に個別に挿入する場合)、ホットスポットは発生しません。ただし、上記の方法を使用してリージョンを分割すると、最初に同じリージョンにデータが書き込まれる可能性があります。
TiDB は一般的な用途のデータベースであり、データの分布については想定していません。そのため、最初は 1 つのリージョンのみを使用してテーブルのデータを格納し、実際のデータが挿入された後、データの分布に従ってリージョンを自動的に分割します。
この状況とホットスポットの問題を回避する必要があることを考慮して、TiDB は、同時書き込みが多いシナリオのパフォーマンスを最適化するSplit Regionの構文を提供します。上記のケースに基づいて、 Split Region構文を使用してリージョンを分散し、負荷分散を観察します。
テストで書き込まれるデータは正の範囲内で完全に離散しているため、次のステートメントを使用して、テーブルをminInt64とmaxInt64の範囲内の 128 のリージョンに事前に分割できます。
SPLIT TABLE TEST_HOTSPOT BETWEEN (0) AND (9223372036854775807) REGIONS 128;
pre-split 操作の後、 SHOW TABLE test_hotspot REGIONS;ステートメントを実行して、 リージョン Scattering のステータスを確認します。 SCATTERING列の値がすべて0の場合、スケジューリングは成功です。
次の SQL ステートメントを使用して、リージョンリーダーの分布を確認することもできます。 table_nameを実際のテーブル名に置き換える必要があります。
SELECT
p.STORE_ID,
COUNT(s.REGION_ID) PEER_COUNT
FROM
INFORMATION_SCHEMA.TIKV_REGION_STATUS s
JOIN INFORMATION_SCHEMA.TIKV_REGION_PEERS p ON s.REGION_ID = p.REGION_ID
WHERE
TABLE_NAME = 'table_name'
AND p.is_leader = 1
GROUP BY
p.STORE_ID
ORDER BY
PEER_COUNT DESC;
次に、書き込みロードを再度操作します。
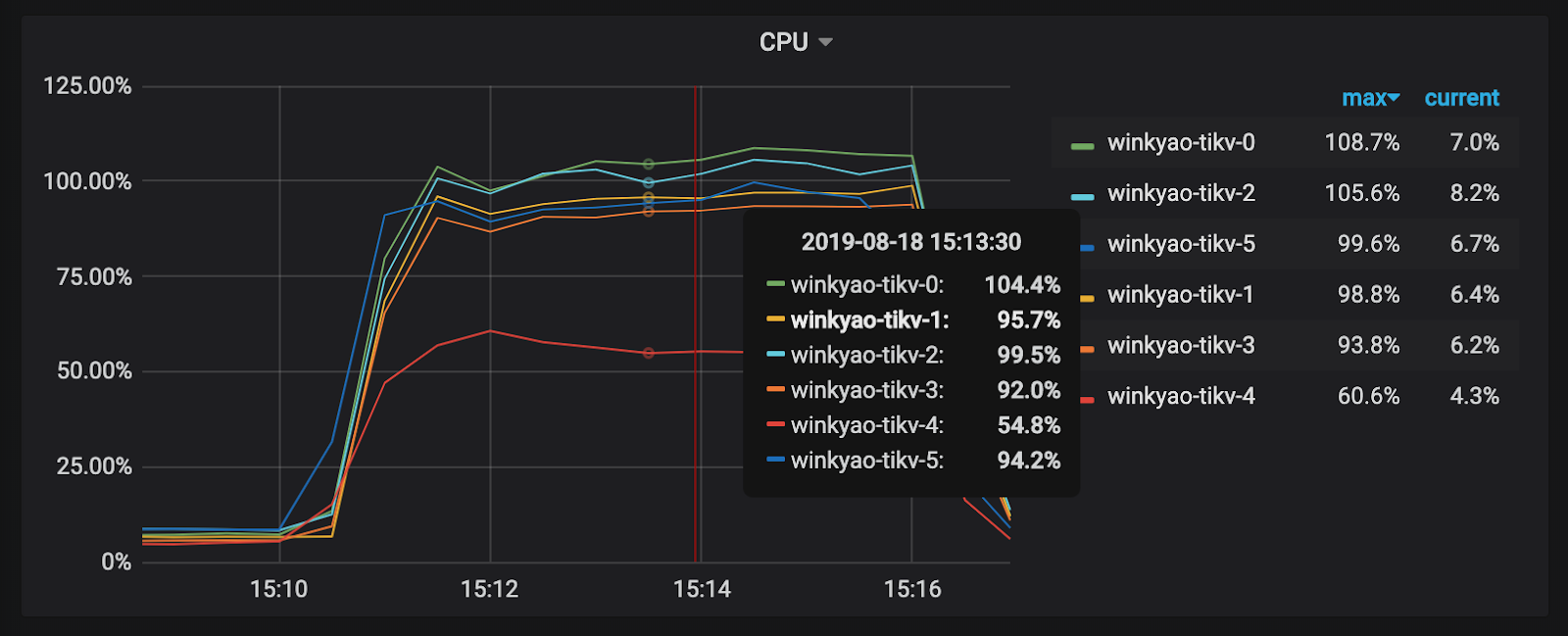
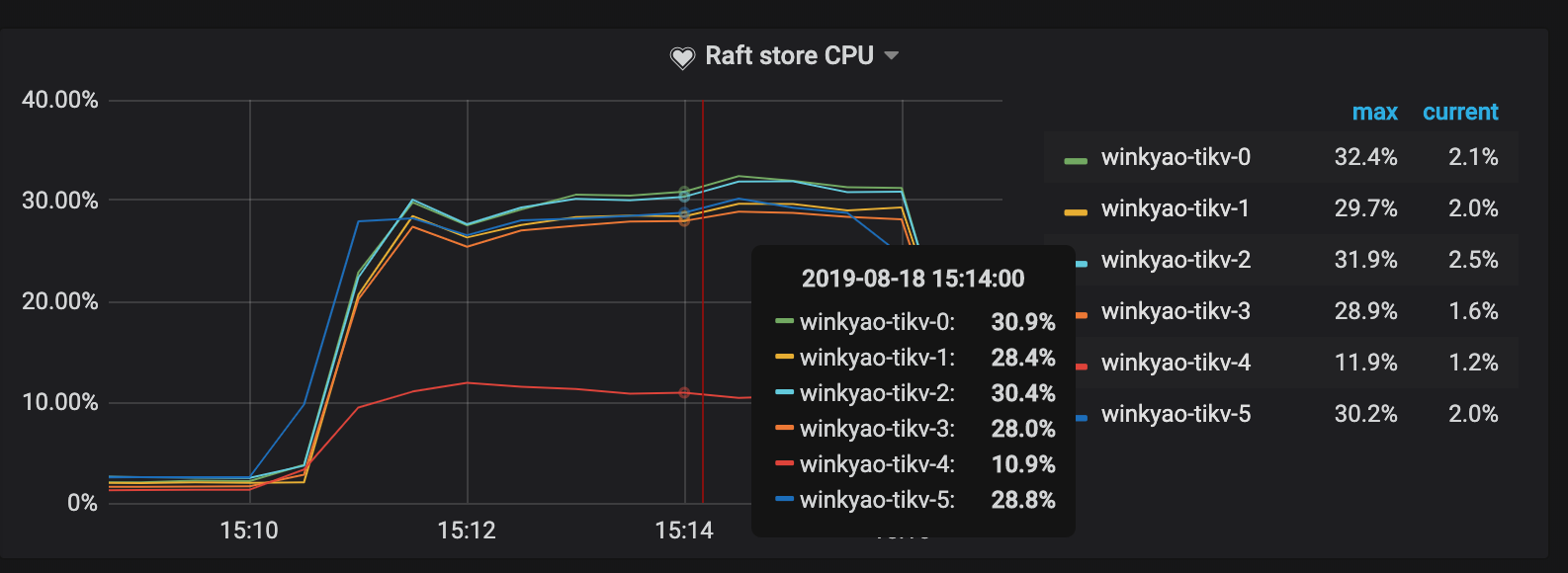
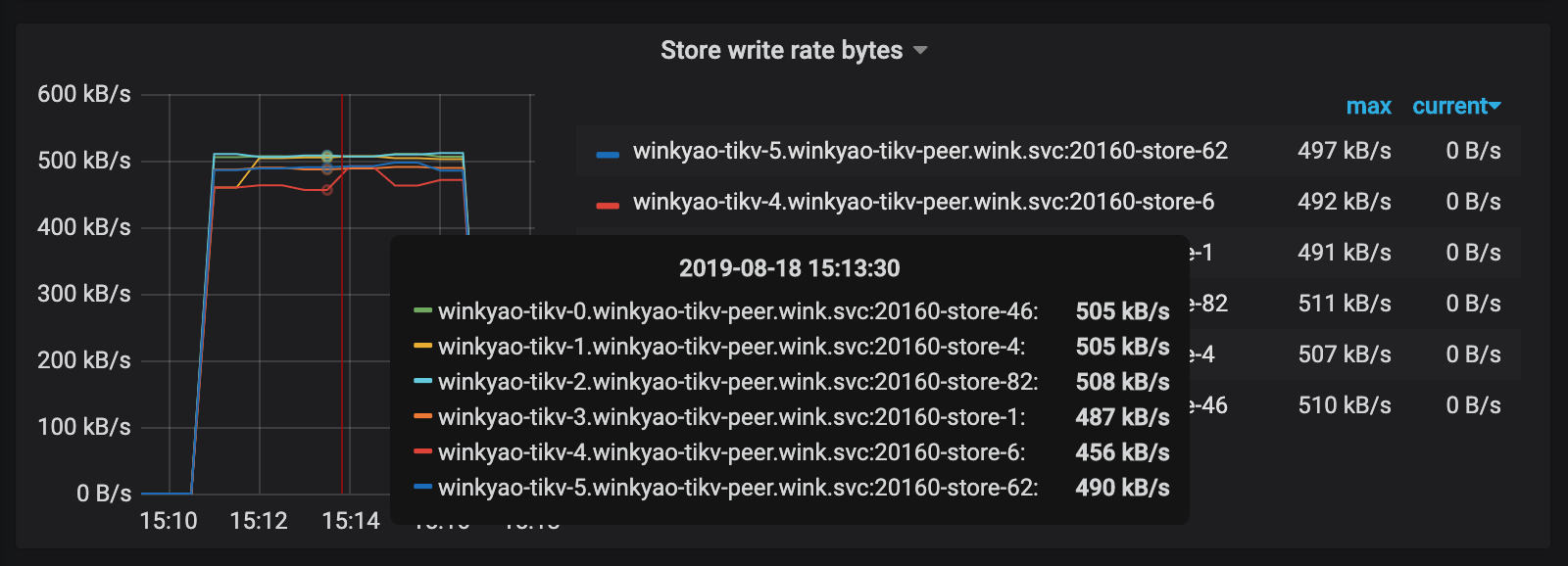
明らかなホットスポットの問題が解決されたことがわかります。
この場合、テーブルは単純です。他の場合では、インデックスのホットスポットの問題も考慮する必要があります。インデックスリージョンを事前に分割する方法の詳細については、 分割リージョンを参照してください。
複雑なホットスポットの問題
問題 1:
テーブルに主キーがない場合、または主キーがInt型ではなく、ランダムに分散された主キー ID を生成したくない場合、TiDB は行 ID として暗黙の_tidb_rowid列を提供します。一般に、 SHARD_ROW_ID_BITSパラメーターを使用しない場合、 _tidb_rowid列の値も単調に増加するため、ホットスポットも発生する可能性があります。詳細については、 SHARD_ROW_ID_BITSを参照してください。
この状況でホットスポットの問題を回避するには、テーブルを作成するときにSHARD_ROW_ID_BITSとPRE_SPLIT_REGIONSを使用できます。 PRE_SPLIT_REGIONSの詳細については、 分割前のリージョンを参照してください。
SHARD_ROW_ID_BITSは、 _tidb_rowid列で生成された行 ID をランダムに分散させるために使用されます。 PRE_SPLIT_REGIONSは、テーブルの作成後にリージョンを事前に分割するために使用されます。
ノート:
PRE_SPLIT_REGIONSの値はSHARD_ROW_ID_BITSの値以下でなければなりません。
例:
create table t (a int, b int) SHARD_ROW_ID_BITS = 4 PRE_SPLIT_REGIONS=3;
SHARD_ROW_ID_BITS = 4は、tidb_rowidの値が 16 (16=2^4) の範囲にランダムに分散されることを意味します。PRE_SPLIT_REGIONS=3は、テーブルが作成後に 8 (2^3) のリージョンに事前に分割されることを意味します。
テーブルtへのデータの書き込みが開始されると、データは事前に分割された 8 つのリージョンに書き込まれます。これにより、テーブルの作成後にリージョンが 1 つしか存在しない場合に発生する可能性のあるホットスポットの問題が回避されます。
ノート:
tidb_scatter_regionグローバル変数はPRE_SPLIT_REGIONSの動作に影響します。この変数は、テーブルの作成後に結果を返す前に、領域が事前に分割および分散されるのを待つかどうかを制御します。テーブルの作成後に集中的な書き込みがある場合は、この変数の値を
1に設定する必要があります。そうすると、すべてのリージョンが分割され分散されるまで、TiDB はクライアントに結果を返しません。そうしないと、TiDB は分散が完了する前にデータを書き込むため、書き込みパフォーマンスに大きな影響を与えます。
問題 2:
テーブルの主キーが整数型で、テーブルが主キーの一意性を保証するためにAUTO_INCREMENTを使用している場合 (連続または増分である必要はありません)、 SHARD_ROW_ID_BITSを使用してこのテーブルのホットスポットを分散させることはできません。これは、TiDB が行の値を直接使用するためです。主キーの_tidb_rowid 。
このシナリオの問題に対処するには、データを挿入するときにAUTO_INCREMENTをAUTO_RANDOM (列属性) に置き換えることができます。次に、TiDB は自動的に値を整数の主キー列に割り当てます。これにより、行 ID の連続性がなくなり、ホットスポットが分散されます。
パラメータ構成
v2.1 では、TiDB にラッチ機構が導入され、書き込みの競合が頻繁に発生するシナリオでトランザクションの競合を事前に特定します。目的は、書き込みの競合によって発生する TiDB および TiKV でのトランザクション コミットの再試行を減らすことです。通常、バッチ タスクは TiDB に既に格納されているデータを使用するため、トランザクションの書き込み競合は発生しません。この状況では、TiDB のラッチを無効にして、小さなオブジェクトのメモリ割り当てを減らすことができます。
[txn-local-latches]
enabled = false