1 つの都市に展開された 2 つのデータ センター
このドキュメントでは、アーキテクチャ、構成、この展開モードを有効にする方法、およびこのモードでレプリカを使用する方法など、1 つの都市にある 2 つのデータ センター (DC) の展開モードを紹介します。
オンプレミス環境では、TiDB は通常、マルチデータセンター展開ソリューションを採用して、高可用性と災害復旧機能を確保します。マルチデータセンター展開ソリューションには、2 つの都市にある 3 つのデータセンターや 1 つの都市にある 3 つのデータセンターなど、複数の展開モードが含まれます。このドキュメントでは、1 つの都市にある 2 つのデータ センターの展開モードを紹介します。このモードで展開された TiDB は、低コストで高可用性と災害復旧の要件を満たすこともできます。この展開ソリューションは、データ レプリケーション自動同期モードまたは DR 自動同期モードを採用しています。
1 つの都市に 2 つのデータ センターがあるモードでは、2 つのデータ センターの距離は 50 km 未満です。それらは通常、同じ都市または隣接する 2 つの都市にあります。 2 つのデータ センター間のネットワークレイテンシーは 1.5 ミリ秒未満であり、帯域幅は 10 Gbps を超えています。
導入アーキテクチャ
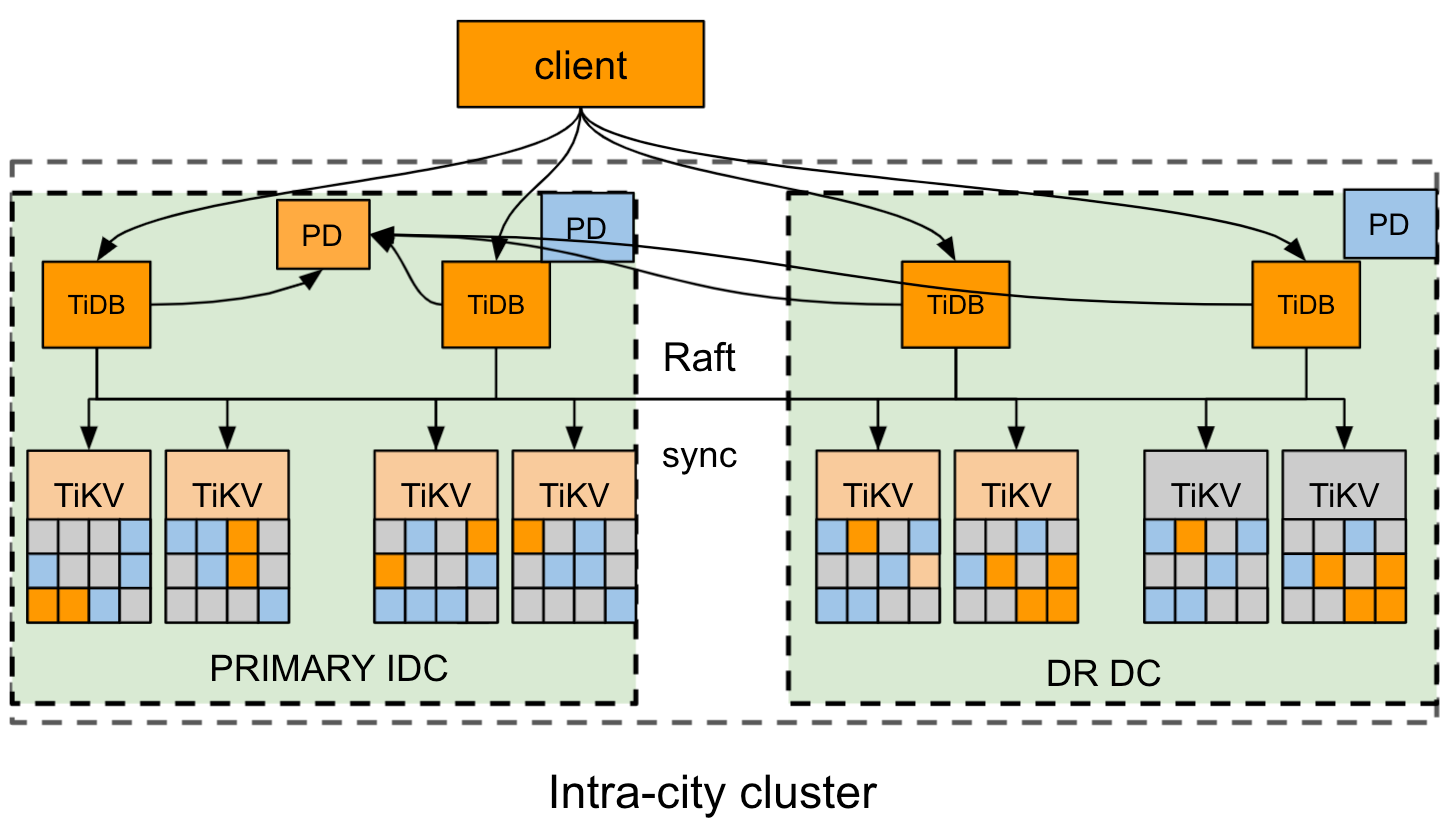
このセクションでは、2 つのデータ センター IDC1 と IDC2 がそれぞれ東と西にある都市の例を取り上げます。
クラスタ展開のアーキテクチャは次のとおりです。
- TiDB クラスターは、1 つの都市の 2 つの DC に展開されます。東部のプライマリ IDC1 と西部の災害復旧 (DR) IDC2 です。
- クラスターには 4 つのレプリカがあります。IDC1 に 2 つの投票者レプリカ、IDC2 に 1 つの投票者レプリカ、1 つの学習者レプリカです。 TiKV コンポーネントの場合、各ラックには適切なラベルが付いています。
- Raftプロトコルは、データの一貫性と高可用性を確保するために採用されており、ユーザーに対して透過的です。
この展開ソリューションは、TiKV のレプリケーション モードを制限するクラスターのレプリケーション ステータスを制御および識別するために 3 つのステータスを定義します。クラスタのレプリケーション モードは、3 つのステータス間で自動的かつ適応的に切り替えることができます。詳細は、 ステータススイッチ節を参照してください。
- sync : 同期レプリケーション モード。このモードでは、ディザスター リカバリー (DR) データ センター内の少なくとも 1 つのレプリカがプライマリ データ センターと同期します。 Raftアルゴリズムは、各ログがラベルに基づいて DR に複製されることを保証します。
- async : 非同期レプリケーション モード。このモードでは、DR データ センターはプライマリ データ センターと完全には同期されません。 Raftアルゴリズムは多数決プロトコルに従ってログを複製します。
- sync-recover : 同期回復モード。このモードでは、DR データ センターはプライマリ データ センターと完全には同期されません。 Raftは徐々にラベル複製モードに切り替え、ラベル情報を PD に報告します。
Configuration / コンフィグレーション
例
次のtiup topology.yamlのサンプル ファイルは、1 つの都市展開モードでの 2 つのデータ センターの一般的なトポロジ構成です。
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/data/tidb_cluster/tidb-deploy"
data_dir: "/data/tidb_cluster/tidb-data"
server_configs:
pd:
replication.location-labels: ["zone","rack","host"]
pd_servers:
- host: 10.63.10.10
name: "pd-10"
- host: 10.63.10.11
name: "pd-11"
- host: 10.63.10.12
name: "pd-12"
tidb_servers:
- host: 10.63.10.10
- host: 10.63.10.11
- host: 10.63.10.12
tikv_servers:
- host: 10.63.10.30
config:
server.labels: { zone: "east", rack: "east-1", host: "30" }
- host: 10.63.10.31
config:
server.labels: { zone: "east", rack: "east-2", host: "31" }
- host: 10.63.10.32
config:
server.labels: { zone: "west", rack: "west-1", host: "32" }
- host: 10.63.10.33
config:
server.labels: { zone: "west", rack: "west-2", host: "33" }
monitoring_servers:
- host: 10.63.10.60
grafana_servers:
- host: 10.63.10.60
alertmanager_servers:
- host: 10.63.10.60
配置ルール
計画されたトポロジーに基づいてクラスターをデプロイするには、 配置ルールを使用してクラスターのレプリカの場所を決定する必要があります。 4 つのレプリカ (2 つの投票者レプリカがプライマリ センターにあり、1 つの投票者レプリカと 1 つの学習者レプリカが DR センターにあります) の展開を例にとると、配置ルールを使用して次のようにレプリカを構成できます。
cat rule.json
[
{
"group_id": "pd",
"group_index": 0,
"group_override": false,
"rules": [
{
"group_id": "pd",
"id": "zone-east",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 2,
"label_constraints": [
{
"key": "zone",
"op": "in",
"values": [
"east"
]
}
],
"location_labels": [
"zone",
"rack",
"host"
]
},
{
"group_id": "pd",
"id": "zone-west",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 1,
"label_constraints": [
{
"key": "zone",
"op": "in",
"values": [
"west"
]
}
],
"location_labels": [
"zone",
"rack",
"host"
]
},
{
"group_id": "pd",
"id": "zone-west",
"start_key": "",
"end_key": "",
"role": "learner",
"count": 1,
"label_constraints": [
{
"key": "zone",
"op": "in",
"values": [
"west"
]
}
],
"location_labels": [
"zone",
"rack",
"host"
]
}
]
}
]
rule.jsonの構成を使用するには、次のコマンドを実行して既存の構成をdefault.jsonファイルにバックアップし、既存の構成をrule.jsonで上書きします。
pd-ctl config placement-rules rule-bundle load --out="default.json"
pd-ctl config placement-rules rule-bundle save --in="rule.json"
以前の構成にロールバックする必要がある場合は、バックアップ ファイルdefault.jsonを復元するか、次の JSON ファイルを手動で書き込んで、現在の構成をこの JSON ファイルで上書きすることができます。
cat default.json
[
{
"group_id": "pd",
"group_index": 0,
"group_override": false,
"rules": [
{
"group_id": "pd",
"id": "default",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 3
}
]
}
]
DR 自動同期モードを有効にする
複製モードは PD によって制御されます。次のいずれかの方法を使用して、PD 構成ファイルでレプリケーション モードを構成できます。
- 方法 1: PD 構成ファイルを構成してから、クラスターをデプロイします。
```toml
[replication-mode]
replication-mode = "dr-auto-sync"
[replication-mode.dr-auto-sync]
label-key = "zone"
primary = "east"
dr = "west"
primary-replicas = 2
dr-replicas = 1
wait-store-timeout = "1m"
wait-sync-timeout = "1m"
```
- 方法 2: クラスターをデプロイした場合は、pd-ctl コマンドを使用して PD の構成を変更します。
```shell
config set replication-mode dr-auto-sync
config set replication-mode dr-auto-sync label-key zone
config set replication-mode dr-auto-sync primary east
config set replication-mode dr-auto-sync dr west
config set replication-mode dr-auto-sync primary-replicas 2
config set replication-mode dr-auto-sync dr-replicas 1
```
構成項目の説明:
replication-modeは有効にする複製モードです。上記の例では、dr-auto-syncに設定されています。デフォルトでは、マジョリティ プロトコルが使用されます。label-keyは、異なるデータ センターを区別するために使用され、配置ルールに一致する必要があります。この例では、プライマリ データ センターは「東」、DR データ センターは「西」です。primary-replicasは、プライマリ データ センター内の Voter レプリカの数です。dr-replicasは、DR データ センター内の Voter レプリカの数です。wait-store-timeoutは、ネットワークの分離または障害が発生したときに、非同期レプリケーション モードに切り替えるための待機時間です。ネットワーク障害の時間が待機時間を超えると、非同期レプリケーション モードが有効になります。デフォルトの待機時間は 60 秒です。
クラスターの現在のレプリケーション ステータスを確認するには、次の API を使用します。
curl http://pd_ip:pd_port/pd/api/v1/replication_mode/status
{
"mode": "dr-auto-sync",
"dr-auto-sync": {
"label-key": "zone",
"state": "sync"
}
}
ステータススイッチ
クラスタのレプリケーション モードは、次の 3 つのステータス間で自動的かつ適応的に切り替えることができます。
- クラスターが正常な場合、同期レプリケーション モードが有効になり、災害復旧データ センターのデータ整合性が最大化されます。
- 2 つのデータセンター間のネットワーク接続に障害が発生した場合、または DR データセンターが故障した場合、事前に設定された保護間隔の後、クラスターは非同期レプリケーション モードを有効にして、アプリケーションの可用性を確保します。
- ネットワークが再接続されるか、DR データセンターが復旧すると、TiKV ノードは再びクラスターに参加し、徐々にデータを複製します。最後に、クラスターは同期レプリケーション モードに切り替わります。
ステータススイッチの詳細は次のとおりです。
初期化: 初期化段階では、クラスターは同期レプリケーション モードになっています。 PD はステータス情報を TiKV に送信し、すべての TiKV ノードは同期レプリケーション モードに厳密に従って動作します。
同期から非同期への切り替え : PD は TiKV のハートビート情報を定期的にチェックして、TiKV ノードが故障しているか、切断されているかを判断します。障害ノードの数がプライマリ データ センター (
primary-replicas) および DR データ センター (dr-replicas) のレプリカの数を超える場合、同期レプリケーション モードはデータ レプリケーションを提供できなくなり、ステータスを切り替える必要があります。障害または切断時間がwait-store-timeoutで設定された時間を超えると、PD はクラスターのステータスを非同期モードに切り替えます。その後、PD は非同期のステータスをすべての TiKV ノードに送信し、TiKV のレプリケーション モードは 2 センター レプリケーションからネイティブRaftマジョリティに切り替わります。async から sync への切り替え : PD は TiKV のハートビート情報を定期的にチェックして、TiKV ノードが再接続されているかどうかを判断します。障害が発生したノードの数が、プライマリ データ センターのレプリカの数 (
primary-replicas) と DR データ センターのレプリカの数 (dr-replicas) よりも少ない場合は、同期レプリケーション モードを再び有効にすることができます。 PD は、最初にクラスターのステータスを同期回復に切り替え、ステータス情報をすべての TiKV ノードに送信します。 TiKV のすべてのリージョンは、2 つのデータセンターの同期レプリケーション モードに徐々に切り替わり、ハートビート情報を PD に報告します。 PD は TiKV リージョンのステータスを記録し、復旧の進行状況を計算します。すべての TiKV リージョンが切り替えを完了すると、PD はレプリケーション モードを同期に切り替えます。
災害からの回復
このセクションでは、1 つの都市に配置された 2 つのデータ センターのディザスタ リカバリ ソリューションを紹介します。
同期レプリケーション モードのクラスタに障害が発生した場合、次のRPO = 0を使用してデータ リカバリを実行できます。
プライマリ データ センターに障害が発生し、Voter レプリカのほとんどが失われ、完全なデータが DR データ センターに存在する場合、失われたデータは DR データ センターから回復できます。現時点では、プロのツールを使用して手動で介入する必要があります。回復ソリューションについては、TiDB チームにお問い合わせください。
DR センターに障害が発生し、いくつかの Voter レプリカが失われた場合、クラスターは自動的に非同期レプリケーション モードに切り替わります。
同期レプリケーションモードではないクラスタに障害が発生し、 RPO = 0でデータリカバリを実行できない場合:
- 投票者のレプリカのほとんどが失われた場合は、専門的なツールを使用して手動で介入する必要があります。回復ソリューションについては、TiDB チームにお問い合わせください。