TiDBLightningを使用してデータを並行してインポートする
v5.3.0以降、TiDB Lightningのローカルバックエンドモードは、単一のテーブルまたは複数のテーブルの並列インポートをサポートします。複数のTiDBLightningインスタンスを同時に実行することにより、異なる単一のテーブルまたは複数のテーブルからデータを並行してインポートできます。このように、TiDB Lightningは水平方向にスケーリングする機能を提供し、大量のデータのインポートに必要な時間を大幅に短縮できます。
技術的な実装では、TiDB Lightningは、各インスタンスのメタデータとインポートされた各テーブルのデータをターゲットTiDBに記録し、さまざまなインスタンスの行ID割り当て範囲、グローバルチェックサムの記録、およびTiKVの構成変更とリカバリを調整します。およびPD。
次のシナリオでは、TiDBLightningを使用してデータを並行してインポートできます。
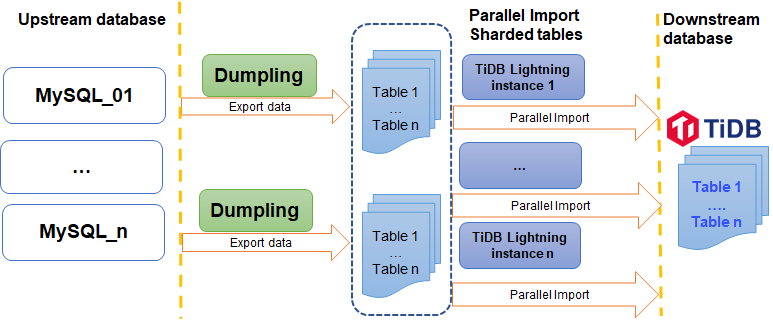
- シャーディングされたスキーマとシャーディングされたテーブルをインポートします。このシナリオでは、複数のアップストリームデータベースインスタンスからの複数のテーブルが、異なるTiDBLightningインスタンスによって並列にダウンストリームTiDBデータベースにインポートされます。
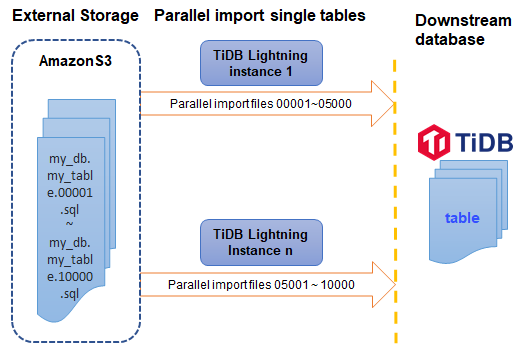
- 単一のテーブルを並行してインポートします。このシナリオでは、特定のディレクトリまたはクラウドストレージ(Amazon S3など)に保存されている単一のテーブルが、異なるTiDBLightningインスタンスによって並列にダウンストリームTiDBクラスタにインポートされます。これは、TiDB5.3.0で導入された新機能です。
ノート:
並列インポートは、TiDBで初期化された空のテーブルのみをサポートし、既存のサービスによって書き込まれたデータを含むテーブルへのデータの移行をサポートしません。そうしないと、データの不整合が発生する可能性があります。
並列インポートは通常、ローカルバックエンドモードで使用されます。
複数のTiDBLightningインスタンスを使用して同じターゲットにデータをインポートする場合は、一度に1つのバックエンドのみを適用してください。たとえば、ローカルバックエンドモードとTiDBバックエンドモードの両方で同時にデータを同じTiDBクラスタにインポートすることはできません。
次の図は、シャーディングされたスキーマとシャーディングされたテーブルのインポートがどのように機能するかを示しています。このシナリオでは、複数のTiDB Lightningインスタンスを使用して、MySQLシャードテーブルをダウンストリームTiDBクラスタにインポートできます。
次の図は、単一のテーブルのインポートがどのように機能するかを示しています。このシナリオでは、複数のTiDB Lightningインスタンスを使用して、単一のテーブルからデータを分割し、それをダウンストリームのTiDBクラスタに並行してインポートできます。
考慮事項
TiDB Lightningを使用した並列インポートには、追加の構成は必要ありません。 TiDB Lightningが起動すると、ダウンストリームのTiDBクラスタにメタデータが登録され、同時にターゲットクラスタにデータを移行する他のインスタンスがあるかどうかが自動的に検出されます。存在する場合は、自動的に並列インポートモードになります。
ただし、データを並行して移行する場合は、次の点を考慮する必要があります。
- 複数のシャードテーブル間での主キーまたは一意のインデックス間の競合を処理します
- インポートパフォーマンスを最適化する
主キーまたは一意のインデックス間の競合を処理する
ローカルバックエンドモードを使用して並行してインポートする場合は、データソース間、およびターゲットTiDBクラスタのテーブル間で主キーまたは一意のインデックスの競合がないことを確認する必要があります。インポート中にターゲットテーブルにデータ書き込みがないことを確認してください。そうしないと、TiDB Lightningはインポートされたデータの正確性を保証できず、インポートの完了後にターゲットテーブルに一貫性のないインデックスが含まれます。
インポートパフォーマンスを最適化する
TiDB Lightningは、生成されたKey-Valueデータを対応するリージョンの各コピーが配置されているTiKVノードにアップロードする必要があるため、インポート速度はターゲットクラスタのサイズによって制限されます。ターゲットTiDBクラスタのTiKVインスタンスの数とTiDBLightningインスタンスの数がn:1(nはリージョンのコピーの数)より大きいことを確認することをお勧めします。同時に、最適なインポートパフォーマンスを実現するには、次の要件を満たす必要があります。
- 各TiDBLightningインスタンスを専用マシンにデプロイします。 1つのTiDBLightningインスタンスがデフォルトですべてのCPUリソースを消費するため、単一のマシンに複数のインスタンスをデプロイしてもパフォーマンスを向上させることはできません。
- 並列インポートを実行する各TiDBLightningインスタンスのソースファイルの合計サイズは、5TiB未満である必要があります
- TiDBLightningインスタンスの総数は10未満である必要があります。
TiDB Lightningを使用して共有データベースとテーブルを並行してインポートする場合は、データの量に応じて適切な数のTiDBLightningインスタンスを選択してください。
- MySQLデータボリュームが2TiB未満の場合、並列インポートに1つのTiDBLightningインスタンスを使用できます。
- MySQLデータボリュームが2TiBを超え、MySQLインスタンスの総数が10未満の場合は、MySQLインスタンスごとに1つのTiDB Lightningインスタンスを使用することをお勧めします。また、並列TiDBLightningインスタンスの数は10を超えないようにする必要があります。
- MySQLデータボリュームが2TiBを超え、MySQLインスタンスの総数が10を超える場合、これらのMySQLインスタンスによってエクスポートされたデータをインポートするために5〜10個のTiDBLightningインスタンスを割り当てることをお勧めします。
次に、このドキュメントでは2つの例を使用して、さまざまなシナリオでの並列インポートの操作手順を詳しく説明します。
- 例1: Dumpling + TiDB Lightningを使用して、シャーディングされたデータベースとテーブルをTiDBに並行してインポートします
- 例2:単一のテーブルを並行してインポートする
制限
TiDB Lightningは、実行時に一部のリソースを排他的に使用します。複数のTiDBLightningインスタンスを単一のマシン(実稼働環境では推奨されません)または複数のマシンで共有されるディスクにデプロイする必要がある場合は、次の使用制限に注意してください。
- 各TiDBLightningインスタンスの一意のパスに
tikv-importer.sorted-kv-dirを設定します。同じパスを共有する複数のインスタンスは、意図しない動作を引き起こし、インポートの失敗やデータエラーを引き起こす可能性があります。 - 各TiDBLightningチェックポイントを個別に保存します。チェックポイント構成の詳細については、 TiDBLightningチェックポイントを参照してください。
- checkpoint.driver = "file"(デフォルト)を設定する場合は、チェックポイントへのパスがインスタンスごとに一意であることを確認してください。
- checkpoint.driver = "mysql"を設定する場合は、インスタンスごとに一意のスキーマを設定する必要があります。
- 各TiDBLightningのログファイルは一意のパスに設定する必要があります。同じログファイルを共有すると、ログのクエリとトラブルシューティングに影響します。
- WebインターフェイスまたはDebugAPIを使用する場合は、インスタンスごとに
lightning.status-addrを一意のアドレスに設定する必要があります。そうしないと、ポートの競合が原因でTiDBLightningプロセスを開始できません。
例1: Dumpling + TiDB Lightningを使用して、シャーディングされたデータベースとテーブルをTiDBに並行してインポートする
この例では、アップストリームが10個のシャードテーブルを持つMySQLクラスタであり、合計サイズが10TiBであると想定しています。 5つのTiDBLightningインスタンスを使用して並列インポートを実行でき、各インスタンスは2つのTiBをインポートします。総輸入時間(Dumplingの輸出にかかる時間を除く)は、約40時間から約10時間に短縮できると見込まれます。
アップストリームライブラリの名前がmy_dbで、各シャーディングテーブルの名前がmy_table_01であると想定しmy_table_10 。それらをマージして、ダウンストリームmy_db.my_tableテーブルにインポートします。特定の手順については、次のセクションで説明します。
ステップ1:Dumplingを使用してデータをエクスポートする
TiDBLightningがデプロイされている5つのノードに2つのシャードテーブルをエクスポートします。
- 2つのシャードテーブルが同じMySQLインスタンスにある場合は、 Dumplingの
--filterパラメーターを使用してそれらを直接エクスポートできます。 TiDB Lightningを使用してインポートする場合、 Dumplingがデータをエクスポートするディレクトリとしてdata-source-dirを指定できます。 - 2つのシャードテーブルのデータが異なるMySQLノードに分散されている場合は、 Dumplingを使用してそれらを個別にエクスポートする必要があります。エクスポートされたデータは、同じ親ディレクトリに配置する必要がありますが、サブディレクトリは異なります。 TiDB Lightningを使用して並列インポートを実行する場合、親ディレクトリとして
data-source-dirを指定する必要があります。
Dumplingを使用してデータをエクスポートする方法の詳細については、 Dumplingを参照してください。
手順2:TiDBLightningデータソースを構成する
構成ファイルtidb-lightning.tomlを作成してから、次のコンテンツを追加します。
[lightning]
status-addr = ":8289"
[mydumper]
# Specify the path for Dumpling to export data. If Dumpling performs several times and the data belongs to different directories, you can place all the exported data in the same parent directory and specify this parent directory here.
data-source-dir = "/path/to/source-dir"
[tikv-importer]
# Whether to allow importing data to tables with data. The default value is `false`.
# When you use parallel import mode, you must set it to `true`, because multiple TiDB Lightning instances are importing the same table at the same time.
incremental-import = true
# "local": The default mode. It applies to large dataset import, for example, greater than 1 TiB. However, during the import, downstream TiDB is not available to provide services.
# "tidb": You can use this mode for small dataset import, for example, smaller than 1 TiB. During the import, downstream TiDB is available to provide services.
backend = "local"
# Specify the path for local sorting data.
sorted-kv-dir = "/path/to/sorted-dir"
# Specify the routes for shard schemas and tables.
[[routes]]
schema-pattern = "my_db"
table-pattern = "my_table_*"
target-schema = "my_db"
target-table = "my_table"
データソースがAmazonS3やGCSなどの外部ストレージに保存されている場合は、 外部ストレージを参照してください。
ステップ3:TiDBLightningを起動してデータをインポートする
並列インポート中、各TiDB Lightningノードのサーバー構成要件は、非並列インポートモードと同じです。各TiDBLightningノードは同じリソースを消費する必要があります。それらを別のサーバーに展開することをお勧めします。展開手順の詳細については、 TiDBLightningをデプロイを参照してください。
各サーバーでTiDBLightningを順番に起動します。 nohupを使用してコマンドラインから直接起動すると、SIGHUP信号が原因で終了する場合があります。したがって、スクリプトにnohupを含めることをお勧めします。次に例を示します。
# !/bin/bash
nohup tiup tidb-lightning -config tidb-lightning.toml > nohup.out &
並列インポート中、TiDB Lightningは、タスクの開始後に次のチェックを自動的に実行します。
- ローカルディスク(
sort-kv-dir構成で制御)およびTiKVクラスタにデータをインポートするための十分なスペースがあるかどうかを確認します。 TiDB Lightningはデータソースをサンプリングし、サンプル結果からインデックスサイズのパーセンテージを推定します。見積もりにはインデックスが含まれているため、ソースデータのサイズがローカルディスクの使用可能なスペースよりも小さい場合でも、チェックが失敗する場合があります。 - TiKVクラスタの領域が均等に分散されているかどうか、および空の領域が多すぎるかどうかを確認します。空の領域の数がmax(1000、テーブルの数* 3)を超える場合、つまり「1000」または「テーブルの数の3倍」の大きい方よりも多い場合、インポートは実行できません。
- データがデータソースから順番にインポートされているかどうかを確認します。
mydumper.batch-sizeのサイズは、チェックの結果に基づいて自動的に調整されます。したがって、mydumper.batch-sizeの構成は使用できなくなります。
チェックをオフにして、 lightning.check-requirements構成で強制インポートを実行することもできます。詳細なチェックについては、 TiDBLightningの事前チェックを参照してください。
ステップ4:インポートの進行状況を確認する
インポートを開始した後、次のいずれかの方法で進行状況を確認できます。
grepログキーワードprogressで進捗状況を確認します。デフォルトでは5分ごとに更新されます。- 監視コンソールで進行状況を確認します。詳細については、 TiDB Lightning Monitoringを参照してください。
すべてのTiDBLightningインスタンスが終了するのを待ってから、インポート全体が完了します。
例2:単一のテーブルを並行してインポートする
TiDB Lightningは、単一テーブルの並列インポートもサポートしています。たとえば、AmazonS3に異なるTiDBLightningインスタンスによって保存されている複数の単一テーブルをダウンストリームTiDBクラスタに並行してインポートします。この方法により、全体的なインポート速度を上げることができます。外部ストレージの詳細については、 外部ストレージ )を参照してください。
ノート:
ローカル環境では、 Dumplingの
--filesizeまたは--whereパラメーターを使用して、単一のテーブルのデータを異なる部分に分割し、事前に複数のサーバーのローカルディスクにエクスポートできます。このようにして、引き続き並列インポートを実行できます。構成は例1と同じです。
ソースファイルがmy_db.my_table.10000.sql my_db.my_table.00001.sql 、合計10,000のSQLファイルです。 2つのTiDBLightningインスタンスを使用してインポートを高速化する場合は、構成ファイルに次の設定を追加する必要があります。
[[mydumper.files]]
# the db schema file
pattern = '(?i)^(?:[^/]*/)*my_db-schema-create\.sql'
schema = "my_db"
type = "schema-schema"
[[mydumper.files]]
# the table schema file
pattern = '(?i)^(?:[^/]*/)*my_db\.my_table-schema\.sql'
schema = "my_db"
table = "my_table"
type = "table-schema"
[[mydumper.files]]
# Only import 00001~05000 and ignore other files
pattern = '(?i)^(?:[^/]*/)*my_db\.my_table\.(0[0-4][0-9][0-9][0-9]|05000)\.sql'
schema = "my_db"
table = "my_table"
type = "sql"
他のインスタンスの構成を変更して、 05001 ~ 10000のデータファイルのみをインポートすることができます。
その他の手順については、例1の関連する手順を参照してください。
エラーを処理する
一部のTiDBLightningノードが異常終了します
並列インポート中に1つ以上のTiDBLightningノードが異常終了した場合は、ログに記録されたエラーに基づいて原因を特定し、エラーの種類に従ってエラーを処理します。
エラーが正常な終了(たとえば、killコマンドに応答した終了)またはOOMによるオペレーティングシステムによる終了を示している場合は、構成を調整してから、TiDBLightningノードを再起動します。
エラーがデータの精度に影響を与えない場合(ネットワークタイムアウトなど)、失敗したすべてのノードでtidb-lightning-ctlを使用して
checkpoint-error-ignoreを実行し、チェックポイントソースデータのエラーをクリーンアップします。次に、これらのノードを再起動して、チェックポイントからのデータのインポートを続行します。詳細については、 チェックポイント-エラー-無視を参照してください。ログがデータの不正確さをもたらすエラーを報告する場合、たとえば、チェックサムの不一致(ソースファイル内の無効なデータを示す)の場合は、失敗したすべてのノードでtidb-lightning-ctlを使用して
checkpoint-error-destroyを実行し、失敗したテーブルにインポートされたデータとチェックポイントソースデータ。詳細については、 チェックポイント-エラー-破棄を参照してください。このコマンドは、障害が発生したテーブルにインポートされたデータをダウンストリームで削除します。したがって、filtersパラメーターを使用して、すべてのTiDB Lightningノード(正常に終了するノードを含む)で障害が発生したテーブルのデータを再構成してインポートする必要があります。
インポート中に、「ターゲットテーブルがチェックサムを計算しています。チェックサムが終了するまで待ってから再試行してください」というエラーが報告されます。
一部の並列インポートには、多数のテーブルまたは少量のデータを含むテーブルが含まれます。この場合、1つ以上のタスクがテーブルの処理を開始する前に、このテーブルの他のタスクが終了し、データのチェックサムが進行中である可能性があります。このとき、エラーTarget table is calculating checksum. Please wait until the checksum is finished and try againが報告されます。この場合、チェックサムの完了を待ってから、失敗したタスクを再開できます。エラーは消え、データの精度は影響を受けません。