TiDBLightningチュートリアル
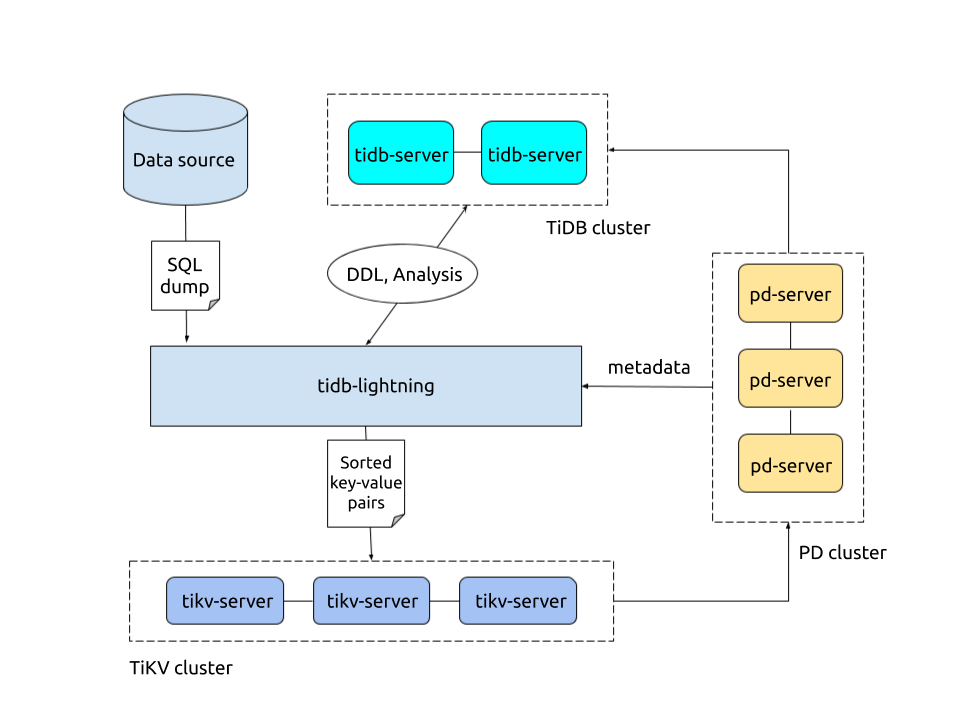
TiDB Lightningは、大量のデータをTiDBクラスタに高速に完全にインポートするために使用されるツールです。現在、TiDB Lightningは、SQLまたはCSVデータソースを介してエクスポートされたSQLダンプの読み取りをサポートしています。次の2つのシナリオで使用できます。
- 大量の新しいデータをすばやくインポートする
- すべてのデータをバックアップおよび復元する
前提条件
このチュートリアルでは、いくつかの新しくクリーンなCentOS7インスタンスを使用することを前提としています。 VMware、VirtualBox、またはその他のツールを使用して、仮想マシンをローカルに展開したり、ベンダー提供のプラットフォームに小さなクラウド仮想マシンを展開したりできます。 TiDB Lightningは大量のコンピュータリソースを消費するため、最高のパフォーマンスで実行するには、少なくとも16GBのメモリと32コアのCPUを割り当てることをお勧めします。
完全バックアップデータを準備する
まず、 dumplingを使用してMySQLからデータをエクスポートします。
./bin/dumpling -h 127.0.0.1 -P 3306 -u root -t 16 -F 256MB -B test -f 'test.t[12]' -o /data/my_database/
上記のコマンドでは:
-B test:データがtestデータベースからエクスポートされることを意味します。-f test.t[12]:test.t1つとtest.t2のテーブルのみがエクスポートされることを意味します。-t 16:データのエクスポートに16スレッドが使用されることを意味します。-F 256MB:テーブルがチャンクに分割され、1つのチャンクが256MBであることを意味します。
このコマンドを実行すると、完全バックアップデータが/data/my_databaseディレクトリにエクスポートされます。
TiDBLightningをデプロイ
ステップ1:TiDBクラスタをデプロイ
データをインポートする前に、TiDBクラスタをデプロイする必要があります。このチュートリアルでは、例としてTiDBv5.4.0を使用します。展開方法については、 TiUPを使用してTiDBクラスターをデプロイするを参照してください。
ステップ2:TiDBLightningインストールパッケージをダウンロードする
次のリンクからTiDBLightningインストールパッケージをダウンロードします。
ノート:
TiDB Lightningは、以前のバージョンのTiDBクラスターと互換性があります。 TiDBLightningインストールパッケージの最新の安定バージョンをダウンロードすることをお勧めします。
ステップ3: tidb-lightningを開始します
パッケージ内の
bin/tidb-lightningとbin/tidb-lightning-ctlを、TiDBLightningがデプロイされているサーバーにアップロードします。準備されたデータソースをサーバーにアップロードします。
tidb-lightning.tomlを次のように構成します。[lightning] # Logging level = "info" file = "tidb-lightning.log" [tikv-importer] # Uses the Local-backend backend = "local" # Sets the directory for temporarily storing the sorted key-value pairs. # The target directory must be empty. sorted-kv-dir = "/mnt/ssd/sorted-kv-dir" [mydumper] # Local source data directory data-source-dir = "/data/my_datasource/" # Configures the wildcard rule. By default, all tables in the mysql, sys, INFORMATION_SCHEMA, PERFORMANCE_SCHEMA, METRICS_SCHEMA, and INSPECTION_SCHEMA system databases are filtered. # If this item is not configured, the "cannot find schema" error occurs when system tables are imported. filter = ['*.*', '!mysql.*', '!sys.*', '!INFORMATION_SCHEMA.*', '!PERFORMANCE_SCHEMA.*', '!METRICS_SCHEMA.*', '!INSPECTION_SCHEMA.*'] [tidb] # Information of the target cluster host = "172.16.31.2" port = 4000 user = "root" password = "rootroot" # Table schema information is fetched from TiDB via this status-port. status-port = 10080 # The PD address of the cluster pd-addr = "172.16.31.3:2379"パラメータを適切に設定した後、
nohupコマンドを使用してtidb-lightningプロセスを開始します。コマンドラインでコマンドを直接実行すると、SIGHUP信号を受信したためにプロセスが終了する場合があります。代わりに、nohupコマンドを含むbashスクリプトを実行することをお勧めします。
```sh
#!/bin/bash
nohup ./tidb-lightning -config tidb-lightning.toml > nohup.out &
```
ステップ4:データの整合性を確認する
インポートが完了すると、TiDBLightningは自動的に終了します。インポートが成功すると、ログファイルの最後の行にtidb lightning exitが表示されます。
エラーが発生した場合は、 TiDB LightningFAQを参照してください。
概要
このチュートリアルでは、TiDB Lightningとは何か、およびTiDBLightningクラスターをすばやく展開して完全バックアップデータをTiDBクラスタにインポートする方法を簡単に紹介しクラスタ。
TiDB Lightningの詳細な機能と使用法については、 TiDBLightningの概要を参照してください。