統計入門
TiDBは統計を使用してどのインデックスを選択するかを決定します。 tidb_analyze_version変数は、TiDBによって収集される統計を制御します。現在、 tidb_analyze_version = 1とtidb_analyze_version = 2の2つのバージョンの統計がサポートされています。 v5.1.0より前のバージョンでは、この変数のデフォルト値は1です。 v5.3.0以降のバージョンでは、この変数のデフォルト値は2であり、これは実験的機能として機能します。クラスタがv5.3.0より前のバージョンからv5.3.0以降にアップグレードされた場合、デフォルト値のtidb_analyze_versionは変更されません。
ノート:
tidb_analyze_version = 2の場合、ANALYZEの実行後にメモリオーバーフローが発生した場合は、tidb_analyze_version = 1を設定し、次のいずれかの操作を行う必要があります。
ANALYZEステートメントを手動で実行する場合は、分析するすべてのテーブルを手動で分析します。自動分析が有効になっているためにTiDBが
ANALYZEステートメントを自動的に実行する場合は、次のステートメントを実行してDROP STATSステートメントを生成します。
これらの2つのバージョンには、TiDBに異なる情報が含まれています。
バージョン1と比較して、バージョン2の統計は、データ量が膨大な場合にハッシュの衝突によって引き起こされる潜在的な不正確さを回避します。また、ほとんどのシナリオで推定精度を維持します。
このドキュメントでは、ヒストグラム、Count-Min Sketch、およびTop-Nを簡単に紹介し、統計の収集と保守について詳しく説明します。
ヒストグラム
ヒストグラムは、データの分布のおおよその表現です。値の全範囲を一連のバケットに分割し、単純なデータを使用して、バケットに含まれる値の数など、各バケットを記述します。 TiDBでは、各テーブルの特定の列に対して同じ深さのヒストグラムが作成されます。等深ヒストグラムを使用して、間隔クエリを推定できます。
ここで「等しい深さ」とは、各バケットに分類される値の数が可能な限り等しいことを意味します。たとえば、特定のセット{1.6、1.9、1.9、2.0、2.4、2.6、2.7、2.7、2.8、2.9、3.4、3.5}に対して、4つのバケットを生成するとします。等深ヒストグラムは次のとおりです。 4つのバケット[1.6、1.9]、[2.0、2.6]、[2.7、2.8]、[2.9、3.5]が含まれています。バケットの深さは3です。
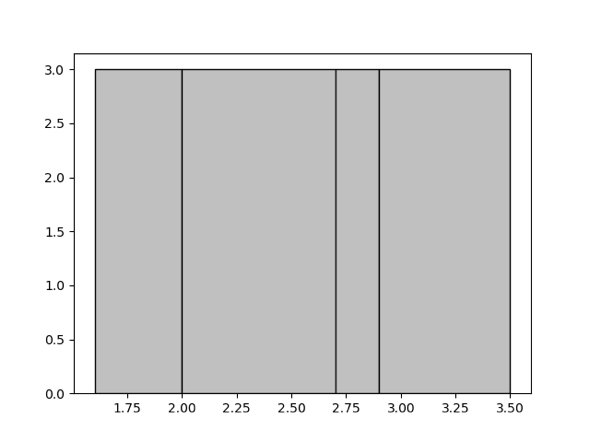
ヒストグラムバケット数の上限を決定するパラメータの詳細については、 手動コレクションを参照してください。バケットの数が多いほど、ヒストグラムの精度が高くなります。ただし、精度が高くなると、メモリリソースの使用量が犠牲になります。この数値は、実際のシナリオに応じて適切に調整できます。
カウント-最小スケッチ
Count-MinSketchはハッシュ構造です。等価クエリにa = 1つまたはINのクエリ(たとえば、 a in (1, 2, 3) )が含まれている場合、TiDBはこのデータ構造を使用して推定します。
Count-Min Sketchはハッシュ構造であるため、ハッシュの衝突が発生する可能性があります。 EXPLAINステートメントでは、同等のクエリの推定値が実際の値から大きく外れている場合、大きい値と小さい値が一緒にハッシュされていると見なすことができます。この場合、ハッシュの衝突を回避するために次のいずれかの方法をとることができます。
WITH NUM TOPNパラメーターを変更します。 TiDBは、高周波(top x)データを個別に保存し、他のデータはCount-MinSketchに保存します。したがって、大きい値と小さい値が一緒にハッシュされるのを防ぐために、WITH NUM TOPNの値を増やすことができます。 TiDBでは、デフォルト値は20です。最大値は1024です。このパラメーターの詳細については、 フルコレクションを参照してください。- 2つのパラメータ
WITH NUM CMSKETCH DEPTHとWITH NUM CMSKETCH WIDTHを変更します。どちらもハッシュバケットの数と衝突確率に影響します。実際のシナリオに従って2つのパラメーターの値を適切に増やして、ハッシュの衝突の可能性を減らすことができますが、統計のメモリ使用量が高くなります。 TiDBでは、デフォルト値のWITH NUM CMSKETCH DEPTHは5で、デフォルト値のWITH NUM CMSKETCH WIDTHは2048です。2つのパラメーターの詳細については、 フルコレクションを参照してください。
トップN値
Top-N値は、列またはインデックスの上位N個の値です。 TiDBは、Top-N値の値と発生を記録します。
統計を収集する
手動収集
ANALYZEステートメントを実行して、統計を収集できます。
ノート:
TiDBの実行時間
ANALYZE TABLEは、MySQLまたはInnoDBの実行時間よりも長くなります。 InnoDBでは、少数のページのみがサンプリングされますが、TiDBでは、包括的な統計セットが完全に再構築されます。 MySQL用に作成されたスクリプトは、ANALYZE TABLEが短期間の操作であると素朴に予想する場合があります。より迅速な分析のために、
tidb_enable_fast_analyzeから1に設定して、クイック分析機能を有効にすることができます。このパラメーターのデフォルト値は0です。クイック分析を有効にすると、TiDBは約10,000行のデータをランダムにサンプリングして統計を作成します。したがって、不均一なデータ分布や比較的少量のデータの場合、統計情報の精度は比較的低くなります。間違ったインデックスを選択するなど、実行計画が不十分になる可能性があります。通常の
ANALYZEステートメントの実行時間が許容できる場合は、クイック分析機能を無効にすることをお勧めします。
tidb_enable_fast_analyzeは実験的機能であり、現在tidb_analyze_version=2の統計情報と正確には一致していません。したがって、tidb_enable_fast_analyzeが有効になっている場合は、tidb_analyze_versionから1の値を設定する必要があります。
フルコレクション
次の構文を使用して、完全な収集を実行できます。
TableNameListのすべてのテーブルの統計を収集するには:
```sql
ANALYZE TABLE TableNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
WITH NUM BUCKETSは、生成されたヒストグラムのバケットの最大数を指定します。WITH NUM TOPNは、生成されるTOPN秒の最大数を指定します。WITH NUM CMSKETCH DEPTHは、CMスケッチの深さを指定します。WITH NUM CMSKETCH WIDTHは、CMスケッチの幅を指定します。WITH NUM SAMPLESはサンプル数を指定します。WITH FLOAT_NUM SAMPLERATEはサンプリングレートを指定します。
WITH NUM SAMPLESとWITH FLOAT_NUM SAMPLERATEは、サンプルを収集する2つの異なるアルゴリズムに対応します。
WITH NUM SAMPLESは、サンプリングセットのサイズを指定します。これは、TiDBのリザーバーサンプリング方法で実装されます。テーブルが大きい場合、この方法を使用して統計を収集することはお勧めしません。リザーバーサンプリングの中間結果セットには冗長な結果が含まれているため、メモリなどのリソースに追加の圧力がかかります。WITH FLOAT_NUM SAMPLERATEは、v5.3.0で導入されたサンプリング方法です。値の範囲が(0, 1]の場合、このパラメーターはサンプリングレートを指定します。これは、TiDBでのベルヌーイサンプリングの方法で実装されます。これは、より大きなテーブルのサンプリングに適しており、収集効率とリソース使用量のパフォーマンスが向上します。
v5.3.0より前では、TiDBはリザーバーサンプリング方式を使用して統計を収集していました。 v5.3.0以降、TiDBバージョン2統計は、デフォルトでベルヌーイサンプリング法を使用して統計を収集します。貯留層サンプリング法を再利用するには、 WITH NUM SAMPLESステートメントを使用できます。
ノート:
現在のサンプリングレートは、適応アルゴリズムに基づいて計算されます。
SHOW STATS_METAを使用してテーブルの行数を確認できる場合、この行数を使用して、100,000行に対応するサンプリングレートを計算できます。この数値がわからない場合は、TABLE_STORAGE_STATS表のTABLE_KEYS列を別の参照として使用して、サンプリングレートを計算できます。通常、
STATS_METAはTABLE_KEYSよりも信頼できます。ただし、 TiDB Lightningなどの方法でデータをインポートすると、STATS_METAの結果は0になります。この状況を処理するために、STATS_METAの結果がTABLE_KEYSの結果よりもはるかに小さい場合に、TABLE_KEYSを使用してサンプリングレートを計算できます。
一部の列の統計を収集する
ほとんどの場合、SQLステートメントを実行するとき、オプティマイザーは一部の列( WHERE 、およびJOIN GROUP BYの列など)の統計のみを使用しORDER BY 。これらの列はPREDICATE COLUMNSと呼ばれます。
テーブルに多くの列がある場合、すべての列の統計を収集すると、大きなオーバーヘッドが発生する可能性があります。オーバーヘッドを削減するために、オプティマイザーが使用する特定の列またはPREDICATE COLUMNSつのみの統計を収集できます。
ノート:
一部の列の統計の収集は、
tidb_analyze_version = 2にのみ適用されます。
- 特定の列の統計を収集するには、次の構文を使用します。
```sql
ANALYZE TABLE TableName COLUMNS ColumnNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
構文では、 `ColumnNameList`はターゲット列の名前リストを指定します。複数の列を指定する必要がある場合は、コンマ`,`を使用して列名を区切ります。たとえば、 `ANALYZE table t columns a, b` 。この構文は、特定のテーブルの特定の列の統計を収集するだけでなく、インデックス付きの列とそのテーブルのすべてのインデックスの統計を同時に収集します。
> **ノート:**
>
> 上記の構文は完全なコレクションです。たとえば、この構文を使用して列`a`と`b`の統計を収集した後、列`c`の統計も収集する場合は、 `ANALYZE TABLE t COLUMNS c`を使用して追加の列`c`を指定するだけでなく、 `ANALYZE table t columns a, b, c`を使用して3つの列すべてを指定する必要があります。
PREDICATE COLUMNSの統計を収集するには、次のようにします。tidb_enable_column_trackingシステム変数の値をONに設定して、TiDBがPREDICATE COLUMNSを収集できるようにします。設定後、TiDBは100*
stats-leaseごとにPREDICATE COLUMNSの情報をmysql.column_stats_usageのシステムテーブルに書き込みます。ビジネスのクエリパターンが比較的安定したら、次の構文を使用して
PREDICATE COLUMNSの統計を収集します。
```sql
ANALYZE TABLE TableName PREDICATE COLUMNS [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
この構文は、特定のテーブルの`PREDICATE COLUMNS`に関する統計を収集するだけでなく、インデックス付きの列とそのテーブル内のすべてのインデックスの統計を同時に収集します。
> **ノート:**
>
> - `mysql.column_stats_usage`のシステムテーブルにそのテーブルの`PREDICATE COLUMNS`のレコードが含まれていない場合、前述の構文は、そのテーブルのすべての列とすべてのインデックスの統計を収集します。
> - この構文を使用して統計を収集した後、新しいタイプのSQLクエリを実行すると、オプティマイザーはこの時点で一時的に古い列または疑似列の統計を使用する場合があり、TiDBは次回から使用された列の統計を収集します。
- すべての列とインデックスの統計を収集するには、次の構文を使用します。
```sql
ANALYZE TABLE TableName ALL COLUMNS [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
ANALYZEステートメント( COLUMNS ColumnNameList 、およびPREDICATE COLUMNSを含む)の列構成を永続化する場合は、 tidb_persist_analyze_optionsシステム変数の値をALL COLUMNSに設定して、 ON機能を使用可能にANALYZE構成の永続性ます。 ANALYZE構成永続化機能を有効にした後:
- TiDBが統計を自動的に収集する場合、または列構成を指定せずに
ANALYZEステートメントを実行して統計を手動で収集する場合、TiDBは統計収集に以前に永続化された構成を引き続き使用します。 - 列構成を指定して
ANALYZEステートメントを手動で複数回実行すると、TiDBは、最新のANALYZEステートメントで指定された新しい構成を使用して、以前に記録された永続構成を上書きします。
統計が収集されたPREDICATE COLUMNS列と列を見つけるには、次の構文を使用します。
SHOW COLUMN_STATS_USAGE [ShowLikeOrWhere];
SHOW COLUMN_STATS_USAGEステートメントは、次の6列を返します。
次の例では、 ANALYZE TABLE t PREDICATE COLUMNS;を実行した後、 dは列b 、およびcの統計を収集します。ここで、列dはbで、列PREDICATE COLUMNおよびcはインデックス列です。
SET GLOBAL tidb_enable_column_tracking = ON;
Query OK, 0 rows affected (0.00 sec)
CREATE TABLE t (a INT, b INT, c INT, d INT, INDEX idx_c_d(c, d));
Query OK, 0 rows affected (0.00 sec)
-- The optimizer uses the statistics on column b in this query.
SELECT * FROM t WHERE b > 1;
Empty set (0.00 sec)
-- After waiting for a period of time (100 * stats-lease), TiDB writes the collected `PREDICATE COLUMNS` to mysql.column_stats_usage.
-- Specify `last_used_at IS NOT NULL` to show the `PREDICATE COLUMNS` collected by TiDB.
SHOW COLUMN_STATS_USAGE WHERE db_name = 'test' AND table_name = 't' AND last_used_at IS NOT NULL;
+---------+------------+----------------+-------------+---------------------+------------------+
| Db_name | Table_name | Partition_name | Column_name | Last_used_at | Last_analyzed_at |
+---------+------------+----------------+-------------+---------------------+------------------+
| test | t | | b | 2022-01-05 17:21:33 | NULL |
+---------+------------+----------------+-------------+---------------------+------------------+
1 row in set (0.00 sec)
ANALYZE TABLE t PREDICATE COLUMNS;
Query OK, 0 rows affected, 1 warning (0.03 sec)
-- Specify `last_analyzed_at IS NOT NULL` to show the columns for which statistics have been collected.
SHOW COLUMN_STATS_USAGE WHERE db_name = 'test' AND table_name = 't' AND last_analyzed_at IS NOT NULL;
+---------+------------+----------------+-------------+---------------------+---------------------+
| Db_name | Table_name | Partition_name | Column_name | Last_used_at | Last_analyzed_at |
+---------+------------+----------------+-------------+---------------------+---------------------+
| test | t | | b | 2022-01-05 17:21:33 | 2022-01-05 17:23:06 |
| test | t | | c | NULL | 2022-01-05 17:23:06 |
| test | t | | d | NULL | 2022-01-05 17:23:06 |
+---------+------------+----------------+-------------+---------------------+---------------------+
3 rows in set (0.00 sec)
インデックスに関する統計を収集する
TableNameのIndexNameListのすべてのインデックスの統計を収集するには、次の構文を使用します。
ANALYZE TABLE TableName INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
IndexNameListが空の場合、この構文はTableNameのすべてのインデックスの統計を収集します。
ノート:
収集の前後の統計情報に一貫性を持たせるために、
tidb_analyze_versionが2の場合、この構文は、インデックスだけでなく、テーブル全体(すべての列とインデックスを含む)の統計を収集します。
パーティションに関する統計を収集する
TableNameのPartitionNameListのすべてのパーティションの統計を収集するには、次の構文を使用します。
```sql
ANALYZE TABLE TableName PARTITION PartitionNameList [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
TableNameのPartitionNameListのすべてのパーティションのインデックス統計を収集するには、次の構文を使用します。
```sql
ANALYZE TABLE TableName PARTITION PartitionNameList INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
テーブル内の一部のパーティションのうち一部の列の統計を収集するだけが必要な場合は、次の構文を使用します。
```sql
ANALYZE TABLE TableName PARTITION PartitionNameList [COLUMNS ColumnNameList|PREDICATE COLUMNS|ALL COLUMNS] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
インクリメンタルコレクション
完全収集後の分析速度を向上させるために、増分収集を使用して、時間列などの単調に減少しない列に新しく追加されたセクションを分析できます。
ノート:
- 現在、インクリメンタルコレクションはインデックス用にのみ提供されています。
- インクリメンタルコレクションを使用する場合は、テーブルに
INSERTの操作のみが存在し、インデックス列に新しく挿入された値が単調に減少しないことを確認する必要があります。そうしないと、統計情報が不正確になり、TiDBオプティマイザが適切な実行プランを選択するのに影響を与える可能性があります。
次の構文を使用して、増分収集を実行できます。
TableName分のIndexNameListsすべてのインデックス列の統計を段階的に収集するには:
```sql
ANALYZE INCREMENTAL TABLE TableName INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
TableName分のPartitionNameListsすべてのパーティションのインデックス列の統計を段階的に収集するには:
```sql
ANALYZE INCREMENTAL TABLE TableName PARTITION PartitionNameList INDEX [IndexNameList] [WITH NUM BUCKETS|TOPN|CMSKETCH DEPTH|CMSKETCH WIDTH]|[WITH NUM SAMPLES|WITH FLOATNUM SAMPLERATE];
```
自動更新
INSERT 、またはDELETEステートメントの場合、 UPDATEは行数と更新された行を自動的に更新します。 TiDBはこの情報を定期的に保持し、更新サイクルは20* stats-leaseです。デフォルト値のstats-leaseは3sです。値を0に指定すると、自動的に更新されません。
統計の自動更新に関連する3つのシステム変数は次のとおりです。
テーブル内のtblの行の総数に対する変更された行の数の比率がtidb_auto_analyze_ratioより大きく、現在の時刻がtidb_auto_analyze_start_timeの場合、 tidb_auto_analyze_end_timeはバックグラウンドでANALYZE TABLE tblステートメントを実行して、この統計を自動的に更新します。テーブル。
ノート:
現在、自動更新では、マニュアル
ANALYZEで入力された構成項目は記録されません。したがって、WITH構文を使用してANALYZEの収集動作を制御する場合は、統計を収集するためにスケジュールされたタスクを手動で設定する必要があります。
v5.0より前では、クエリを実行すると、TiDBはfeedback-probabilityでフィードバックを収集し、フィードバックに基づいてヒストグラムとカウント最小スケッチを更新します。 v5.0以降、この機能はデフォルトで無効になっているため、この機能を有効にすることはお勧めしません。
ANALYZE並行性を制御する
ANALYZEステートメントを実行する場合、次のパラメーターを使用して並行性を調整し、システムへの影響を制御できます。
tidb_build_stats_concurrency
現在、 ANALYZEステートメントを実行すると、タスクは複数の小さなタスクに分割されます。各タスクは、1つの列またはインデックスでのみ機能します。 tidb_build_stats_concurrencyパラメーターを使用して、同時タスクの数を制御できます。デフォルト値は4です。
tidb_distsql_scan_concurrency
通常の列を分析する場合、 tidb_distsql_scan_concurrencyパラメーターを使用して、一度に読み取るリージョンの数を制御できます。デフォルト値は15です。
tidb_index_serial_scan_concurrency
インデックス列を分析する場合、 tidb_index_serial_scan_concurrencyパラメーターを使用して、一度に読み取るリージョンの数を制御できます。デフォルト値は1です。
ANALYZE構成を永続化する
v5.4.0以降、TiDBはいくつかのANALYZE構成の永続化をサポートしています。この機能を使用すると、既存の構成を将来の統計収集に簡単に再利用できます。
永続性をサポートするANALYZEの構成は次のとおりです。
ANALYZE構成の永続性を有効にする
ANALYZE構成永続化機能は、デフォルトで有効になっています(システム変数tidb_analyze_versionは2で、 tidb_persist_analyze_optionsはデフォルトでONです)。この機能を使用して、ステートメントを手動で実行するときに、 ANALYZEステートメントで指定された永続性構成を記録できます。記録されると、次にTiDBが統計を自動的に更新するか、これらの構成を指定せずに手動で統計を収集すると、TiDBは記録された構成に従って統計を収集します。
永続性構成を指定してANALYZEステートメントを手動で複数回実行すると、TiDBは、最新のANALYZEステートメントで指定された新しい構成を使用して、以前に記録された永続性構成を上書きします。
ANALYZE構成の永続性を無効にする
ANALYZE構成の永続化機能を無効にするには、 tidb_persist_analyze_optionsシステム変数をOFFに設定します。 ANALYZE構成の永続化機能はtidb_analyze_version = 1には適用できないため、 tidb_analyze_version = 1を設定すると機能を無効にすることもできます。
ANALYZE構成の永続化機能を無効にした後、TiDBは永続化された構成レコードをクリアしません。したがって、この機能を再度有効にすると、TiDBは、以前に記録された永続的な構成を使用して統計を収集し続けます。
ノート:
ANALYZE構成の永続性機能を再度有効にしたときに、以前に記録された永続性構成が最新のデータに適用できなくなった場合は、ANALYZEステートメントを手動で実行し、新しい永続性構成を指定する必要があります。
ANALYZE状態を表示
ANALYZEステートメントを実行する場合、次のSQLステートメントを使用してANALYZEの現在の状態を表示できます。
SHOW ANALYZE STATUS [ShowLikeOrWhere]
このステートメントは、 ANALYZEの状態を返します。 ShowLikeOrWhereを使用して、必要な情報をフィルタリングできます。
現在、 SHOW ANALYZE STATUSステートメントは次の7列を返します。
統計を表示する
次のステートメントを使用して、統計ステータスを表示できます。
テーブルのメタデータ
SHOW STATS_METAステートメントを使用して、行の総数と更新された行の数を表示できます。
SHOW STATS_META [ShowLikeOrWhere];
ShowLikeOrWhereOptの構文は次のとおりです。

現在、 SHOW STATS_METAステートメントは次の6列を返します。
ノート:
TiDBがDMLステートメントに従って行の総数と変更された行の数を自動的に更新すると、
update_timeも更新されます。したがって、update_timeは、ANALYZEステートメントが最後に実行された時刻を必ずしも示しているわけではありません。
テーブルのヘルス状態
SHOW STATS_HEALTHYステートメントを使用して、テーブルの正常性状態を確認し、統計の精度を大まかに見積もることができます。 modify_count > = row_countの場合、ヘルス状態は0です。 modify_count < row_countの場合、ヘルス状態は( modify_count / row_count )*100です。
構文は次のとおりです。
SHOW STATS_HEALTHY [ShowLikeOrWhere];
SHOW STATS_HEALTHYの概要は次のとおりです。

現在、 SHOW STATS_HEALTHYステートメントは次の4列を返します。
列のメタデータ
SHOW STATS_HISTOGRAMSステートメントを使用して、すべての列のさまざまな値の数とNULLの数を表示できます。
構文は次のとおりです。
SHOW STATS_HISTOGRAMS [ShowLikeOrWhere]
このステートメントは、すべての列の異なる値の数とNULLの数を返します。 ShowLikeOrWhereを使用して、必要な情報をフィルタリングできます。
現在、 SHOW STATS_HISTOGRAMSステートメントは次の10列を返します。
ヒストグラムのバケット
SHOW STATS_BUCKETSステートメントを使用して、ヒストグラムの各バケットを表示できます。
構文は次のとおりです。
SHOW STATS_BUCKETS [ShowLikeOrWhere]
回路図は以下の通りです:

このステートメントは、すべてのバケットに関する情報を返します。 ShowLikeOrWhereを使用して、必要な情報をフィルタリングできます。
現在、 SHOW STATS_BUCKETSステートメントは次の11列を返します。
トップN情報
SHOW STATS_TOPNステートメントを使用して、TiDBによって現在収集されているTop-N情報を表示できます。
構文は次のとおりです。
SHOW STATS_TOPN [ShowLikeOrWhere];
現在、 SHOW STATS_TOPNステートメントは次の7列を返します。
統計を削除する
DROP STATSステートメントを実行して、統計を削除できます。
構文は次のとおりです。
DROP STATS TableName
このステートメントは、 TableNameのすべてのテーブルの統計を削除します。
負荷統計
デフォルトでは、列統計のサイズに応じて、TiDBは次のように統計を異なる方法でロードします。
- 小さなスペース(count、distinctCount、nullCountなど)を消費する統計の場合、列データが更新されている限り、TiDBは対応する統計をメモリに自動的にロードしてSQL最適化段階で使用します。
- 大きなスペースを消費する統計(ヒストグラム、TopN、Count-Min Sketchなど)の場合、SQL実行のパフォーマンスを確保するために、TiDBはオンデマンドで統計を非同期にロードします。例としてヒストグラムを取り上げます。 TiDBは、オプティマイザがその列のヒストグラム統計を使用する場合にのみ、列のヒストグラム統計をメモリにロードします。オンデマンドの非同期統計ロードはSQL実行のパフォーマンスに影響を与えませんが、SQL最適化の統計が不完全になる可能性があります。
v5.4.0以降、TiDBは同期ロード統計機能を導入しています。この機能により、SQLステートメントの実行時にTiDBが大規模な統計(ヒストグラム、TopN、Count-Min Sketch統計など)をメモリに同期的にロードできるようになり、SQL最適化の統計の完全性が向上します。
統計の同期ロード機能はデフォルトで無効になっています。この機能を有効にするには、 tidb_stats_load_sync_waitシステム変数の値を、SQL最適化が完全な列統計を同期的にロードするために最大で待機できるタイムアウト(ミリ秒単位)に設定します。この変数のデフォルト値は0で、機能が無効になっていることを示します。
同期ロード統計機能を有効にした後、次のように機能をさらに構成できます。
- SQL最適化の待機時間がタイムアウトに達したときのTiDBの動作を制御するには、
tidb_stats_load_pseudo_timeoutシステム変数の値を変更します。この変数のデフォルト値はOFFで、タイムアウト後にSQLの実行が失敗することを示します。この変数をONに設定すると、タイムアウト後、SQL最適化プロセスはどの列にもヒストグラム、TopN、またはCMSketch統計を使用しませんが、疑似統計の使用に戻ります。 - 同期ロード統計機能が同時に処理できる列の最大数を指定するには、TiDB構成ファイルの
stats-load-concurrencyオプションの値を変更します。デフォルト値は5です。 - 同期ロード統計機能がキャッシュできる列要求の最大数を指定するには、TiDB構成ファイルの
stats-load-queue-sizeオプションの値を変更します。デフォルト値は1000です。
統計のインポートとエクスポート
統計のエクスポート
統計をエクスポートするためのインターフェースは次のとおりです。
${db_name}データベースの${table_name}テーブルのJSON形式の統計を取得するには:
```
http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}
```
例えば:
```
curl -s http://127.0.0.1:10080/stats/dump/test/t1 -o /tmp/t1.json
```
- 特定の時間に
${db_name}データベースの${table_name}テーブルのJSON形式の統計を取得するには:
```
http://${tidb-server-ip}:${tidb-server-status-port}/stats/dump/${db_name}/${table_name}/${yyyyMMddHHmmss}
```
統計のインポート
ノート:
MySQLクライアントを起動するときは、
--local-infile=1オプションを使用します。
通常、インポートされた統計は、エクスポートインターフェイスを使用して取得されたJSONファイルを参照します。
構文:
LOAD STATS 'file_name'
file_nameは、インポートする統計のファイル名です。