TiDBダッシュボード診断レポート
このドキュメントでは、診断レポートの内容と表示のヒントを紹介します。クラスタ診断ページにアクセスしてレポートを生成するには、 TiDBダッシュボードクラスター診断ページを参照してください。
レポートを表示
診断レポートは、次の部分で構成されています。
- 基本情報:診断レポートの時間範囲、クラスタのハードウェア情報、クラスタトポロジのバージョン情報が含まれます。
- 診断情報:自動診断の結果を表示します。
- 負荷情報:サーバー、TiDB、PD、またはTiKVのCPU、メモリ、およびその他の負荷情報が含まれます。
- 概要情報:各TiDB、PD、またはTiKVモジュールの消費時間とエラー情報が含まれます。
- TiDB / PD / TiKV監視情報:各コンポーネントの監視情報が含まれます。
- Configuration / コンフィグレーション情報:各コンポーネントの構成情報が含まれます。
診断レポートの例は次のとおりです。

上の画像では、上部の青いボックスの合計時間消費がレポート名です。下の赤いボックスの情報は、このレポートの内容とレポートの各フィールドの意味を説明しています。
このレポートでは、いくつかの小さなボタンについて次のように説明しています。
- iアイコン:マウスをiアイコンに移動すると、行の説明文が表示されます。
- 展開:[展開]をクリックして、この監視メトリックの詳細を表示します。たとえば、上の画像の
tidb_get_tokenの詳細情報には、各TiDBインスタンスのレイテンシの監視情報が含まれています。 - 折りたたみ:展開とは逆に、ボタンは詳細な監視情報を折りたたむために使用されます。
すべての監視メトリックは、基本的にTiDBGrafana監視ダッシュボードのメトリックに対応しています。モジュールが異常であることが判明した後、TiDBGrafanaでより多くの監視情報を表示できます。
さらに、このレポートのTOTAL_TIMEとTOTAL_COUNTのメトリックは、Prometheusから読み取られたデータを監視しているため、計算の不正確さが統計に存在する可能性があります。
このレポートの各部分は、次のように紹介されています。
基本情報
診断時間範囲
診断レポートを生成するための時間範囲には、開始時刻と終了時刻が含まれます。

クラスターハードウェア情報
クラスタハードウェア情報には、クラスタの各サーバーのCPU、メモリ、ディスクなどの情報が含まれます。

上記の表のフィールドは次のとおりです。
HOST:サーバーのIPアドレス。INSTANCE:サーバーにデプロイされたインスタンスの数。たとえば、pd * 1は、このサーバーに1つのPDインスタンスがデプロイされていることを意味します。tidb * 2 pd * 1は、このサーバーに2つのTiDBインスタンスと1つのPDインスタンスがデプロイされていることを意味します。CPU_CORES:サーバーのCPUコア(物理コアまたは論理コア)の数を示します。MEMORY:サーバーのメモリサイズを示します。単位はGBです。DISK:サーバーのディスクサイズを示します。単位はGBです。UPTIME:サーバーの稼働時間。単位は日です。
クラスタートポロジ情報
Cluster Infoの表は、クラスタトポロジー情報を示しています。この表の情報は、 information_schema.cluster_infoシステム表からのものです。

上記の表のフィールドは次のとおりです。
TYPE:ノードタイプ。INSTANCE:インスタンスアドレスIP:PORT形式の文字列です。STATUS_ADDRESS:HTTPAPIサービスアドレス。VERSION:対応するノードのセマンティックバージョン番号。GIT_HASH:ノードバージョンをコンパイルするときにGit Commit Hashを実行します。これは、2つのノードが完全に一貫したバージョンであるかどうかを識別するために使用されます。START_TIME:対応するノードの開始時刻。UPTIME:対応するノードの稼働時間。
診断情報
TiDBには自動診断結果が組み込まれています。各フィールドの説明については、 information_schema.inspection-結果のシステム表を参照してください。
情報を読み込む
ノード負荷情報
Node Load Infoの表は、サーバーノードの負荷情報を示しています。これには、時間範囲内のサーバーの次のメトリックの平均値(AVG)、最大値(MAX)、最小値(MIN)が含まれます。
- CPU使用率(最大値は
100%) - メモリ使用量
- ディスクI/Oの使用
- ディスク書き込みレイテンシ
- ディスク読み取りの待ち時間
- 1秒あたりのディスク読み取りバイト数
- 1秒あたりのディスク書き込みバイト数
- 1分あたりにノードネットワークが受信したバイト数
- 1分あたりにノードネットワークから送信されたバイト数
- ノードで使用されているTCP接続の数
- ノードのすべてのTCP接続の数
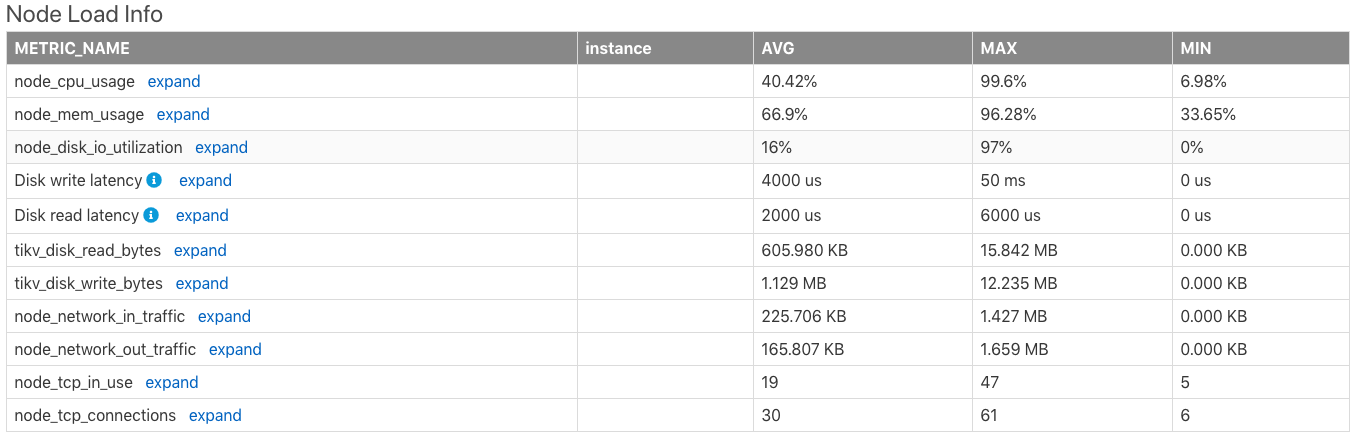
インスタンスのCPU使用率
Instance CPU Usageの表は、各TiDB / PD / TiKVプロセスのCPU使用率の平均値(AVG)、最大値(MAX)、および最小値(MIN)を示しています。プロセスの最大CPU使用率は100% * the number of CPU logical coresです。

インスタンスのメモリ使用量
Instance Memory Usageの表は、各TiDB / PD / TiKVプロセスが占有するメモリバイトの平均値(AVG)、最大値(MAX)、および最小値(MIN)を示しています。

TiKVスレッドのCPU使用率
TiKV Thread CPU Usageの表は、TiKVの各モジュールスレッドのCPU使用率の平均値(AVG)、最大値(MAX)、および最小値(MIN)を示しています。プロセスの最大CPU使用率は100% * the thread count of the corresponding configurationです。
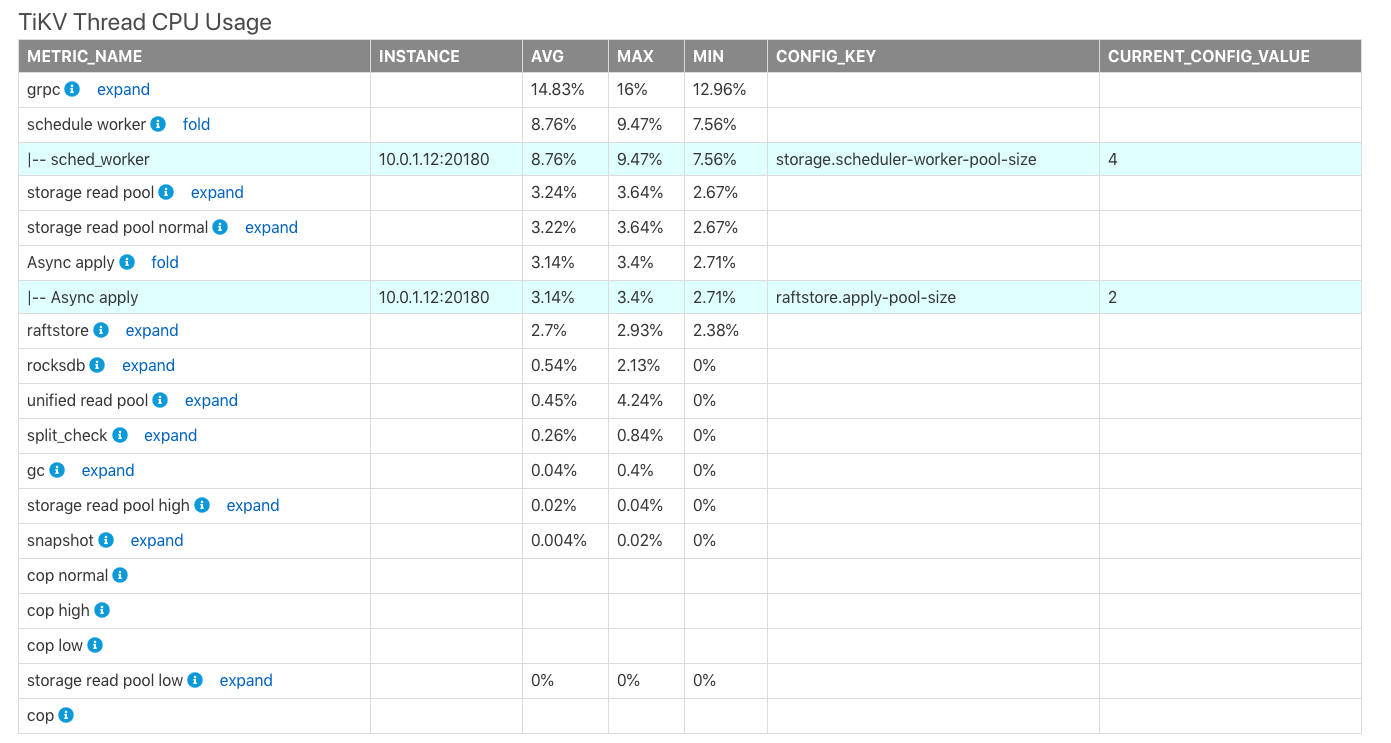
上の表では、
CONFIG_KEY:対応するモジュールの関連するスレッド構成。CURRENT_CONFIG_VALUE:レポート生成時の構成の現在の値。
ノート:
CURRENT_CONFIG_VALUEはレポートが生成されたときの値であり、このレポートの時間範囲内の値ではありません。現在、過去の時間の一部の構成値を取得できません。
TiDB/PD Goroutines Count
TiDB/PD Goroutines Countの表は、TiDBまたはPDゴルーチンの数の平均値(AVG)、最大値(MAX)、および最小値(MIN)を示しています。ゴルーチンの数が2,000を超える場合、プロセスの同時実行性が高すぎるため、全体的なリクエストのレイテンシーに影響します。

概要情報
各コンポーネントにかかる時間
Time Consumed by Each Componentの表は、監視された消費時間と、クラスタのTiDB、PD、TiKVモジュールの時間比率を示しています。デフォルトの時間単位は秒です。この表を使用して、より多くの時間を消費するモジュールをすばやく見つけることができます。
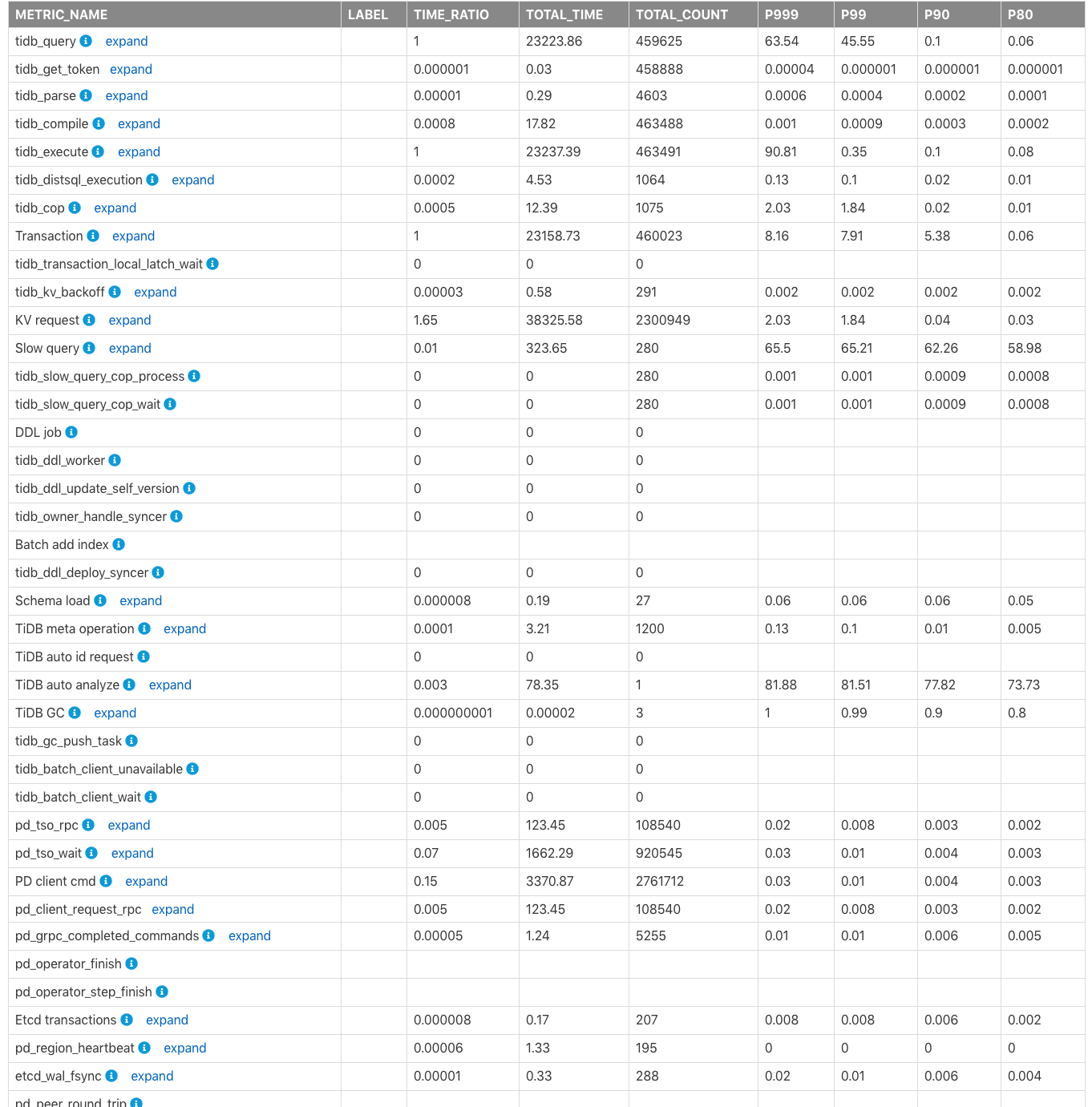
上記の表の列のフィールドは、次のように説明されています。
METRIC_NAME:監視メトリックの名前。Label:監視メトリックのラベル情報。 [**展開]**をクリックして、メトリックの各ラベルのより詳細な監視情報を表示します。TIME_RATIO:この監視メトリックによって消費された合計時間と監視行の合計時間の比率(TIME_RATIOは1)。たとえば、kv_requestの合計消費時間はtidb_queryの1.65(つまり、38325.58/23223.86)倍です。 KVリクエストは同時に実行されるため、すべてのKVリクエストの合計時間がクエリの合計(tidb_query)実行時間を超える可能性があります。TOTAL_TIME:この監視メトリックによって消費された合計時間。TOTAL_COUNT:この監視メトリックが実行された合計回数。P999:この監視メトリックの最大P999時間。P99:この監視メトリックの最大P99時間。P90:この監視メトリックの最大P90時間。P80:この監視メトリックの最大P80時間。
次の画像は、上記の監視メトリックにおける関連モジュールの時間消費の関係を示しています。
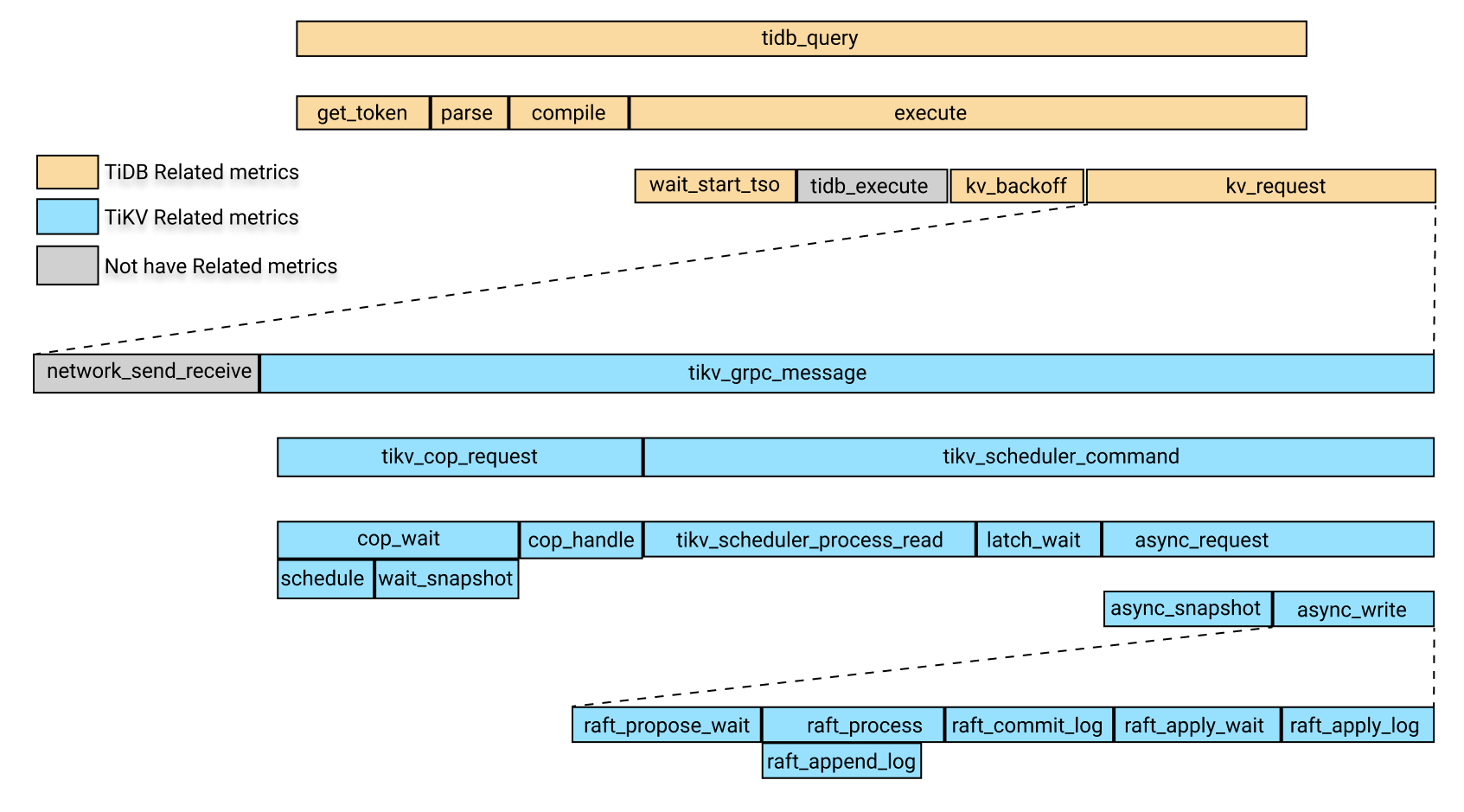
上の画像で、黄色のボックスはTiDB関連の監視メトリックです。青いボックスはTiKV関連の監視メトリックであり、灰色のボックスは一時的に特定の監視メトリックに対応していません。
上の画像では、 tidb_queryの時間消費には次の4つの部分が含まれています。
get_tokenparsecompileexecute
execute回には、次の部分が含まれます。
wait_start_tso- 現在監視されていないTiDBレイヤーでの実行時間
- KVリクエスト時間
KV_backoff時間。これは、KV要求が失敗した後のバックオフの時間です。
上記の部分のうち、KV要求時間には次の部分が含まれます。
- ネットワークがリクエストを送受信するのにかかる時間。現在、このアイテムの監視メトリックはありません。 KV要求時間から
tikv_grpc_messageの時間を差し引くと、このアイテムを概算できます。 tikv_grpc_message時間の消費。
上記の部分のうち、 tikv_grpc_message回の消費には次の部分が含まれます。
コプロセッサー要求時間の消費。これは、COPタイプの要求の処理を指します。この時間の消費には、次の部分が含まれます。
tikv_cop_wait:リクエストキューによって消費された時間。Coprocessor handle:コプロセッサー要求の処理に費やされた時間。
次の部分を含む
tikv_scheduler_command時間の消費:tikv_scheduler_processing_read:読み取り要求の処理に費やされた時間。tikv_storage_async_requestでスナップショットを取得するのにかかった時間(スナップショットはこの監視メトリックのラベルです)。- 書き込み要求の処理にかかる時間。この時間の消費には、次の部分が含まれます。
tikv_scheduler_latch_wait:ラッチの待機にかかる時間。tikv_storage_async_requestでの書き込みの時間消費(書き込みはこの監視メトリックのラベルです)。
上記のメトリックの中で、 tikv_storage_async_requestでの書き込みの時間消費は、次の部分を含むRaftKVの書き込みの時間消費を指します。
tikv_raft_propose_waittikv_raft_process、主にtikv_raft_append_logを含むtikv_raft_commit_logtikv_raft_apply_waittikv_raft_apply_log
TOTAL_TIME 、P999時間、およびP99時間を使用して、上記の時間消費量の関係に従って、どのモジュールがより長い時間を消費するかを判別し、関連する監視メトリックを確認できます。
ノート:
Raft KVの書き込みは
tikv_raft_commit_logtikv_raft_apply_waitのバッチで処理される可能性があるため、TOTAL_TIMEを使用して各モジュールで消費される時間を測定することは、Raft KVの書き込みに関連するメトリック(具体的にはtikv_raft_process、およびtikv_raft_append_log)の監視には適用できtikv_raft_apply_logん。この状況では、各モジュールの消費時間をP999およびP99の時間と比較する方が合理的です。その理由は、非同期書き込み要求が10個ある場合、Raft KVは内部で10個の要求をバッチ実行にパックし、実行時間は1秒であるためです。したがって、各リクエストの実行時間は1秒、10リクエストの合計時間は10秒ですが、RaftKV処理の合計時間は1秒です。
TOTAL_TIMEを使用して消費時間を測定すると、残りの9秒がどこで費やされているかがわからない場合があります。また、リクエストの総数から、Raft KVのモニタリングメトリックと他の以前のモニタリングメトリックの違いを確認できます(TOTAL_COUNT)。
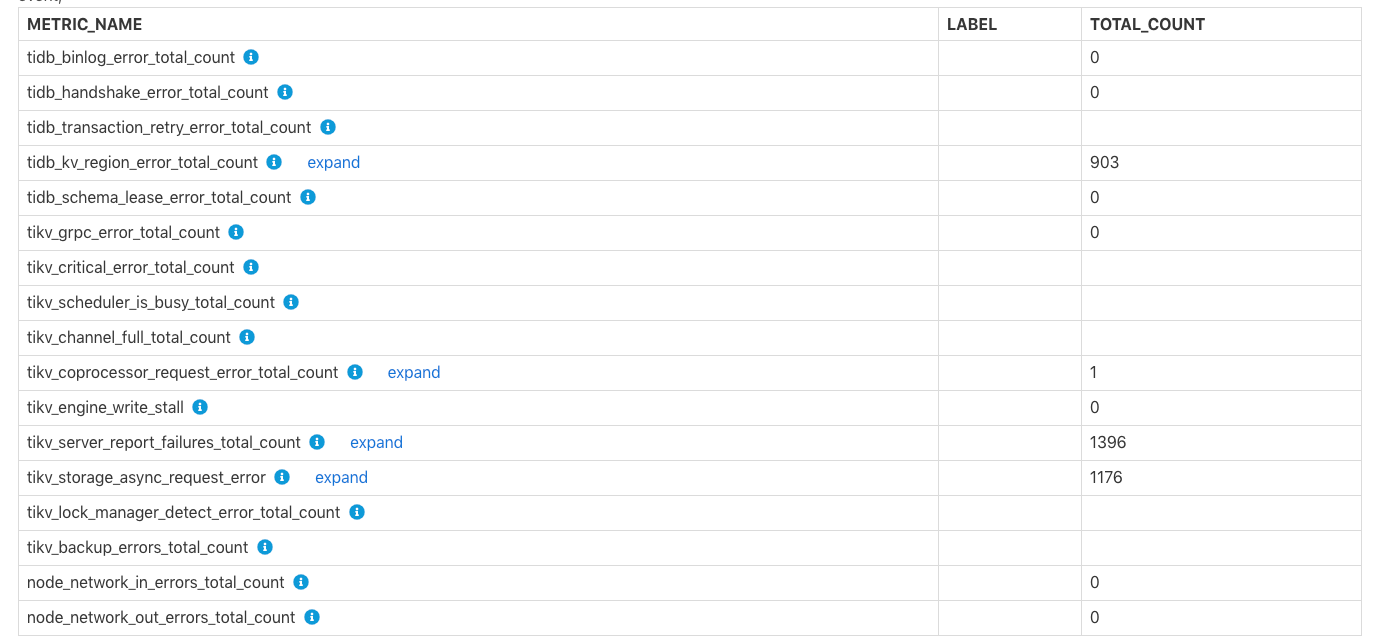
各コンポーネントで発生したエラー
Errors Occurred in Each Componentの表は、binlogの書き込みの失敗、 tikv server is busyなど、 TiKV channel fullとTiKVのエラーの総数を示していtikv write stall 。各エラーの特定の意味については、行のコメントを確認できます。
特定のTiDB/PD/TiKV監視情報
このパートには、TiDB、PD、またはTiKVのより具体的な監視情報が含まれています。
TiDB関連の監視情報
TiDBコンポーネントにかかる時間
この表は、各TiDBモジュールで消費される時間と各時間消費の比率を示しています。これは、概要のtime consumeの表と同様ですが、この表のラベル情報はより詳細です。
TiDBサーバー接続
この表は、各TiDBインスタンスのクライアント接続の数を示しています。
TiDBトランザクション
この表は、トランザクション関連の監視メトリックを示しています。
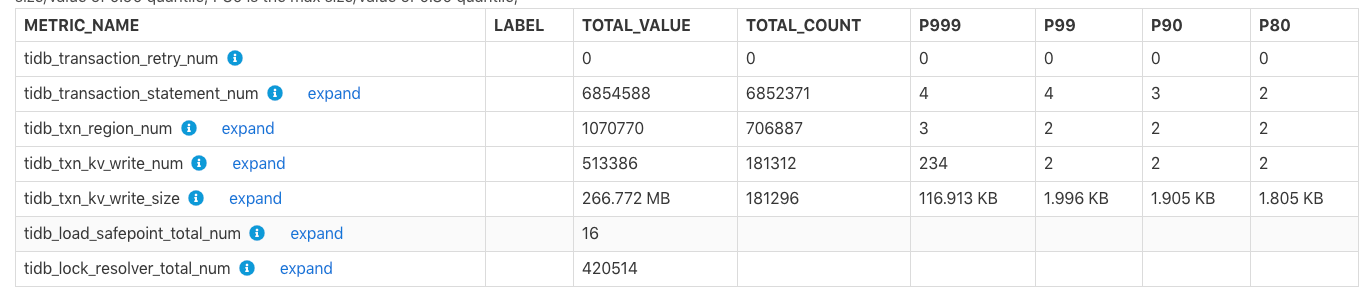
TOTAL_VALUE:レポートの時間範囲内のすべての値の合計(SUM)。TOTAL_COUNT:この監視メトリックの発生の総数。P999:この監視メトリックの最大P999値。P99:この監視メトリックの最大P99値。P90:この監視メトリックの最大P90値。P80:この監視メトリックの最大P80値。
例:
上記の表では、レポートの時間範囲内で、 tidb_txn_kv_write_size :KV書き込みの合計約181,296トランザクション、合計KV書き込みサイズは266.772 MBであり、そのうちの最大P999、P99、P90、P80値はKV書き込みは116.913KB、1.996 KB、1.905 KB、および1.805KBです。
DDL所有者

上の表は、 2020-05-21 14:40:00から、クラスターのDDL OWNERが10.0.1.13:10080ノードにあることを示しています。所有者が変更された場合、上の表には複数行のデータが存在しますMin_Time列は、対応する既知の所有者の最小時間を示します。
ノート:
所有者情報が空の場合でも、この期間に所有者が存在しないことを意味するものではありません。この場合、
ddl_workerの監視情報に基づいてDDL所有者が決定されるため、この期間にddl_workerがDDLジョブを実行しておらず、所有者情報が空になっている可能性があります。
TiDBの他の監視テーブルは次のとおりです。
- 統計情報:TiDB統計情報の関連する監視メトリックを表示します。
- トップ10スロークエリ:レポート時間範囲のトップ10スロークエリ情報を表示します。
- ダイジェスト別の上位10の低速クエリグループ:レポートの時間範囲内の上位10の低速クエリ情報を表示します。これはSQLフィンガープリントに従って集計されます。
- Diff Planを使用した低速クエリ:レポートの時間範囲内で実行プランが変更されるSQLステートメント。
PD関連の監視情報
PDモジュールの監視情報に関する表は以下のとおりです。
Time Consumed by PD Component:PD内の関連モジュールの監視メトリックによって消費される時間。Blance Leader/Region:balance-regionとbalance leaderの監視情報は、tikv_note_1からスケジュールされたリーダーの数やでスケジュールされたリーダーの数など、レポートの時間範囲内でクラスタ内で発生しました。Cluster Status:TiKVノードの総数、クラスタの総ストレージ容量、リージョンの数、オフラインTiKVノードの数などのクラスタステータス情報。Store Status:リージョンスコア、リーダースコア、リージョン/リーダーの数など、各TiKVノードのステータス情報を記録します。Etcd Status:PDのetcd関連情報。
TiKV関連の監視情報
TiKVモジュールの監視情報に関する表は次のとおりです。
Time Consumed by TiKV Component:TiKVの関連モジュールが消費する時間。Time Consumed by RocksDB:TiKVでRocksDBが消費する時間。TiKV Error:TiKVの各モジュールに関連するエラー情報。TiKV Engine Size:TiKVの各ノードに保存されている列ファミリーのデータのサイズ。Coprocessor Info:TiKVのコプロセッサーモジュールに関連する監視情報。Raft Info:TiKVのラフトモジュールの監視情報。Snapshot Info:TiKVのスナップショット関連の監視情報。GC Info:TiKVのガベージコレクション(GC)関連の監視情報。Cache Hit:TiKVのRocksDBの各キャッシュのヒット率情報。
Configuration / コンフィグレーション情報
構成情報では、一部のモジュールの構成値がレポート時間範囲内に表示されます。ただし、これらのモジュールの他の構成の履歴値は取得できないため、これらの構成の表示値は現在の(レポートが生成されたときの)値です。
レポートの時間範囲内で、次の表には、レポートの時間範囲の開始時に値が構成されている項目が含まれています。
Scheduler Initial Config:レポートの開始時のPDスケジューリング関連の構成の初期値。TiDB GC Initial Config:レポート開始時のTiDBGC関連構成の初期値TiKV RocksDB Initial Config:レポートの開始時のTiKVRocksDB関連の構成の初期値TiKV RaftStore Initial Config:レポート開始時のTiKVRaftStore関連の設定の初期値
レポートの時間範囲内で、一部の構成が変更されている場合、次の表には、変更された一部の構成のレコードが含まれています。
Scheduler Config Change HistoryTiDB GC Config Change HistoryTiKV RocksDB Config Change HistoryTiKV RaftStore Config Change History
例:

上記の表は、 leader-schedule-limitの構成パラメーターがレポートの時間範囲内で変更されたことを示しています。
2020-05-22T20:00:00+08:00:レポートの開始時にleader-schedule-limitの構成値は4です。これは、構成が変更されたことを意味するのではなく、レポートの時間範囲の開始時に、その構成値が4であることを意味します。2020-05-22T20:07:00+08:00:leader-schedule-limit構成値は8です。これは、この構成の値が約2020-05-22T20:07:00+08:00に変更されたことを示します。
次の表は、レポートが生成された時点でのTiDB、PD、およびTiKVの現在の構成を示しています。
TiDB's Current ConfigPD's Current ConfigTiKV's Current Config
比較レポート
2つの時間範囲の比較レポートを生成できます。レポートの内容は、2つの時間範囲の違いを示すために比較列が追加されていることを除いて、単一の時間範囲のレポートと同じです。次のセクションでは、比較レポートのいくつかの固有のテーブルと、比較レポートを表示する方法を紹介します。
まず、基本情報のCompare Report Time Rangeのレポートは、比較のために2つの時間範囲を示しています。

上記の表で、 t1は通常の時間範囲または参照時間範囲です。 t2は異常な時間範囲です。
低速クエリに関連するテーブルを以下に示します。
Slow Queries In Time Range t2:t2にのみ表示され、t1には表示されない低速クエリを表示します。Top 10 slow query in time range t1:t1の間のトップ10の遅いクエリ。Top 10 slow query in time range t2:t2の間のトップ10の遅いクエリ。
DIFF_RATIOの紹介
このセクションでは、例としてInstance CPU Usageテーブルを使用してDIFF_RATIOを紹介します。

t1.AVGは、t1.MAXのt1.Min使用率の平均値、最大値、および最小値t1。t2.AVG、およびt2.MAXは、t2.Minの間のCPU使用率の平均値、最大値、および最小値t2。AVG_DIFF_RATIOは、t1とt2の間の平均値のDIFF_RATIOです。MAX_DIFF_RATIOは、t1とt2の間の最大値のDIFF_RATIOです。MIN_DIFF_RATIOは、t1とt2の間の最小値のDIFF_RATIOです。
DIFF_RATIO :2つの時間範囲の差の値を示します。次の値があります。
- 監視メトリックの値が
t2以内で、値がt1以内でない場合、DIFF_RATIOの値は1です。 - 監視メトリックの値が
t1以内で、t2時間範囲内に値がない場合、DIFF_RATIOの値は-1です。 t2の値がt1の値より大きい場合、DIFF_RATIO=(t2.value / t1.value)-1t2の値がt1の値よりも小さい場合、DIFF_RATIO=1-(t1.value / t2.value)
たとえば、上の表では、 t2のtidbノードの平均CPU使用率はt1のそれより2.02倍高く、 2.02 = 1240/410-1です。
最大異なるアイテムテーブル
Maximum Different Itemの表は、2つの時間範囲の監視メトリックを比較し、監視メトリックの違いに従ってそれらをソートします。この表を使用すると、2つの時間範囲で最大の違いがある監視メトリックをすばやく見つけることができます。次の例を参照してください。
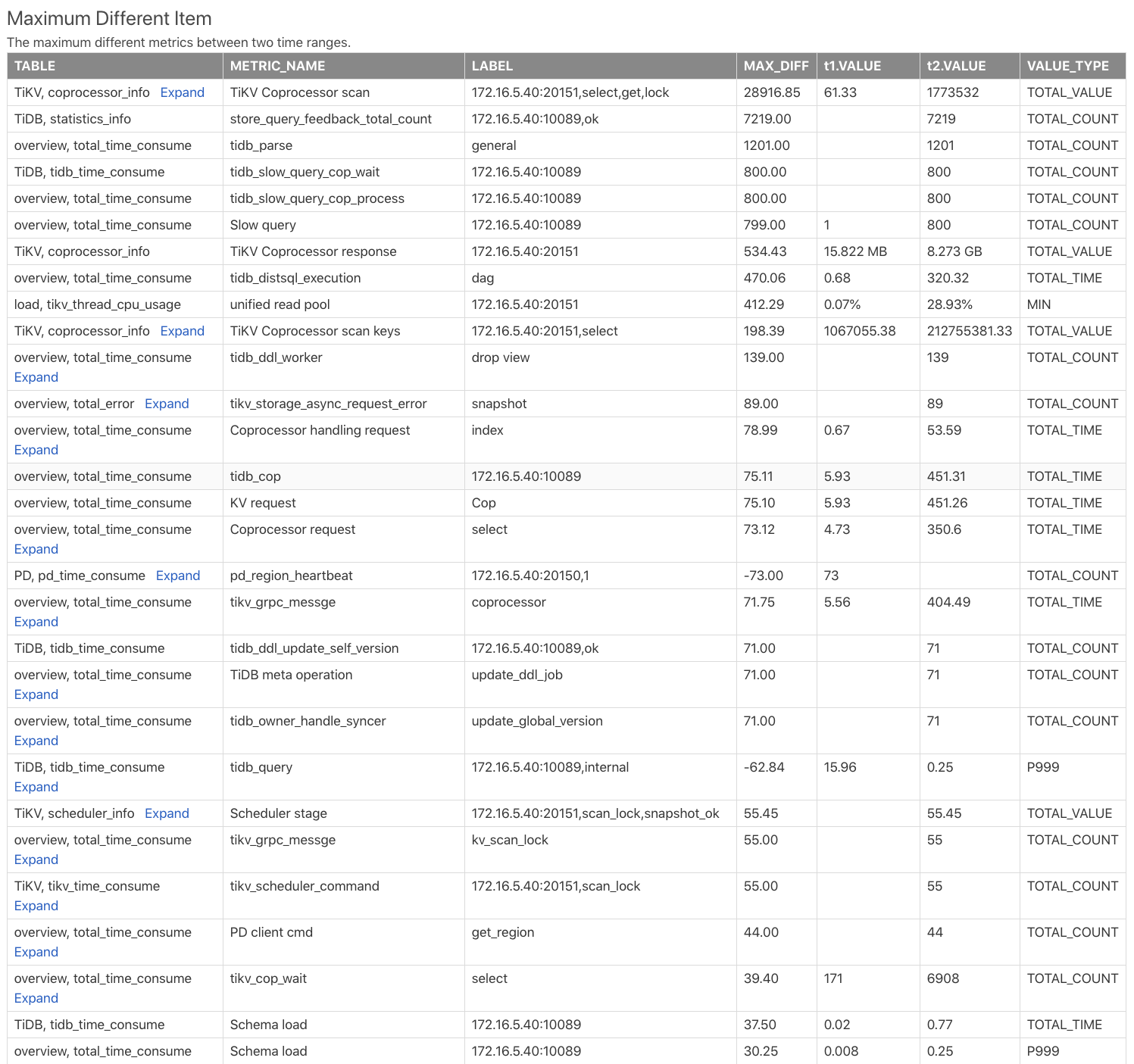
Table:この監視メトリックが比較レポートのどのテーブルからのものであるかを示します。たとえば、TiKV, coprocessor_infoはTiKVコンポーネントのcoprocessor_infoテーブルを示します。METRIC_NAME:監視メトリック名。expandをクリックして、メトリックのさまざまなラベルの比較を表示します。LABEL:監視メトリックに対応するラベル。たとえば、2の監視メトリックにはTiKV Coprocessor scaninstanceのラベル、つまりreqがありsql_type。これらは、tagアドレス、要求タイプ、操作タイプ、および操作列ファミリーです。MAX_DIFF:差の値t1.VALUEとt2.VALUEのDIFF_RATIOの計算です。
上記の表から、 t2つの時間範囲にはt1の時間範囲よりもはるかに多くのコプロセッサー要求があり、 t2のTiDBのSQL解析時間ははるかに長いことがわかります。