TiDB Dashboard診断レポート
このドキュメントでは、診断レポートの内容と表示に関するヒントを紹介します。クラスター診断ページにアクセスしてレポートを生成するには、 TiDB Dashboardのクラスタ診断ページ参照してください。
レポートを表示する
診断レポートは次の部分で構成されます。
- 基本情報: 診断レポートの時間範囲、クラスターのハードウェア情報、クラスター トポロジのバージョン情報が含まれます。
- 診断情報: 自動診断の結果を表示します。
- 負荷情報:サーバー、TiDB、PD、または TiKV の CPU、メモリ、その他の負荷情報が含まれます。
- 概要情報: 各 TiDB、PD、または TiKV モジュールの消費時間とエラー情報が含まれます。
- TiDB/PD/TiKV 監視情報:各コンポーネントの監視情報が含まれます。
- コンフィグレーション情報: 各コンポーネントの構成情報が含まれます。
診断レポートの例は次のとおりです。

上の画像では、上部の青い枠内の「Total Time Consume(総消費時間)」がレポート名です。下部の赤い枠内の情報は、このレポートの内容と各フィールドの意味を説明しています。
このレポートでは、いくつかの小さなボタンについて次のように説明しています。
- iアイコン: マウスをiアイコンに移動すると、行の説明が表示されます。
- expand : expandをクリックすると、この監視メトリックの詳細が表示されます。例えば、上の画像の
tidb_get_tokenの詳細情報には、各 TiDB インスタンスのレイテンシーの監視情報が含まれています。 - 折りたたみ:展開とは逆に、詳細な監視情報を折りたたむためのボタンです。
すべての監視メトリックは、基本的にTiDB Grafana監視ダッシュボードのメトリックと一致しています。モジュールに異常が見つかった場合は、TiDB Grafanaで詳細な監視情報を確認できます。
また、このレポートのメトリックTOTAL_TIMEとTOTAL_COUNT Prometheus から読み取ったデータを監視しているため、統計に計算上の不正確さが存在する可能性があります。
このレポートの各部分は次のように紹介されています。
基本情報
診断時間範囲
診断レポートを生成する時間範囲には、開始時刻と終了時刻が含まれます。

クラスタハードウェア情報
クラスタハードウェア情報には、クラスター内の各サーバーの CPU、メモリ、ディスクなどの情報が含まれます。

上記の表のフィールドの説明は次のとおりです。
HOST:サーバーの IP アドレス。INSTANCE:サーバーにデプロイされているインスタンスの数。たとえば、pd * 1サーバーに PD インスタンスが 1 つデプロイされていることを意味します。4tidb * 2 pd * 1、サーバーに TiDB インスタンスが 2 つと PD インスタンスが 1 つデプロイされていることを意味します。CPU_CORES:サーバーの CPU コア数 (物理コアまたは論理コア) を示します。MEMORY:サーバーのメモリサイズを示します。単位はGBです。DISK:サーバーのディスクサイズを示します。単位はGBです。UPTIME:サーバーの稼働時間。単位は日です。
クラスタトポロジ情報
表Cluster Infoはクラスタトポロジ情報を示しています。この表の情報はTiDB 情報スキーマ.クラスタ情報システムテーブルから取得されています。

上記の表のフィールドの説明は次のとおりです。
TYPE: ノードタイプ。INSTANCE: インスタンス アドレス (IP:PORT形式の文字列)。STATUS_ADDRESS: HTTP API サービス アドレス。VERSION: 対応するノードのセマンティック バージョン番号。GIT_HASH: ノード バージョンをコンパイルするときの Git コミット ハッシュ。2 つのノードが完全に一貫したバージョンであるかどうかを識別するために使用されます。START_TIME: 対応するノードの開始時刻。UPTIME: 対応するノードの稼働時間。
診断情報
TiDBには自動診断結果が組み込まれています。各フィールドの説明については、 情報スキーマ.検査結果システムテーブルを参照してください。
ロード情報
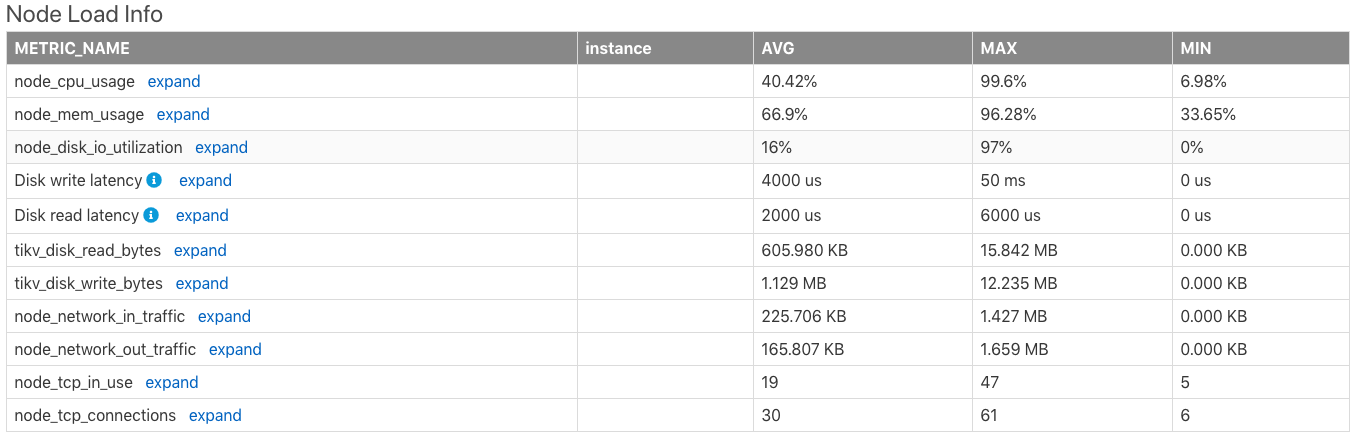
ノード負荷情報
Node Load Infoテーブルには、時間範囲内でのサーバーの以下のメトリックの平均値 (AVG)、最大値 (MAX)、最小値 (MIN) を含む、サーバーノードの負荷情報が表示されます。
- CPU使用率(最大値は
100%) - メモリ使用量
- ディスクI/O使用量
- ディスク書き込みレイテンシー
- ディスク読み取りレイテンシー
- ディスク読み取りバイト数/秒
- 1秒あたりのディスク書き込みバイト数
- ノードネットワークが1分あたりに受信したバイト数
- ノードネットワークから1分あたりに送信されるバイト数
- ノードで使用されているTCP接続の数
- ノードのすべてのTCP接続の数
インスタンスのCPU使用率
表Instance CPU Usageは、各TiDB/PD/TiKVプロセスのCPU使用率の平均値(AVG)、最大値(MAX)、最小値(MIN)を示しています。プロセスの最大CPU使用率は100% * the number of CPU logical coresです。

インスタンスのメモリ使用量
表Instance Memory Usageは、各 TiDB/PD/TiKV プロセスが占有するメモリバイトの平均値 (AVG)、最大値 (MAX)、最小値 (MIN) が表示されます。

TiKV スレッド CPU 使用率
表TiKV Thread CPU Usageは、TiKVにおける各モジュールスレッドのCPU使用率の平均値(AVG)、最大値(MAX)、最小値(MIN)を示しています。プロセスの最大CPU使用率は100% * the thread count of the corresponding configurationです。
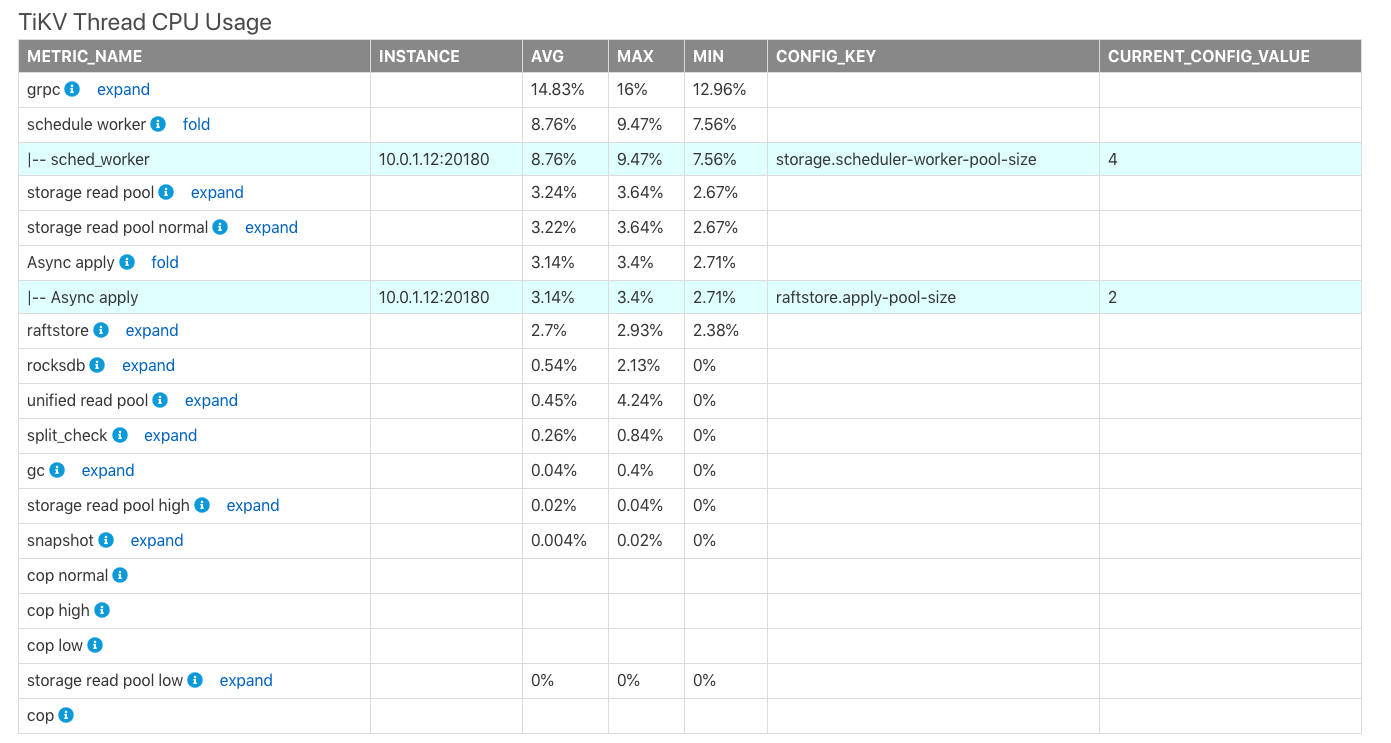
上の表では、
CONFIG_KEY: 対応するモジュールの関連スレッド構成。CURRENT_CONFIG_VALUE: レポートが生成された時点の構成の現在の値。
TiDB/PD Goroutines Count
表TiDB/PD Goroutines Countは、TiDBまたはPDゴルーチンの数の平均値(AVG)、最大値(MAX)、最小値(MIN)を示しています。ゴルーチンの数が2,000を超えると、プロセスの同時実行性が高くなりすぎて、全体的なリクエストレイテンシーに影響を与えます。

概要情報
各コンポーネントの消費時間
表Time Consumed by Each Componentは、クラスター内のTiDB、PD、TiKVモジュールの監視対象消費時間と時間比率を示しています。デフォルトの時間単位は秒です。この表を使用すると、どのモジュールがより多くの時間を消費しているかを素早く特定できます。
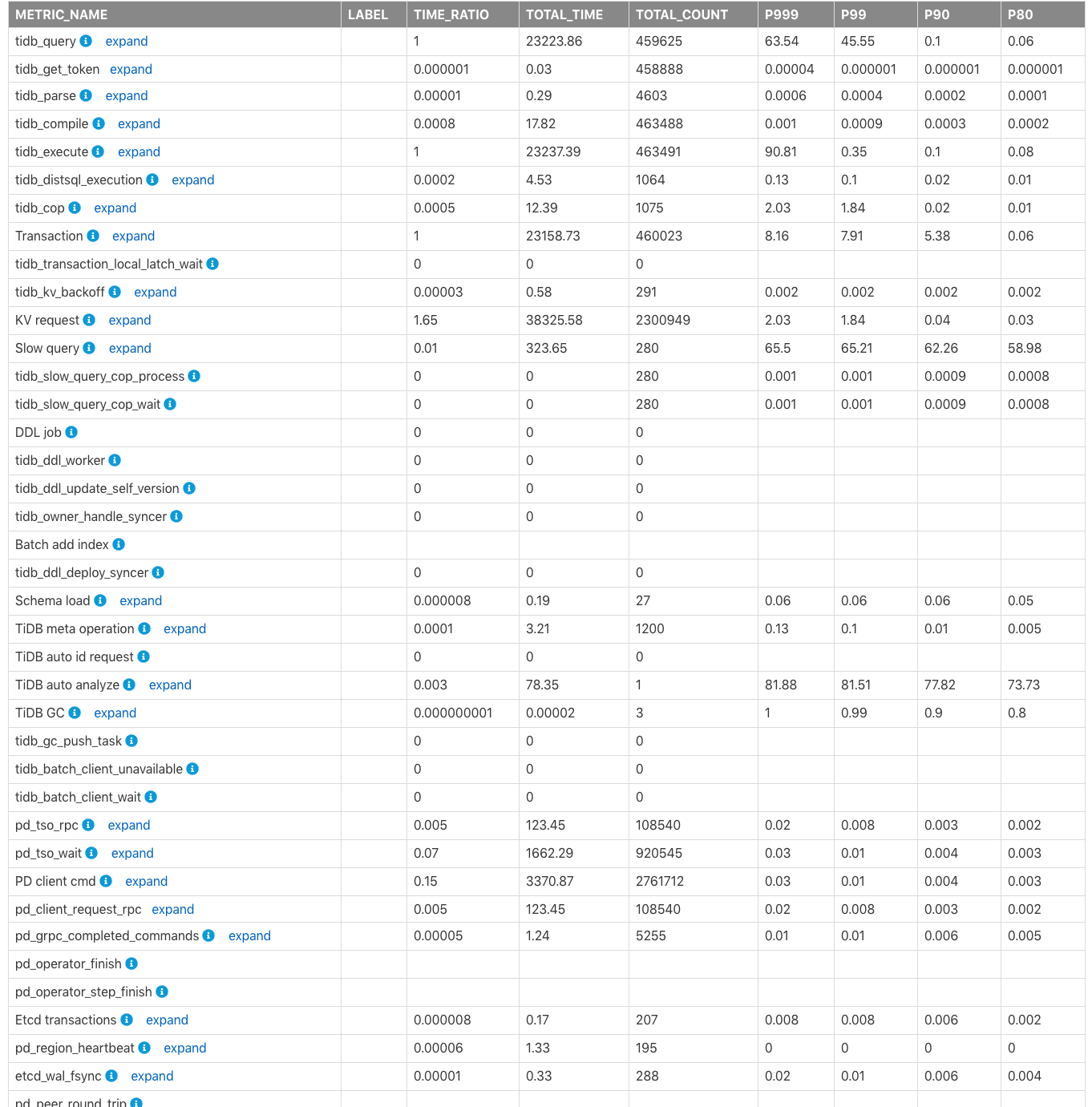
上記の表の列のフィールドは次のように説明されます。
METRIC_NAME: 監視メトリックの名前。Label: 監視メトリックのラベル情報。展開をクリックすると、メトリックの各ラベルの詳細な監視情報が表示されます。TIME_RATIO: この監視メトリックによって消費された合計時間と、監視行の合計時間の比率(TIME_RATIOは1です。たとえば、kv_requestの合計消費時間はtidb_queryの1.65倍(つまり38325.58/23223.86)です。KVリクエストは同時に実行されるため、すべてのKVリクエストの合計時間は、クエリの合計実行時間(tidb_query)を超える可能性があります。TOTAL_TIME: この監視メトリックによって消費された合計時間。TOTAL_COUNT: この監視メトリックが実行された合計回数。P999: この監視メトリックの最大 P999 時間。P99: この監視メトリックの最大 P99 時間。P90: この監視メトリックの最大 P90 時間。P80: この監視メトリックの最大 P80 時間。
次の画像は、上記の監視メトリックにおける関連モジュールの時間消費の関係を示しています。
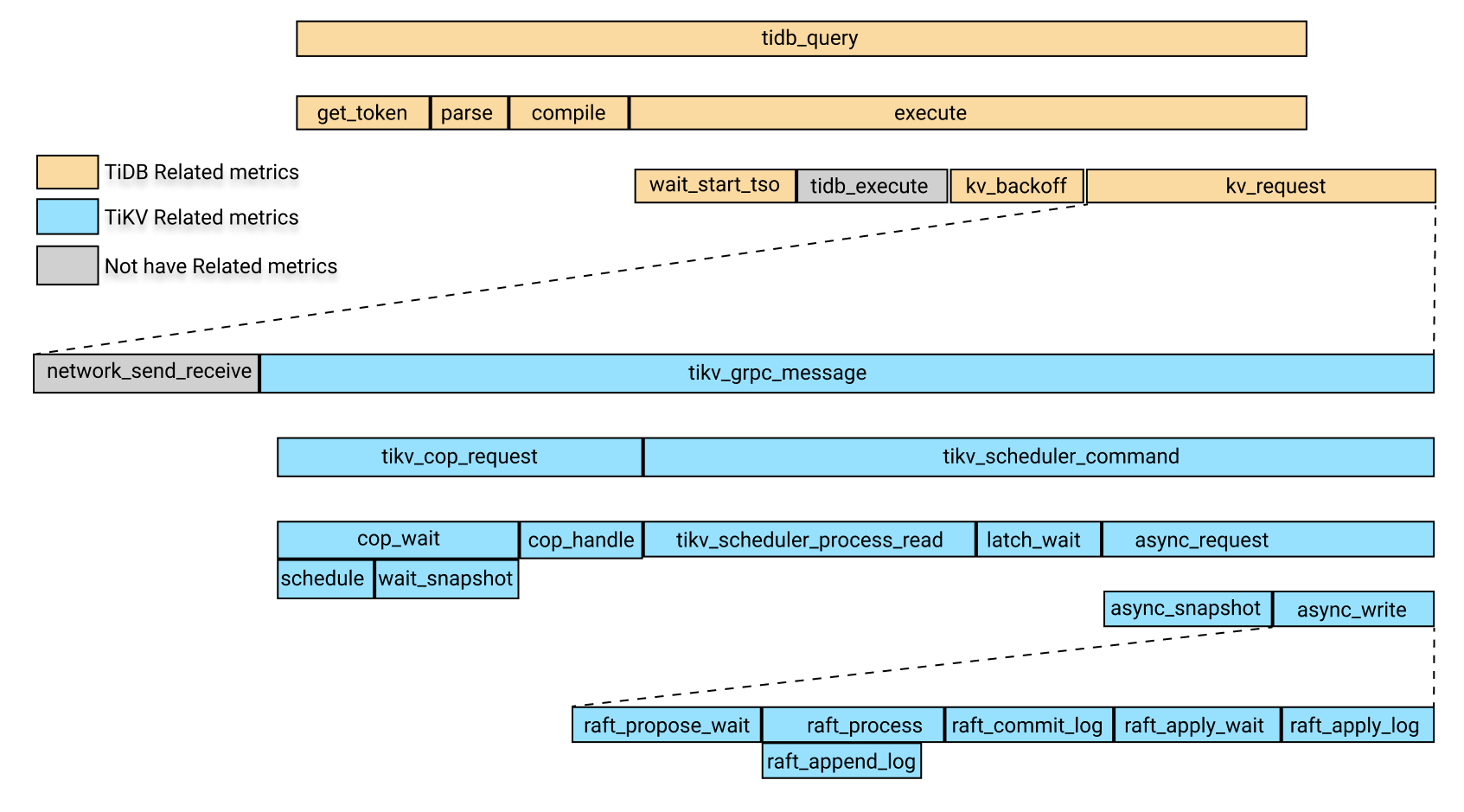
上の画像では、黄色のボックスは TiDB 関連の監視メトリックです。青色のボックスは TiKV 関連の監視メトリックであり、灰色のボックスは一時的に特定の監視メトリックに対応していません。
上の画像では、時間消費量tidb_queryには次の 4 つの部分が含まれます。
get_tokenparsecompileexecute
execute回には次の部分が含まれます。
wait_start_tso- 現在監視されていないTiDBレイヤーでの実行時間
- KVリクエスト時間
KV_backoff時間、これはKVリクエストが失敗した後のバックオフの時間です
上記の部分のうち、KV 要求時間には次の部分が含まれます。
- ネットワークのリクエスト送受信にかかった時間です。現在、この項目の監視指標はありません。KVリクエスト時間から
tikv_grpc_message差し引くことで、この項目のおおよその見積もりが可能です。 - 消費時間
tikv_grpc_message。
上記の部品のうち、 tikv_grpc_message回の消費量に含まれる部品は以下のとおりです。
コプロセッサー要求の消費時間。これは、COPタイプの要求の処理を指します。この消費時間には、以下の部分が含まれます。
tikv_cop_wait: リクエスト キューによって消費された時間。Coprocessor handle:コプロセッサー要求の処理に費やされた時間。
tikv_scheduler_command時間の消費で、次の部分が含まれます。tikv_scheduler_processing_read: 読み取り要求の処理に費やされた時間。- スナップショットを
tikv_storage_async_requestで取得するのにかかった時間 (スナップショットはこの監視メトリックのラベルです)。 - 書き込みリクエストの処理にかかる時間。この時間消費には以下の部分が含まれます。
tikv_scheduler_latch_wait: ラッチを待機するのにかかる時間。tikv_storage_async_requestの書き込みの消費時間 (書き込みはこの監視メトリックのラベルです)。
上記のメトリックのうち、 tikv_storage_async_requestの書き込み時間の消費は、次の部分を含むRaft KV の書き込み時間の消費を指します。
tikv_raft_propose_waittikv_raft_process、主にtikv_raft_append_log含むtikv_raft_commit_logtikv_raft_apply_waittikv_raft_apply_log
TOTAL_TIME 、P999 時間、および P99 時間を使用して、上記の時間消費間の関係に従ってどのモジュールがより長い時間を消費しているかを判断し、関連する監視メトリックを確認することができます。
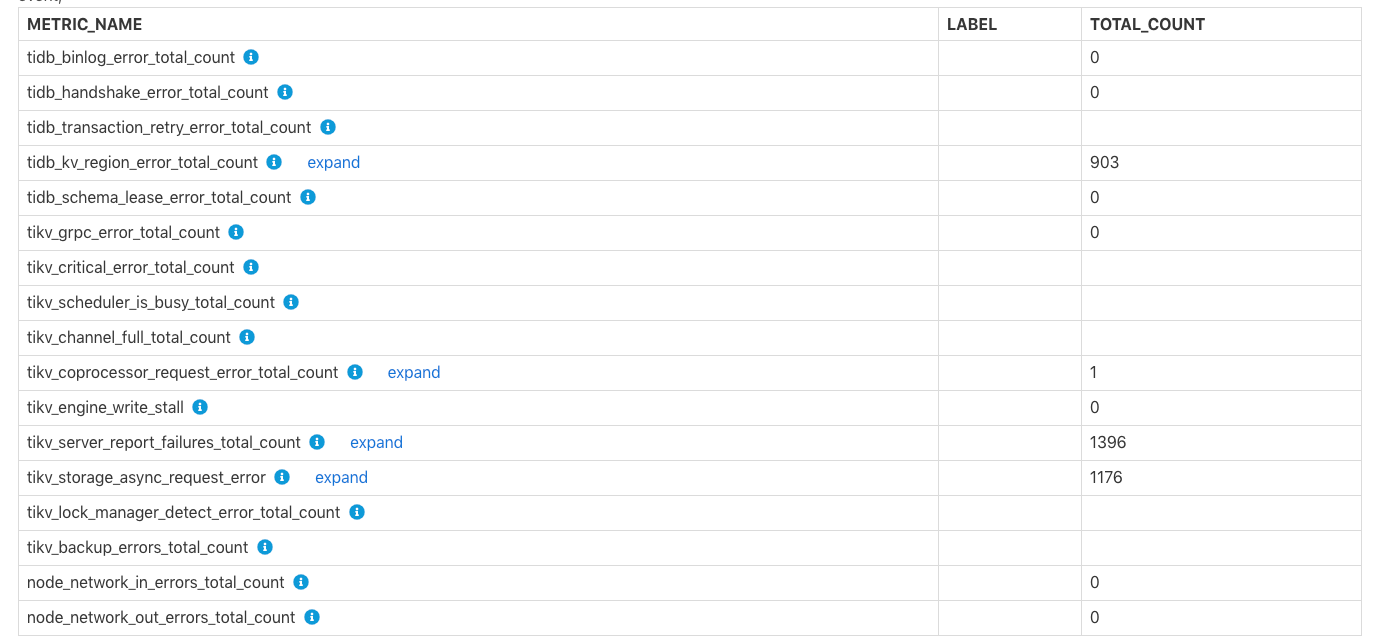
各コンポーネントでエラーが発生しました
表Errors Occurred in Each Componentは、TiDBとTiKVにおけるエラーの総数を示しています。binlogへのbinlog失敗、 tikv server is busyなどです。各エラーの具体的な意味についてはTiKV channel full行のコメントtikv write stall参照してください。
特定の TiDB/PD/TiKV 監視情報
この部分には、TiDB、PD、または TiKV のより具体的な監視情報が含まれています。
TiDB関連の監視情報
TiDBコンポーネントの消費時間
この表には、各 TiDB モジュールで消費された時間と各時間消費の比率が表示されます。これは概要の表time consumeと似ていますが、この表のラベル情報はより詳細です。
TiDB サーバー接続
この表は、各 TiDB インスタンスのクライアント接続の数を示しています。
TiDBトランザクション
この表は、トランザクション関連の監視メトリックを示しています。
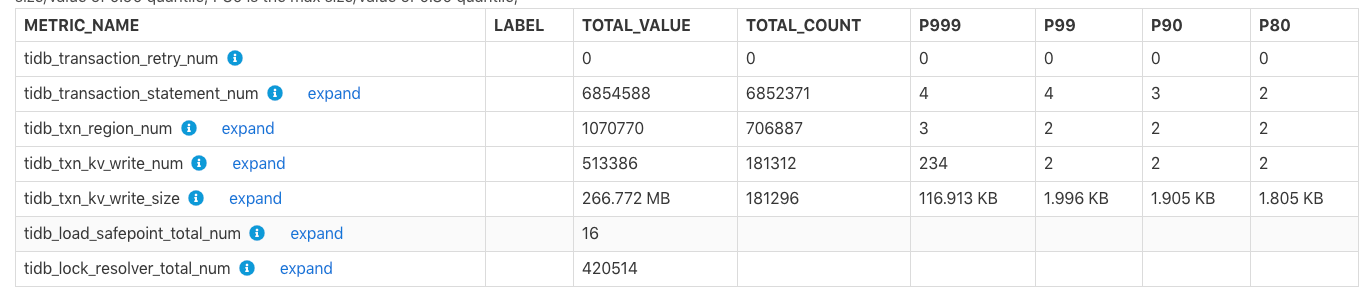
TOTAL_VALUE: レポート時間範囲内のすべての値の合計 (SUM)。TOTAL_COUNT: この監視メトリックの発生回数の合計。P999: この監視メトリックの最大の P999 値。P99: この監視メトリックの最大 P99 値。P90: この監視メトリックの最大 P90 値。P80: この監視メトリックの最大 P80 値。
例:
上記の表では、レポート時間範囲内で、 tidb_txn_kv_write_size :KV 書き込みトランザクションの合計は約 181,296 件で、KV 書き込みの合計サイズは 266.772 MB です。そのうち、KV 書き込みの単一トランザクションの最大 P999、P99、P90、P80 値は、116.913 KB、1.996 KB、1.905 KB、1.805 KB です。
DDLオーナー

上記の表は、 2020-05-21 14:40:00から5ノード目にあるクラスタのDDL OWNERノード10.0.1.13:10080であることを示しています。所有者が変更された場合、上記の表には複数のデータ行が存在し、 Min_Time列は対応する既知の所有者の最小時間を示します。
TiDB のその他の監視テーブルは次のとおりです。
- 統計情報: TiDB 統計情報の関連する監視メトリックを表示します。
- スロークエリ上位 10 件: レポートの時間範囲内でスロークエリ上位 10 件の情報を表示します。
- ダイジェストによるトップ 10 のスロークエリ グループ: SQL フィンガープリントに従って集計された、レポートの時間範囲内の上位 10 件のスロークエリ情報を表示します。
- 異なるプランを持つスロークエリ: レポートの時間範囲内で実行プランが変更される SQL ステートメント。
PD関連のモニタリング情報
PD モジュールの監視情報に関連するテーブルは次のとおりです。
Time Consumed by PD Component: PD 内の関連モジュールの監視メトリックによって消費された時間。Blance Leader/Region:tikv_note_1からスケジュールアウトされたリーダーの数や、スケジュールインされたリーダーの数など、レポート時間範囲内でクラスター内でbalance-regionとbalance leaderの監視情報が発生しました。Cluster Status: TiKV ノードの合計数、クラスターの合計ストレージ容量、リージョンの数、オフラインの TiKV ノードの数などのクラスターのステータス情報。Store Status:リージョンスコア、リーダー スコア、リージョン/リーダーの数など、各 TiKV ノードのステータス情報を記録します。Etcd Status: PD 内の etcd 関連情報。
TiKV関連の監視情報
TiKV モジュールの監視情報に関連するテーブルは次のとおりです。
Time Consumed by TiKV Component: TiKV 内の関連モジュールによって消費された時間。Time Consumed by RocksDB: TiKV で RocksDB によって消費された時間。TiKV Error: TiKV 内の各モジュールに関連するエラー情報。TiKV Engine Size: TiKV 内の各ノード上の列ファミリーの保存データのサイズ。Coprocessor Info: TiKV 内のコプロセッサーモジュールに関連する監視情報。Raft Info: TiKV 内のRaftモジュールの監視情報。Snapshot Info: TiKV 内のスナップショット関連の監視情報。GC Info: TiKV 内のガベージ コレクション (GC) 関連の監視情報。Cache Hit: TiKV 内の RocksDB の各キャッシュのヒット率情報。
コンフィグレーション情報
設定情報では、一部のモジュールの設定値はレポート期間内に表示されます。ただし、これらのモジュールの他の設定値については履歴値を取得できないため、表示される値はレポート生成時点の現在の値となります。
レポート時間範囲内で、次のテーブルにはレポート時間範囲の開始時間に値が設定される項目が含まれます。
Scheduler Initial Config: レポートの開始時刻における PD スケジュール関連構成の初期値。TiDB GC Initial Config: レポート開始時のTiDB GC関連構成の初期値TiKV RocksDB Initial Config: レポート開始時のTiKV RocksDB関連設定の初期値TiKV RaftStore Initial Config: レポート開始時の TiKV RaftStore 関連設定の初期値
レポートの時間範囲内で、一部の構成が変更された場合、次のテーブルには変更された一部の構成のレコードが含まれます。
Scheduler Config Change HistoryTiDB GC Config Change HistoryTiKV RocksDB Config Change HistoryTiKV RaftStore Config Change History
例:

上記の表は、レポート時間範囲内でleader-schedule-limit構成パラメータが変更されたことを示しています。
2020-05-22T20:00:00+08:00: レポートの開始時刻では、構成値leader-schedule-limitは4です。これは、構成が変更されたことを意味するのではなく、レポート時間範囲の開始時刻では、構成値が4あることを意味します。2020-05-22T20:07:00+08:00:leader-schedule-limit構成値は8であり、この構成の値が2020-05-22T20:07:00+08:00付近で変更されたことを示します。
次の表は、レポートが生成された時点での TiDB、PD、および TiKV の現在の構成を示しています。
TiDB's Current ConfigPD's Current ConfigTiKV's Current Config
比較レポート
2つの期間の比較レポートを生成できます。レポートの内容は、2つの期間の差異を示す比較列が追加されていることを除けば、単一の期間のレポートと同じです。以下のセクションでは、比較レポートに含まれるいくつかの独自のテーブルと、比較レポートの表示方法について説明します。
まず、基本情報のCompare Report Time Rangeレポートには、比較のための 2 つの時間範囲が表示されます。

上記の表では、 t1正常な時間範囲、つまり基準時間範囲です。3 t2異常な時間範囲です。
スロークエリに関連するテーブルは次のように表示されます。
Slow Queries In Time Range t2:t2にのみ表示され、t1では表示されないスロークエリを表示します。Top 10 slow query in time range t1:t1期間中のスロークエリ トップ10。Top 10 slow query in time range t2:t2期間中のスロークエリ トップ10。
DIFF_RATIOの紹介
このセクションでは、 Instance CPU Usage表を例にDIFF_RATIO紹介します。

t1.AVG、t1.MAX、t1.Min、t1における CPU 使用率の平均値、最大値、最小値です。t2.AVGt2.MAXt2.Mint2中のCPU使用率の平均値、最大値、最小値です。AVG_DIFF_RATIOはt1とt2間の平均値のDIFF_RATIOです。MAX_DIFF_RATIOはt1とt2間の最大値のDIFF_RATIOです。MIN_DIFF_RATIOはt1とt2間の最小値のDIFF_RATIOです。
DIFF_RATIO : 2つの時間範囲の差の値を示します。以下の値があります。
- 監視メトリックの値が
t2以内のみで、t1以内の値がない場合は、DIFF_RATIOの値は1なります。 - 監視メトリックの値が
t1内のみにあり、t2時間範囲内に値がない場合は、DIFF_RATIOの値は-1なります。 t2の値がt1より大きい場合、DIFF_RATIO=(t2.value / t1.value)-1なります。t2の値がt1の値より小さい場合、DIFF_RATIO=1-(t1.value / t2.value)
たとえば、上の表では、 t2のtidbノードの平均 CPU 使用率はt1の 2.02 倍、つまり2.02 = 1240/410-1です。
最大異なるアイテムテーブル
表Maximum Different Itemは、2つの時間範囲の監視指標を比較し、監視指標の差に応じて並べ替えています。この表を使用すると、2つの時間範囲でどの監視指標の差が最も大きいかを素早く確認できます。次の例をご覧ください。
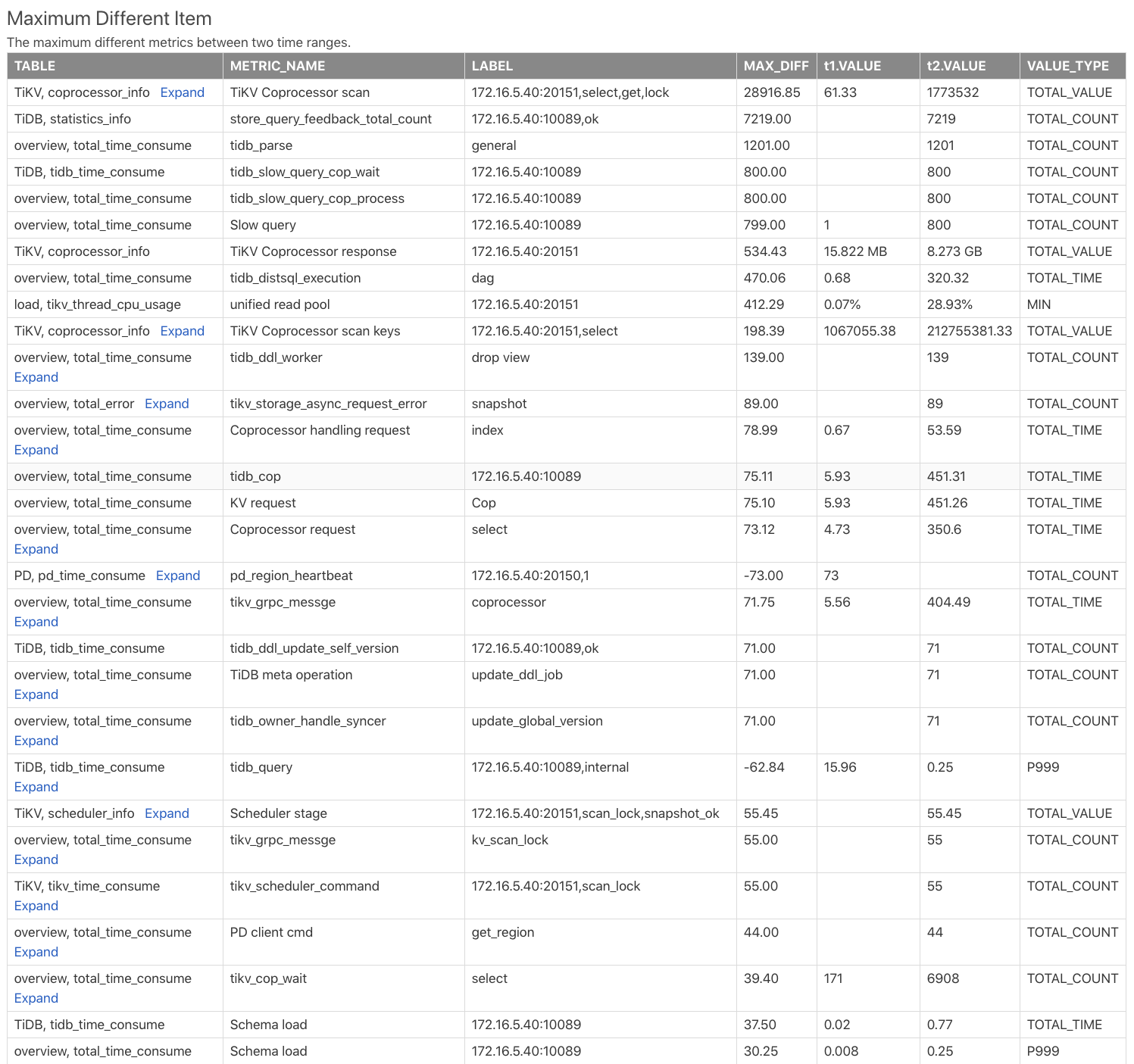
Table: この監視メトリックが比較レポート内のどのテーブルから取得されるかを示します。たとえば、TiKV, coprocessor_infoTiKVコンポーネントのcoprocessor_infoのテーブルを示します。METRIC_NAME: 監視メトリック名。2expandクリックすると、メトリックの異なるラベルの比較が表示されます。LABEL: 監視メトリックに対応するラベル。例えば、監視メトリックTiKV Coprocessor scanには、TiKVアドレス、リクエストタイプ、操作タイプ、操作カラムファミリーを表す2つのラベル(instance、req、tag、sql_type)があります。MAX_DIFF:t1.VALUEとt2.VALUEのDIFF_RATIO計算した結果の差の値。
上記の表から、 t2時間範囲ではt1時間範囲よりもコプロセッサー要求がはるかに多く、 t2の TiDB の SQL 解析時間が大幅に長くなっていることがわかります。