ホットスポットの問題のトラブルシューティング
このドキュメントでは、読み取りおよび書き込みホットスポットの問題を特定して解決する方法について説明します。
分散データベースであるTiDBは、アプリケーションの負荷を異なるコンピューティングノードまたはstorageノードに可能な限り均等に分散し、サーバーリソースをより有効に活用する負荷分散メカニズムを備えています。しかし、特定のシナリオでは、一部のアプリケーションの負荷が適切に分散されず、パフォーマンスに影響を与え、単一の高負荷ポイント(ホットスポット)が形成される可能性があります。
TiDBは、ホットスポットのトラブルシューティング、解決、または回避のための包括的なソリューションを提供します。負荷ホットスポットを分散することで、QPSの向上やレイテンシーの削減など、全体的なパフォーマンスを向上させることができます。
一般的なホットスポット
このセクションでは、TiDB エンコーディング ルール、テーブル ホットスポット、およびインデックス ホットスポットについて説明します。
TiDBエンコーディングルール
TiDBは各テーブルにTableID、各インデックスにIndexID、各行にRowIDを割り当てます。デフォルトでは、テーブルが整数の主キーを使用している場合、主キーの値がRowIDとして扱われます。これらのIDのうち、TableIDはクラスター全体で一意であり、IndexIDとRowIDはテーブル内で一意です。これらのIDの型はすべてint64です。
各データ行は、次の規則に従ってキーと値のペアとしてエンコードされます。
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1, col2, col3, col4]
キーのtablePrefixとrecordPrefixSep特定の文字列定数であり、KV 空間内の他のデータと区別するために使用されます。
インデックス データの場合、キーと値のペアは次の規則に従ってエンコードされます。
Key: tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue
Value: rowID
インデックス データには、一意インデックスと非一意インデックスの 2 種類があります。
一意のインデックスの場合は、上記のコーディング規則に従うことができます。
非一意インデックスの場合、このエンコーディングでは一意キーを構築できません。これは、同じインデックスの
tablePrefix{TableID}_indexPrefixSep{IndexID}番目は同じですが、複数の行のColumnsValue番目は同じになる可能性があるためです。非一意インデックスのエンコーディング規則は次のとおりです。Key: tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_rowID Value: null
テーブルホットスポット
TiDBのコーディングルールによれば、同一テーブルのデータはTableIDの先頭で始まる範囲に収められ、RowID値の順序で並べられます。テーブルへの挿入時にRowID値が増加する場合、挿入された行は末尾にのみ追加されます。Regionは一定のサイズに達すると分割されますが、その後も範囲の末尾にのみ追加できます。1 INSERT操作は1つのリージョンに対してのみ実行でき、ホットスポットを形成します。
一般的な自動インクリメント主キーは、順次増加します。主キーが整数型の場合、デフォルトで主キーの値がRowIDとして使用されます。この場合、RowIDは順次増加し、 INSERT操作が多数発生すると、テーブルの書き込みホットスポットが発生します。
一方、TiDBのRowIDもデフォルトで自動増分されます。主キーが整数型でない場合は、書き込みホットスポットの問題が発生する可能性があります。
さらに、データ書き込み(新規作成されたテーブルまたはパーティション)またはデータ読み取り(読み取り専用シナリオにおける定期的な読み取りホットスポット)のプロセス中にホットスポットが発生した場合、テーブル属性を使用してリージョンのマージ動作を制御できます。詳細については、 テーブル属性を使用してリージョン結合の動作を制御する参照してください。
インデックスホットスポット
インデックスのホットスポットはテーブルのホットスポットに似ています。一般的なインデックスのホットスポットは、時間順に単調に増加するフィールド、または多数の重複値が含まれるINSERTで発生します。
ホットスポットの問題を特定する
パフォーマンスの問題は必ずしもホットスポットが原因であるとは限らず、複数の要因が絡み合っている可能性があります。問題のトラブルシューティングを行う前に、ホットスポットに関連しているかどうかを確認してください。
書き込みホットスポットを判断するには、 TiKV トラブルシューティング監視パネルでHot Write を開き、任意の TiKV ノードのRaftstore CPU メトリック値が他のノードの値よりも大幅に高いかどうかを確認します。
読み取りホットスポットを判断するには、 TiKV 詳細監視パネルでThread_CPUを開き、いずれかの TiKV ノードのコプロセッサ CPU メトリック値が特に高いかどうかを確認します。
TiDBダッシュボードを使用してホットスポットテーブルを見つける
TiDBダッシュボードのKey Visualizer機能は、ホットスポットのトラブルシューティング範囲をテーブルレベルに絞り込むのに役立ちます。以下は、 Key Visualizerで表示されたサーマルダイアグラムの例です。グラフの横軸は時間、縦軸は各種テーブルとインデックスです。色が明るいほど負荷が大きいことを示します。ツールバーで読み取りフローと書き込みフローを切り替えることができます。
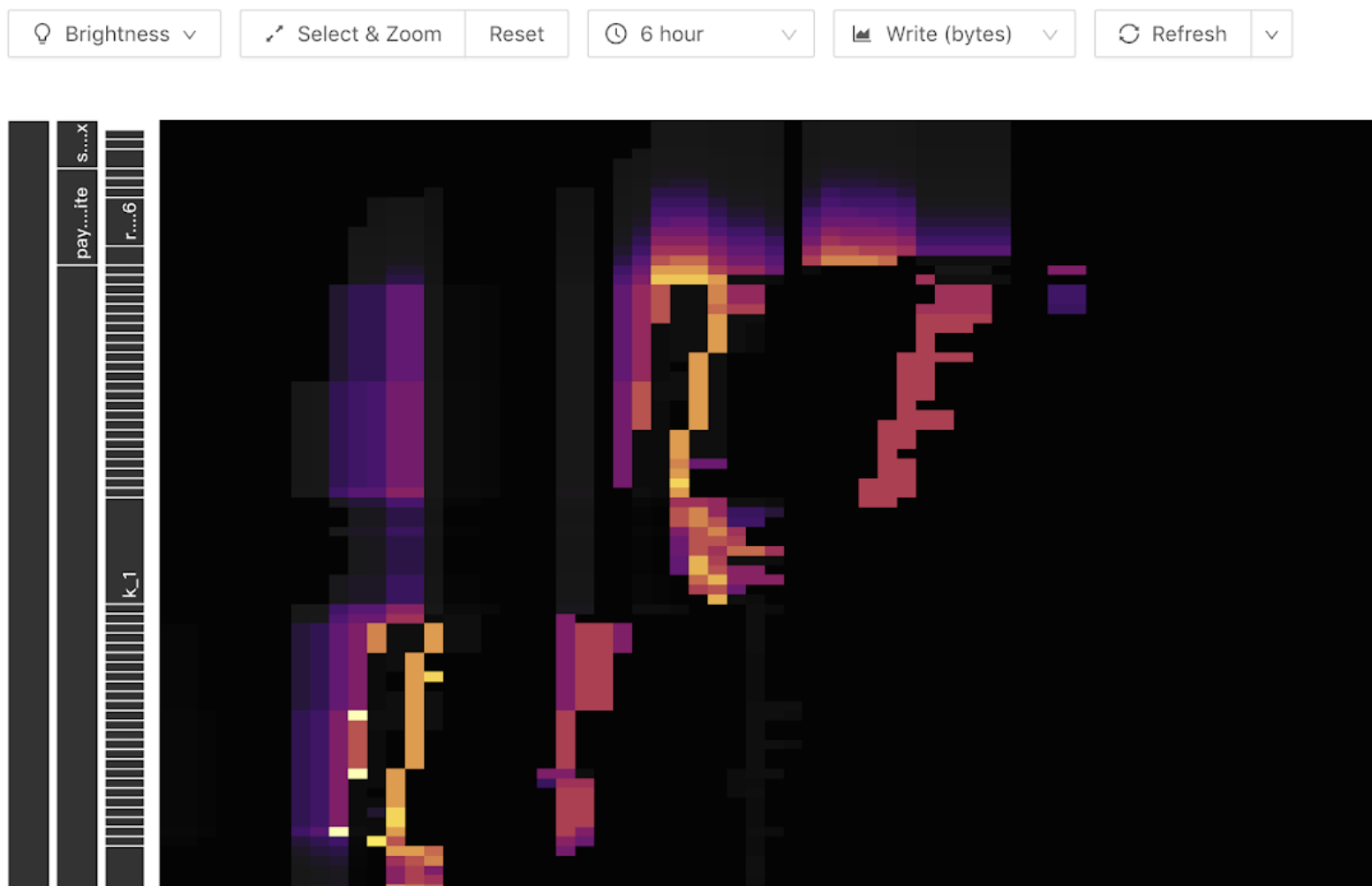
書き込みフローグラフに、以下のような明るい斜線(上向きまたは下向き)が現れることがあります。書き込みは最後にのみ現れるため、テーブルのリージョン数が増えるにつれて、梯子状の線が現れます。これは、このテーブルに書き込みホットスポットが発生していることを示しています。

読み取りホットスポットの場合、一般的に温度図に明るい水平線が表示されます。これは通常、アクセス回数が多い小さなテーブルによって発生し、以下のように示されます。

明るいブロックにマウスを合わせると、どのテーブルまたはインデックスの負荷が高いかを確認できます。例:
SHARD_ROW_ID_BITSを使用してホットスポットを処理する
非クラスター化主キーまたは主キーのないテーブルの場合、TiDBは暗黙的な自動インクリメントRowIDを使用します。1 INSERT操作が多数存在する場合、データは単一のリージョンに書き込まれるため、書き込みホットスポットが発生します。
SHARD_ROW_ID_BITS設定すると、行 ID が分散されて複数のリージョンに書き込まれるため、書き込みホットスポットの問題を軽減できます。
SHARD_ROW_ID_BITS = 4 # Represents 16 shards.
SHARD_ROW_ID_BITS = 6 # Represents 64 shards.
SHARD_ROW_ID_BITS = 0 # Represents the default 1 shard.
ステートメントの例:
CREATE TABLE: CREATE TABLE t (c int) SHARD_ROW_ID_BITS = 4;
ALTER TABLE: ALTER TABLE t SHARD_ROW_ID_BITS = 4;
SHARD_ROW_ID_BITSの値は動的に変更できます。変更された値は、新しく書き込まれたデータにのみ適用されます。
CLUSTERED型の主キーを持つテーブルの場合、TiDBはテーブルの主キーをRowIDとして使用します。この場合、 SHARD_ROW_ID_BITSオプションはRowIDの生成ルールを変更するため使用できません。5 NONCLUSTEREDの主キーを持つテーブルの場合、TiDBは自動的に割り当てられた64ビット整数をRowIDとして使用します。この場合、 SHARD_ROW_ID_BITS CLUSTEREDが使用できます。9型の主キーの詳細については、 クラスター化インデックスを参照してください。
以下の2つの負荷図は、主キーを持たない2つのテーブルでSHARD_ROW_ID_BITS使用してホットスポットを分散させた場合を示しています。最初の図はホットスポットを分散させる前の状況を示し、2番目の図はホットスポットを分散させた後の状況を示しています。
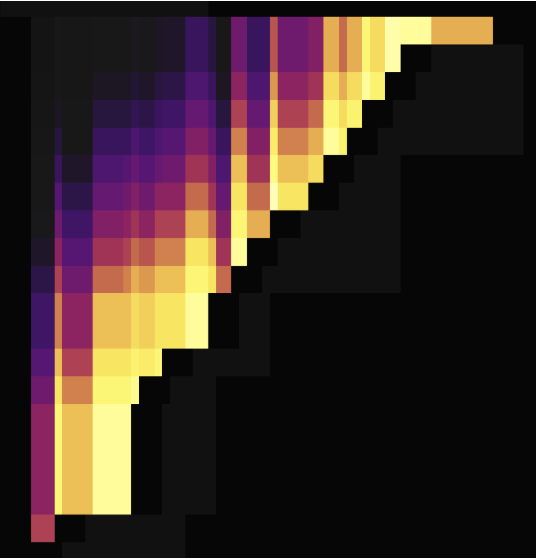
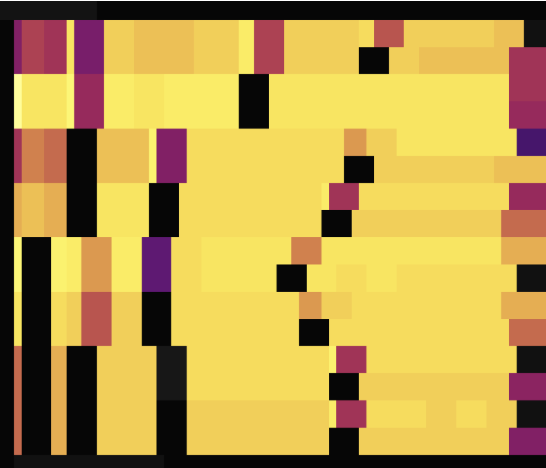
上記の負荷図に示すように、設定SHARD_ROW_ID_BITSより前では、負荷のホットスポットが単一のリージョンに集中していました。設定SHARD_ROW_ID_BITSより後では、負荷のホットスポットが分散するようになります。
AUTO_RANDOMを使用して自動増分主キー ホットスポット テーブルを処理する
自動インクリメント主キーによってもたらされる書き込みホットスポットを解決するには、 AUTO_RANDOM使用して、自動インクリメント主キーを持つホットスポット テーブルを処理します。
この機能を有効にすると、TiDB は書き込みホットスポットを分散させる目的を達成するために、ランダムに分散され、重複のない (スペースが使い果たされる前に) 主キーを生成します。
TiDB によって生成される主キーは自動増分主キーではなくなり、 LAST_INSERT_ID()使用して前回割り当てられた主キー値を取得できることに注意してください。
この機能を使用するには、 CREATE TABLEステートメントのAUTO_INCREMENTをAUTO_RANDOMに変更してください。この機能は、主キーの一意性のみを保証する必要がある非アプリケーションシナリオに適しています。
例えば:
CREATE TABLE t (a BIGINT PRIMARY KEY AUTO_RANDOM, b varchar(255));
INSERT INTO t (b) VALUES ("foo");
SELECT * FROM t;
+------------+---+
| a | b |
+------------+---+
| 1073741825 | b |
+------------+---+
SELECT LAST_INSERT_ID();
+------------------+
| LAST_INSERT_ID() |
+------------------+
| 1073741825 |
+------------------+
以下の2つの負荷図は、 AUTO_INCREMENT ~ AUTO_RANDOMを変更してホットスポットを分散させる前と後の状況を示しています。最初の図ではAUTO_INCREMENT使用し、2番目の図ではAUTO_RANDOM使用しています。
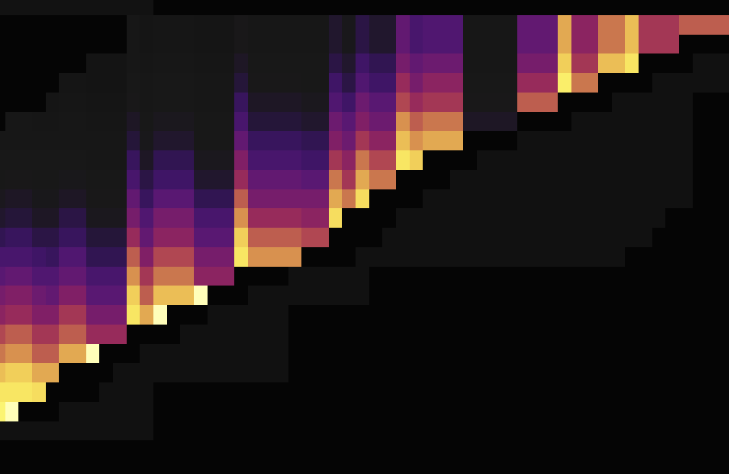

上記の負荷図に示されているように、 AUTO_INCREMENT代わりにAUTO_RANDOM使用すると、ホットスポットを適切に分散できます。
詳細については自動ランダム参照してください。
小さなテーブルホットスポットの最適化
TiDBのコプロセッサーキャッシュ機能は、計算結果のキャッシュのプッシュダウンをサポートします。この機能を有効にすると、TiDBはTiKVにプッシュダウンされる計算結果をキャッシュします。この機能は、小さなテーブルの読み取りホットスポットに適しています。
詳細についてはコプロセッサーキャッシュ参照してください。
参照:
散在する読み取りホットスポット
読み取りホットスポットが発生すると、ホットスポット TiKV ノードは読み取り要求を時間内に処理できず、読み取り要求がキューイングされます。ただし、この時点ですべての TiKV リソースが使い果たされるわけではありません。レイテンシーを短縮するために、TiDB v7.1.0 では負荷ベースのレプリカ読み取り機能が導入されました。この機能により、TiDB はホットスポット TiKV ノードでキューイングすることなく、他の TiKV ノードからデータを読み取ることができます。読み取り要求のキューの長さは、 tidb_load_based_replica_read_thresholdシステム変数を使用して制御できます。リーダーノードの推定キュー時間がこのしきい値を超えると、TiDB はフォロワーノードからのデータの読み取りを優先します。この機能により、読み取りホットスポットが発生すると、読み取りホットスポットを分散させない場合と比較して、読み取りスループットが 70% ~ 200% 向上します。
TiKV MVCC インメモリ エンジンを使用して、高い MVCC 読み取り増幅によって発生する読み取りホットスポットを軽減します。
GCの履歴MVCCデータの保持期間が長すぎる場合、またはレコードが頻繁に更新または削除される場合、多数のMVCCバージョンをスキャンすることで読み取りホットスポットが発生する可能性があります。このようなホットスポットを軽減するには、 TiKV MVCC インメモリエンジン機能を有効にします。