TiFlash のパフォーマンス分析とチューニング方法
このドキュメントでは、 TiFlash のリソース使用率と主要なパフォーマンス指標について紹介します。パフォーマンス概要ダッシュボードのTiFlashパネルから、 TiFlashクラスターのパフォーマンスを監視および評価できます。
TiFlashクラスタのリソース利用率
次の 3 つのメトリックを使用すると、 TiFlashクラスターのリソース使用率を簡単に取得できます。
- CPU: TiFlashインスタンスごとの CPU 使用率。
- メモリ: TiFlashインスタンスごとのメモリ使用量。
- IO 使用率: TiFlashインスタンスごとの IO 使用率。
例: CH-benCHmark ワークロードのリソース使用率
このTiFlashクラスターは2つのノードで構成され、各ノードは16コアと48GBのメモリで構成されています。CH-benCHmarkワークロードの実行中、CPU使用率は最大1500%、メモリ使用量は最大20GB、IO使用率は最大91%に達する可能性があります。これらの指標は、 TiFlashノードのリソースが飽和状態に近づいていることを示しています。

TiFlashパフォーマンスの主要指標
スループットメトリック
次のメトリックを使用して、 TiFlashのスループットを取得できます。
- MPP クエリ数: 各TiFlashインスタンスの MPP クエリ数の瞬間値。TiFlashTiFlashで処理する必要がある現在の MPP クエリ数 (処理中のクエリとスケジュール待ちのクエリを含む) を反映します。
- 要求 QPS: すべてのTiFlashインスタンスによって受信されたコプロセッサ要求の数。
run_mpp_task、およびmpp_establish_conndispatch_mpp_taskMPP 要求です。batch: バッチリクエストの数。cop: コプロセッサ インターフェイスを介して直接送信されるコプロセッサ要求の数。cop_execution: 現在実行中のコプロセッサ要求の数。remote_readremote_read_sentリモート読み取り関連のメトリックです。リモート読み取りの増加は通常remote_read_constructedシステムに問題があることを示しています。
- Executor QPS: すべてのTiFlashインスタンスが受信したリクエスト内の各タイプの DAG 演算子の数。1 はテーブル スキャン演算子、
table_scanselection選択演算子、aggregationは集約演算子、top_nは TopN 演算子、limitは制限演算子、joinは結合演算子、exchange_senderはデータ送信演算子、exchange_receiverデータ受信演算子です。
レイテンシメトリクス
次のメトリックを使用して、 TiFlashのレイテンシーを取得できます。
リクエスト期間の概要: すべてのTiFlashインスタンスにおけるすべてのリクエスト タイプの 1 秒あたりの合計処理期間の積み上げグラフを提供します。
リクエストのタイプが
run_mpp_task、dispatch_mpp_task、またはmpp_establish_conn場合、SQL文の実行がTiFlashに部分的または完全にプッシュダウンされたことを示します。これには通常、結合操作とデータ分散操作が含まれます。これはTiFlashで最も一般的なリクエストタイプです。リクエストのタイプが
cop場合、そのリクエストに関連するステートメントがTiFlashに完全にプッシュダウンされていないことを示します。通常、TiDB はデータアクセスとフィルタリングのために、テーブルフルスキャン演算子をTiFlashにプッシュダウンします。積み上げチャートでcop最も多く表示されるリクエストタイプになった場合は、それが妥当かどうかを確認する必要があります。- SQL ステートメントによってクエリされるデータの量が大きい場合、オプティマイザーはコスト モデルに従って、 TiFlash のフル テーブル スキャンの方がコスト効率が高いと見積もる場合があります。
- クエリ対象のテーブルのスキーマに適切なインデックスがない場合、クエリ対象のデータ量が少ない場合でも、オプティマイザーはクエリをTiFlashにプッシュダウンしてテーブル全体をスキャンするしかありません。このような場合、適切なインデックスを作成し、TiKVを介してデータにアクセスする方が効率的です。
要求期間: すべてのTiFlashインスタンス内の各 MPP およびコプロセッサ要求タイプの合計処理期間。これには平均レイテンシーと p99レイテンシーが含まれます。
リクエスト処理時間:
copとbatch copリクエストの実行開始から完了までの時間(待機時間を除く)。この指標は、平均レイテンシとP99レイテンシーを含む、copとbatch cop番目のリクエストにのみ適用されます。
例1: TiFlash MPPリクエストの処理時間の概要
次の図のワークロードでは、 run_mpp_taskとmpp_establish_conn要求が合計処理時間の大部分を占めており、要求のほとんどが実行のためにTiFlashに完全にプッシュダウンされる MPP タスクであることがわかります。
copリクエストの処理時間は比較的短いため、リクエストの一部はデータ アクセスとコプロセッサを介したフィルタリングのためにTiFlashにプッシュダウンされていることがわかります。

例2: TiFlash copリクエストが全体の処理時間の大部分を占める
次の図のワークロードでは、 copリクエストが全体の処理時間の大部分を占めています。この場合、SQL実行プランを確認することで、これらのcopリクエストが生成された理由を確認できます。

ラフト関連のメトリクス
次のメトリックを使用して、 TiFlashのRaftレプリケーション ステータスを取得できます。
Raft待機インデックス期間: すべてのTiFlashインスタンスのローカルリージョンインデックスが
read_indexになるまでの待機時間。これは、wait_index操作のレイテンシーを表します。この指標が高すぎる場合、TiKV からTiFlashへのデータレプリケーションに大きなレイテンシーがあることを示しています。考えられる原因は次のとおりです。- TiKV リソースが過負荷になっています。
- TiFlashリソース、特に IO リソースが過負荷になっています。
- TiKV とTiFlashの間にネットワークのボトルネックがあります。
Raftバッチ読み取りインデックス期間:すべてのTiFlashインスタンスのレイテンシーは
read_index。この指標が高すぎる場合、 TiFlashと TiKV 間のやり取りが遅いことを示しています。考えられる原因は以下のとおりです。- TiFlashリソースが過負荷になっています。
- TiKV リソースが過負荷になっています。
- TiFlashと TiKV の間にネットワークのボトルネックがあります。
IOスループットメトリック
次のメトリックを使用して、 TiFlashの IO スループットを取得できます。
インスタンスごとの書き込みスループット:各TiFlashインスタンスによって書き込まれるデータのスループット。RaftデータRaftとRaftスナップショットを適用した場合のスループットも含まれます。
書き込みフロー: すべてのTiFlashインスタンスによるディスク書き込みのトラフィック。
- ファイル記述子: TiFlashで使用される DeltaTreestorageエンジンの安定したレイヤー。
- Page: TiFlashで使用される DeltaTreestorageエンジンの Delta 変更レイヤーである Pagestore を指します。
読み取りフロー: すべてのTiFlashインスタンスのディスク読み取り操作のトラフィック。
- ファイル記述子: TiFlashで使用される DeltaTreestorageエンジンの安定したレイヤー。
- Page: TiFlashで使用される DeltaTreestorageエンジンの Delta 変更レイヤーである Pagestore を指します。
(Read flow + Write flow) ÷ total Write Throughput By Instance式を使用して、 TiFlashクラスター全体の書き込み増幅係数を計算できます。
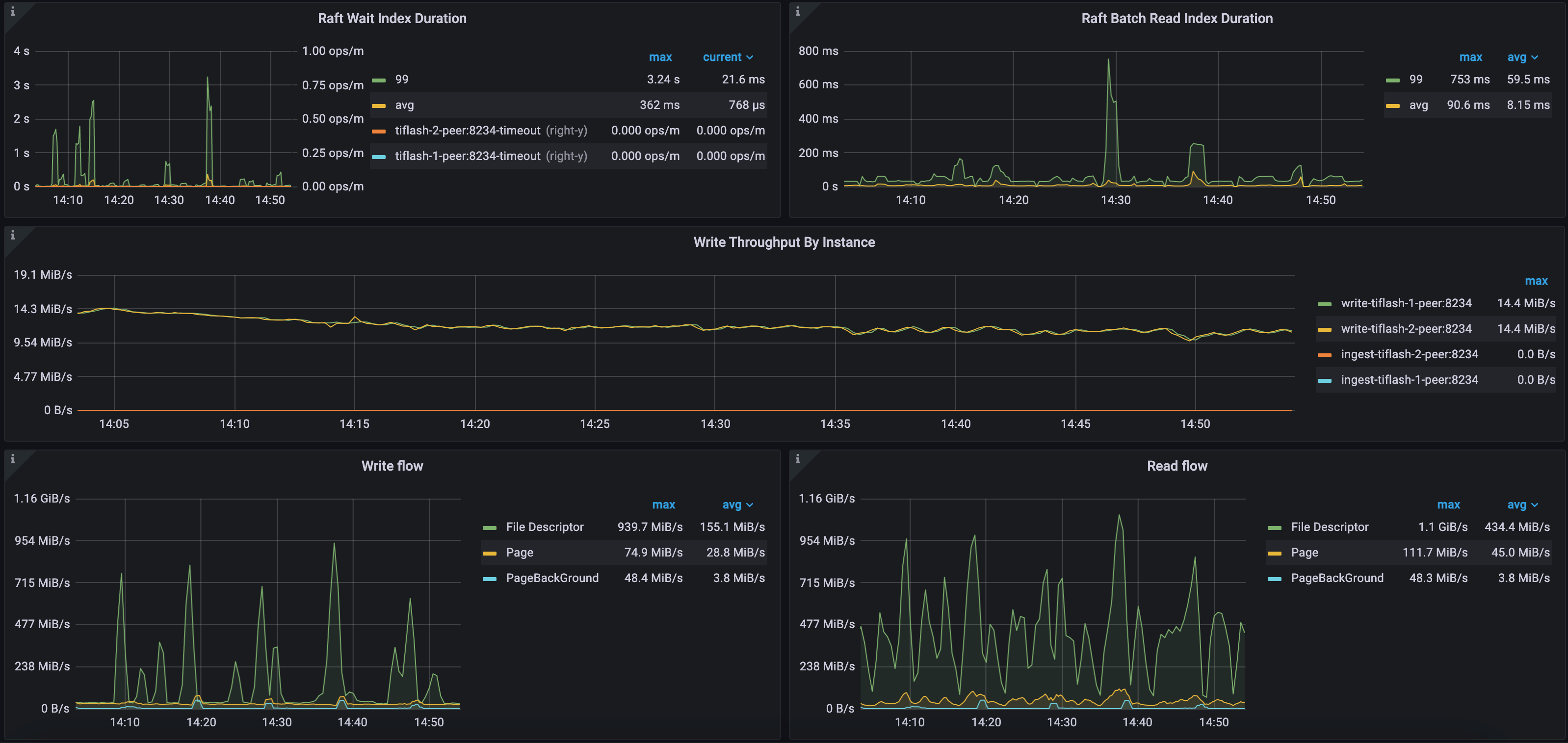
例1: セルフホスト環境におけるRaftとIOメトリクスCH-benCHmark ワークロード
次の図に示すように、このTiFlashクラスターのRaft Wait Index DurationパーセンタイルとRaft Batch Read Index Durationパーセンタイルはそれぞれ3.24秒と753ミリ秒と比較的高い値を示しています。これは、このクラスターのTiFlashワークロードが高く、データレプリケーションでレイテンシーが発生しているためです。
このクラスターには2つのTiFlashノードがあります。TiKVからTiFlashへの増分データレプリケーション速度は約28MB/秒です。安定レイヤー(ファイルディスクリプタ)の最大書き込みスループットは939MB/秒、最大読み取りスループットは1.1GiB/秒です。一方、デルタレイヤー(ページ)の最大書き込みスループットは74MB/秒、最大読み取りスループットは111MB/秒です。この環境では、 TiFlashは強力なIOスループットを備えた専用のNVMEディスクを使用しています。
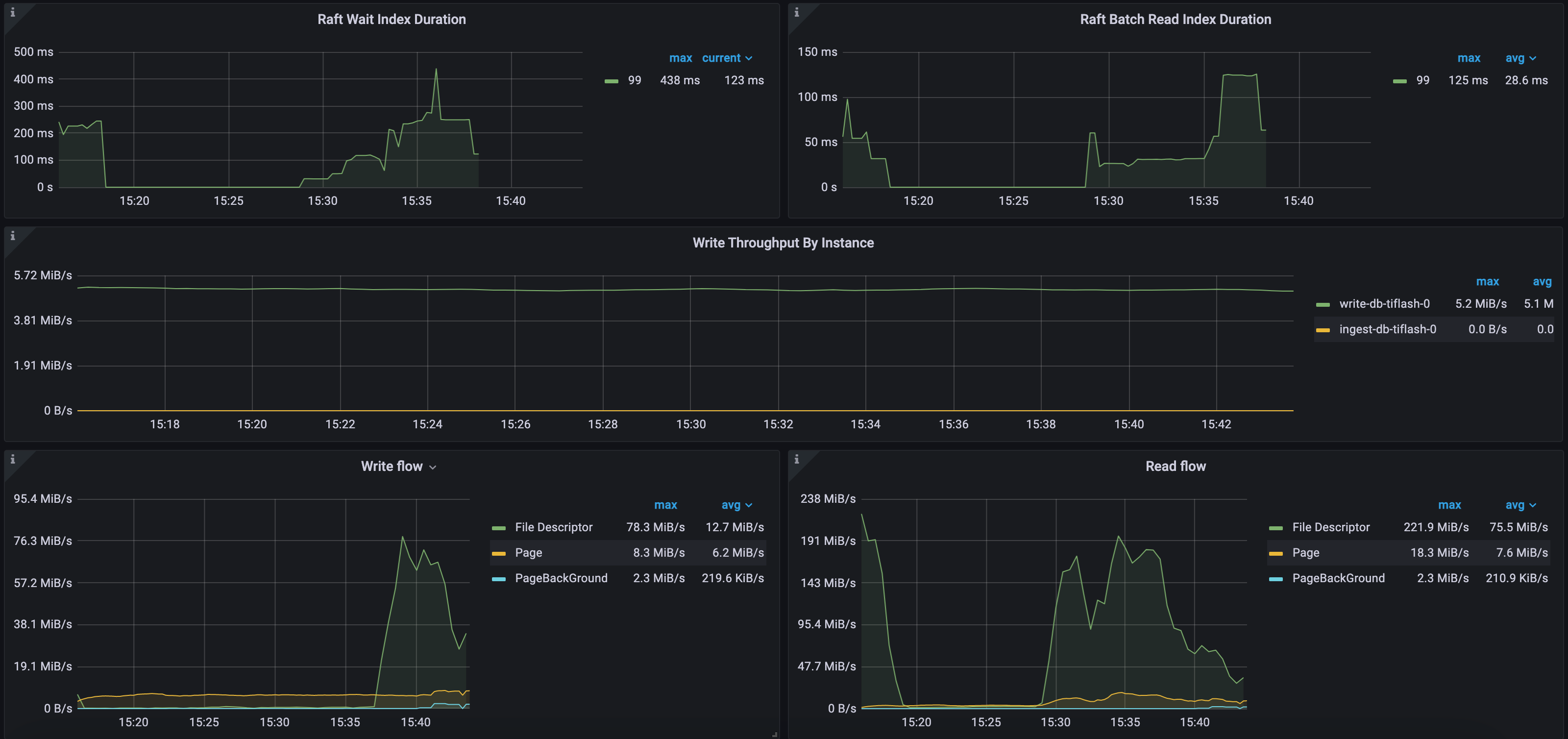
例2: パブリッククラウド導入環境におけるRaftとIOメトリクスCH-benCHmark ワークロード
次の図に示すように、 Raft Wait Index Durationの 99 パーセンタイルは最大 438 ミリ秒、 Raft Batch Read Index Durationの 99 パーセンタイルは最大 125 ミリ秒です。このクラスターにはTiFlashノードが 1 つだけあります。TiKV は、1 秒あたり約 5 MB の増分データをTiFlashに複製します。安定レイヤー(ファイル記述子) の最大書き込みトラフィックは 78 MB/秒、最大読み取りトラフィックは 221 MB/秒です。一方、デルタレイヤー(ページ) の最大書き込みトラフィックは 8 MB/秒、最大読み取りトラフィックは 18 MB/秒です。この環境では、 TiFlash は比較的 IO スループットが低い AWS EBS クラウドディスクを使用しています。