TiDBを最適なパフォーマンスに構成する
このガイドでは、TiDBのパフォーマンスを最適化する方法について説明します。具体的には、以下の内容が含まれます。
- 一般的なワークロードに対するベストプラクティス。
- 困難なパフォーマンス状況に対処するための戦略。
注記:
このガイドで紹介する最適化手法は、TiDB の最適なパフォーマンスを実現するのに役立ちます。ただし、パフォーマンスの調整には複数の要素のバランスを取る必要があり、すべてのパフォーマンスニーズに対応できる単一のソリューションは存在しません。このガイドで紹介する手法の中には、実験的機能を使用するものがあり、それらはその旨が明記されています。これらの最適化によってパフォーマンスを大幅に向上させることは可能ですが、本番環境には適さない場合があり、実装前に慎重な評価が必要です。
概要
TiDBのパフォーマンスを最適化するには、さまざまな設定を慎重に調整する必要があります。多くの場合、最適なパフォーマンスを実現するには、デフォルト値以外の設定変更が必要となります。
デフォルト設定では、パフォーマンスよりも安定性が優先されます。パフォーマンスを最大限に引き出すには、より積極的な設定や、場合によっては実験的機能を使用する必要があるかもしれません。これらの推奨事項は、本番での導入経験とパフォーマンス最適化に関する研究に基づいています。
このガイドでは、デフォルト以外の設定について、それぞれの利点と潜在的なトレードオフを含めて説明します。この情報を活用して、ワークロードの要件に合わせてTiDBの設定を最適化してください。
一般的なワークロードの主要設定
TiDBのパフォーマンスを最適化するために、一般的に以下の設定が使用されます。
- SQL準備済み実行プランキャッシュなどの実行プランキャッシュ準備されていないプランキャッシュ強化しますインスタンスレベルの実行プランキャッシュ
- オプティマイザー修正コントロールを使用して TiDB オプティマイザの動作を最適化します。
- storageエンジンタイタンをより積極的に活用する。
- 書き込み負荷の高いワークロード下でも最適かつ安定したパフォーマンスを確保するために、TiKVの圧縮およびフロー制御の設定を微調整します。
これらの設定は、多くのワークロードのパフォーマンスを大幅に向上させることができます。ただし、他の最適化と同様に、本番に展開する前に、必ずご自身の環境で十分にテストしてください。
システム変数
推奨設定を適用するには、以下のSQLコマンドを実行してください。
SET GLOBAL tidb_enable_instance_plan_cache=on;
SET GLOBAL tidb_instance_plan_cache_max_size=2GiB;
SET GLOBAL tidb_enable_non_prepared_plan_cache=on;
SET GLOBAL tidb_ignore_prepared_cache_close_stmt=on;
SET GLOBAL tidb_analyze_column_options='ALL';
SET GLOBAL tidb_stats_load_sync_wait=2000;
SET GLOBAL tidb_opt_limit_push_down_threshold=10000;
SET GLOBAL tidb_opt_derive_topn=on;
SET GLOBAL tidb_runtime_filter_mode=LOCAL;
SET GLOBAL tidb_opt_enable_mpp_shared_cte_execution=on;
SET GLOBAL tidb_rc_read_check_ts=on;
SET GLOBAL tidb_guarantee_linearizability=off;
SET GLOBAL pd_enable_follower_handle_region=on;
SET GLOBAL tidb_opt_fix_control = '44262:ON,44389:ON,44823:10000,44830:ON,44855:ON,52869:ON';
以下の表は、特定のシステム変数構成が及ぼす影響を概説したものです。
以下では、追加の最適化を可能にするオプティマイザ制御構成について説明します。
44262:ON: グローバル統計が欠落している場合は、 動的プルーニングモード使用してパーティションテーブルにアクセスします。44389:ON:c = 10 and (a = 'xx' or (a = 'kk' and b = 1))のようなフィルターの場合、IndexRangeScanのより包括的なスキャン範囲を作成します。44823:10000:メモリを節約するため、プランキャッシュは、この変数で指定された数を超えるパラメータを持つクエリをキャッシュしません。長いインリストを持つクエリでもプランキャッシュを使用できるようにするには、プランキャッシュのパラメータ制限を200から10000に増やしてください。44830:ON: プランキャッシュは、物理最適化中に生成されたPointGet演算子を含む実行プランをキャッシュすることを許可します。44855:ON:IndexJoin演算子のProbe側にSelection演算子が含まれている場合、オプティマイザはIndexJoin選択します。52869:ON: オプティマイザがクエリ プランに対して (フル テーブル スキャン以外の) 単一のインデックス スキャン メソッドを選択できる場合、オプティマイザは自動的にインデックス マージを選択します。
TiKV構成
TiKV設定ファイルに以下の設定項目を追加してください。
[server]
concurrent-send-snap-limit = 64
concurrent-recv-snap-limit = 64
snap-io-max-bytes-per-sec = "400MiB"
[rocksdb]
max-manifest-file-size = "256MiB"
[rocksdb.titan]
enabled = true
[rocksdb.defaultcf.titan]
min-blob-size = "1KB"
blob-file-compression = "zstd"
[storage]
scheduler-pending-write-threshold = "512MiB"
[storage.flow-control]
l0-files-threshold = 50
soft-pending-compaction-bytes-limit = "512GiB"
[rocksdb.writecf]
level0-slowdown-writes-trigger = 20
soft-pending-compaction-bytes-limit = "192GiB"
[rocksdb.defaultcf]
level0-slowdown-writes-trigger = 20
soft-pending-compaction-bytes-limit = "192GiB"
[rocksdb.lockcf]
level0-slowdown-writes-trigger = 20
soft-pending-compaction-bytes-limit = "192GiB"
前述の表に示されている圧縮およびフロー制御構成の調整は、以下の仕様を持つインスタンスへの TiKV デプロイメントに合わせて調整されていることに注意してください。
- CPU: 32コア
- メモリ: 128 GiB
- ストレージ: 5 TiB EBS
- ディスクスループット:1 GiB/秒
書き込み負荷の高いワークロードに対する推奨構成調整
書き込み負荷の高いワークロードにおける TiKV のパフォーマンスと安定性を最適化するには、インスタンスのハードウェア仕様に基づいて、特定の圧縮およびフロー制御パラメータを調整することをお勧めします。例:
rocksdb.rate-bytes-per-sec: 通常はデフォルト値を使用します。圧縮 I/O がディスク帯域幅のかなりの割合を消費していることに気づいた場合は、レートをディスクの最大スループットの約 60% に制限することを検討してください。これにより、圧縮作業のバランスが取れ、ディスクが飽和状態にならないようになります。たとえば、 1 GiB/sの定格のディスクでは、これを約600MiBに設定します。storage.flow-control.soft-pending-compaction-bytes-limitとstorage.flow-control.hard-pending-compaction-bytes-limit:これらの制限を、利用可能なディスク容量に比例して増やします(例えば、それぞれ1 TiBと2 TiB)。これにより、圧縮処理のためのバッファが増えます。
これらの設定は、リソースの効率的な利用を確保し、書き込み負荷がピークに達した際の潜在的なボトルネックを最小限に抑えるのに役立ちます。
注記:
TiKVは、システムの安定性を確保するために、スケジューラレイヤーでフロー制御を実装しています。保留中の圧縮バイト数や書き込みキューサイズなどの重要なしきい値を超えると、TiKVは書き込み要求を拒否し、ServerIsBusyエラーを返します。このエラーは、バックグラウンドの圧縮プロセスがフォアグラウンドの書き込み操作の現在の速度に追いつけないことを示しています。フロー制御が有効になると、通常、レイテンシーの急増とクエリスループットの低下(QPSの低下)が発生します。これらのパフォーマンス低下を防ぐには、包括的なキャパシティプランニングと、圧縮パラメータおよびstorage設定の適切な構成が不可欠です。
TiFlash -学習者向け設定
TiFlash-learner 設定ファイルに以下の設定項目を追加してください。
[server]
snap-io-max-bytes-per-sec = "300MiB"
ベンチマーク
このセクションでは、デフォルト設定(ベースライン)と前述の一般的な負荷に対する主要な設定に基づいて最適化された設定のパフォーマンスを比較します。
1000個のテーブルに対するSysbenchワークロード
テスト環境
テスト環境は以下のとおりです。
- TiDBサーバー3台(16コア、64GiB)
- TiKVサーバー3台(16コア、64GiB)
- TiDBバージョン:v8.4.0
- 作業負荷: sysbench oltp_read_only
性能比較
以下の表は、ベースライン設定と最適化設定におけるスループット、レイテンシー、およびプランキャッシュヒット率を比較したものです。
主なメリット
インスタンスプランキャッシュは、ベースライン構成と比較して大幅なパフォーマンス向上を実現しています。
ヒット率の向上:53.82%増加(56.89%から87.51%へ)。
メモリ使用量の削減:26.34%減少(95.3 MiBから70.2 MiBへ)。
パフォーマンスの向上:
- QPSは12.38%増加する。
- 平均レイテンシーは11.01%減少します。
- P95のレイテンシーは13.41%減少する。
仕組み
インスタンスプランキャッシュは、以下のメカニズムを通じてパフォーマンスを向上させます。
- メモリ内の
SELECTステートメントの実行プランをキャッシュします。 - 同じ TiDB インスタンス上のすべての接続 (最大 200) 間で、キャッシュされたプランを共有します。
- 1,000個のテーブルにわたって、最大5,000
SELECTステートメントのプランを効率的に保存できます。 - キャッシュミスは主に
BEGINとCOMMITステートメントの場合にのみ発生します。
実生活におけるメリット
シンプルなsysbench oltp_read_onlyクエリ(プランあたり14KB)を使用したベンチマークではわずかな改善しか見られませんが、実際のアプリケーションではより大きな効果が期待できます。
- 複雑なクエリは最大20倍高速に実行できます。
- セッションレベルのプランキャッシュと比較して、メモリ使用量がより効率的です。
インスタンスプランキャッシュは、特に以下のようなシステムに効果的です。
- 列数の多い大きな表。
- 複雑なSQLクエリ。
- 同時接続数が多い。
- 多様なクエリパターン。
メモリ効率
インスタンスプランキャッシュは、セッションレベルのプランキャッシュよりもメモリ効率が優れています。その理由は次のとおりです。
- プランはすべての接続で共有されます
- 各セッションごとに計画を複製する必要はありません
- より高いヒット率を維持しながら、メモリ利用効率を向上させる。
複数の接続と複雑なクエリが発生するシナリオでは、セッションレベルのプランキャッシュでは同等のヒット率を達成するために相当量のメモリが必要となるため、インスタンスプランキャッシュの方が効率的な選択肢となります。
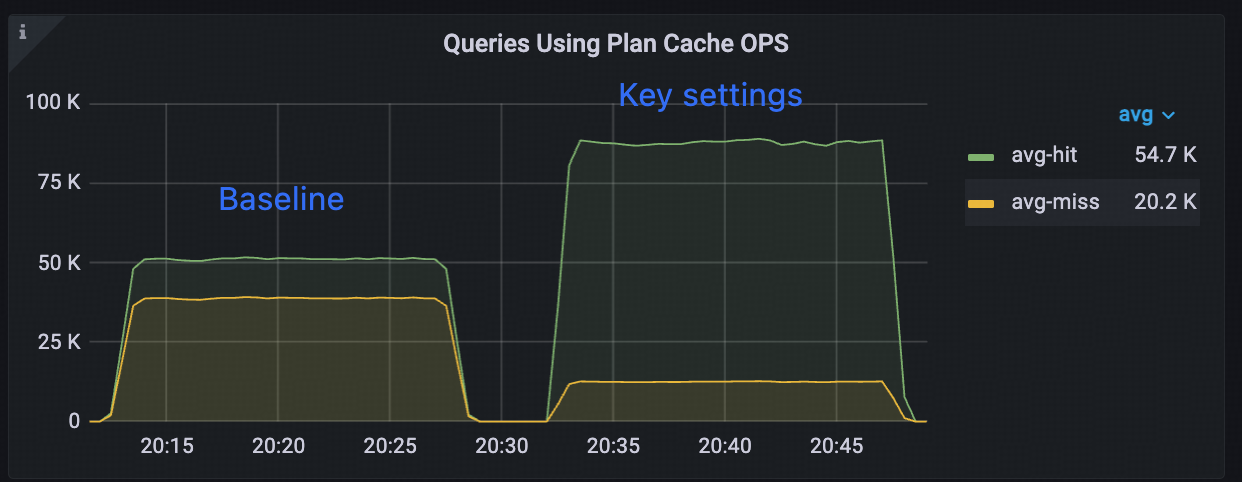
テストワークロード
以下のsysbench oltp_read_only prepareコマンドでデータが読み込まれます。
sysbench oltp_read_only prepare --mysql-host={host} --mysql-port={port} --mysql-user=root --db-driver=mysql --mysql-db=test --threads=100 --time=900 --report-interval=10 --tables=1000 --table-size=10000
以下のsysbench oltp_read_only runコマンドでワークロードが実行されます。
sysbench oltp_read_only run --mysql-host={host} --mysql-port={port} --mysql-user=root --db-driver=mysql --mysql-db=test --threads=200 --time=900 --report-interval=10 --tables=1000 --table-size=10000
詳細については、 Sysbenchを使用してTiDBをテストする方法参照してください。
YCSBの大規模レコード値に関するワークロード
テスト環境
テスト環境は以下のとおりです。
- TiDBサーバー3台(16コア、64GiB)
- TiKVサーバー3台(16コア、64GiB)
- TiDBバージョン:v8.4.0
- 作業負荷: go-ycsbワークロード
性能比較
以下の表は、基準設定と最適化設定におけるスループット(1秒あたりの処理回数)を比較したものです。
パフォーマンス分析
バージョン7.6.0以降、Titanはデフォルトで有効になっています。TiDB v8.4.0では、Titanのデフォルト値はmin-blob-sizeですが、現在は32KiBなっています。ベースライン構成では、レコードサイズを31KiBに設定することで、データがRocksDBに保存されるようにしています。一方、キー設定構成では、 min-blob-size ~ 1KiBに設定すると、データがTitanに保存されます。
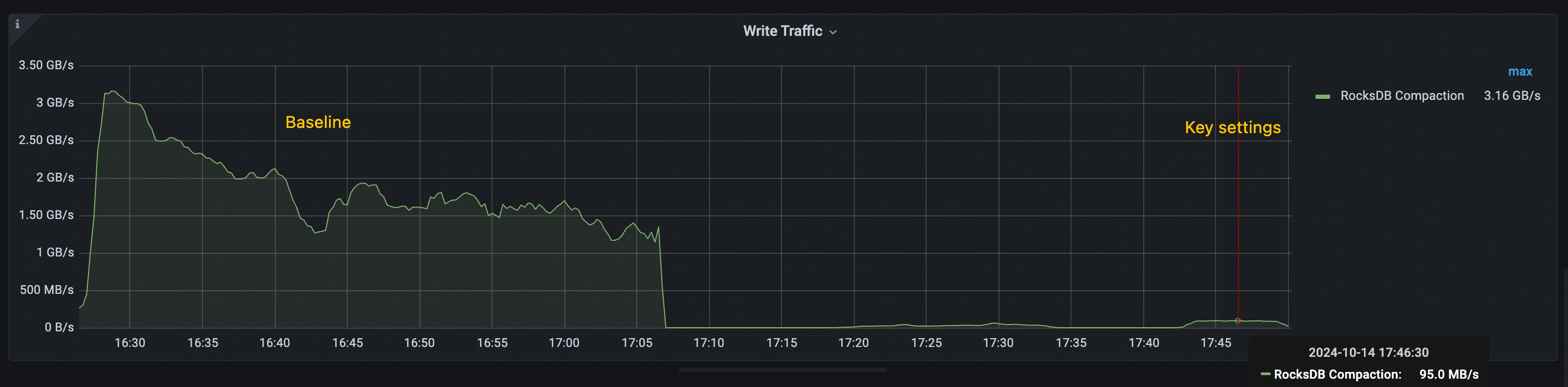
主要設定で確認されたパフォーマンスの向上は、主にTitanがRocksDBの圧縮を削減する能力によるものです。以下の図に示すように、
- ベースライン:RocksDBの圧縮処理の総スループットは1 GiB/sを超え、ピーク時には3 GiB/sを超える。
- 主な設定:RocksDBの圧縮処理のピークスループットは100 MiB/sを下回っています。
この圧縮処理オーバーヘッドの大幅な削減は、主要設定構成で見られる全体的なスループットの向上に貢献しています。
テストワークロード
以下のコマンドgo-ycsb loadデータが読み込まれます。
go-ycsb load mysql -P /ycsb/workloads/workloada -p {host} -p mysql.port={port} -p threadcount=100 -p recordcount=5000000 -p operationcount=5000000 -p workload=core -p requestdistribution=uniform -pfieldcount=31 -p fieldlength=1024
以下のgo-ycsb runコマンドでワークロードが実行されます。
go-ycsb run mysql -P /ycsb/workloads/workloada -p {host} -p mysql.port={port} -p mysql.db=test -p threadcount=100 -p recordcount=5000000 -p operationcount=5000000 -p workload=core -prequestdistribution=uniform -p fieldcount=31 -p fieldlength=1024
エッジケースと最適化
このセクションでは、基本的な最適化を超えた、より的を絞った調整が必要な特定のシナリオに合わせてTiDBを最適化する方法を説明します。特定のユースケースに合わせてTiDBを調整する方法を習得できます。
エッジケースを特定する
例外的なケースを特定するには、以下の手順を実行してください。
- クエリパターンとワークロード特性を分析する。
- システム指標を監視して、パフォーマンスのボトルネックを特定します。
- アプリケーション開発チームから、具体的な問題点に関するフィードバックを収集する。
一般的なエッジケース
以下に、よくある例外的なケースをいくつか挙げます。
- 高頻度の小さなクエリに対して、TSOは高い待機時間を設ける。
- さまざまなワークロードに適した最大チャンクサイズを選択してください。
- 読み込み負荷の高いワークロード向けにコプロセッサキャッシュを調整する
- ワークロード特性に合わせてチャンクサイズを最適化
- さまざまなワークロードに合わせてトランザクションモードとDMLタイプを最適化する
- TiKVプッシュダウンによる
GROUP BYおよびDISTINCTオペレーションの最適化 - インメモリエンジンを使用してMVCCバージョンの蓄積を軽減する
- バッチ処理中の統計情報収集を最適化する
- インスタンスの種類ごとにスレッドプールの設定を最適化する
以下のセクションでは、これらの各ケースへの対処方法について説明します。それぞれのシナリオに応じて、異なるパラメータを調整したり、特定のTiDB機能を使用したりする必要があります。
注記:
これらの最適化は、使用状況やデータパターンによって効果が異なる可能性があるため、慎重に適用し、徹底的にテストしてください。
高頻度の小さなクエリに対して、TSOは高い待機時間を設ける。
トラブルシューティング
ワークロードに頻繁に発生する小規模なトランザクションや、タイムスタンプを頻繁に要求するクエリが含まれる場合、 TSO(タイムスタンプオラクル)パフォーマンスのボトルネックになる可能性があります。TSO の待機時間がシステムに影響を与えているかどうかを確認するには、 パフォーマンス概要 > SQL実行時間概要パネルを確認してください。TSO の待機時間が SQL 実行時間の大部分を占める場合は、次の最適化を検討してください。
- 厳密な一貫性を必要としない読み取り操作には、低精度TSO(
tidb_low_resolution_tsoを有効にする)を使用します。詳細については、 解決策1:低精度TSOを使用する参照してください。 - 可能な場合は、小さな取引をまとめて大きな取引にします。詳細については、 解決策2:TSO要求の並列モード参照してください。
解決策1:低精度TSO
低精度TSO機能( tidb_low_resolution_tso )を有効にすることで、TSOの待ち時間を短縮できます。この機能を有効にすると、TiDBはキャッシュされたタイムスタンプを使用してデータを読み取り、TSOの待ち時間を短縮しますが、その代償として古いデータを読み取る可能性があります。
この最適化は、特に以下のシナリオで効果を発揮します。
- 読み込み負荷の高いワークロードで、多少の古さは許容範囲内。
- クエリのレイテンシーを削減することが、絶対的な一貫性よりも重要なシナリオ。
- 最新のコミット状態から数秒遅れた読み取りを許容できるアプリケーション。
メリットとデメリット:
- キャッシュされたTSOを使用して古いデータの読み取りを有効にすることで、クエリのレイテンシーを削減し、新しいタイムスタンプを要求する必要性をなくします。
- パフォーマンスとデータの一貫性のバランスを取る:この機能は、古い読み取りデータが許容されるシナリオにのみ適しています。厳密なデータの一貫性が求められる場合には、使用を推奨しません。
この最適化を有効にするには:
SET GLOBAL tidb_low_resolution_tso=ON;
解決策2:TSO要求の並列モード
システム変数tidb_tso_client_rpc_modeは、TiDBがPDにTSO RPCリクエストを送信するモードを切り替えます。デフォルト値はDEFAULTです。以下の条件を満たす場合、パフォーマンス向上の可能性を考慮して、この変数をPARALLELまたはPARALLEL-FASTに切り替えることを検討してください。
- TSOの待機時間は、SQLクエリの総実行時間の大部分を占める。
- PDにおけるTSOの割り当ては、まだボトルネックに達していません。
- PDノードとTiDBノードは十分なCPUリソースを備えています。
- TiDBとPD間のネットワークレイテンシーは、PDがTSOを割り当てるのにかかる時間よりもかなり長い(つまり、TSO RPCの実行時間の大部分はネットワークレイテンシーによるものである)。
- TSO RPCリクエストの所要時間を取得するには、Grafana TiDBダッシュボードのPDクライアントセクションにあるPD TSO RPC所要時間パネルを確認してください。
- PD TSO割り当ての期間を確認するには、Grafana PDダッシュボードのTiDBセクションにあるPDサーバーTSOハンドル期間パネルを確認してください。
- TiDBとPD間のTSO RPCリクエストの増加(
PARALLELの場合は2倍、PARALLEL-FASTの場合は4倍)によって生じる追加のネットワークトラフィックは許容範囲内です。
並列モードを切り替えるには、次のコマンドを実行してください。
-- Use the PARALLEL mode
SET GLOBAL tidb_tso_client_rpc_mode=PARALLEL;
-- Use the PARALLEL-FAST mode
SET GLOBAL tidb_tso_client_rpc_mode=PARALLEL-FAST;
読み込み負荷の高いワークロード向けにコプロセッサキャッシュを調整する
コプロセッサキャッシュキャッシュを最適化することで、読み取り負荷の高いワークロードのクエリ パフォーマンスを向上させることができます。このキャッシュにはコプロセッサのリクエスト結果が格納され、頻繁にアクセスされるデータの繰り返し計算が削減されます。キャッシュのパフォーマンスを最適化するには、次の手順を実行します。
- コプロセッサーキャッシュで説明した指標を使用してキャッシュヒット率を監視します。
- キャッシュサイズを増やすことで、より大きなワーキングセットにおけるヒット率を向上させることができます。
- クエリパターンに基づいて、承認基準値を調整する。
以下に、読み込み負荷の高いワークロード向けに推奨される設定例をいくつか示します。
[tikv-client.copr-cache]
capacity-mb = 4096
admission-max-ranges = 5000
admission-max-result-mb = 10
admission-min-process-ms = 0
ワークロード特性に合わせてチャンクサイズを最適化
システム変数tidb_max_chunk_sizeは、実行プロセス中にチャンク内の最大行数を設定します。ワークロードに応じてこの値を調整することで、パフォーマンスを向上させることができます。
同時実行数が多くトランザクション数が少ないOLTPワークロードの場合:
- 値を
128から256行の間で設定してください(デフォルト値は1024です)。 - これによりメモリ使用量が削減され、制限クエリの処理速度が向上します。
- 使用例:ポイントクエリ、小範囲スキャン。
SET GLOBAL tidb_max_chunk_size = 128;- 値を
複雑なクエリと大規模な結果セットを伴うOLAPまたは分析ワークロードの場合:
- 値を
1024から4096行の間で設定してください。 - これにより、大量のデータをスキャンする際のスループットが向上します。
- 使用例:集計処理、大規模テーブルのスキャン。
SET GLOBAL tidb_max_chunk_size = 4096;- 値を
さまざまなワークロードに合わせてトランザクションモードとDMLタイプを最適化する
TiDBは、さまざまなワークロードパターンに合わせてパフォーマンスを最適化するために、複数のトランザクションモードとDML実行タイプを提供します。
トランザクションモード
トランザクションモードは、システム変数tidb_txn_modeを使用して設定できます。
悲観的な取引モード (デフォルト):
- 書き込み競合が発生する可能性のある一般的なワークロードに適しています。
- より強力な一貫性保証を提供します。
SET SESSION tidb_txn_mode = "pessimistic";- 書き込み競合が最小限のワークロードに適しています。
- 複数明細の取引におけるパフォーマンスが向上しました。
- 例:
BEGIN; INSERT...; INSERT...; COMMIT;.
SET SESSION tidb_txn_mode = "optimistic";
DMLタイプ
バージョン8.0.0で導入されたシステム変数tidb_dml_typeを使用して、DMLステートメントの実行モードを制御できます。
バルクDML実行モードを使用するには、 tidb_dml_type ~ "bulk"に設定します。このモードでは、競合のないバルクデータロードが最適化され、大規模な書き込み操作中のメモリ使用量が削減されます。このモードを使用する前に、以下の点を確認してください。
autocommitが有効です。pessimistic-auto-commit設定項目はfalseに設定されています。
SET SESSION tidb_dml_type = "bulk";
TiKVプッシュダウンを使用してGROUP BYおよびDISTINCT操作を最適化します
TiDBは集計処理をTiKVにプッシュダウンすることで、データ転送と処理のオーバーヘッドを削減します。パフォーマンスの向上度合いは、データの特性によって異なります。
使用シナリオ
理想的なシナリオ(高いパフォーマンス向上):
- 異なる値が少ない列(NDVが低い)。
- 重複値が頻繁に含まれるデータ。
- 例:ステータス列、カテゴリコード、日付部分。
理想的でないシナリオ(潜在的なパフォーマンス低下):
- ほとんどが一意の値を含む列(NDVが高い)。
- 固有の識別子またはタイムスタンプ。
- 例:ユーザーID、トランザクションID。
コンフィグレーション
セッションレベルまたはグローバルレベルでプッシュダウン最適化を有効にする:
-- Enable regular aggregation pushdown
SET GLOBAL tidb_opt_agg_push_down = ON;
-- Enable distinct aggregation pushdown
SET GLOBAL tidb_opt_distinct_agg_push_down = ON;
インメモリエンジンを使用してMVCCバージョンの蓄積を軽減する
MVCC のバージョンが多すぎると、特に読み書き頻度の高い領域や、ガベージコレクションと圧縮の問題により、パフォーマンスのボトルネックが発生する可能性があります。この問題を軽減するには、v8.5.0 で導入されたバージョンTiKV MVCC インメモリエンジン (IME)使用できます。これを有効にするには、TiKV 設定ファイルに次の設定を追加してください。
注記:
インメモリエンジンは、過剰なMVCCバージョンの影響を軽減するのに役立ちますが、メモリ使用量が増加する可能性があります。この機能を有効にした後は、システムを監視してください。
[in-memory-engine]
enable = true
バッチ処理中の統計情報収集を最適化する
統計情報の収集を管理することで、クエリの最適化を維持しながら、バッチ処理中のパフォーマンスを向上させることができます。このセクションでは、このプロセスを効果的に管理する方法について説明します。
auto analyzeを無効にするタイミング
以下のシナリオでは、システム変数tidb_enable_auto_analyze OFFに設定することでauto analyzeを無効にできます。
- 大量のデータインポート時。
- 一括更新処理中。
- 時間制約のあるバッチ処理向け。
- 統計情報の収集タイミングを完全に制御する必要がある場合。
ベストプラクティス
バッチ処理の前に:
-- Disable auto analyze SET GLOBAL tidb_enable_auto_analyze = OFF;バッチ処理後:
-- Manually collect statistics ANALYZE TABLE your_table; -- Re-enable auto analyze SET GLOBAL tidb_enable_auto_analyze = ON;
インスタンスの種類ごとにスレッドプールの設定を最適化する
TiKVのパフォーマンスを向上させるには、インスタンスのCPUリソースに基づいてスレッドプールを設定してください。以下のガイドラインは、これらの設定を最適化するのに役立ちます。
8~16コアのインスタンスの場合、デフォルト設定で通常は十分です。
32コア以上のインスタンスでは、リソース利用効率を向上させるためにプールサイズを増やしてください。設定は以下のように調整してください。
[server] # Increase gRPC thread pool grpc-concurrency = 10 [raftstore] # Optimize for write-intensive workloads apply-pool-size = 4 store-pool-size = 4 store-io-pool-size = 2