TiCDC のパフォーマンス分析とチューニング方法
このドキュメントでは、TiCDCのリソース使用率と主要なパフォーマンス指標についてご紹介します。パフォーマンス概要ダッシュボードのCDCパネルを通じて、データレプリケーションにおけるTiCDCのパフォーマンスを監視および評価できます。
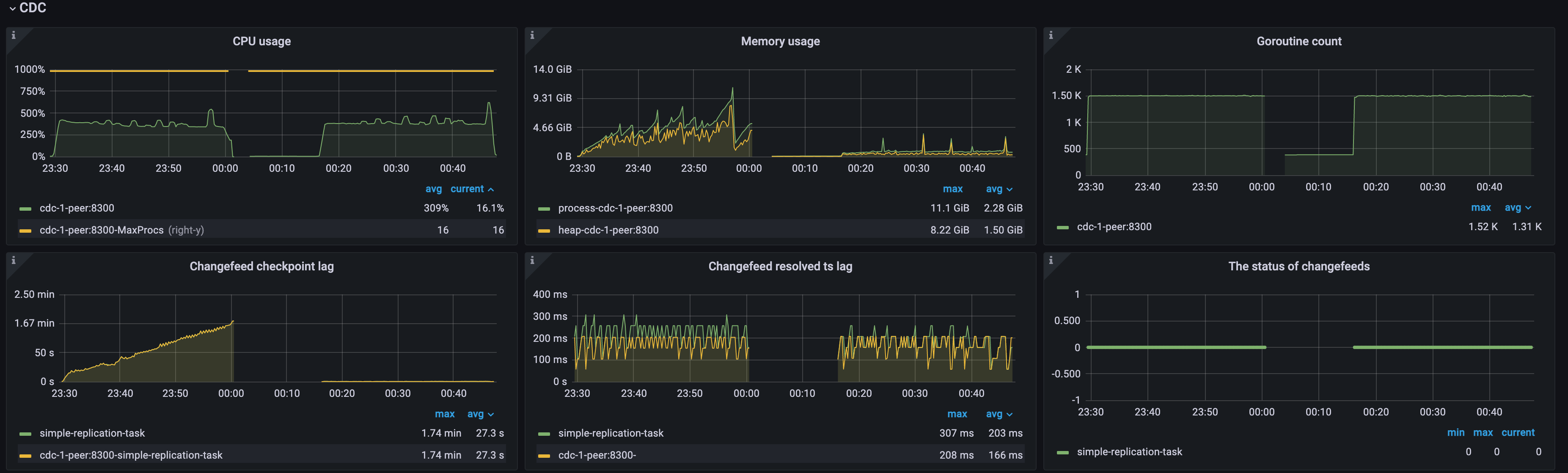
TiCDC クラスターのリソース利用率
次の 3 つのメトリックを使用すると、TiCDC クラスターのリソース使用率を簡単に取得できます。
- CPU 使用率: TiCDC ノードごとの CPU 使用率。
- メモリ使用量: TiCDC ノードごとのメモリ使用量。
- ゴルーチン数: TiCDC ノードあたりのゴルーチンの数。
TiCDCデータレプリケーションの主要指標
TiCDC の全体的な指標
次のメトリックを使用すると、TiCDC データ レプリケーションの概要を把握できます。
Changefeed チェックポイント ラグ: アップストリームとダウンストリーム間のデータ複製の進行ラグ (秒単位で測定)。
TiCDC がデータを消費し、下流に書き込む速度が上流のデータの変化に追いついている場合、この指標は小さなレイテンシー範囲内(通常は 10 秒以内)に留まります。そうでない場合、この指標は増加し続けます。
このメトリック (つまり
Changefeed checkpoint lag) が増加する場合、一般的な理由は次のとおりです。- システム リソースが不十分: TiCDC の CPU、メモリ、またはディスク領域が不十分な場合、データ処理が遅くなりすぎて、TiCDC 変更フィードのチェックポイントが長くなる可能性があります。
- ネットワークの問題: TiCDC でネットワークの中断、遅延、または帯域幅不足が発生すると、データ転送速度に影響し、TiCDC 変更フィードのチェックポイントが長くなる可能性があります。
- アップストリームのQPSが高い場合:TiCDCで処理するデータが過度に大きい場合、データ処理のタイムアウトが発生し、TiCDCチェンジフィードのチェックポイントが増加する可能性があります。通常、単一のTiCDCノードは最大約60KのQPSを処理できます。
- データベースの問題:
- アップストリームTiKVクラスタの
min resolved tsと最新のPD TSOのギャップが大きくなっています。この問題は通常、アップストリームの書き込みワークロードが過度に重い場合に、TiKVが解決済みのTSを時間内に進めることができないために発生します。 - ダウンストリーム データベースのレイテンシーが大きいため、TiCDC がダウンストリームにデータをタイムリーに複製できなくなります。
- アップストリームTiKVクラスタの
Changefeed 解決 ts ラグ: TiCDC ノードの内部レプリケーション状態と上流との間の進捗ラグ(秒単位)。このメトリックが高い場合、TiCDC Puller または Sorter モジュールのデータ処理能力が不足しているか、ネットワークレイテンシーやディスクの読み取り/書き込み速度の低下などの問題が発生している可能性があります。このような場合、TiCDC の効率的かつ安定した運用を確保するには、TiCDC ノードの数を増やす、ネットワーク構成を最適化するなどの適切な対策を講じる必要があります。
changefeed のステータス: changefeed のステータスの説明については、 チェンジフィード状態転送参照してください。
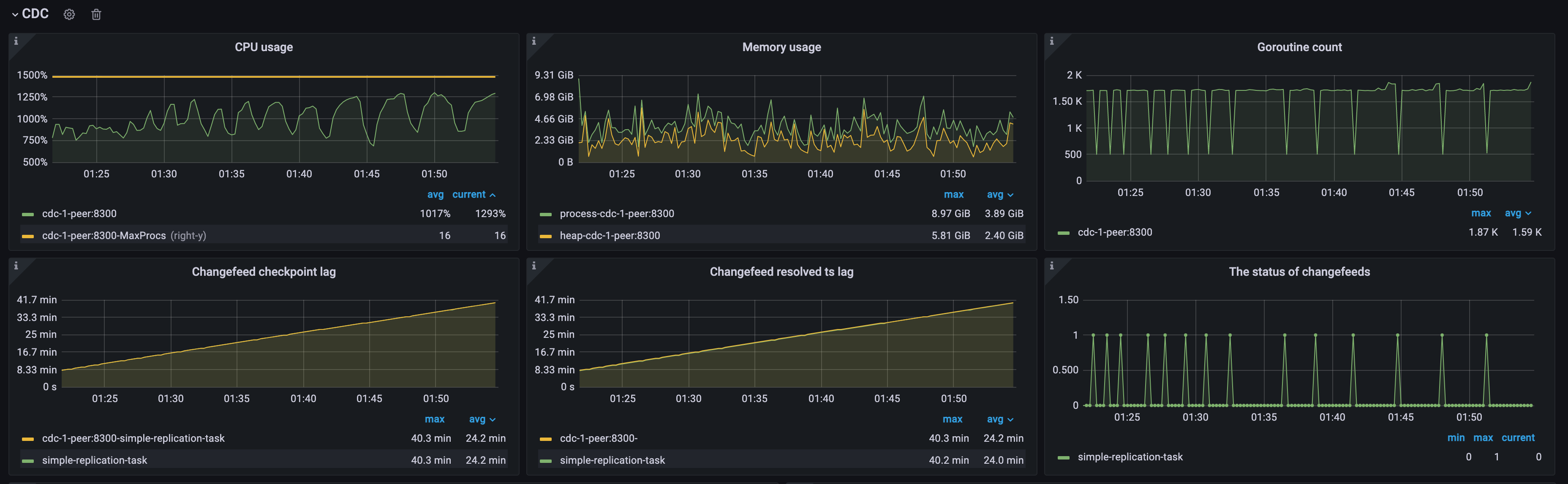
例1: 単一のTiCDCノードの場合、上流QPSが高いためにチェックポイントの遅延が大きくなる
次の図に示すように、アップストリームのQPSが過度に高く、クラスター内にTiCDCノードが1つしかないため、TiCDCノードが過負荷状態になり、CPU使用率が高くなり、 Changefeed checkpoint lagとChangefeed resolved ts lag両方が増加し続けています。changefeedのステータスは断続的に0から1に遷移しており、changefeedでエラーが発生し続けていることを示しています。以下の手順でリソースを追加することで、この問題を解決できます。
- TiCDC ノードを追加します。処理能力を高めるために、TiCDC クラスターを複数のノードにスケールアウトします。
- TiCDC ノードのリソースを最適化します。TiCDC ノードの CPU とメモリの構成を増やしてパフォーマンスを向上させます。
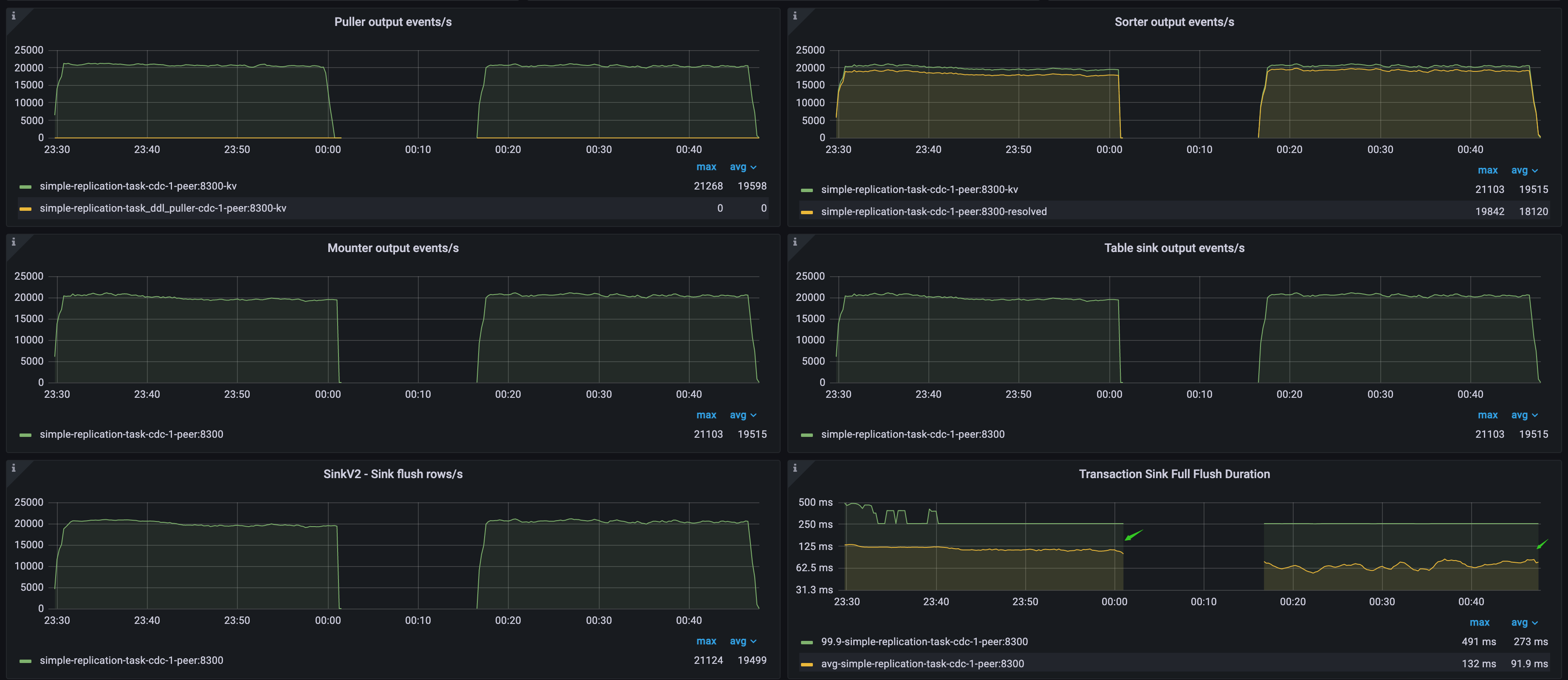
データフローのスループット指標とダウンストリームのレイテンシー
次のメトリックを使用すると、TiCDC のデータフロー スループットとダウンストリームレイテンシーを知ることができます。
- Puller 出力イベント/秒: TiCDC ノードの Puller モジュールが Sorter モジュールに 1 秒あたりに送信する行数。
- ソーター出力イベント/秒: TiCDC ノードのソーター モジュールがマウント モジュールに 1 秒あたりに送信する行数。
- マウンター出力イベント/秒: TiCDC ノードのマウンター モジュールがシンク モジュールに 1 秒あたりに送信する行数。
- テーブル シンク出力イベント/秒: TiCDC ノードのテーブル ソーター モジュールがシンク モジュールに 1 秒あたりに送信する行数。
- SinkV2 - シンク フラッシュ行数/秒: TiCDC ノードのシンク モジュールがダウンストリームに 1 秒あたりに送信する行数。
- トランザクションシンクの完全フラッシュ期間: TiCDC ノードの MySQL シンクによるダウンストリーム トランザクションの書き込みの平均レイテンシーと p999レイテンシー。
- MQ ワーカーのメッセージ送信期間パーセンタイル: ダウンストリームが Kafka の場合の MQ ワーカーによるメッセージ送信のレイテンシー。
- Kafka 送信バイト: MQ ワークロードでのダウンストリーム トランザクションの書き込みトラフィック。
例2: 下流データベースの書き込み速度がTiCDCデータレプリケーションのパフォーマンスに与える影響
次の図に示すように、上流と下流の両方がTiDBクラスターです。TiCDC Puller output events/sメトリックは上流データベースのQPSを示しますTransaction Sink Full Flush Durationメトリックは下流データベースの平均書き込みレイテンシーを示しており、最初のワークロードでは高く、2番目のワークロードでは低くなります。
- 最初のワークロードでは、下流のTiDBクラスターが低速でデータを書き込むため、TiCDCは上流のQPSに遅れをとる速度でデータを消費し、
Changefeed checkpoint lag継続的に増加します。しかし、Changefeed resolved ts lag300ミリ秒以内に収まっているため、レプリケーションの遅延とスループットのボトルネックは、プラーモジュールとソーターモジュールではなく、下流のシンクモジュールによって発生していることがわかります。 - 2 番目のワークロードでは、下流の TiDB クラスターがデータをより高速に書き込むため、TiCDC は上流に完全に追いつく速度でデータを複製し、
Changefeed checkpoint lagとChangefeed resolved ts lag500 ミリ秒以内に留まります。これは、TiCDC にとって比較的理想的なレプリケーション速度です。