TiCDCの概要
TiCDC 、TiDBから増分データを複製するためのツールです。具体的には、TiCDCはTiKVの変更ログを取得し、キャプチャしたデータをソートし、行ベースの増分データを下流のデータベースにエクスポートします。データ複製機能の詳細については、 TiCDC データレプリケーション機能参照してください。
使用シナリオ
TiCDC には、次のような複数の使用シナリオがあります。
- 複数のTiDBクラスタに高可用性と災害復旧ソリューションを提供します。TiCDCは、災害発生時にプライマリクラスタとセカンダリクラスタ間の最終的なデータ整合性を確保します。
- リアルタイムのデータ変更を同種システムに複製します。これにより、監視、キャッシュ、グローバルインデックス作成、データ分析、異種データベース間のプライマリ-セカンダリレプリケーションなど、さまざまなシナリオに対応するデータソースが提供されます。
主な特徴
主な機能
TiCDC には次の主要な機能があります。
- 秒レベルの RPO と分レベルの RTO を使用して、TiDB クラスター間で増分データをレプリケートします。
- TiDB クラスター間の双方向レプリケーションにより、TiCDC を使用したマルチアクティブ TiDB ソリューションの作成が可能になります。
- TiDB クラスターから MySQL データベースまたはその他の MySQL 互換データベースに低レイテンシーで増分データを複製します。
- TiDBクラスターからKafkaクラスターへの増分データのレプリケーション。推奨されるデータ形式アブロ 運河-JSON デベジウム
- TiDB クラスターから Amazon S3、GCS、Azure Blob Storage、NFS などのstorageサービスに増分データを複製します。
- データベース、テーブル、DML、DDL をフィルターする機能を使用してテーブルを複製します。
- 単一障害点のない高可用性、TiCDC ノードの動的な追加と削除をサポートします。
- タスク ステータスの照会、タスク構成の動的な変更、タスクの作成または削除など、 オープンAPIを介したクラスタ管理。
複製順序
すべての DDL または DML ステートメントについて、TiCDC はそれらを少なくとも 1 回出力します。
TiKVまたはTiCDCクラスターで障害が発生すると、TiCDCは同じDDL/DML文を繰り返し送信することがあります。重複したDDL/DML文については、以下のようになります。
- MySQLシンクはDDL文を繰り返し実行できます。1
TRUNCATE TABLEように下流で繰り返し実行できるDDL文は正常に実行されます。3CREATE TABLEように繰り返し実行できないDDL文は実行に失敗し、TiCDCはエラーを無視してレプリケーションプロセスを続行します。 - Kafka シンクは、データ分散のためのさまざまな戦略を提供します。
- テーブル、主キー、またはタイムスタンプに基づいて、データを異なるKafkaパーティションに分散できます。これにより、行の更新データが順番に同じパーティションに送信されるようになります。
- これらの分散戦略はすべて、すべてのトピックとパーティションに定期的に
Resolved TSメッセージを送信します。これは、Resolved TSより前のすべてのメッセージが既にトピックとパーティションに送信されていることを示します。KafkaコンシューマーはResolved TSを使用して受信したメッセージをソートできます。 - Kafkaシンクは重複したメッセージを送信することがありますが、これらの重複メッセージは
Resolved Tsの制約には影響しません。例えば、チェンジフィードが一時停止されて再開された場合、Kafkaシンクはmsg1、msg2、msg3、msg2、msg3の順に送信する可能性があります。Kafkaコンシューマーから重複メッセージをフィルタリングできます。
- MySQLシンクはDDL文を繰り返し実行できます。1
レプリケーションの一貫性
MySQLシンク
TiCDC は、REDO ログを有効にして、データ レプリケーションの最終的な一貫性を保証します。
TiCDC は、単一行の更新の順序がアップストリームと一致していることを保証します。
TiCDC では、ダウンストリーム トランザクションがアップストリーム トランザクションと同じ順序で実行されることは保証されません。
注記:
バージョン6.2以降では、シンクURIパラメータ
transaction-atomicityを使用して、単一テーブルトランザクションを分割するかどうかを制御できます。単一テーブルトランザクションを分割することで、大規模トランザクションのレプリケーションにおけるレイテンシーとメモリ消費を大幅に削減できます。
TiCDCアーキテクチャの概要
TiCDCは、PDのetcdを通じて高可用性を実現するTiDB用の増分データレプリケーションツールです。レプリケーションプロセスは、以下のステップで構成されます。
- 複数の TiCDC プロセスが TiKV ノードからデータの変更をプルします。
- TiCDC はデータの変更を並べ替えてマージします。
- TiCDC は、複数のレプリケーション タスク (変更フィード) を通じて、データの変更を複数のダウンストリーム システムに複製します。
TiCDC のアーキテクチャは次の図に示されています。
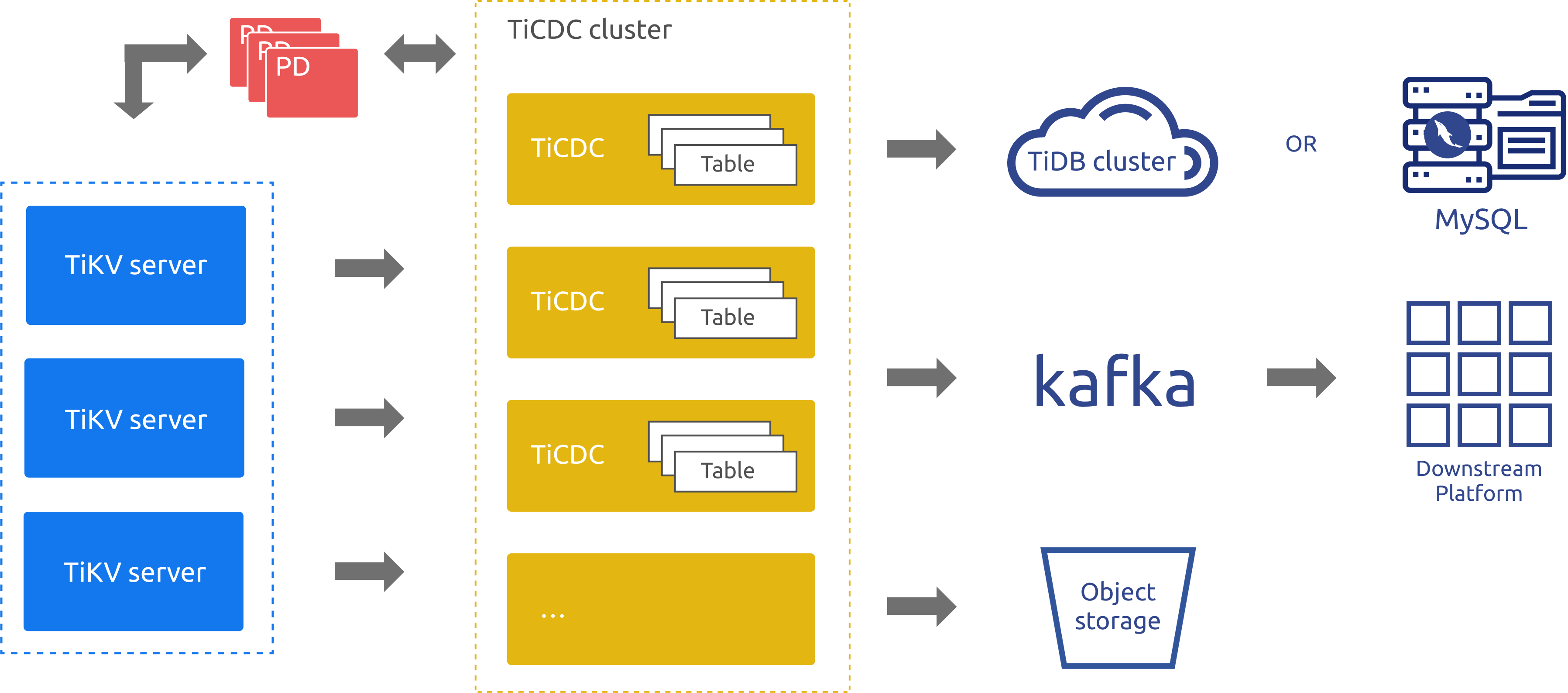
アーキテクチャ図のコンポーネントは次のように説明されます。
- TiKVサーバー:TiDBクラスター内のTiKVノード。データ変更が発生すると、TiKVノードは変更内容を変更ログ(KV変更ログ)としてTiCDCノードに送信します。TiCDCノードは変更ログが連続していないことを検出すると、TiKVノードに変更ログの提供を積極的に要求します。
- TiCDC: TiCDCプロセスが実行されるTiCDCノード。各ノードはTiCDCプロセスを実行します。各プロセスは、TiKVノード内の1つ以上のテーブルからデータ変更を取得し、シンクコンポーネントを介して下流のシステムに変更を複製します。
- PD: TiDBクラスタ内のスケジューリングモジュール。このモジュールはクラスタデータのスケジューリングを担当し、通常は3つのPDノードで構成されます。PDはetcdクラスタを通じて高可用性を提供します。etcdクラスタでは、TiCDCがノードステータス情報や変更フィード設定などのメタデータを保存します。
実装においては、TiCDC の新しいアーキテクチャと古典アーキテクチャどちらも同じ増分データレプリケーションモデルに基づいて構築されています。従来のアーキテクチャと比較して、新しいアーキテクチャではタスクスケジューリングとレプリケーションメカニズムがリファクタリングおよび最適化されており、リアルタイムデータレプリケーションのパフォーマンス、スケーラビリティ、安定性が大幅に向上するとともに、リソースコストも削減されます。
アーキテクチャ図に示されているように、TiCDC は TiDB、MySQL、Kafka、およびstorageサービスへのデータの複製をサポートしています。
有効なインデックス
一般的に、TiCDC は、少なくとも 1 つの有効なインデックスを持つテーブルのみを下流に複製します。テーブル内のインデックスが以下のいずれかの要件を満たしている場合、そのインデックスは有効です。
- 主キー(
PRIMARY KEY)は有効なインデックスです。 - ユニークインデックス(
UNIQUE INDEX)は、インデックスのすべての列が明示的に非NULLとして定義され(NOT NULL)、インデックスに仮想生成列(VIRTUAL GENERATED COLUMNS)がない場合に有効です。
注記:
force-replicateをtrueに設定すると、 TiCDC は強制的に有効なインデックスのないテーブルを複製するします。
ベストプラクティス
TiCDC を使用して 2 つの TiDB クラスター間でデータをレプリケートする場合、2 つのクラスター間のネットワークレイテンシーが 100 ミリ秒を超えると、次のようになります。
- v6.5.2 より前のバージョンの TiCDC の場合、ダウンストリーム TiDB クラスターが配置されているリージョン (IDC) に TiCDC をデプロイすることをお勧めします。
- TiCDC v6.5.2 から導入された一連の改善により、アップストリーム TiDB クラスターが配置されているリージョン (IDC) に TiCDC を展開することが推奨されます。
TiCDC によって複製される各テーブルには、少なくとも 1 つの有効なインデックスがあります。
TiCDC を災害復旧に使用する場合、最終的な一貫性を確保するには、 再実行ログ設定し、上流で災害が発生したときに、REDO ログが書き込まれるstorageシステムを正常に読み取ることができるようにする必要があります。
処理データの変更の実装
このセクションでは主に、TiCDC がアップストリーム DML 操作によって生成されたデータの変更を処理する方法について説明します。
上流のDDL操作によって生成されたデータ変更については、TiCDCは完全なDDL SQL文を取得し、下流のシンクタイプに基づいて対応する形式に変換し、下流に送信します。このセクションではこれについては詳しく説明しません。
注記:
TiCDC がデータ変更を処理するロジックは、以降のバージョンで調整される可能性があります。
MySQLのbinlogは、上流で実行されたすべてのDML SQL文を直接記録します。MySQLとは異なり、TiCDCは上流TiKV内の各リージョンRaftログのリアルタイム情報をリッスンし、各トランザクションの前後のデータの差分に基づいて、複数のSQL文に対応するデータ変更情報を生成します。TiCDCは、出力された変更イベントが上流TiDBの変更と同等であることを保証するだけで、上流TiDBのデータ変更を引き起こしたSQL文を正確に復元できることは保証しません。
データ変更情報には、データ変更の種類と変更前後のデータ値が含まれます。トランザクション前後のデータの違いによって、以下の3種類のイベントが発生する可能性があります。
DELETEイベント: 変更前のデータが含まれるDELETE種類のデータ変更メッセージに対応します。INSERTイベント: 変更後のデータが含まれるPUT種類のデータ変更メッセージに対応します。UPDATEのイベント: 変更前と変更後の両方のデータが含まれるPUT種類のデータ変更メッセージに対応します。
TiCDCは、データ変更情報に基づいて、下流の様々なタイプに適した形式でデータを生成し、下流に送信します。例えば、Canal-JSONやAvroなどの形式でデータを生成し、Kafkaに書き込んだり、データをSQL文に変換して下流のMySQLやTiDBに送信したりします。
現在、TiCDCは対応するプロトコルに合わせてデータ変更情報を適応させる際に、特定のUPDATEイベントについて、 DELETEイベントとINSERTイベントに分割することがあります。詳細については、 MySQLシンクのUPDATEイベントを分割するとMySQL以外のシンクの主キーまたは一意キーのUPDATEイベントを分割する参照してください。
下流がMySQLまたはTiDBの場合、TiCDCは下流に書き込まれるSQL文が上流で実行されたSQL文と完全に同一であることを保証できません。これは、TiCDCが上流で実行された元のDML文を直接取得するのではなく、データの変更情報に基づいてSQL文を生成するためです。ただし、TiCDCは最終結果の一貫性を保証します。
たとえば、次の SQL ステートメントはアップストリームで実行されます。
Create Table t1 (A int Primary Key, B int);
BEGIN;
Insert Into t1 values(1,2);
Insert Into t1 values(2,2);
Insert Into t1 values(3,3);
Commit;
Update t1 set b = 4 where b = 2;
TiCDC は、データ変更情報に基づいて次の 2 つの SQL ステートメントを生成し、ダウンストリームに書き込みます。
INSERT INTO `test.t1` (`A`,`B`) VALUES (1,2),(2,2),(3,3);
UPDATE `test`.`t1`
SET `A` = CASE
WHEN `A` = 1 THEN 1
WHEN `A` = 2 THEN 2
END, `B` = CASE
WHEN `A` = 1 THEN 4
WHEN `A` = 2 THEN 4
END
WHERE `A` = 1 OR `A` = 2;
サポートされていないシナリオ
現在、次のシナリオはサポートされていません。
- RawKV のみを使用する TiKV クラスター。
- TiDBの
CREATE SEQUENCEDDL操作とSEQUENCE関数 。上流のTiDBがSEQUENCE使用する場合、TiCDCは上流で実行されるSEQUENCEDDL操作/関数を無視します。ただし、SEQUENCE関数を使用するDML操作は正しく複製されます。 - 現在、TiCDCによって複製されているテーブルおよびデータベースにTiDB Lightning物理インポートモードを使用してデータをインポートすることはサポートされていません。詳細については、 TiDB Lightning物理インポート モードと TiCDC 間の互換性の制限は何ですか?参照してください。
- v8.2.0より前のバージョンでは、 BRはTiCDCレプリケーションタスクを含むクラスターに対してデータの復元サポートしていません。詳細については、 BR (バックアップと復元) と TiCDC 間の互換性の制限は何ですか?参照してください。
- v8.2.0以降、 BRはTiCDCのデータ復元に関する制限を緩和しました。復元対象データの
BackupTS(バックアップ時刻)が変更フィードCheckpointTS(現在のレプリケーションの進行状況を示すタイムスタンプ)よりも前であれば、 BRは通常通りデータ復元を続行できます。5BackupTS通常それよりもずっと前であることを考慮すると、ほとんどのシナリオにおいて、 BRはTiCDCレプリケーションタスクを含むクラスターのデータ復元をサポートしていると推測できます。
TiCDCは、アップストリームにおける大規模トランザクションを含むシナリオを部分的にしかサポートしていません。詳細については、 TiCDCFAQを参照してください。TiCDCが大規模トランザクションの複製をサポートしているかどうか、および関連するリスクについて詳しく説明されています。