TiCDC クラシックアーキテクチャ
このドキュメントでは、TiCDC の従来のアーキテクチャと動作原理について説明します。
注記:
- このドキュメントは、v8.5.4-release.1 より前のバージョンの TiCDC に適用されます。
- v8.5.4-release.1以降、TiCDCは、リソースコストを削減しながら、リアルタイムデータレプリケーションのパフォーマンス、スケーラビリティ、安定性を向上させる新しいアーキテクチャを導入しました。詳細については、 TiCDC の新しいアーキテクチャご覧ください。
TiCDC クラシックアーキテクチャ
複数のTiCDCノードで構成されるTiCDCクラスターは、分散型かつステートレスなアーキテクチャを採用しています。TiCDCとそのコンポーネントの設計は次のとおりです。
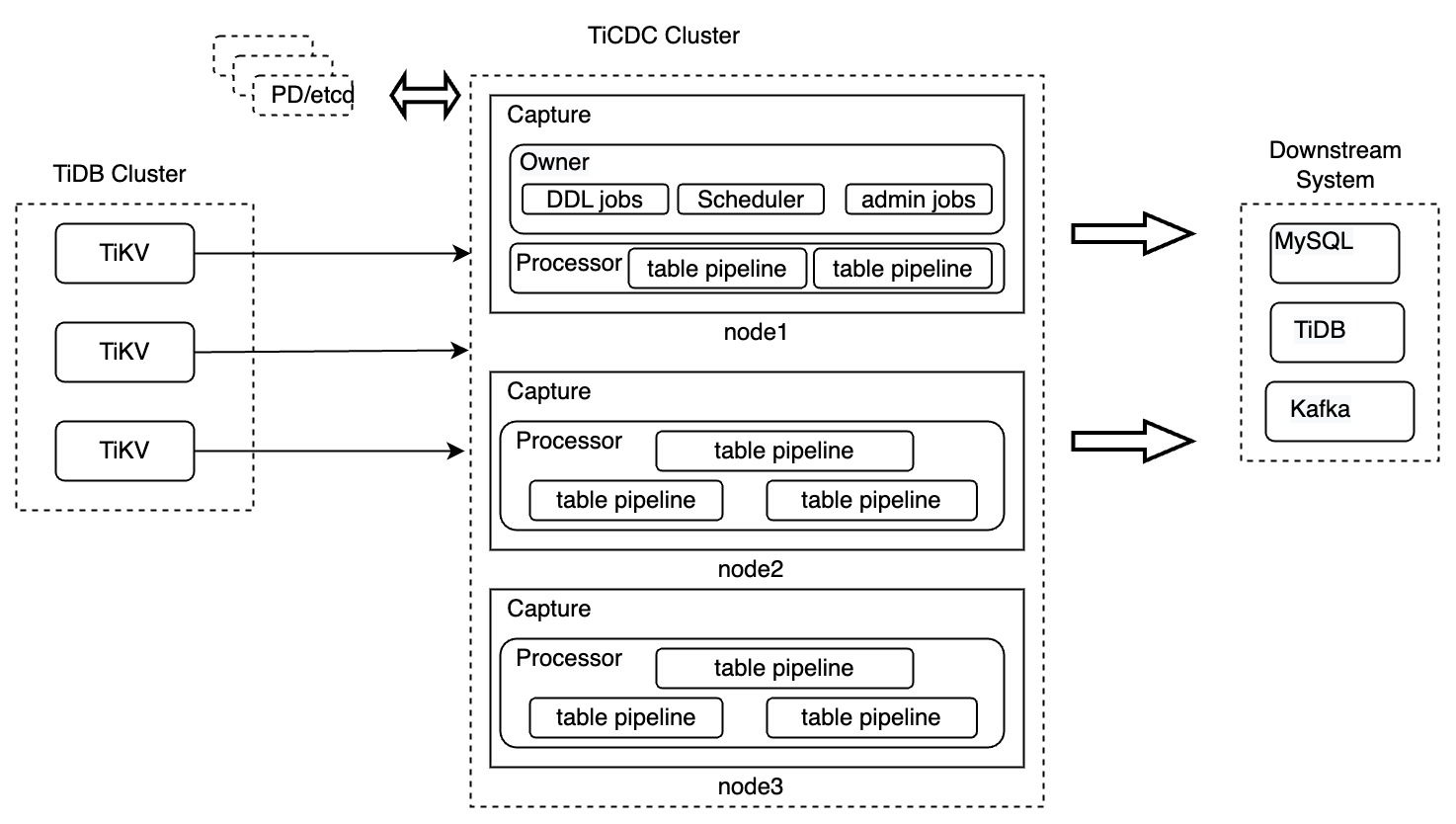
TiCDC コンポーネント
上の図では、TiCDC クラスターは TiCDC インスタンスを実行する複数のノードで構成されています。各 TiCDC インスタンスはキャプチャプロセスを実行します。キャプチャプロセスの 1 つがオーナーキャプチャとして選出され、ワークロードのスケジュール設定、DDL ステートメントのレプリケーション、および管理タスクの実行を担当します。
各キャプチャプロセスには、上流TiDBのテーブルからデータを複製するための1つまたは複数のプロセッサスレッドが含まれています。テーブルはTiCDCにおけるデータ複製の最小単位であるため、プロセッサは複数のテーブルパイプラインで構成されます。
各パイプラインには、プラー、ソーター、マウンター、シンクのコンポーネントが含まれています。
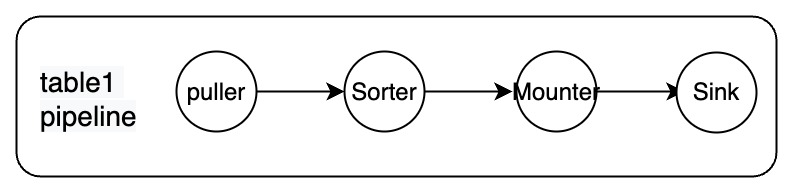
これらのコンポーネントは、データのプル、データのソート、データのロード、上流から下流へのデータの複製など、レプリケーションプロセスを完了するために、互いに連続して動作します。各コンポーネントの説明は以下のとおりです。
- プーラー: TiKV ノードから DDL と行の変更をプルします。
- ソーター: TiKV ノードから受信した変更をタイムスタンプの昇順で並べ替えます。
- マウンター: スキーマ情報に基づいて、変更を TiCDC シンクが処理できる形式に変換します。
- シンク: 変更を下流のシステムに複製します。
高可用性を実現するために、各 TiCDC クラスターは複数の TiCDC ノードを実行します。これらのノードは、PD 内の etcd クラスターに定期的にステータスを報告し、いずれかのノードを TiCDC クラスターのオーナーとして選出します。オーナーノードは、etcd に保存されているステータスに基づいてデータをスケジュールし、スケジューリング結果を etcd に書き込みます。プロセッサは、etcd のステータスに従ってタスクを完了します。プロセッサを実行しているノードに障害が発生した場合、クラスターは他のノードにテーブルをスケジュールします。オーナーノードに障害が発生した場合、他のノードのキャプチャプロセスによって新しいオーナーが選出されます。次の図を参照してください。
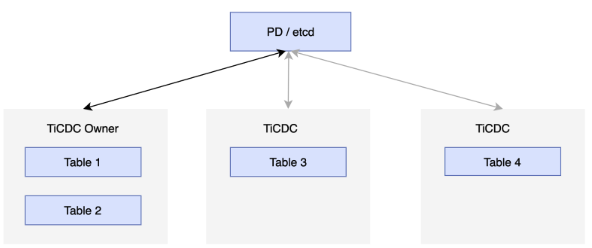
チェンジフィードとタスク
TiCDCにおけるChangefeedとTaskは、2つの論理的な概念です。具体的な説明は次のとおりです。
- Changefeed: レプリケーションタスクを表します。レプリケート対象のテーブルと下流のテーブルに関する情報を保持します。
- タスク: TiCDCはレプリケーションタスクを受信すると、このタスクを複数のサブタスクに分割します。これらのサブタスクはタスクと呼ばれます。これらのタスクは、TiCDCノードのキャプチャプロセスに割り当てられ、処理されます。
例えば:
cdc cli changefeed create --server="http://127.0.0.1:8300" --sink-uri="kafka://127.0.0.1:9092/cdc-test?kafka-version=2.4.0&partition-num=6&max-message-bytes=67108864&replication-factor=1"
cat changefeed.toml
......
[sink]
dispatchers = [
{matcher = ['test1.tab1', 'test2.tab2'], topic = "{schema}_{table}"},
{matcher = ['test3.tab3', 'test4.tab4'], topic = "{schema}_{table}"},
]
前述のcdc cli changefeed createコマンドのパラメータの詳細については、 TiCDC Changefeedコンフィグレーションパラメータ参照してください。
上記のコマンドcdc cli changefeed createは、 test1.tab1 、 test1.tab2 、 test3.tab3 、 test4.tab4 Kafkaクラスターに複製する changefeed タスクを作成します。TiCDCがこのコマンドを受信した後の処理フローは以下のとおりです。
- TiCDC はこのタスクを所有者のキャプチャ プロセスに送信します。
- 所有者の Capture プロセスは、この changefeed タスクに関する情報を PD の etcd に保存します。
- 所有者のキャプチャ プロセスは、変更フィード タスクを複数のタスクに分割し、完了するタスクを他のキャプチャ プロセスに通知します。
- キャプチャ プロセスは TiKV ノードからデータの取得を開始し、データを処理してレプリケーションを完了します。
以下は、Changefeed と Task が含まれた TiCDCアーキテクチャ図です。
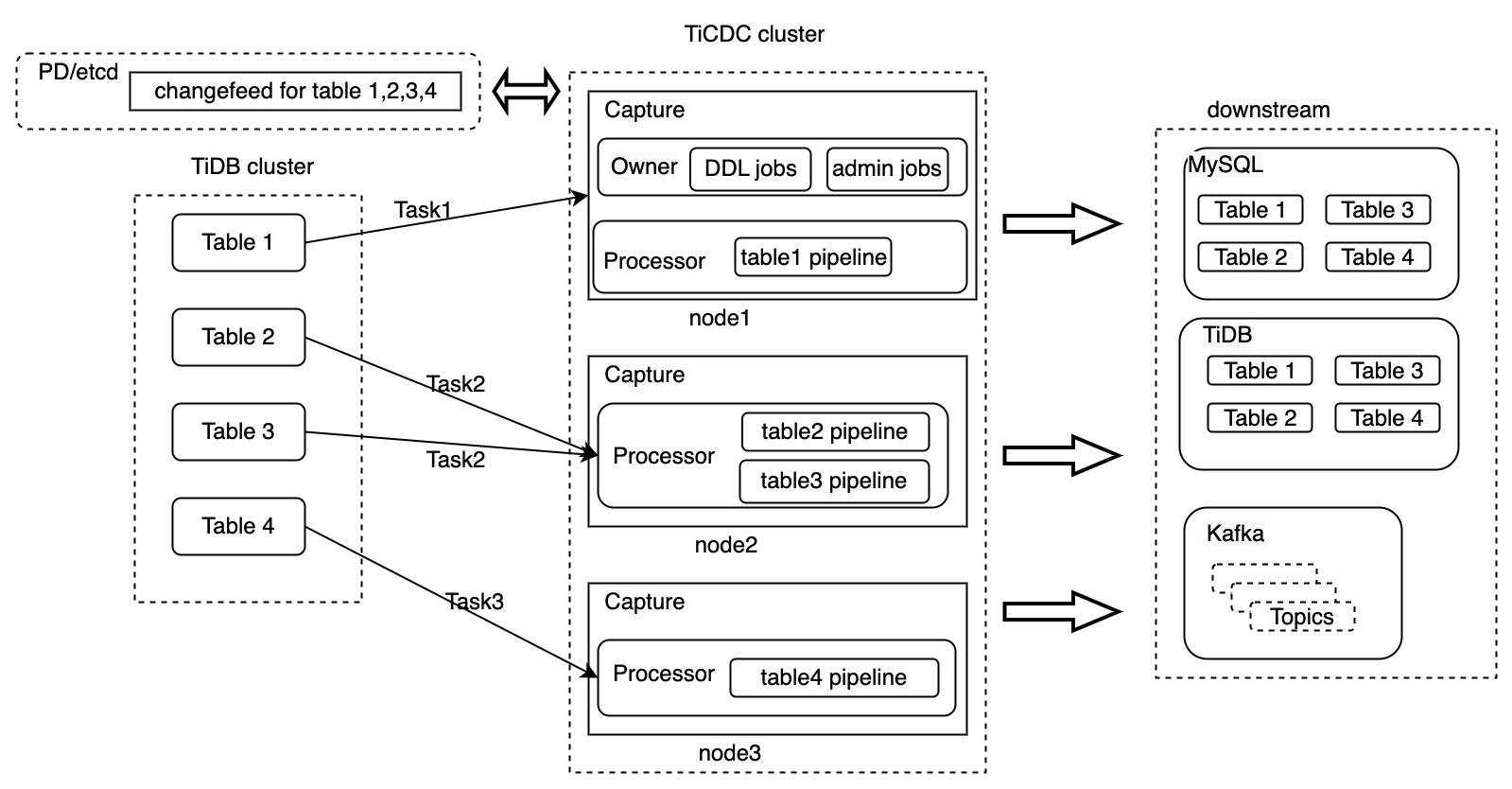
上の図では、4つのテーブルを下流に複製するための変更フィードが作成されています。この変更フィードは3つのタスクに分割され、TiCDCクラスター内の3つのキャプチャプロセスにそれぞれ送信されます。TiCDCがデータを処理した後、データは下流システムに複製されます。
TiCDCは、MySQL、TiDB、Kafkaデータベースへのデータレプリケーションをサポートしています。上の図は、チェンジフィードレベルでのデータ転送プロセスのみを示しています。以下のセクションでは、テーブルtable1をレプリケーションするタスク1を例に、TiCDCがデータを処理する方法を詳しく説明します。
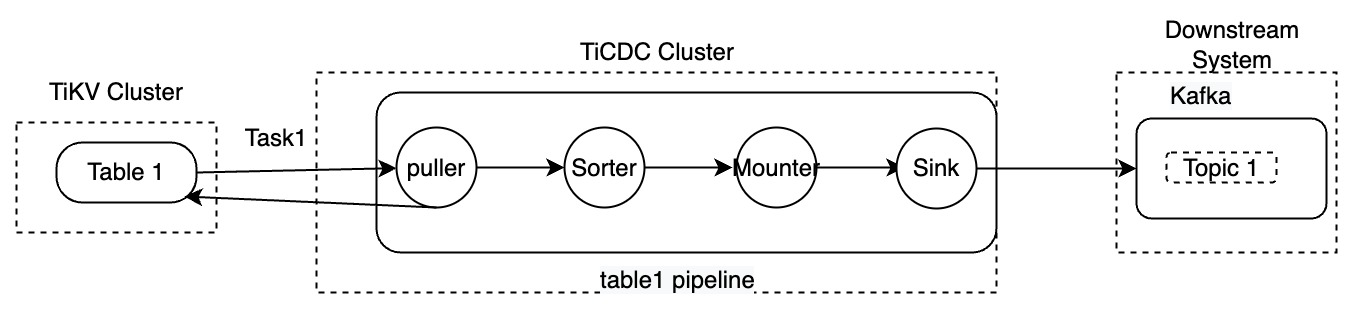
- データのプッシュ: データの変更が発生すると、TiKV はデータを Puller モジュールにプッシュします。
- 増分データをスキャン: 受信したデータの変更が連続していないことを検出すると、Puller モジュールは TiKV からデータをプルします。
- データのソート: Sorter モジュールは、TiKV から受信したデータをタイムスタンプに基づいてソートし、ソートされたデータを Mounter モジュールに送信します。
- データのマウント: データの変更を受信すると、Mounter モジュールは TiCDC シンクが理解できる形式でデータをロードします。
- データの複製: シンク モジュールは、データの変更をダウンストリームに複製します。
TiCDCの上流は、トランザクションをサポートする分散リレーショナルデータベースTiDBです。TiCDCはデータを複製する際に、複数のテーブルを複製する際にデータとトランザクションの一貫性を確保する必要がありますが、これは大きな課題です。以下のセクションでは、この課題に対処するためにTiCDCが使用する主要なテクノロジーとコンセプトを紹介します。
TiCDCの主要概念
下流のリレーショナルデータベースでは、TiCDC は単一テーブル内のトランザクションの一貫性と、複数テーブルにおける最終的なトランザクションの一貫性を保証します。さらに、TiCDC は上流の TiDB クラスターで発生したデータ変更が下流に少なくとも 1 回は複製されることを保証します。
建築関連の概念
- キャプチャ:TiCDCノードを実行するプロセス。複数のキャプチャプロセスがTiCDCクラスターを構成します。各キャプチャプロセスは、TiKVへのデータ変更のレプリケーション(データ変更の受信とアクティブプル、ダウンストリームへのデータレプリケーションなど)を担当します。
- キャプチャオーナー:複数のキャプチャプロセスにおけるキャプチャのオーナー。TiCDCクラスタには、一度に1つのオーナーロールのみが存在します。キャプチャオーナーは、クラスタ内のデータのスケジュール設定を担当します。
- プロセッサ: Captureノード内の論理スレッド。各プロセッサは、同じレプリケーションストリーム内の1つ以上のテーブルのデータを処理する役割を担います。Captureノードは複数のプロセッサを実行できます。
- チェンジフィード: 上流のTiDBクラスタから下流のシステムにデータを複製するタスク。チェンジフィードには複数のタスクが含まれ、各タスクはキャプチャノードによって処理されます。
タイムスタンプ関連の概念
TiCDCは、データ複製の状態を示すために、一連のタイムスタンプ(TS)を導入します。これらのタイムスタンプは、データが下流に少なくとも1回複製され、データの一貫性が保証されることを保証するために使用されます。
解決済みTS
このタイムスタンプは TiKV と TiCDC の両方に存在します。
TiKVにおけるResolvedTS:リージョンリーダーにおける最も古いトランザクションの開始時刻を表します。つまり、
ResolvedTS= max(ResolvedTS, min(StartTS)) です。TiDBクラスターには複数のTiKVノードが含まれるため、すべてのTiKVノードにおけるリージョンリーダーのResolvedTSの最小値はグローバルResolvedTSと呼ばれます。TiDBクラスターは、グローバルResolvedTSより前のすべてのトランザクションがコミットされることを保証します。あるいは、このタイムスタンプより前にコミットされていないトランザクションは存在しないと仮定することもできます。TiCDC の解決済みTS:
- テーブルResolvedTS: 各テーブルにはテーブルレベルのResolvedTSがあり、これはテーブル内のResolvedTSより小さいデータ変更がすべて受信されたことを示します。簡単に言うと、このタイムスタンプは、TiKVノード上のこのテーブルに対応するすべてのリージョンのResolvedTSの最小値と同じです。
- global ResolvedTS: すべてのTiCDCノード上のすべてのプロセッサの最小ResolvedTS。各TiCDCノードには1つ以上のプロセッサがあるため、各プロセッサは複数のテーブルパイプラインに対応します。
TiCDCの場合、TiKVから送信されるResolvedTSは
<resolvedTS: timestamp>形式の特別なイベントです。一般に、ResolvedTSは以下の制約を満たします。table ResolvedTS >= global ResolvedTS
チェックポイントTS
このタイムスタンプはTiCDCにのみ存在します。これは、このタイムスタンプより前に発生したデータ変更が下流システムに複製されていることを意味します。
- テーブル CheckpointTS: TiCDC はテーブル内のデータを複製するため、テーブル checkpointTS は、CheckpointTS がテーブル レベルで複製される前に発生したすべてのデータ変更を示します。
- プロセッサ CheckpointTS: プロセッサ上の最小テーブル CheckpointTS を示します。
- グローバル CheckpointTS: すべてのプロセッサ間の最小 CheckpointTS を示します。
一般に、チェックポイントTS は次の制約を満たします。
table CheckpointTS >= global CheckpointTS
TiCDC はグローバル ResolvedTS よりも小さいデータのみをダウンストリームに複製するため、完全な制約は次のようになります。
table ResolvedTS >= global ResolvedTS >= table CheckpointTS >= global CheckpointTS
データの変更とトランザクションがコミットされた後、TiKVノードのResolvedTSは引き続き進み、TiCDCノードのPullerモジュールはTiKVからプッシュされたデータを受信し続けます。Pullerモジュールは受信したデータの変更に基づいて増分データをスキャンするかどうかも決定し、すべてのデータ変更がTiCDCノードに送信されるようにします。
Sorterモジュールは、Pullerモジュールが受信したデータをタイムスタンプの昇順でソートします。このプロセスにより、テーブルレベルでのデータの一貫性が確保されます。次に、Mounterモジュールは、上流からのデータ変更をSinkモジュールが処理できる形式に組み立て、Sinkモジュールに送信します。Sinkモジュールは、CheckpointTSとResolvedTS間のデータ変更をタイムスタンプ順に下流に複製し、下流がデータ変更を受信した後にCheckpointTSを進めます。
これまでのセクションでは、DMLステートメントのデータ変更についてのみ説明しており、DDLステートメントについては触れていません。以下のセクションでは、DDLステートメントに関連するタイムスタンプについて説明します。
バリアTS
バリア TS は、DDL 変更イベントが発生したとき、または同期ポイントが使用されたときに生成されます。
- DDL変更イベント:バリアTSは、DDL文の実行前におけるすべての変更が下流に複製されることを保証します。このDDL文が実行され、複製された後、TiCDCは他のデータ変更の複製を開始します。DDL文はキャプチャオーナーによって処理されるため、DDL文に対応するバリアTSはオーナーノードによってのみ生成されます。
- 同期ポイント:TiCDCの同期ポイント機能を有効にすると、指定した
sync-point-intervalに基づいてTiCDCによってバリアTSが生成されます。このバリアTS以前のすべてのテーブル変更がレプリケーションされると、TiCDCは現在のグローバルチェックポイントTSをプライマリTSとして、下流のtsMapを記録するテーブルに挿入します。その後、TiCDCはデータレプリケーションを続行します。
バリアTSが生成されると、TiCDCは、このバリアTSより前に発生したデータ変更のみが下流にレプリケートされるようにします。これらのデータ変更が下流にレプリケートされるまでは、レプリケーションタスクは続行されません。オーナーTiCDCは、グローバルチェックポイントTSとバリアTSを継続的に比較することで、すべてのターゲットデータがレプリケートされたかどうかを確認します。グローバルチェックポイントTSがバリアTSと等しい場合、TiCDCは指定された操作(DDL文の実行、グローバルチェックポイントTSの下流への記録など)を実行した後、レプリケーションを続行します。それ以外の場合、TiCDCはバリアTSより前に発生したすべてのデータ変更が下流にレプリケートされるまで待機します。
主なプロセス
このセクションでは、TiCDC の主なプロセスについて説明し、その動作原理をより深く理解できるようにします。
以下のプロセスはTiCDC内でのみ実行され、ユーザーからは透過的に行われるため、どのTiCDCノードを起動するかを気にする必要はありません。
TiCDCを開始する
所有者ではない TiCDC ノードの場合は、次のように動作します。
- キャプチャ プロセスを開始します。
- プロセッサを起動します。
- 所有者によって実行されたタスク スケジュール コマンドを受け取ります。
- スケジュール コマンドに従って tablePipeline を開始または停止します。
所有者 TiCDC ノードの場合、次のように動作します。
- キャプチャ プロセスを開始します。
- ノードがオーナーとして選出され、対応するスレッドが開始されます。
- 変更フィード情報を読み取ります。
- 変更フィード管理プロセスを開始します。
- 変更フィード構成と最新の CheckpointTS に従って TiKV 内のスキーマ情報を読み取り、複製するテーブルを決定します。
- 各プロセッサによって現在複製されているテーブルのリストを読み取り、追加するテーブルを配布します。
- レプリケーションの進行状況を更新します。
TiCDCを停止する
通常、TiCDCノードを停止するのは、アップグレードや計画的なメンテナンス作業を行う必要がある場合です。TiCDCノードを停止するプロセスは次のとおりです。
- ノードは自身を停止するコマンドを受信します。
- ノードはサービス ステータスを利用不可に設定します。
- ノードは新しいレプリケーション タスクの受信を停止します。
- ノードは、オーナー ノードにデータ複製タスクを他のノードに転送するように通知します。
- レプリケーション タスクが他のノードに転送されると、ノードは停止します。