TiCDC の新しいアーキテクチャ
TiCDC v8.5.4-リリース.1から、TiCDC は、リソース コストを削減しながら、リアルタイム データ レプリケーションのパフォーマンス、スケーラビリティ、および安定性を向上させる新しいアーキテクチャを導入します。
この新しいアーキテクチャは、TiCDCのコアコンポーネントを再設計し、データ処理ワークフローを最適化しながら、 古典的なTiCDCアーキテクチャの構成、使用方法、APIとの互換性を維持しています。これにより、以下の利点が得られます。
- 単一ノードのパフォーマンスの向上: 単一ノードで最大 500,000 個のテーブルを複製でき、ワイド テーブル シナリオでは単一ノードで最大 190 MiB/秒のレプリケーション スループットを実現します。
- 拡張性の向上:クラスタレプリケーション機能はほぼ直線的に拡張可能です。単一のクラスタで100ノード以上に拡張でき、10,000以上の変更フィードをサポートし、単一の変更フィード内で数百万のテーブルをレプリケートできます。
- 安定性の向上:高トラフィック、頻繁なDDL操作、クラスターのスケーリングイベントが発生するシナリオにおいて、チェンジフィードのレイテンシーが短縮され、パフォーマンスがより安定します。リソースの分離と優先スケジューリングにより、複数のチェンジフィードタスク間の干渉が軽減されます。
- リソース コストの削減: リソース使用率の向上と冗長性の削減により、一般的なシナリオでは CPU とメモリのリソース使用量を最大 50% 削減できます。
建築設計
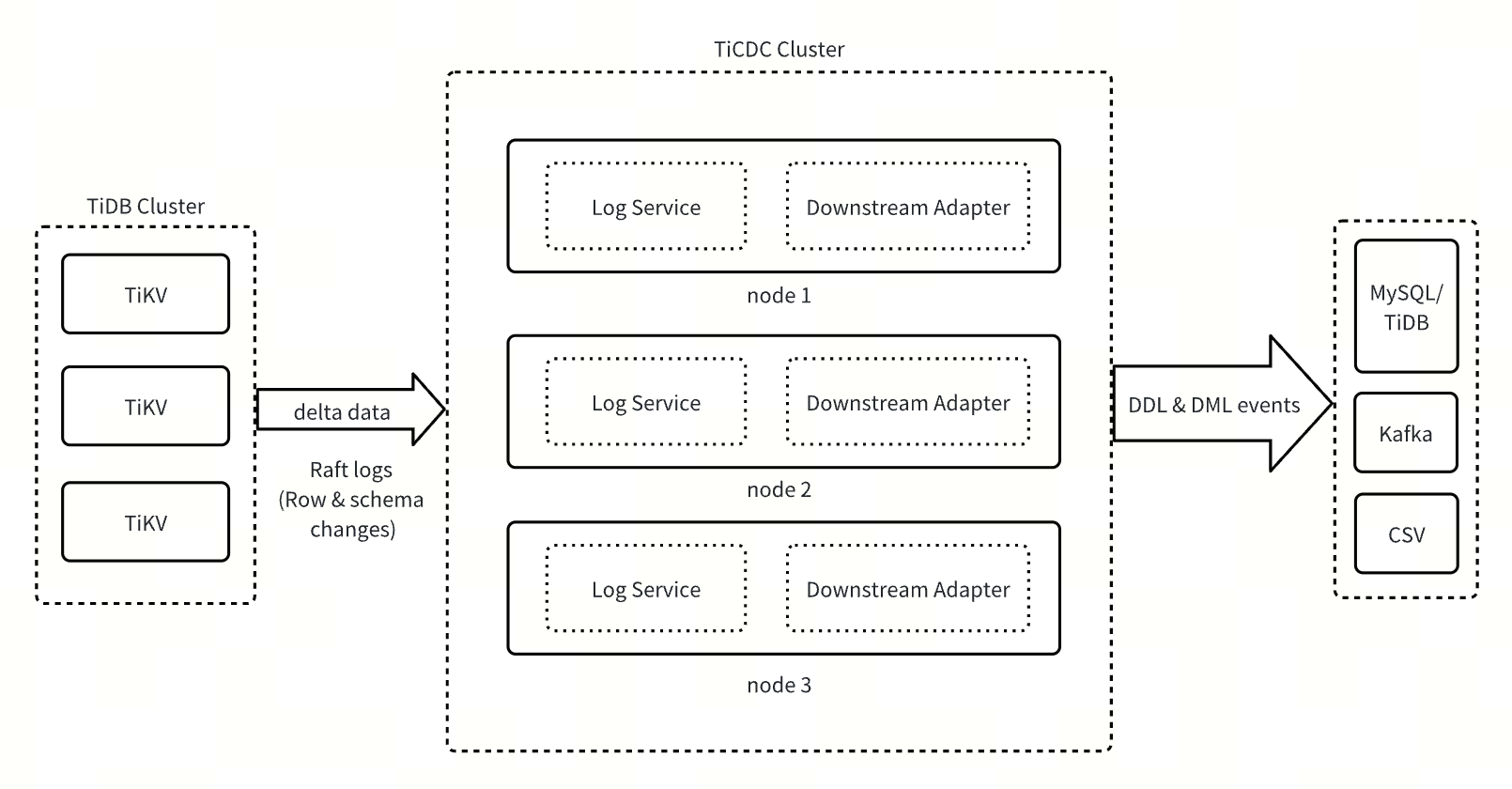
TiCDC の新しいアーキテクチャは、ログ サービスとダウンストリーム アダプターの 2 つのコア コンポーネントで構成されます。
- ログサービス:コアデータサービスレイヤーとして、ログサービスは上流TiDBクラスタから行変更やDDLイベントなどの情報を取得し、変更データをローカルディスクに一時的に保存します。また、下流アダプタからのデータ要求に応答し、DMLデータとDDLデータを定期的にマージおよびソートし、ソート済みのデータを下流アダプタにプッシュします。
- ダウンストリームアダプタ:ダウンストリームデータレプリケーション適応レイヤーとして、ダウンストリームアダプタはユーザーが開始した変更フィード操作を処理します。関連するレプリケーションタスクをスケジュールおよび生成し、ログサービスからデータを取得し、取得したデータをダウンストリームシステムに複製します。
TiCDCの新しいアーキテクチャは、アーキテクチャをステートフルコンポーネントとステートレスコンポーネントに分離することで、システムのスケーラビリティ、信頼性、柔軟性を大幅に向上させます。ステートフルコンポーネントであるログサービスは、データの取得、ソート、storageに重点を置いています。ログサービスをチェンジフィード処理ロジックから分離することで、複数のチェンジフィード間でのデータ共有が可能になり、リソース使用率を効果的に向上させ、システムオーバーヘッドを削減します。ステートレスコンポーネントであるダウンストリームアダプタは、軽量なスケジューリングメカニズムを使用して、インスタンス間でのレプリケーションタスクの迅速な移行を可能にします。ワークロードの変化に基づいてレプリケーションタスクの分割とマージを動的に調整できるため、さまざまなシナリオで低レイテンシのレプリケーションを実現します。
古典的なアーキテクチャと新しいアーキテクチャの比較
新しいアーキテクチャは、パフォーマンスのボトルネック、不十分な安定性、スケーラビリティの限界など、システムの継続的なスケーリング時に古典アーキテクチャする一般的な問題に対処するように設計されています。1と比較して、新しいアーキテクチャは以下の主要な側面において大幅な最適化を実現しています。
クラシックアーキテクチャと新しいアーキテクチャから選択
ワークロードが次のいずれかの条件を満たす場合は、パフォーマンスと安定性を向上させるために、アーキテクチャ古典的なTiCDCアーキテクチャから新しいアーキテクチャに切り替えることをお勧めします。
- 増分スキャン パフォーマンスのボトルネック: 増分スキャン タスクの完了に非常に長い時間がかかり、レプリケーションのレイテンシーが継続的に増加します。
- 超高トラフィック シナリオ: 合計変更フィード トラフィックが 700 MiB/s を超えます。
- MySQL シンクでの高スループット書き込みを備えた単一テーブル: ターゲット テーブルには主キーまたは null 以外の一意のキーが 1 つだけあります。
- 大規模なテーブルレプリケーション: 複製するテーブルの数が 100,000 を超えます。
- 頻繁な DDL 操作によるレイテンシーの発生: DDL ステートメントを頻繁に実行すると、レプリケーションのレイテンシーが大幅に増加します。
新機能
新しいアーキテクチャは、すべてのシンクに対してテーブルレベルのタスク分割をサポートします。この機能を有効にするには、changefeed 設定でscheduler.enable-table-across-nodes = true設定します。
この機能を有効にすると、TiCDCは、以下のいずれかの条件を満たすテーブルを複数のノードに自動的に分割して分散し、並列レプリケーションを実行します。これにより、レプリケーションの効率とリソース利用率が向上します。
- テーブルのリージョン数が設定されたしきい値 (デフォルトでは
10000ですが、scheduler.region-thresholdで調整可能) を超えています。 - テーブル書き込みトラフィックが設定されたしきい値を超えています (デフォルトでは無効、
scheduler.write-key-thresholdで設定可能)。
注記:
MySQL シンク変更フィードの場合、テーブル分割モードでのデータ レプリケーションの正確性を確保するために、前述の条件のいずれかを満たし、主キーまたは null 以外の一意のキーを 1 つだけ持つテーブルのみが TiCDC によって分割および分散されます。
互換性
DDL 進捗追跡テーブル
TiCDCの従来のアーキテクチャでは、DDLレプリケーション操作は厳密にシリアル化されているため、レプリケーションの進行状況は変更フィードのCheckpointTsを使用してのみ追跡できます。しかし、新しいアーキテクチャでは、TiCDCは可能な限り異なるテーブルのDDL変更を並列にレプリケートすることで、DDLレプリケーションの効率を向上させます。下流のMySQL互換データベースの各テーブルのDDLレプリケーションの進行状況を正確に記録するために、TiCDCの新しいアーキテクチャは下流データベースにtidb_cdc.ddl_ts_v1という名前のテーブルを作成し、変更フィードのDDLレプリケーションの進行状況情報を具体的に保存します。
DDLレプリケーション動作の変更
従来のTiCDCアーキテクチャでは、テーブル名を入れ替えるDDL(例:
RENAME TABLE a TO c, b TO a, c TO b;)はサポートされていません。新しいアーキテクチャでは、このようなDDLがサポートされています。新しいアーキテクチャでは、
RENAMEDDL のフィルタリング ルールが統合され、簡素化されます。クラシックアーキテクチャでは、フィルタリング ロジックは次のようになります。
- 単一テーブルの名前変更: 古いテーブル名がフィルター ルールと一致する場合にのみ、DDL ステートメントが複製されます。
- 複数テーブルの名前変更: 古いテーブル名と新しいテーブル名の両方がフィルター ルールに一致する場合にのみ、DDL ステートメントが複製されます。
新しいアーキテクチャでは、単一テーブルと複数テーブルの両方の名前変更において、ステートメント内の古いテーブル名がフィルター ルールと一致する限り、DDL ステートメントが複製されます。
次のフィルタ ルールを例に挙げます。
[filter] rules = ['test.t*']- クラシックアーキテクチャの場合:
RENAME TABLE test.t1 TO ignore.t1のような単一テーブルの名前変更では、古いテーブル名test.t1ルールに一致するため、レプリケートされます。5RENAME TABLE test.t1 TO ignore.t1, test.t2 TO test.t22;ような複数テーブルの名前変更では、新しいテーブル名ignore.t1ルールに一致しないため、レプリケートされません。 - 新しい TiCDCアーキテクチャでは、
RENAME TABLE test.t1 TO ignore.t1とRENAME TABLE test.t1 TO ignore.t1, test.t2 TO test.t22;の両方の古いテーブル名がルールに一致するため、両方の DDL ステートメントが複製されます。
- クラシックアーキテクチャの場合:
制限事項
新しいTiCDCアーキテクチャには、従来のアーキテクチャのすべての機能が組み込まれています。ただし、一部の機能はまだ完全にテストされていません。システムの安定性を確保するため、以下の機能は本番本番環境での使用は推奨されません。
さらに、新しいTiCDCアーキテクチャは現在、ダウンストリームレプリケーションのために大規模なトランザクションを複数のバッチに分割することをサポートしていません。そのため、非常に大規模なトランザクションを処理する際には、依然としてOOMのリスクが存在します。新しいアーキテクチャを使用する前に、このリスクを適切に評価し、軽減するようにしてください。
アップグレードガイド
新しいアーキテクチャの TiCDC は、TiDB クラスター v7.5.0 以降にのみ導入できます。導入前に、TiDB クラスターがこの要件を満たしていることを確認してください。
TiUPまたはTiDB Operator を使用して、新しいアーキテクチャに TiCDC ノードをデプロイできます。
新しいアーキテクチャで TiCDC ノードを使用して新しい TiDB クラスターをデプロイ
TiUPを使用して v8.5.4 以降の新しい TiDB クラスターをデプロイする際に、同時に新しいアーキテクチャの TiCDC ノードもデプロイできます。これを行うには、 TiUP がTiDB クラスターの起動に使用する設定ファイルに TiCDC 関連のセクションを追加し、 newarch: true設定するだけです。以下は例です。
cdc_servers:
- host: 10.0.1.20
config:
newarch: true
- host: 10.0.1.21
config:
newarch: true
TiCDC の展開の詳細については、 TiUPを使用して TiCDC を含む新しい TiDB クラスターをデプロイ。参照してください。
TiDB Operator を使用して v8.5.4 以降の新しい TiDB クラスターをデプロイする際に、同時に新しいアーキテクチャの TiCDC ノードもデプロイできます。そのためには、クラスター設定ファイルに TiCDC 関連のセクションを追加し、 newarch = true設定するだけです。以下は例です。
spec:
ticdc:
baseImage: pingcap/ticdc
version: v8.5.4
replicas: 3
config:
newarch = true
TiCDC の展開の詳細については、 新しい TiCDC の展開参照してください。
既存の TiDB クラスタに新しいアーキテクチャの TiCDC ノードをデプロイ
TiUPを使用して新しいアーキテクチャに TiCDC ノードを展開するには、次の手順を実行します。
TiDBクラスターにまだTiCDCノードが存在しない場合は、 TiCDC クラスターをスケールアウトするを参照してクラスターに新しいTiCDCノードを追加してください。そうでない場合は、この手順をスキップしてください。
TiDBクラスタのバージョンがv8.5.4より前の場合は、新しいアーキテクチャのTiCDCバイナリパッケージを手動でダウンロードし、ダウンロードしたファイルをTiDBクラスタにパッチ適用する必要があります。それ以外の場合は、この手順をスキップしてください。
ダウンロード リンクの形式は
https://tiup-mirrors.pingcap.com/cdc-${version}-${os}-${arch}.tar.gzです${version}は TiCDC のバージョン (使用可能なバージョンについては新しいアーキテクチャ向けのTiCDCリリース参照)、${os}はオペレーティング システム、${arch}はコンポーネントが実行されるプラットフォーム (amd64またはarm64) です。たとえば、Linux (x86-64) 用の TiCDC v8.5.4-release.1 のバイナリ パッケージをダウンロードするには、次のコマンドを実行します。
wget https://tiup-mirrors.pingcap.com/cdc-v8.5.4-release.1-linux-amd64.tar.gzTiDB クラスターで変更フィードが実行中の場合は、 レプリケーションタスクを一時停止するを参照して、変更フィードのすべてのレプリケーション タスクを一時停止します。
# The default server port of TiCDC is 8300. cdc cli changefeed pause --server=http://<ticdc-host>:8300 --changefeed-id <changefeed-name>tiup cluster patchコマンドを使用して、ダウンロードした TiCDC バイナリ ファイルを TiDB クラスターにパッチ適用します。tiup cluster patch <cluster-name> ./cdc-v8.5.4-release.1-linux-amd64.tar.gz -R cdc --overwrite新しいアーキテクチャを有効にするには、
tiup cluster edit-configコマンドを使用して TiCDC 構成を更新します。tiup cluster edit-config <cluster-name>server_configs: cdc: newarch: trueすべてのレプリケーション タスクを再開するには、 レプリケーションタスクを再開するを参照してください。
# The default server port of TiCDC is 8300. cdc cli changefeed resume --server=http://<ticdc-host>:8300 --changefeed-id <changefeed-name>
TiDB Operatorを使用して既存の TiDB クラスターに新しいアーキテクチャの TiCDC ノードをデプロイするには、次の手順を実行します。
TiDBクラスタにTiCDCコンポーネントが含まれていない場合は、 既存の TiDB クラスターに TiCDC を追加する参照して新しいTiCDCノードを追加してください。その際、クラスタ構成ファイルで新しいアーキテクチャバージョンとしてTiCDCイメージバージョンを指定してください。使用可能なバージョンについては、 新しいアーキテクチャ向けのTiCDCリリース参照してください。
例えば:
spec: ticdc: baseImage: pingcap/ticdc version: v8.5.4-release.1 replicas: 3 config: newarch = trueTiDB クラスターにすでに TiCDCコンポーネントが含まれている場合は、次の手順を実行します。
TiDB クラスターで変更フィードが実行されている場合は、変更フィードのすべてのレプリケーション タスクを一時停止します。
kubectl exec -it ${pod_name} -n ${namespace} -- sh# The default server port of TiCDC deployed via TiDB Operator is 8301. /cdc cli changefeed pause --server=http://127.0.0.1:8301 --changefeed-id <changefeed-name>クラスター構成ファイル内の TiCDC イメージ バージョンを新しいアーキテクチャバージョンに更新します。
kubectl edit tc ${cluster_name} -n ${namespace}spec: ticdc: baseImage: pingcap/ticdc version: v8.5.4-release.1 replicas: 3kubectl apply -f ${cluster_name} -n ${namespace}変更フィードのすべてのレプリケーション タスクを再開します。
kubectl exec -it ${pod_name} -n ${namespace} -- sh# The default server port of TiCDC deployed via TiDB Operator is 8301. /cdc cli changefeed resume --server=http://127.0.0.1:8301 --changefeed-id <changefeed-name>
新しいアーキテクチャを使用する
新しいアーキテクチャでTiCDCノードをデプロイした後も、クラシックアーキテクチャと同じコマンドを引き続き使用できます。新しいコマンドを学習したり、クラシックアーキテクチャで使用されていたコマンドを変更したりする必要はありません。
たとえば、新しいアーキテクチャで新しい TiCDC ノードのレプリケーション タスクを作成するには、次のコマンドを実行します。
cdc cli changefeed create --server=http://127.0.0.1:8300 --sink-uri="mysql://root:123456@127.0.0.1:3306/" --changefeed-id="simple-replication-task"
特定のレプリケーション タスクの詳細を照会するには、次のコマンドを実行します。
cdc cli changefeed query -s --server=http://127.0.0.1:8300 --changefeed-id=simple-replication-task
コマンドの使用方法や詳細については、 チェンジフィードを管理する参照してください。
監視
新しいアーキテクチャにおけるTiCDCの監視ダッシュボードはTiCDC-New-Archです。v8.5.4以降のバージョンのTiDBクラスターでは、この監視ダッシュボードはクラスターのデプロイまたはアップグレード時にGrafanaに統合されるため、手動操作は不要です。v8.5.4より前のバージョンのクラスターをご利用の場合は、監視を有効にするためにTiCDC 監視メトリックファイル手動でインポートする必要があります。
インポート手順と各監視メトリックの詳細な説明については、 新しいアーキテクチャにおける TiCDC のメトリクス参照してください。