Confluent Cloud、Snowflake、ksqlDB、SQL Server とデータを統合
Confluentは、Apache Kafka互換のストリーミングデータプラットフォームであり、強力なデータ統合機能を提供します。このプラットフォームでは、ノンストップのリアルタイムストリーミングデータにアクセス、保存、管理できます。
TiDB v6.1.0以降、TiCDCはAvro形式でConfluentへの増分データのレプリケーションをサポートします。本ドキュメントでは、 TiCDC使用してTiDBの増分データをConfluentにレプリケーションし、さらにConfluent Cloud経由でSnowflake、ksqlDB、SQL Serverにデータをレプリケーションする方法を紹介します。本ドキュメントの構成は以下のとおりです。
- TiCDC が組み込まれた TiDB クラスターを迅速に展開します。
- TiDB から Confluent Cloud にデータを複製する変更フィードを作成します。
- Confluent Cloud から Snowflake、ksqlDB、SQL Server にデータを複製するコネクタを作成します。
- go-tpc を使用して TiDB にデータを書き込み、Snowflake、ksqlDB、SQL Server のデータの変更を観察します。
上記の手順はラボ環境で実行されています。これらの手順を参考に、本番環境にクラスターをデプロイすることもできます。
増分データをConfluent Cloudに複製する
ステップ1. 環境を設定する
TiCDC が含まれた TiDB クラスターをデプロイ。
ラボまたはテスト環境では、 TiUP Playground を使用して、TiCDC が組み込まれた TiDB クラスターを迅速にデプロイできます。
tiup playground --host 0.0.0.0 --db 1 --pd 1 --kv 1 --tiflash 0 --ticdc 1 # View cluster status tiup statusTiUPがまだインストールされていない場合は、 TiUPをインストールするを参照してください。実本番環境では、 TiCDCをデプロイの手順に従って TiCDC を展開できます。
Confluent Cloud を登録し、Confluent クラスターを作成します。
ベーシッククラスタを作成し、インターネット経由でアクセスできるようにします。詳細はConfluent Cloud のクイックスタート参照してください。
ステップ2. アクセスキーペアを作成する
クラスター API キーを作成します。
Confluent Cloudにサインインします。データ統合> APIキー>キーの作成 を選択します。表示されるAPIキーのスコープの選択ページで、グローバルアクセスを選択します。
作成後、以下に示すようにキー ペア ファイルが生成されます。
=== Confluent Cloud API key: xxx-xxxxx === API key: L5WWA4GK4NAT2EQV API secret: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx Bootstrap server: xxx-xxxxx.ap-east-1.aws.confluent.cloud:9092スキーマ レジストリ エンドポイントを記録します。
Confluent Cloud Console で、 「スキーマレジストリ」 > 「API エンドポイント」を選択します。スキーマレジストリエンドポイントを記録します。以下は例です。
https://yyy-yyyyy.us-east-2.aws.confluent.cloudスキーマ レジストリ API キーを作成します。
Confluent Cloud Console で、 「スキーマレジストリ」 > 「API 認証情報」を選択します。 「編集」をクリックし、 「キーの作成」をクリックします。
作成後、次に示すようにキー ペア ファイルが生成されます。
=== Confluent Cloud API key: yyy-yyyyy === API key: 7NBH2CAFM2LMGTH7 API secret: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxこの手順はConfluent CLIを使用して実行することもできます。詳細についてはConfluent CLI を Confluent Cloudクラスタに接続する参照してください。
ステップ3. Kafkaの変更フィードを作成する
changefeed 構成ファイルを作成します。
AvroおよびConfluent Connectorの要件に従い、各テーブルの増分データは独立したトピックに送信され、イベントごとに主キーの値に基づいてパーティションがディスパッチされる必要があります。そのため、以下の内容を含むchangefeed設定ファイル
changefeed.confを作成する必要があります。[sink] dispatchers = [ {matcher = ['*.*'], topic = "tidb_{schema}_{table}", partition="index-value"}, ]設定ファイルの
dispatchersの詳細な説明についてはKafka シンクのトピックおよびパーティションディスパッチャーのルールをカスタマイズする参照してください。増分データを Confluent Cloud に複製するための変更フィードを作成します。
tiup cdc:v<CLUSTER_VERSION> cli changefeed create --server="http://127.0.0.1:8300" --sink-uri="kafka://<broker_endpoint>/ticdc-meta?protocol=avro&replication-factor=3&enable-tls=true&auto-create-topic=true&sasl-mechanism=plain&sasl-user=<broker_api_key>&sasl-password=<broker_api_secret>" --schema-registry="https://<schema_registry_api_key>:<schema_registry_api_secret>@<schema_registry_endpoint>" --changefeed-id="confluent-changefeed" --config changefeed.conf次のフィールドの値をステップ2. アクセスキーペアを作成するで作成または記録された値に置き換える必要があります。
<broker_endpoint><broker_api_key><broker_api_secret><schema_registry_api_key><schema_registry_api_secret><schema_registry_endpoint>
1 の値を置き換える前に、 HTML URL エンコーディングリファレンスに基づいて
<schema_registry_api_secret>エンコードする必要があることに注意してください。上記のすべてのフィールドを置き換えた後、設定ファイルは次のようになります。tiup cdc:v<CLUSTER_VERSION> cli changefeed create --server="http://127.0.0.1:8300" --sink-uri="kafka://xxx-xxxxx.ap-east-1.aws.confluent.cloud:9092/ticdc-meta?protocol=avro&replication-factor=3&enable-tls=true&auto-create-topic=true&sasl-mechanism=plain&sasl-user=L5WWA4GK4NAT2EQV&sasl-password=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" --schema-registry="https://7NBH2CAFM2LMGTH7:xxxxxxxxxxxxxxxxxx@yyy-yyyyy.us-east-2.aws.confluent.cloud" --changefeed-id="confluent-changefeed" --config changefeed.confコマンドを実行して、変更フィードを作成します。
changefeed が正常に作成されると、以下に示すように、changefeed ID などの changefeed 情報が表示されます。
Create changefeed successfully! ID: confluent-changefeed Info: {... changfeed info json struct ...}コマンドを実行しても結果が返されない場合は、コマンドを実行したサーバーとConfluent Cloud間のネットワーク接続を確認してください。詳細はConfluent Cloudへの接続をテストする参照してください。
changefeed を作成した後、次のコマンドを実行して changefeed のステータスを確認します。
tiup cdc:v<CLUSTER_VERSION> cli changefeed list --server="http://127.0.0.1:8300"チェンジフィードを管理するには、 TiCDC チェンジフィードを管理するを参照してください。
ステップ4. 変更ログを生成するためにデータを書き込む
上記の手順が完了すると、TiCDC は TiDB クラスター内の増分データの変更ログを Confluent Cloud に送信します。このセクションでは、TiDB にデータを書き込んで変更ログを生成する方法について説明します。
サービスのワークロードをシミュレートします。
ラボ環境で変更ログを生成するには、go-tpc を使用して TiDB クラスターにデータを書き込むことができます。具体的には、以下のコマンドを実行して TiDB クラスターにデータベース
tpccを作成します。次に、 TiUP bench を使用してこの新しいデータベースにデータを書き込みます。tiup bench tpcc -H 127.0.0.1 -P 4000 -D tpcc --warehouses 4 prepare tiup bench tpcc -H 127.0.0.1 -P 4000 -D tpcc --warehouses 4 run --time 300sgo-tpc の詳細についてはTiDBでTPC-Cテストを実行する方法を参照してください。
Confluent Cloud でデータを観察します。
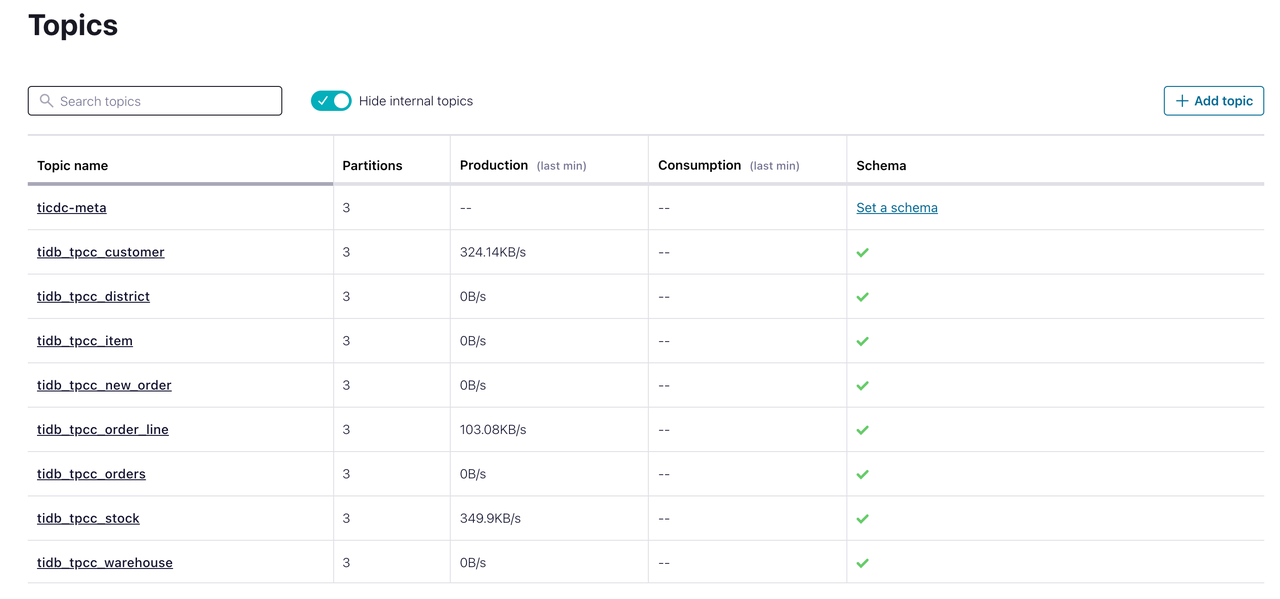
Confluent Cloud コンソールで、 「トピック」をクリックします。対象のトピックが作成され、データを受信していることがわかります。この時点で、TiDB データベースの増分データが Confluent Cloud に正常に複製されています。
Snowflakeとデータを統合する
Snowflakeはクラウドネイティブなデータウェアハウスです。Confluentを使用すると、Snowflakeシンクコネクタを作成することで、TiDBの増分データをSnowflakeに複製できます。
前提条件
- Snowflakeクラスターの登録と作成が完了しましたSnowflakeを使い始める参照してください。
- Snowflakeクラスタに接続する前に、クラスタ用の秘密鍵を生成しておきます。1 キーペア認証とキーペアローテーション参照してください。
統合手順
Snowflake でデータベースとスキーマを作成します。
Snowflakeコントロールコンソールで、 「データ」 > 「データベース」を選択します。5
TPCC名前のデータベースとTiCDCという名前のスキーマを作成します。Confluent Cloud Consoleで、 「データ統合」 > 「コネクタ」 > 「Snowflake Sink」を選択します。以下のページが表示されます。

Snowflakeにレプリケートするトピックを選択してください。次のページに進みます。
Snowflakeに接続するための認証情報を指定します。データベース名とスキーマ名には、前の手順で作成した値を入力してください。次のページに進みます。
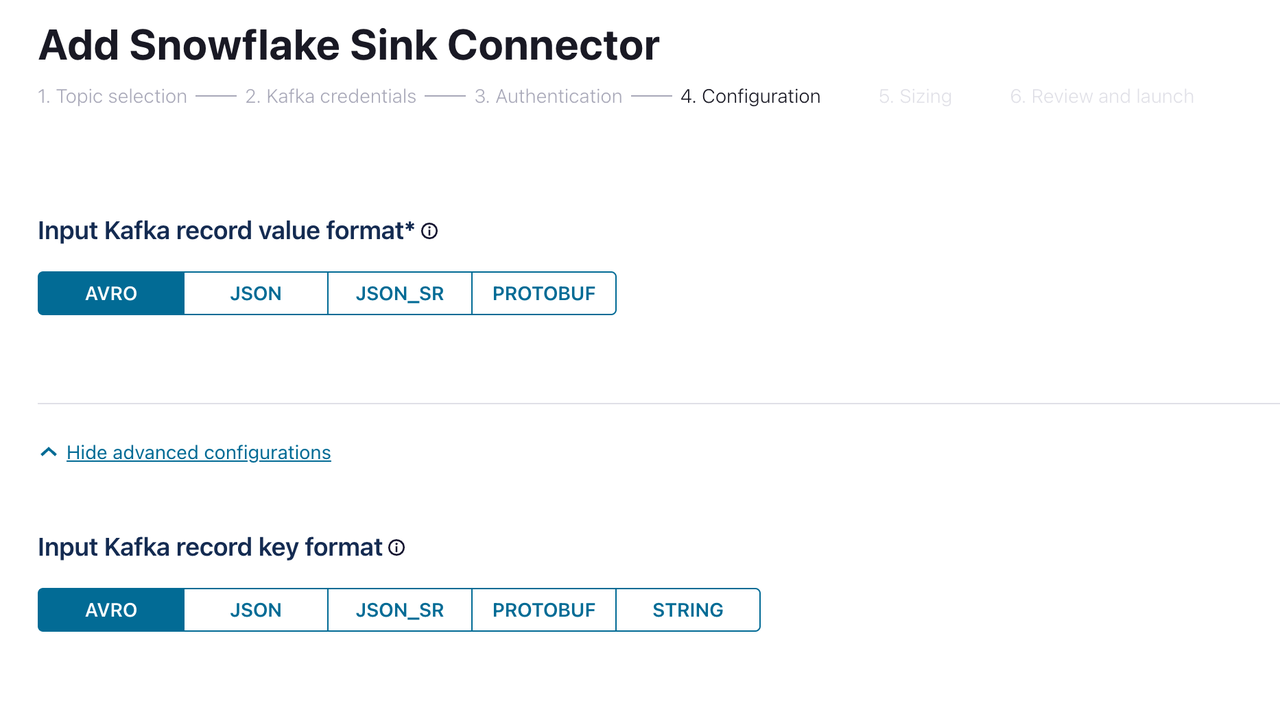
コンフィグレーションページで、入力Kafkaレコード値の形式と入力Kafkaレコードキーの形式の両方に
AVRO選択します。次に、 「続行」をクリックします。コネクタが作成され、ステータスが「実行中」になるまでお待ちください。これには数分かかる場合があります。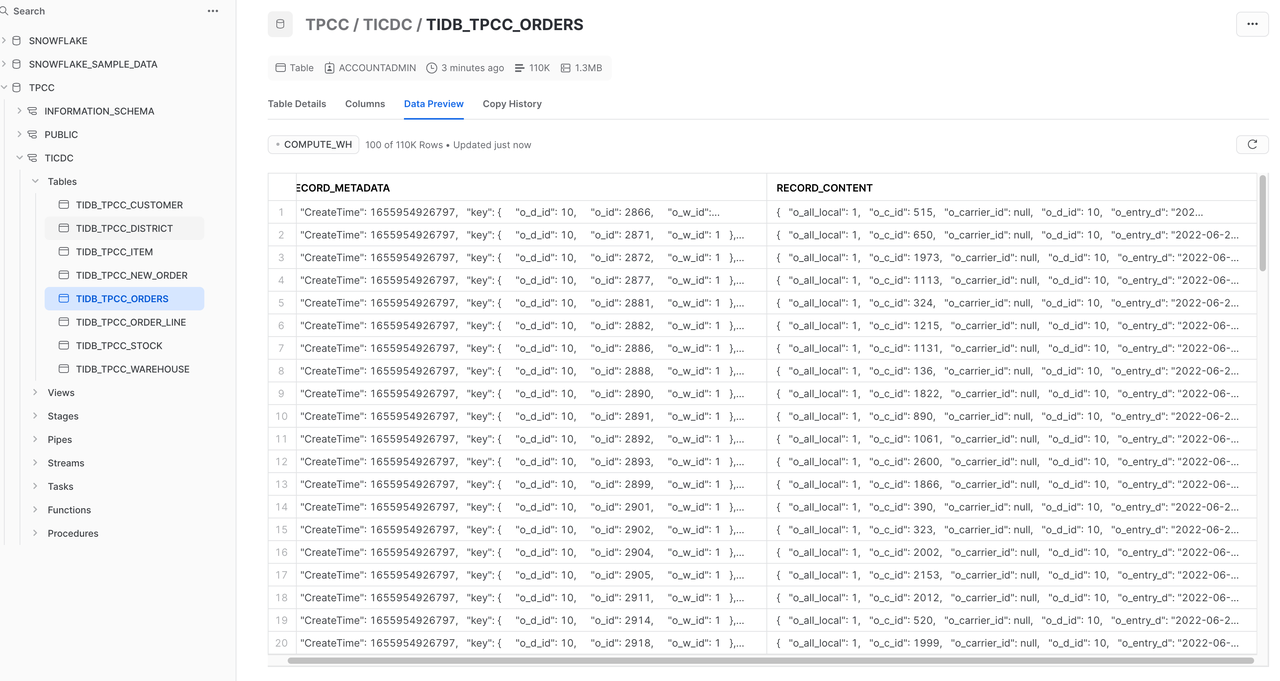
Snowflakeコンソールで、 「データ」 > 「データベース」 > 「TPCC」 > 「TiCDC」を選択します。TiDBの増分データがSnowflakeに複製されていることがわかります。Snowflakeとのデータ統合は完了しています(上図を参照)。ただし、Snowflakeのテーブル構造はTiDBとは異なり、データは増分的にSnowflakeに挿入されます。ほとんどのシナリオでは、SnowflakeのデータはTiDBの変更ログを保存するのではなく、TiDBのデータのレプリカであることが想定されます。この問題については、次のセクションで説明します。
SnowflakeでTiDBテーブルのデータレプリカを作成する
前のセクションでは、TiDB増分データの変更ログがSnowflakeに複製されました。本セクションではUPDATE INSERT応じて処理し、上流と同じ構造のテーブルに書き込むことで、SnowflakeにTiDBテーブルのデータレプリカを作成する方法について説明します。以下ではDELETEイベントタイプITEMのテーブルを例に説明します。
ITEMテーブルの構造は次のとおりです。
CREATE TABLE `item` (
`i_id` int NOT NULL,
`i_im_id` int DEFAULT NULL,
`i_name` varchar(24) DEFAULT NULL,
`i_price` decimal(5,2) DEFAULT NULL,
`i_data` varchar(50) DEFAULT NULL,
PRIMARY KEY (`i_id`)
);
Snowflakeには、Confluent Snowflake Sink Connectorによって自動的に作成されたTIDB_TEST_ITEMというテーブルがあります。テーブル構造は次のとおりです。
create or replace TABLE TIDB_TEST_ITEM (
RECORD_METADATA VARIANT,
RECORD_CONTENT VARIANT
);
Snowflake で、TiDB と同じ構造のテーブルを作成します。
create or replace table TEST_ITEM ( i_id INTEGER primary key, i_im_id INTEGER, i_name VARCHAR, i_price DECIMAL(36,2), i_data VARCHAR );TIDB_TEST_ITEMストリームを作成し、append_onlyからtrueを次のように設定します。create or replace stream TEST_ITEM_STREAM on table TIDB_TEST_ITEM append_only=true;このようにして作成されたストリームは、リアルタイムで
INSERTイベントのみをキャプチャします。具体的には、TiDBでITEM新しい変更ログが生成されると、その変更ログがTIDB_TEST_ITEMに挿入され、ストリームによってキャプチャされます。ストリーム内のデータを処理します。イベントの種類に応じて、
TEST_ITEMテーブル内のストリームデータを挿入、更新、または削除します。--Merge data into the TEST_ITEM table merge into TEST_ITEM n using -- Query TEST_ITEM_STREAM (SELECT RECORD_METADATA:key as k, RECORD_CONTENT:val as v from TEST_ITEM_STREAM) stm -- Match the stream with table on the condition that i_id is equal on k:i_id = n.i_id -- If the TEST_ITEM table contains a record that matches i_id and v is empty, delete this record when matched and IS_NULL_VALUE(v) = true then delete -- If the TEST_ITEM table contains a record that matches i_id and v is not empty, update this record when matched and IS_NULL_VALUE(v) = false then update set n.i_data = v:i_data, n.i_im_id = v:i_im_id, n.i_name = v:i_name, n.i_price = v:i_price -- If the TEST_ITEM table does not contain a record that matches i_id, insert this record when not matched then insert (i_data, i_id, i_im_id, i_name, i_price) values (v:i_data, v:i_id, v:i_im_id, v:i_name, v:i_price) ;上の例では、Snowflakeの
MERGE INTOのステートメントを使用して、ストリームとテーブルを特定の条件で一致させ、レコードの削除、更新、挿入などの対応する操作を実行しています。この例では、以下の3つのシナリオで3つのWHERE句が使用されています。- ストリームとテーブルが一致し、ストリーム内のデータが空の場合、テーブル内のレコードを削除します。
- ストリームとテーブルが一致し、ストリーム内のデータが空でない場合は、テーブル内のレコードを更新します。
- ストリームとテーブルが一致しない場合は、テーブルにレコードを挿入します。
データが常に最新であることを確認するために、手順3のステートメントを定期的に実行してください。Snowflakeの
SCHEDULED TASK機能を使用することもできます。-- Create a TASK to periodically execute the MERGE INTO statement create or replace task STREAM_TO_ITEM warehouse = test -- Execute the TASK every minute schedule = '1 minute' when -- Skip the TASK when there is no data in TEST_ITEM_STREAM system$stream_has_data('TEST_ITEM_STREAM') as -- Merge data into the TEST_ITEM table. The statement is the same as that in the preceding example merge into TEST_ITEM n using (select RECORD_METADATA:key as k, RECORD_CONTENT:val as v from TEST_ITEM_STREAM) stm on k:i_id = n.i_id when matched and IS_NULL_VALUE(v) = true then delete when matched and IS_NULL_VALUE(v) = false then update set n.i_data = v:i_data, n.i_im_id = v:i_im_id, n.i_name = v:i_name, n.i_price = v:i_price when not matched then insert (i_data, i_id, i_im_id, i_name, i_price) values (v:i_data, v:i_id, v:i_im_id, v:i_name, v:i_price) ;
これで、特定のETL機能を備えたデータチャネルが確立されました。このデータチャネルを通じて、TiDBの増分データ変更ログをSnowflakeに複製し、TiDBのデータレプリカを維持し、Snowflakeでデータを使用することができます。
最後のステップは、 TIDB_TEST_ITEMテーブル内の不要なデータを定期的にクリーンアップすることです。
-- Clean up the TIDB_TEST_ITEM table every two hours
create or replace task TRUNCATE_TIDB_TEST_ITEM
warehouse = test
schedule = '120 minute'
when
system$stream_has_data('TIDB_TEST_ITEM')
as
TRUNCATE table TIDB_TEST_ITEM;
ksqlDBとデータを統合する
ksqlDBは、ストリーム処理アプリケーション向けに特別に構築されたデータベースです。Confluent Cloud上にksqlDBクラスターを作成し、TiCDCによって複製された増分データにアクセスできます。
Confluent Cloud Console でksqlDBを選択し、指示に従って ksqlDB クラスターを作成します。
ksqlDB クラスターのステータスが「実行中」になるまでお待ちください。このプロセスには数分かかります。
ksqlDB エディターで次のコマンドを実行して、
tidb_tpcc_ordersトピックにアクセスするためのストリームを作成します。CREATE STREAM orders (o_id INTEGER, o_d_id INTEGER, o_w_id INTEGER, o_c_id INTEGER, o_entry_d STRING, o_carrier_id INTEGER, o_ol_cnt INTEGER, o_all_local INTEGER) WITH (kafka_topic='tidb_tpcc_orders', partitions=3, value_format='AVRO');注文の STREAM データを確認するには、次のコマンドを実行します。
SELECT * FROM ORDERS EMIT CHANGES;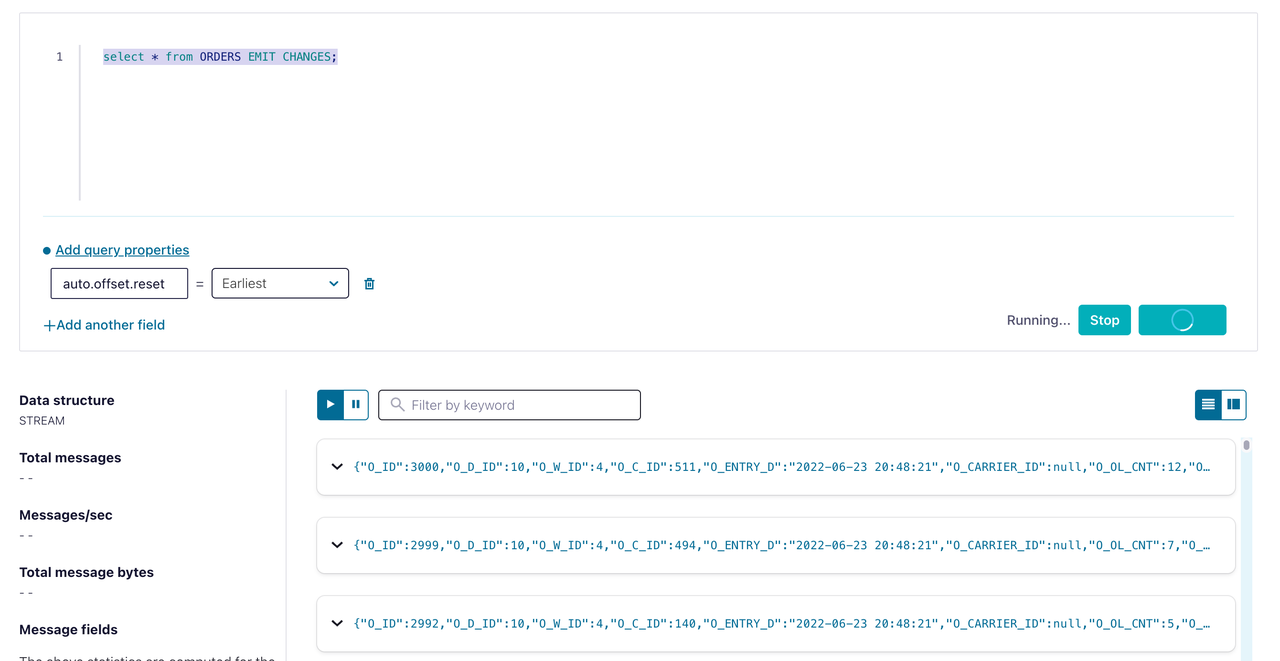
上図に示すように、増分データがksqlDBに複製されたことがわかります。ksqlDBとのデータ統合が完了しました。
SQL Server とデータを統合する
Microsoft SQL Server は、Microsoft が開発したリレーショナルデータベース管理システム (RDBMS) です。Confluent を使用すると、SQL Server シンクコネクタを作成することで、TiDB の増分データを SQL Server に複製できます。
SQL Server に接続し、
tpccという名前のデータベースを作成します。[ec2-user@ip-172-1-1-1 bin]$ sqlcmd -S 10.61.43.14,1433 -U admin Password: 1> create database tpcc 2> go 1> select name from master.dbo.sysdatabases 2> go name ---------------------------------------------------------------------- master tempdb model msdb rdsadmin tpcc (6 rows affected)Confluent Cloud Console で、 「データ統合」 > 「コネクタ」 > 「Microsoft SQL Server Sink」を選択します。以下のページが表示されます。
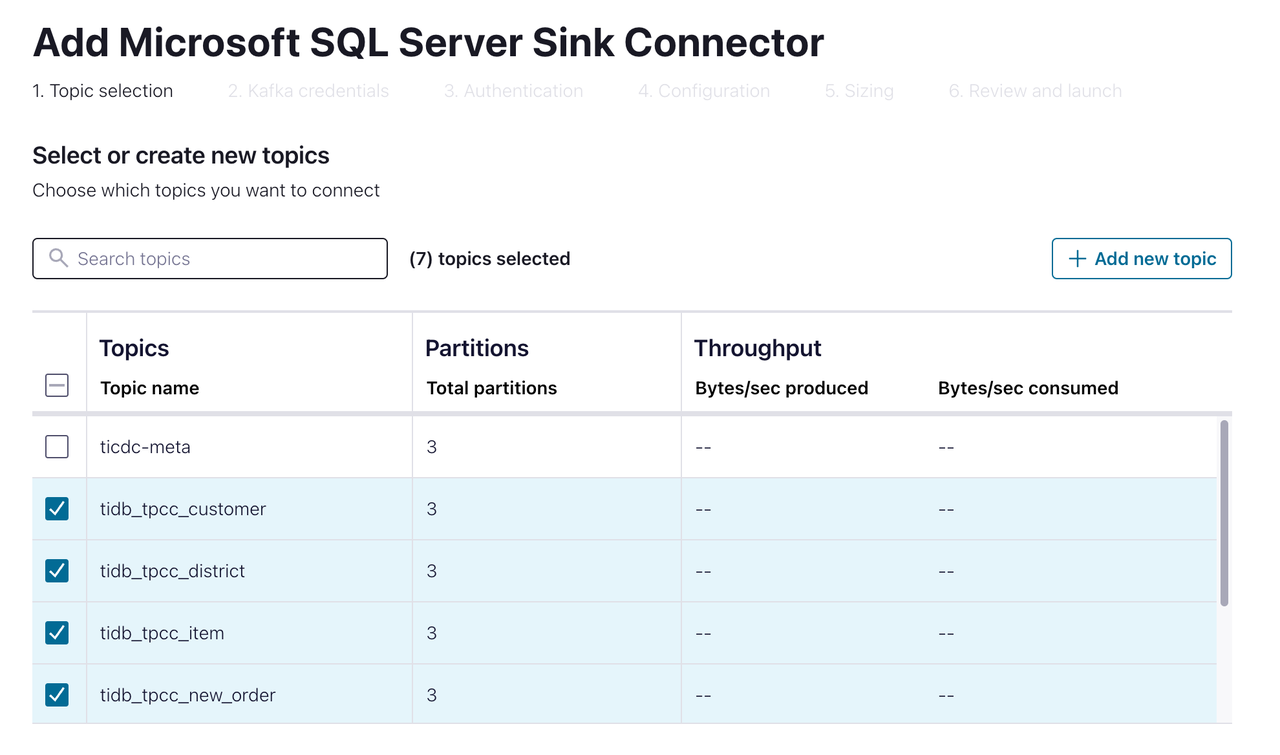
SQL Server にレプリケートするトピックを選択します。次のページに進みます。
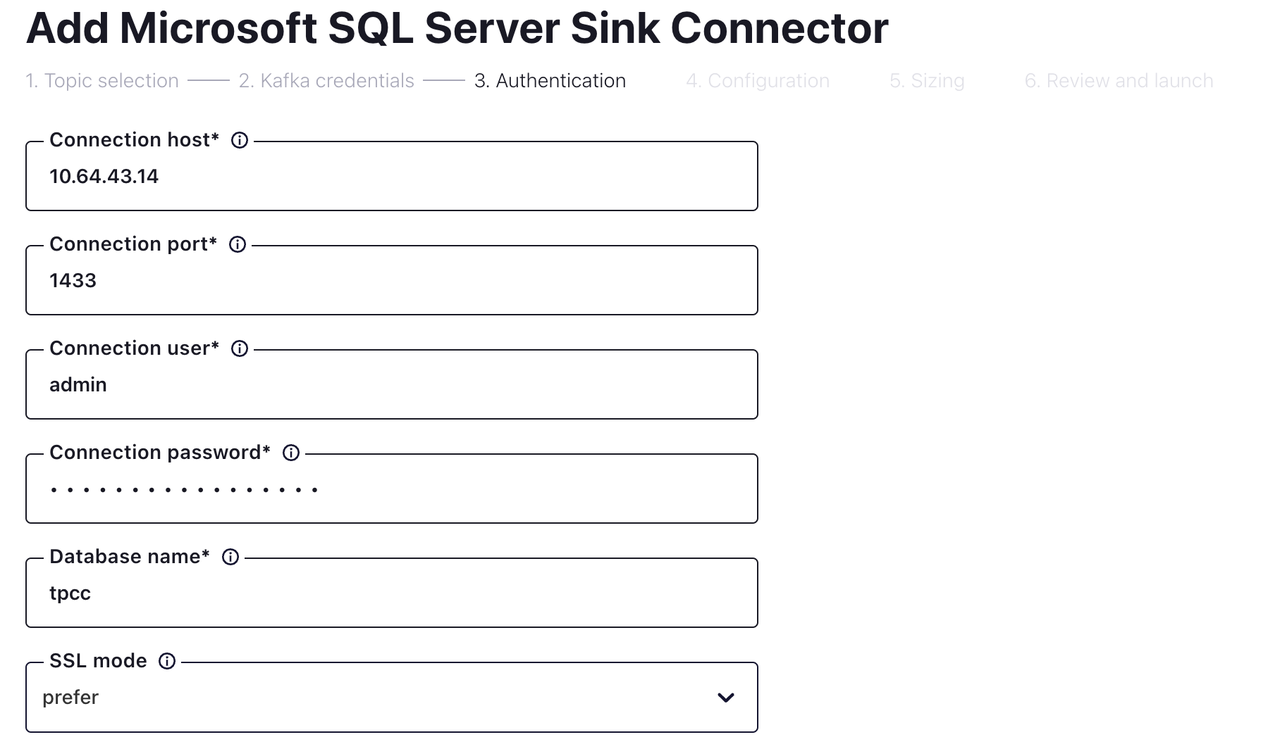
接続情報と認証情報を入力してください。次のページに進んでください。
「コンフィグレーション」ページで次のフィールドを構成し、 「続行」をクリックします。
設定後、 「続行」をクリックします。コネクタのステータスが「実行中」になるまで待ちます。これには数分かかる場合があります。
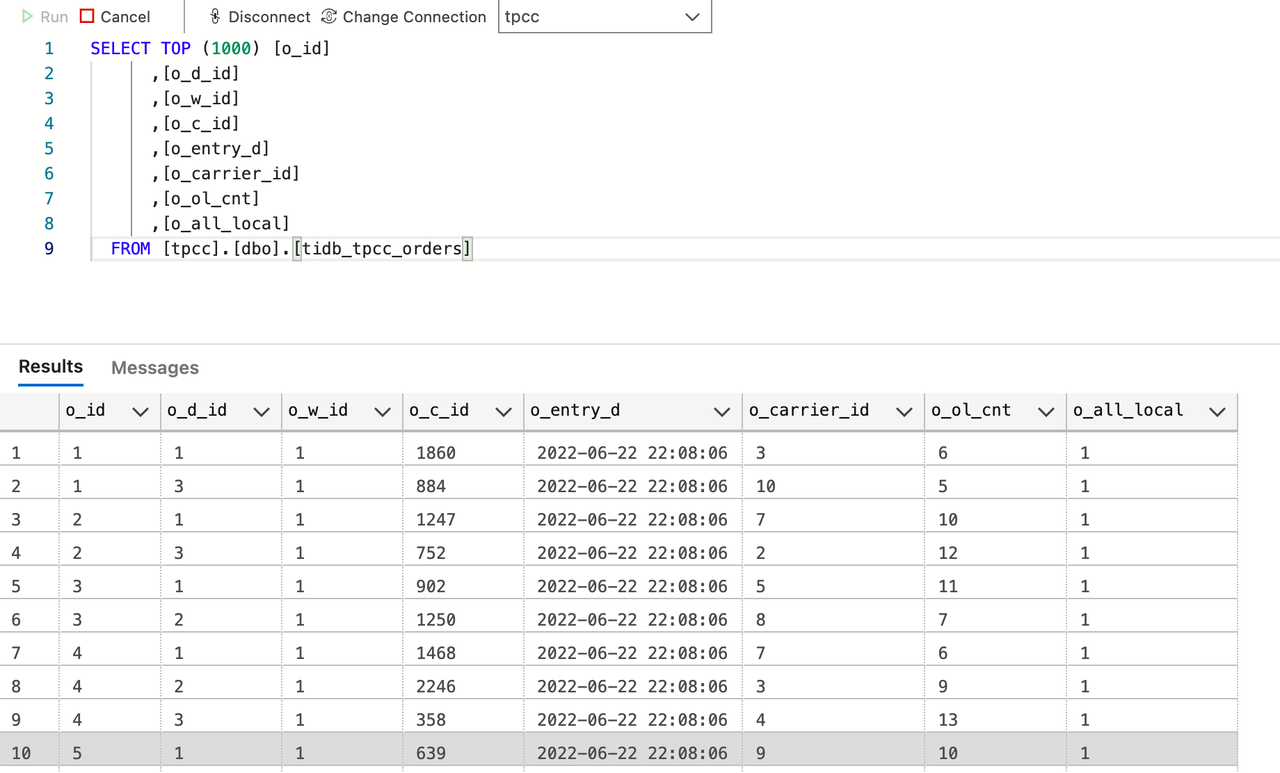
SQL Server に接続し、データを確認します。上図に示すように、増分データが SQL Server に複製されていることがわかります。これで SQL Server とのデータ統合が完了しました。