TiDB 災害復旧ソリューションの概要
このドキュメントでは、TiDBが提供する災害復旧(DR)ソリューションについてご紹介します。このドキュメントの構成は以下のとおりです。
- DR の基本的な概念について説明します。
- TiDB、TiCDC、およびバックアップと復元 ( BR ) のアーキテクチャを紹介します。
- TiDB が提供する DR ソリューションについて説明します。
- これらの DR ソリューションを比較します。
基本概念
- RTO (目標復旧時間): システムが災害から回復するのに必要な時間。
- RPO (目標復旧ポイント): 災害時に企業が許容できるデータ損失の最大量。
次の図は、これら 2 つの概念を示しています。
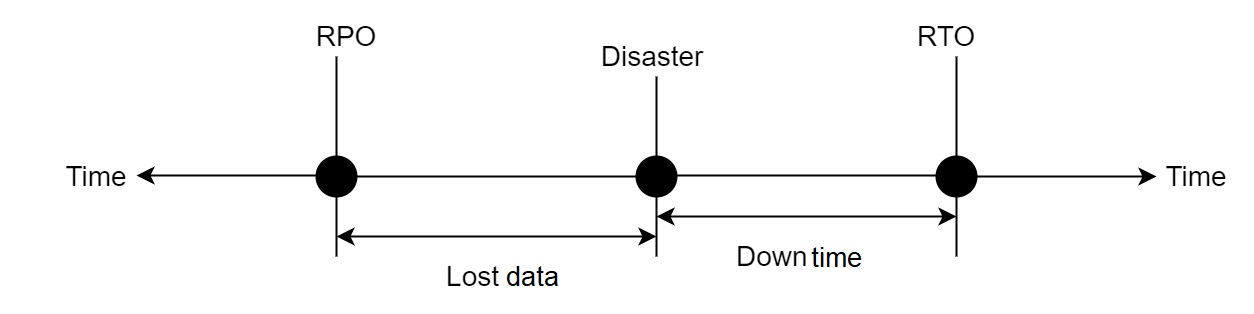
- エラー許容目標:災害は複数の地域に影響を及ぼす可能性があるためです。このドキュメントでは、「エラー許容目標」という用語は、システムが許容できる災害の最大範囲を表すために使用されます。
- リージョン: このドキュメントは地域 DR に焦点を当てており、ここで言及されている「地域」は地理的なエリアまたは都市を指します。
コンポーネントアーキテクチャ
具体的な DR ソリューションを紹介する前に、このセクションでは、TiDB、TiCDC、 BRなどの TiDB コンポーネントのアーキテクチャをDR の観点から紹介します。
TiDB
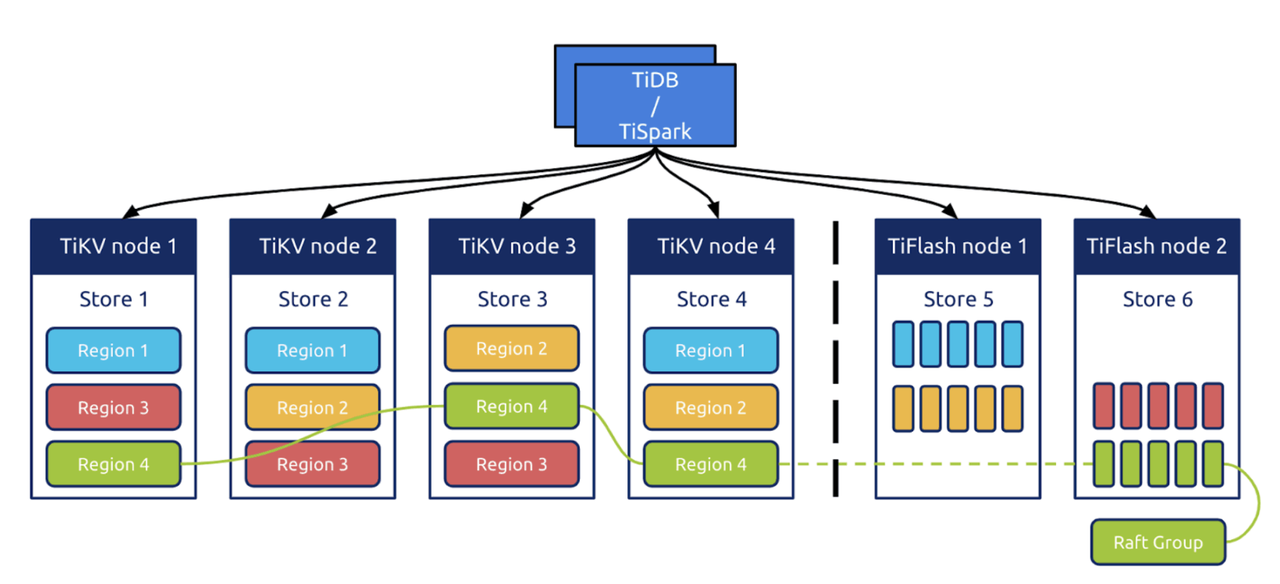
TiDB は、コンピューティングとstorageを分離したアーキテクチャで設計されています。
- TiDB はシステムの SQL コンピューティングレイヤーです。
- TiKVはシステムのstorageレイヤーであり、行ベースのstorageエンジンです。1 リージョン TiKVにおけるデータのスケジューリングの基本単位です。リージョンはソートされたデータ行の集合です。リージョン内のデータは少なくとも3つのレプリカに保存され、データの変更はRaftプロトコルを介してログレイヤーに複製されます。
- オプションコンポーネントTiFlashは、分析クエリを高速化するために使用できる列指向storageエンジンです。データは、 Raftグループの学習者ロールを通じてTiKVからTiFlashに複製されます。
TiDBは3つの完全なデータレプリカを保存します。そのため、複数のレプリカに基づくDR(ディザスタリカバリ)が可能です。同時に、TiDBはRaftログを使用してトランザクションログを複製するため、トランザクションログのレプリケーションに基づくDRも提供できます。
TiCDC
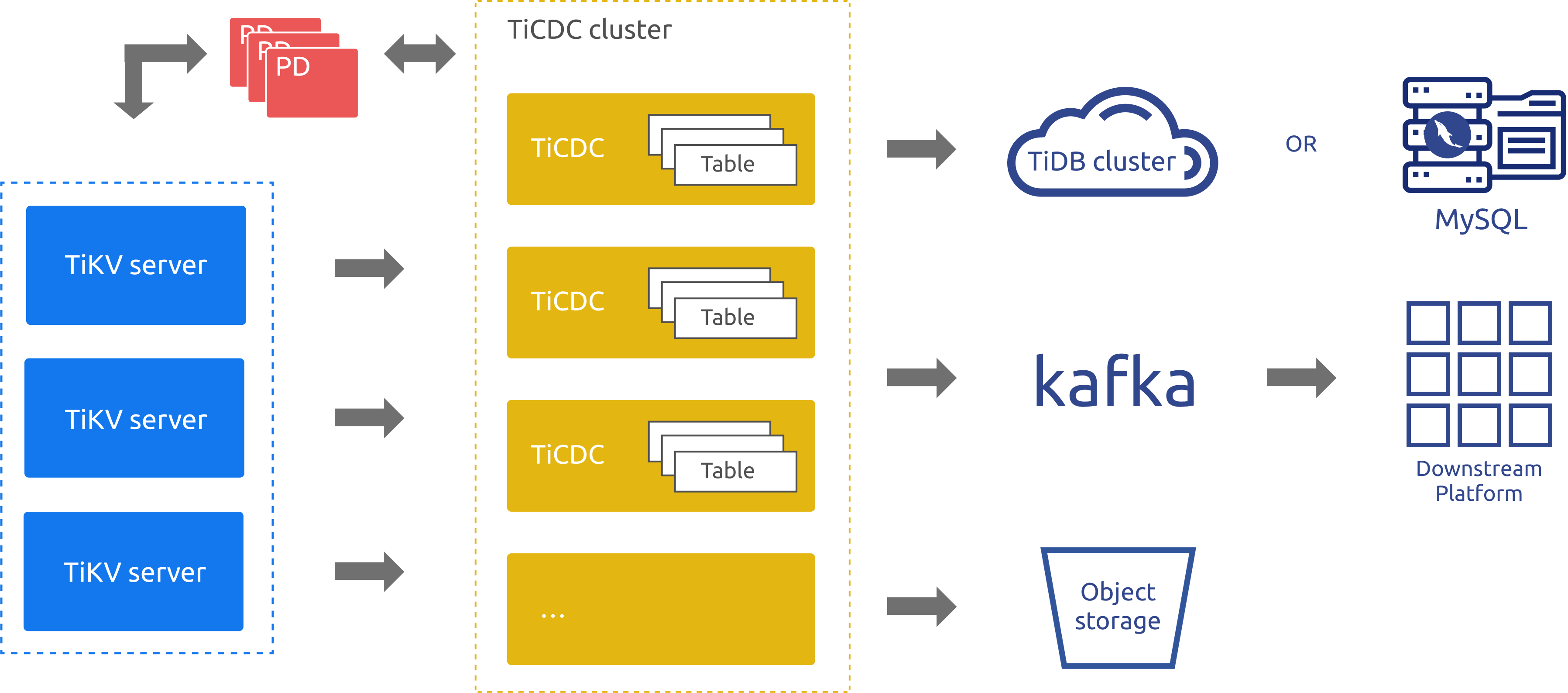
TiDBの増分データレプリケーションツールであるTiCDCは、PDのetcdを通じて高可用性を実現します。TiCDCは、複数のキャプチャプロセスを通じてTiKVノードからデータ変更を取得し、内部でデータ変更をソートおよびマージします。その後、複数のレプリケーションタスクを使用して、複数の下流システムにデータを複製します。上記のアーキテクチャ図では、次のようになっています。
- TiKVサーバー:上流のデータ変更をTiCDCノードに送信します。TiCDCノードは変更ログが連続していないと判断した場合、TiKVサーバーに変更ログの提供を積極的に要求します。
- TiCDC: 複数のキャプチャプロセスを実行します。各キャプチャプロセスはKV変更ログの一部を取得し、取得したデータをソートしてから、変更内容を異なる下流システムに複製します。
上記のアーキテクチャ図からわかるように、TiCDCのアーキテクチャはトランザクションログレプリケーションシステムに似ていますが、より優れたスケーラビリティと論理データレプリケーションのメリットを備えています。そのため、TiCDCはDRシナリオにおいてTiDBの優れた補完機能となります。
BR
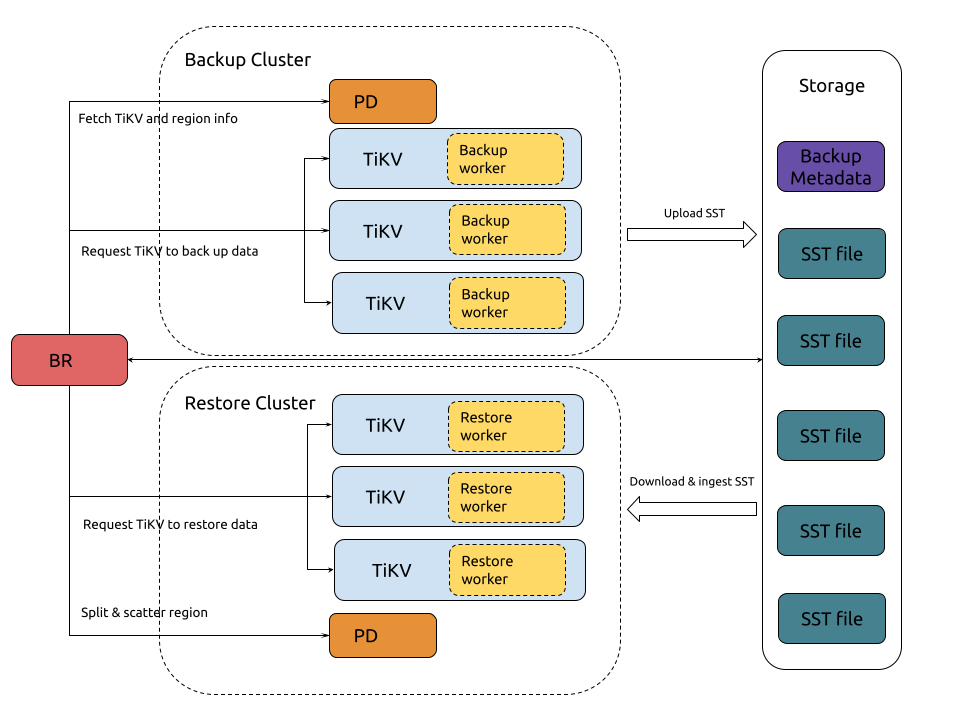
TiDBのバックアップおよびリストアツールであるBRは、特定の時点に基づく完全なスナップショットバックアップと、TiDBクラスタの継続的なログバックアップを実行できます。TiDBクラスタが完全に利用できなくなった場合でも、新しいクラスタにバックアップファイルをリストアできます。BRは通常、データセキュリティの最後の手段と考えられています。
ソリューション紹介
プライマリクラスタとセカンダリクラスタに基づくDRソリューション
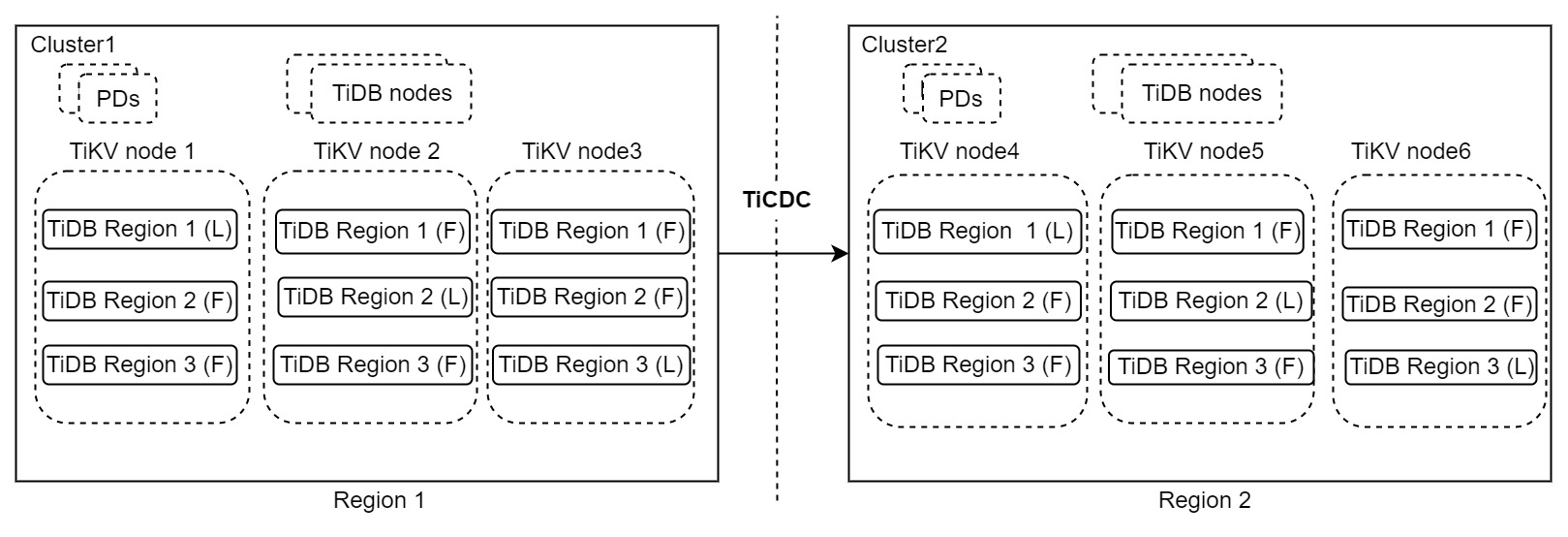
上記のアーキテクチャには2つのTiDBクラスタが含まれています。クラスタ1はリージョン1で実行され、読み取りおよび書き込みリクエストを処理します。クラスタ2はリージョン2で実行され、セカンダリクラスタとして機能します。クラスタ1で災害が発生すると、クラスタ2がサービスを引き継ぎます。データの変更は、TiCDCを使用して2つのクラスタ間で複製されます。このアーキテクチャは「1:1」DRソリューションとも呼ばれます。
このアーキテクチャはシンプルで高可用性を備えており、リージョンレベルのエラー許容度目標、スケーラブルな書き込み機能、秒単位のRPO、そして分単位、あるいはそれ以下のRTOを実現します。本番システムでRPOをゼロにする必要がない場合は、このDRソリューションをお勧めします。このソリューションの詳細については、 プライマリクラスタとセカンダリクラスタに基づくDRソリューションご覧ください。
単一クラスタ内の複数のレプリカに基づく DR ソリューション
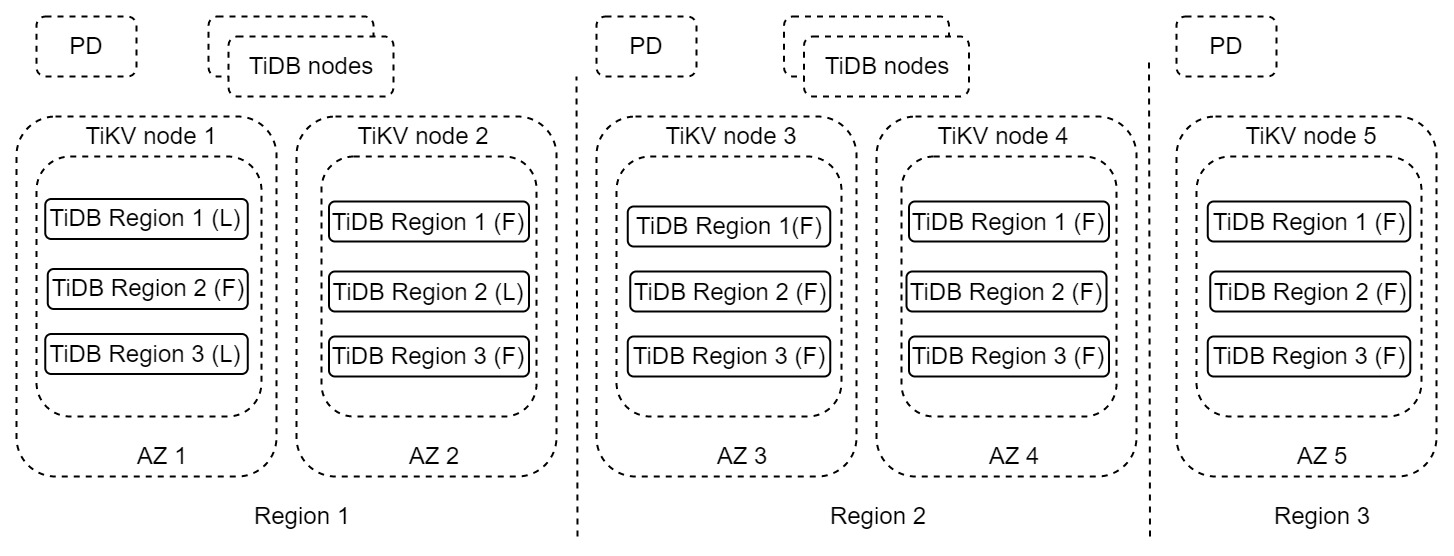
上記のアーキテクチャでは、各リージョンに2つの完全なデータレプリカがそれぞれ異なる利用可能ゾーン(AZ)に配置されています。クラスター全体は3つのリージョンにまたがっています。リージョン1は、読み取りおよび書き込みリクエストを処理するプライマリリージョンです。災害によりリージョン1が完全に利用できなくなった場合、リージョン2はDRリージョンとして使用できます。リージョン3は、多数決プロトコルを満たすために使用されるレプリカです。このアーキテクチャは「2-2-1」ソリューションとも呼ばれます。
このソリューションは、リージョンレベルのエラー耐性、スケーラブルな書き込み機能、ゼロRPO、そして分単位、あるいはそれ以下のRTOを実現します。本番システムでゼロRPOが求められる場合は、このDRソリューションのご利用をお勧めします。このソリューションの詳細については、 単一クラスタ内の複数のレプリカに基づく DR ソリューションご覧ください。
TiCDCと複数のレプリカに基づくDRソリューション
上記の2つのソリューションは、リージョンDRを実現します。ただし、複数のリージョンが同時に利用できなくなった場合は機能しません。システムが非常に重要で、複数のリージョンをカバーするためのエラー許容度目標が必要な場合は、これら2つのソリューションを組み合わせる必要があります。
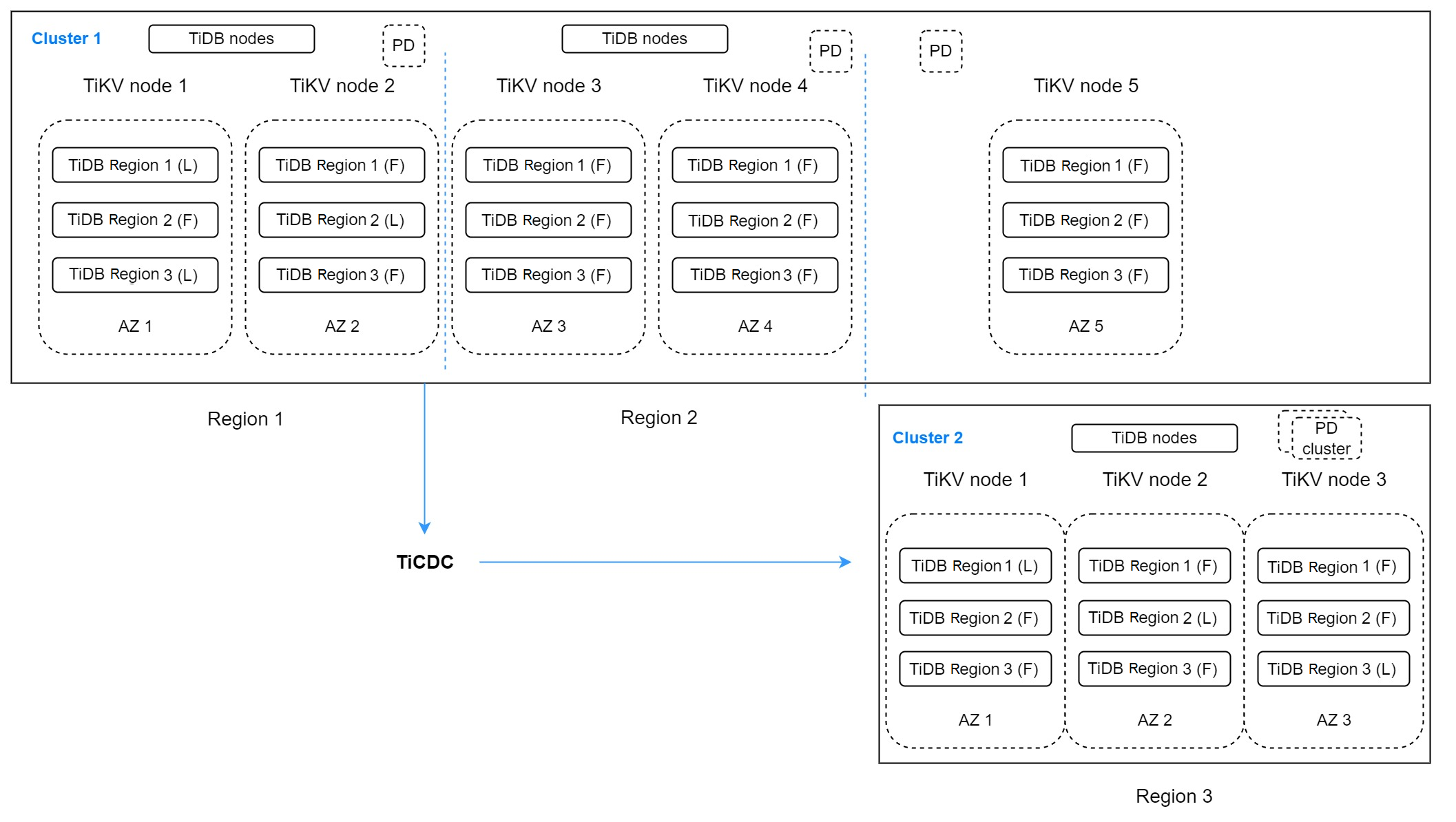
上記のアーキテクチャには、2つのTiDBクラスターがあります。クラスタ1には、3つのリージョンにまたがる5つのレプリカがあります。リージョン1には、プライマリリージョンとして機能し、書き込みリクエストを処理する2つのレプリカがあります。リージョン2には、リージョン1のDRリージョンとして機能する2つのレプリカがあります。このリージョンは、レイテンシーの影響を受けない読み取りサービスを提供します。リージョン3にある最後のレプリカは、投票に使用されます。
リージョン1とリージョン2のDRクラスターとして、クラスター2はリージョン3で実行され、3つのレプリカを保持しています。TiCDCはクラスター1からデータを複製します。このアーキテクチャは複雑に見えますが、複数のリージョンへのエラー許容度を高めることができます。複数のリージョンが同時に利用できなくなった場合でもRPOをゼロにする必要がない場合は、このアーキテクチャが適しています。このアーキテクチャは「2-2-1:1」ソリューションとも呼ばれます。
もちろん、エラー許容度の目標が複数のリージョンにあり、RPOをゼロにする必要がある場合は、5つのリージョンにまたがる9つ以上のレプリカを持つクラスターの作成も検討できます。このアーキテクチャは「2-2-2-2-1」ソリューションとも呼ばれます。
BRベースのDRソリューション

このアーキテクチャでは、TiDBクラスタ1はリージョン1にデプロイされています。BRはクラスタ1のデータをリージョン2に定期的にバックアップし、このクラスタのデータ変更ログもリージョン2に継続的にバックアップします。リージョン1で災害が発生し、クラスタ1が復旧できない場合でも、バックアップデータとデータ変更ログを使用して、リージョン2に新しいクラスタ(クラスタ2)を復元し、サービスを提供できます。
BRベースのDRソリューションは、5分未満のRPO(目標復旧時点)と、復元するデータのサイズに応じて変化するRTO(目標復旧時間)を提供します。BR v6.5.0の場合、復元速度についてはスナップショット復元のパフォーマンスと影響とPITRのパフォーマンスと影響を参照してください。通常、リージョンをまたいだバックアップ機能は、データセキュリティの最後の手段と考えられており、ほとんどのシステムにとって必須のソリューションでもあります。このソリューションの詳細については、 BRベースのDRソリューション参照してください。
一方、v6.5.0以降、 BRはEBSボリュームスナップショットからTiDBクラスターを復元するサポートします。クラスターがKubernetes上で実行されており、クラスターに影響を与えずにできるだけ早くクラスターを復元したい場合は、この機能を使用してシステムのRTOを短縮できます。
その他のDRソリューション
上記のDRソリューションに加えて、同一都市内のデュアルセンターシナリオでゼロRPOが必須の場合は、DR-AUTO同期ソリューションもご利用いただけます。詳細については、 1 つの地域に展開された 2 つのデータ センターご覧ください。
ソリューションの比較
このセクションでは、このドキュメントに記載されている DR ソリューションを比較し、ビジネス ニーズを満たす適切な DR ソリューションを選択できるようにします。
| DRソリューション | TCO | エラー許容目標 | RPO | RTO | ネットワークレイテンシー要件 | 対象システム |
|---|---|---|---|---|---|---|
| 単一クラスタ内の複数のレプリカに基づく DR ソリューション (2-2-1) | 高い | 単一地域 | 0 | 分レベル | 領域間の間隔は30ミリ秒未満 | DR と対応に関する特定の要件がある本番システム (RPO = 0) |
| プライマリクラスタとセカンダリクラスタに基づくDRソリューション(1:1) | 中くらい | 単一地域 | 10秒未満 | 5分未満 | 領域間の間隔は100ミリ秒未満 | DR と対応に関する特定の要件がある本番システム (RPO > 0) |
| TiCDC と複数のレプリカ (2-2-1:1) に基づく DR ソリューション | 高い | 複数の地域 | 10秒未満 | 5分未満 | DRに複数のレプリカを使用するリージョンでは30ミリ秒未満。3番目のリージョンとその他のリージョンでは100ミリ秒未満 | DRとレスポンスに厳しい要件がある生産システム |
| BRベースのDRソリューション | 低い | 単一地域 | 5分未満 | 時間レベル | 特別な要件はありません | 5 分未満の RPO と最大 1 時間の RTO を受け入れる本番システム |