从 TiDB 自建集群迁移到 TiDB Cloud
本文档介绍如何通过 Dumpling 和 TiCDC,将数据从你的 TiDB 自建集群迁移到 TiDB Cloud(基于 AWS)。
整体流程如下:
- 搭建环境并准备工具。
- 迁移全量数据。流程如下:
- 使用 Dumpling 将数据从 TiDB 自建集群导出到 Amazon S3。
- 将数据从 Amazon S3 导入到 TiDB Cloud。
- 使用 TiCDC 同步增量数据。
- 校验迁移后的数据。
前置条件
建议将 S3 bucket 和 TiDB Cloud 集群放在同一区域。跨区域迁移可能会产生额外的数据转换费用。
在迁移前,你需要准备以下内容:
- 一个具有管理员权限的 AWS 账号
- 一个 AWS S3 bucket
- 一个 TiDB Cloud 账号,并对目标 AWS 上托管的 TiDB Cloud 集群拥有至少
Project Data Access Read-Write权限
准备工具
你需要准备以下工具:
- Dumpling:数据导出工具
- TiCDC:数据同步工具
Dumpling
Dumpling 是一个可以将 TiDB 或 MySQL 数据导出为 SQL 或 CSV 文件的工具。你可以使用 Dumpling 从 TiDB 自建集群导出全量数据。
在部署 Dumpling 前,请注意以下事项:
- 推荐在与 TiDB Cloud 集群同一 VPC 的新 EC2 实例上部署 Dumpling。
- 推荐的 EC2 实例类型为 c6g.4xlarge(16 vCPU 和 32 GiB 内存)。你也可以根据实际需求选择其他 EC2 实例类型。Amazon Machine Image(AMI)可以选择 Amazon Linux、Ubuntu 或 Red Hat。
你可以通过 TiUP 或安装包部署 Dumpling。
使用 TiUP 部署 Dumpling
使用 TiUP 部署 Dumpling:
## 部署 TiUP
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
source /root/.bash_profile
## 部署 Dumpling 并升级到最新版本
tiup install dumpling
tiup update --self && tiup update dumpling
使用安装包部署 Dumpling
通过安装包部署 Dumpling:
下载 toolkit 安装包。
解压到目标机器。你也可以通过运行
tiup install dumpling使用 TiUP 获取 Dumpling。之后可以通过tiup dumpling ...运行 Dumpling。更多信息参见 Dumpling 介绍。
配置 Dumpling 所需权限
你需要以下权限才能从上游数据库导出数据:
- SELECT
- RELOAD
- LOCK TABLES
- REPLICATION CLIENT
- PROCESS
部署 TiCDC
你需要 部署 TiCDC 以将增量数据从上游 TiDB 集群同步到 TiDB Cloud。
确认当前 TiDB 版本是否支持 TiCDC。TiDB v4.0.8.rc.1 及以上版本支持 TiCDC。你可以在 TiDB 集群中执行
select tidb_version();检查 TiDB 版本。如需升级,参见 使用 TiUP 升级 TiDB。向 TiDB 集群添加 TiCDC 组件。参见 使用 TiUP 向现有 TiDB 集群添加或扩容 TiCDC。编辑
scale-out.yml文件添加 TiCDC:cdc_servers: - host: 10.0.1.3 gc-ttl: 86400 data_dir: /tidb-data/cdc-8300 - host: 10.0.1.4 gc-ttl: 86400 data_dir: /tidb-data/cdc-8300添加 TiCDC 组件并检查状态。
tiup cluster scale-out <cluster-name> scale-out.yml tiup cluster display <cluster-name>
迁移全量数据
要将数据从 TiDB 自建集群迁移到 TiDB Cloud,请按如下步骤进行全量数据迁移:
- 将数据从 TiDB 自建集群迁移到 Amazon S3。
- 将数据从 Amazon S3 迁移到 TiDB Cloud。
将数据从 TiDB 自建集群迁移到 Amazon S3
你需要使用 Dumpling 将数据从 TiDB 自建集群迁移到 Amazon S3。
如果你的 TiDB 集群在本地 IDC,或者 Dumpling 服务器与 Amazon S3 之间网络不通,可以先将文件导出到本地存储,再上传到 Amazon S3。
步骤 1. 临时关闭上游 TiDB 自建集群的 GC 机制
为确保增量迁移期间新写入的数据不会丢失,在开始迁移前需要关闭上游集群的垃圾回收(GC)机制,防止系统清理历史数据。
运行以下命令,验证设置是否生效。
SET GLOBAL tidb_gc_enable = FALSE;
以下为示例输出,其中 0 表示已关闭。
SELECT @@global.tidb_gc_enable;
+-------------------------+
| @@global.tidb_gc_enable |
+-------------------------+
| 0 |
+-------------------------+
1 row in set (0.01 sec)
步骤 2. 为 Dumpling 配置 Amazon S3 bucket 访问权限
在 AWS 控制台创建访问密钥。详见 创建访问密钥。
使用你的 AWS 账号 ID 或账号别名、IAM 用户名和密码登录 IAM 控制台。
在右上角导航栏选择你的用户名,然后点击 My Security Credentials。
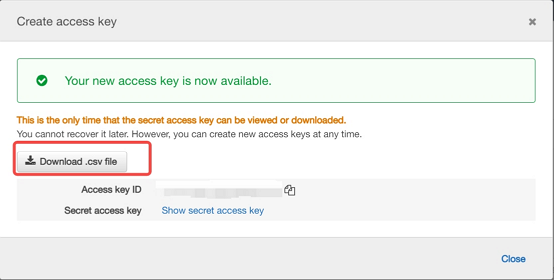
点击 Create access key 创建访问密钥。然后选择 Download .csv file,将访问密钥 ID 和密钥保存到本地 CSV 文件。请妥善保存该文件,关闭对话框后将无法再次获取密钥。下载 CSV 文件后,点击 Close。创建访问密钥后,密钥对默认处于激活状态,可以立即使用。
步骤 3. 使用 Dumpling 将数据从上游 TiDB 集群导出到 Amazon S3
按如下步骤使用 Dumpling 将数据从上游 TiDB 集群导出到 Amazon S3:
配置 Dumpling 的环境变量。
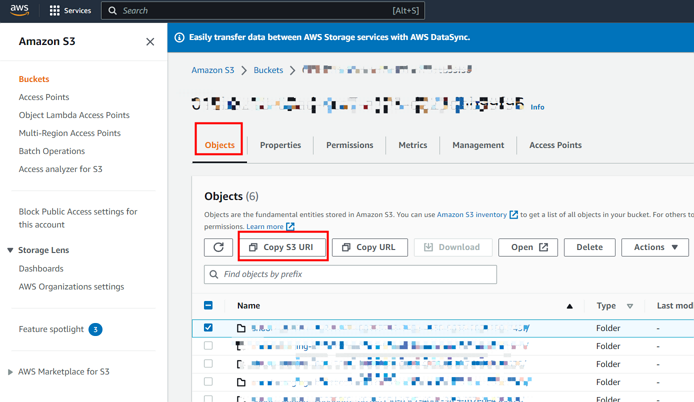
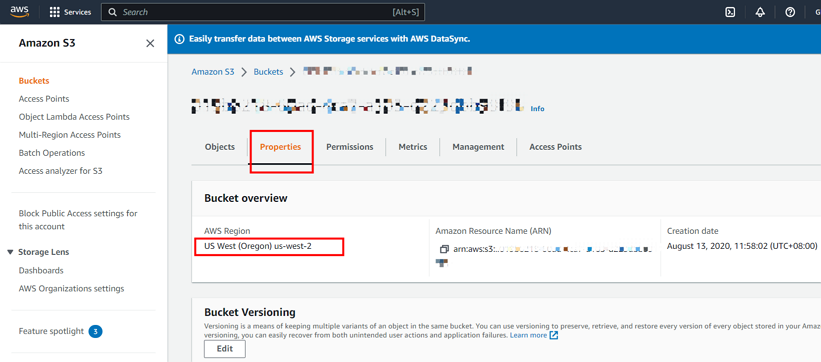
export AWS_ACCESS_KEY_ID=${AccessKey} export AWS_SECRET_ACCESS_KEY=${SecretKey}从 AWS 控制台获取 S3 bucket 的 URI 和区域信息。详见 创建 bucket。
下图展示了如何获取 S3 bucket URI 信息:
下图展示了如何获取区域信息:
运行 Dumpling,将数据导出到 Amazon S3 bucket。
dumpling \ -u root \ -P 4000 \ -h 127.0.0.1 \ -r 20000 \ --filetype {sql|csv} \ -F 256MiB \ -t 8 \ -o "${S3 URI}" \ --s3.region "${s3.region}"-t参数指定导出线程数。增加线程数可以提升 Dumpling 的并发和导出速度,但也会增加数据库的内存消耗,因此不建议设置过大。更多信息参见 Dumpling。
检查导出数据。通常导出的数据包括以下内容:
metadata:包含导出起始时间和主库 binlog 位置{schema}-schema-create.sql:创建 schema 的 SQL 文件{schema}.{table}-schema.sql:创建表的 SQL 文件{schema}.{table}.{0001}.{sql|csv}:数据文件*-schema-view.sql、*-schema-trigger.sql、*-schema-post.sql:其他导出的 SQL 文件
将数据从 Amazon S3 迁移到 TiDB Cloud
将数据从 TiDB 自建集群导出到 Amazon S3 后,需要将数据迁移到 TiDB Cloud。
在 TiDB Cloud 控制台 根据以下文档获取目标集群的 Account ID 和 External ID:
- 对于 TiDB Cloud Dedicated 集群,参见 通过 Role ARN 配置 Amazon S3 访问权限。
- 对于 TiDB Cloud Starter 或 TiDB Cloud Essential 集群,参见 通过 Role ARN 配置 Amazon S3 访问权限。
配置 Amazon S3 访问权限。通常需要以下只读权限:
- s3:GetObject
- s3:GetObjectVersion
- s3:ListBucket
- s3:GetBucketLocation
如果 S3 bucket 启用了服务端加密 SSE-KMS,还需添加 KMS 权限:
- kms:Decrypt
配置访问策略。进入 AWS Console > IAM > Access Management > Policies,切换到你的区域,检查是否已存在 TiDB Cloud 的访问策略。如果不存在,按照 在 JSON 选项卡上创建策略 创建策略。
以下为 json 策略模板示例。
## Create a json policy template ##<Your customized directory>: 填写 S3 bucket 中待导入数据文件所在文件夹的路径 ##<Your S3 bucket ARN>: 填写 S3 bucket 的 ARN。可在 S3 Bucket Overview 页面点击 Copy ARN 按钮获取 ##<Your AWS KMS ARN>: 填写 S3 bucket KMS 密钥的 ARN。可在 S3 bucket > Properties > Default encryption > AWS KMS Key ARN 获取。更多信息参见 https://docs.aws.amazon.com/AmazonS3/latest/userguide/viewing-bucket-key-settings.html { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:GetObjectVersion" ], "Resource": "arn:aws:s3:::<Your customized directory>" }, { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation" ], "Resource": "<Your S3 bucket ARN>" } // 如果 S3 bucket 启用了 SSE-KMS,需要添加以下权限 { "Effect": "Allow", "Action": [ "kms:Decrypt" ], "Resource": "<Your AWS KMS ARN>" } , { "Effect": "Allow", "Action": "kms:Decrypt", "Resource": "<Your AWS KMS ARN>" } ] }配置角色。参见 创建 IAM 角色(控制台)。在 Account ID 字段填写你在第 1 步记录的 TiDB Cloud Account ID 和 TiDB Cloud External ID。
获取 Role-ARN。进入 AWS Console > IAM > Access Management > Roles,切换到你的区域,点击你创建的角色,记录 ARN。导入数据到 TiDB Cloud 时会用到。
导入数据到 TiDB Cloud。
- 对于 TiDB Cloud Dedicated 集群,参见 从云存储导入 CSV 文件到 TiDB Cloud Dedicated。
- 对于 TiDB Cloud Starter 或 TiDB Cloud Essential 集群,参见 从云存储导入 CSV 文件到 TiDB Cloud Starter 或 Essential。
同步增量数据
要同步增量数据,请按如下步骤操作:
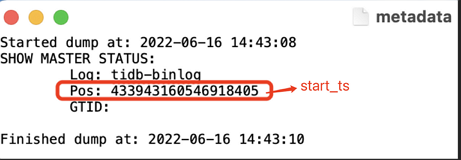
获取增量数据迁移的起始时间。例如,可以从全量数据迁移的 metadata 文件中获取。
授权 TiCDC 连接 TiDB Cloud。
- 在 TiDB Cloud 控制台 进入 Clusters 页面,点击目标集群名称进入概览页。
- 在左侧导航栏点击 Settings > Networking。
- 在 Networking 页面点击 Add IP Address。
- 在弹窗中选择 Use IP addresses,点击 +,在 IP Address 字段填写 TiCDC 组件的公网 IP 地址,然后点击 Confirm。此时 TiCDC 可以访问 TiDB Cloud。更多信息参见 配置 IP 访问列表。
获取下游 TiDB Cloud 集群的连接信息。
- 在 TiDB Cloud 控制台 进入 Clusters 页面,点击目标集群名称进入概览页。
- 点击右上角 Connect。
- 在连接对话框中,Connection Type 下拉选择 Public,Connect With 下拉选择 General。
- 从连接信息中获取集群的 host IP 地址和端口。更多信息参见 通过公网连接。
创建并运行增量同步任务。在上游集群运行如下命令:
tiup cdc cli changefeed create \ --pd=http://172.16.6.122:2379 \ --sink-uri="tidb://root:123456@172.16.6.125:4000" \ --changefeed-id="upstream-to-downstream" \ --start-ts="431434047157698561"--pd:上游集群的 PD 地址,格式为[upstream_pd_ip]:[pd_port]--sink-uri:同步任务的下游地址。--sink-uri的格式如下。目前支持的 scheme 有mysql、tidb、kafka、s3和local。[scheme]://[userinfo@][host]:[port][/path]?[query_parameters]--changefeed-id:同步任务的 ID,格式需符合 ^[a-zA-Z0-9]+(-[a-zA-Z0-9]+)*$ 正则表达式。如果未指定,TiCDC 会自动生成一个 UUID(v4 格式)作为 ID。--start-ts:指定 changefeed 的起始 TSO,TiCDC 集群将从该 TSO 开始拉取数据。默认值为当前时间。
更多信息参见 TiCDC Changefeed 的 CLI 及配置参数。
在上游集群重新开启 GC 机制。如果增量同步无报错或延迟,建议开启 GC 机制,恢复集群的垃圾回收。
运行以下命令,验证设置是否生效。
SET GLOBAL tidb_gc_enable = TRUE;以下为示例输出,其中
1表示 GC 已开启。SELECT @@global.tidb_gc_enable; +-------------------------+ | @@global.tidb_gc_enable | +-------------------------+ | 1 | +-------------------------+ 1 row in set (0.01 sec)校验增量同步任务。
如果输出中显示 "Create changefeed successfully!",则同步任务创建成功。
如果状态为
normal,则同步任务正常。tiup cdc cli changefeed list --pd=http://172.16.6.122:2379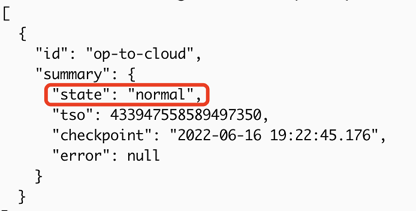
校验同步效果。向上游集群写入新记录,检查该记录是否同步到下游 TiDB Cloud 集群。
设置上下游集群的时区一致。TiDB Cloud 默认时区为 UTC。如果上下游集群时区不同,需要将两端时区设置为一致。
在上游集群运行以下命令检查时区:
SELECT @@global.time_zone;在下游集群运行以下命令设置时区:
SET GLOBAL time_zone = '+08:00';再次检查时区,确认设置生效:
SELECT @@global.time_zone;
备份上游集群的 查询绑定,并在下游集群恢复。你可以使用以下 SQL 备份查询绑定:
SELECT DISTINCT(CONCAT('CREATE GLOBAL BINDING FOR ', original_sql,' USING ', bind_sql,';')) FROM mysql.bind_info WHERE status='enabled';如果没有输出,说明上游集群未使用查询绑定,可以跳过此步骤。
获取到查询绑定后,在下游集群执行这些 SQL 以恢复查询绑定。
备份上游集群的用户和权限信息,并在下游集群恢复。你可以使用以下脚本备份用户和权限信息。注意需将占位符替换为实际值。
#!/bin/bash export MYSQL_HOST={tidb_op_host} export MYSQL_TCP_PORT={tidb_op_port} export MYSQL_USER=root export MYSQL_PWD={root_password} export MYSQL="mysql -u${MYSQL_USER} --default-character-set=utf8mb4" function backup_user_priv(){ ret=0 sql="SELECT CONCAT(user,':',host,':',authentication_string) FROM mysql.user WHERE user NOT IN ('root')" for usr in `$MYSQL -se "$sql"`;do u=`echo $usr | awk -F ":" '{print $1}'` h=`echo $usr | awk -F ":" '{print $2}'` p=`echo $usr | awk -F ":" '{print $3}'` echo "-- Grants for '${u}'@'${h}';" [[ ! -z "${p}" ]] && echo "CREATE USER IF NOT EXISTS '${u}'@'${h}' IDENTIFIED WITH 'mysql_native_password' AS '${p}' ;" $MYSQL -se "SHOW GRANTS FOR '${u}'@'${h}';" | sed 's/$/;/g' [ $? -ne 0 ] && ret=1 && break done return $ret } backup_user_priv获取到用户和权限信息后,在下游集群执行生成的 SQL 语句以恢复用户和权限信息。