Follower Read
在 TiDB 中,为了保证高可用和数据安全,TiKV 会为每个 Region 存储多个副本,其中一个为 leader,其余为 Follower。默认情况下,所有读写请求都由 leader 处理。Follower Read 功能使 TiDB 能够在保证强一致性的前提下,从 Region 的 Follower 副本读取数据,从而减轻 leader 的读负载,提高集群整体读吞吐。
在执行 Follower Read 时,TiDB 会根据拓扑结构信息选择合适的副本。具体来说,TiDB 使用 zone 标签来识别本地副本:如果 TiDB 节点的 zone 标签与目标 TiKV 节点的 zone 标签相同,则认为该副本为本地副本。在 TiDB Cloud 中,zone 标签会自动设置。
通过让 Follower 处理读请求,Follower Read 实现了以下目标:
- 分散读热点,降低 leader 的负载。
- 在多可用区或多数据中心部署中优先本地副本读,减少跨可用区流量。
使用场景
Follower Read 适用于以下场景:
- 应用存在大量读请求或明显读热点。
- 多可用区部署,希望优先从本地副本读取以减少跨可用区带宽消耗。
- 读写分离架构,希望进一步提升整体读性能。
使用方法
要启用 TiDB 的 Follower Read 功能,可以按如下方式修改 tidb_replica_read 变量的值:
set [session | global] tidb_replica_read = '<target value>';
作用域:SESSION | GLOBAL
默认值:leader
该变量定义了期望的数据读取模式。从 v8.5.4 起,该变量仅对只读 SQL 语句生效。
在需要通过本地副本读减少跨可用区流量的场景下,推荐如下配置:
leader:默认值,提供最佳性能。closest-adaptive:在尽量减少跨可用区流量的同时,将性能损失降到最低。closest-replicas:最大化节省跨可用区流量,但可能会带来一定的性能下降。
如果你正在使用其他配置,请参考下表修改为推荐配置:
| 当前配置 | 推荐配置 |
|---|---|
follower | closest-replicas |
leader-and-follower | closest-replicas |
prefer-leader | closest-adaptive |
learner | closest-replicas |
如果你希望使用更精细的读副本选择策略,可参考下方完整配置列表:
当你将
tidb_replica_read设置为leader或空字符串时,TiDB 保持默认行为,所有读操作都发送到 leader 副本执行。当你将
tidb_replica_read设置为follower时,TiDB 会选择 Region 的 Follower 副本执行读操作。如果该 Region 存在 learner 副本,TiDB 也会以同等优先级考虑其读操作。如果当前 Region 没有可用的 Follower 或 learner 副本,TiDB 会从 leader 副本读取。当
tidb_replica_read设置为leader-and-follower时,TiDB 可选择任意副本执行读操作。在该模式下,读请求会在 leader、Follower 和 learner 之间负载均衡。当
tidb_replica_read设置为prefer-leader时,TiDB 优先选择 leader 副本执行读操作。如果 leader 副本在处理读操作时明显变慢(如磁盘或网络性能抖动导致),TiDB 会选择其他可用的 Follower 副本执行读操作。当
tidb_replica_read设置为closest-replicas时,TiDB 优先选择同一可用区内的副本执行读操作,该副本可以是 leader、Follower 或 learner。如果同一可用区内没有副本,TiDB 会从 leader 副本读取。当
tidb_replica_read设置为closest-adaptive时:- 如果一次读请求的预估结果大于等于
tidb_adaptive_closest_read_threshold的值,TiDB 优先选择同一可用区内的副本进行读操作。为避免各可用区读流量分布不均,TiDB 会动态检测所有在线 TiDB 和 TiKV 节点的可用区分布。在每个可用区内,closest-adaptive配置生效的 TiDB 节点数量,始终等于 TiDB 节点最少的可用区中的节点数,其余 TiDB 节点会自动从 leader 副本读取。例如,TiDB 节点分布在 3 个可用区(A、B、C),A、B 各有 3 个 TiDB 节点,C 有 2 个 TiDB 节点,则每个可用区closest-adaptive配置生效的 TiDB 节点数为 2,A、B 区多出来的 TiDB 节点会自动选择 leader 副本进行读操作。 - 如果一次读请求的预估结果小于
tidb_adaptive_closest_read_threshold的值,TiDB 只能选择 leader 副本进行读操作。
- 如果一次读请求的预估结果大于等于
当你将
tidb_replica_read设置为learner时,TiDB 会从 learner 副本读取数据。如果当前 Region 没有可用的 learner 副本,TiDB 会从可用的 leader 或 Follower 副本读取。
实现机制
在引入 Follower Read 功能之前,TiDB 遵循强 leader 原则,所有读写请求都提交给 Region 的 leader 节点处理。虽然 TiKV 能将 Region 均匀分布在多个物理节点上,但对于每个 Region,只有 leader 能对外提供服务,其余 Follower 无法处理读请求,只能实时接收 leader 复制的数据,并在故障时准备参与 leader 选举。
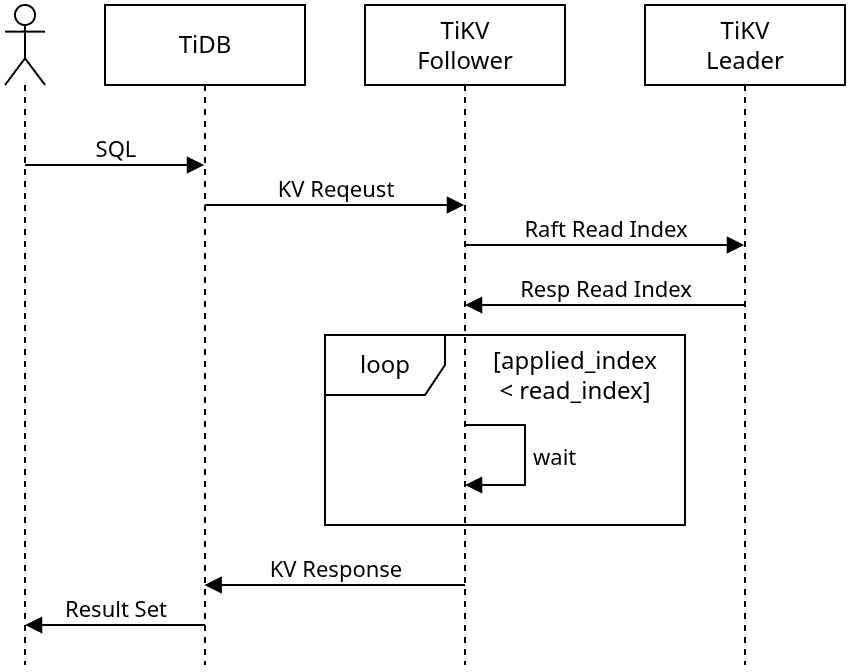
Follower Read 包含一套负载均衡机制,将 TiKV 的读请求从 leader 副本分流到 Region 的 Follower 副本。为了保证从 Follower 节点读取数据不会破坏线性一致性或影响 TiDB 的快照隔离,Follower 节点需要使用 Raft 协议的 ReadIndex,确保读请求能读取到 leader 节点已提交的最新数据。在 TiDB 层面,Follower Read 只需根据负载均衡策略,将 Region 的读请求发送到 Follower 副本。
强一致性读
当 Follower 节点处理读请求时,会先通过 Raft 协议的 ReadIndex 与 Region 的 leader 交互,获取当前 Raft group 的最新提交索引。在该提交索引被应用到本地 Follower 后,才开始处理读请求。
Follower 副本选择策略
Follower Read 不影响 TiDB 的快照隔离事务隔离级别。TiDB 会根据 tidb_replica_read 配置选择副本进行首次读尝试。从第二次重试开始,TiDB 优先保证读成功。因此,当选中的 Follower 节点不可达或发生其他错误时,TiDB 会切换到 leader 提供服务。
leader
- 无论副本位置如何,始终选择 leader 副本进行读操作。
closest-replicas
- 当与 TiDB 同一可用区的副本为 leader 节点时,TiDB 不会对其进行 Follower Read。
- 当与 TiDB 同一可用区的副本为 Follower 节点时,TiDB 会对其进行 Follower Read。
closest-adaptive
- 如果预估结果不够大,TiDB 采用
leader策略,不进行 Follower Read。 - 如果预估结果足够大,TiDB 采用
closest-replicas策略。
Follower Read 性能开销
为保证数据强一致性,Follower Read 无论读取数据量多少,都会执行一次 ReadIndex 操作,这必然会消耗额外的 TiKV CPU 资源。因此,在小查询(如点查)场景下,Follower Read 的性能损失相对更明显。此外,小查询本地读带来的流量减少有限,Follower Read 更推荐用于大查询或批量读取场景。
当 tidb_replica_read 设置为 closest-adaptive 时,TiDB 不会对小查询进行 Follower Read。因此,在各种负载下,TiKV 的额外 CPU 开销通常不会超过 leader 策略下的 10%。