TiDB 分布式执行框架
TiDB 采用计算存储分离架构,具有出色的扩展性和弹性的扩缩容能力。从 v7.1.0 开始,TiDB 引入了一个分布式执行框架,以进一步发挥分布式架构的资源优势。该框架的目标是对基于该框架的任务进行统一调度与分布式执行,并提供整体和单个任务两个维度的资源管理能力,更好地满足用户对于资源使用的预期。
本文档介绍了 TiDB 分布式执行框架的使用场景、限制、使用方法和实现原理。
使用场景
在数据库中,除了核心的事务型负载任务 (TP) 和分析型查询任务 (AP),也存在着其他重要任务,如 DDL 语句、IMPORT INTO、TTL、Analyze 和 Backup/Restore 等。这些任务需要处理数据库对象(表)中的大量数据,通常具有如下特点:
- 需要处理一个 schema 或者一个数据库对象(表)中的所有数据。
- 可能需要周期执行,但频率较低。
- 如果资源控制不当,容易对事务型任务和分析型任务造成影响,影响数据库的服务质量。
启用 TiDB 分布式执行框架能够解决上述问题,并且具有以下三个优势:
- 提供高扩展性、高可用性和高性能的统一能力支持。
- 支持任务分布式执行,可以在整个 TiDB 集群可用的计算资源范围内进行灵活的调度,从而更好地利用 TiDB 集群内的计算资源。
- 提供统一的资源使用和管理能力,从整体和单个任务两个维度提供资源管理的能力。
目前,分布式执行框架支持分布式执行 ADD INDEX 和 IMPORT INTO 这两类任务。
ADD INDEX,即 DDL 创建索引的场景。例如以下 SQL 语句:ALTER TABLE t1 ADD INDEX idx1(c1); CREATE INDEX idx1 ON table t1(c1);IMPORT INTO即通过该 SQL 语句将CSV、SQL、PARQUET等格式的数据导入到一张空表中。详情请参考IMPORT INTO。
使用限制
分布式执行框架一次只能调度一个 ADD INDEX 任务进行分布式执行。如果在当前的 ADD INDEX 分布式任务还未执行完成时就提交了一个新的 ADD INDEX 任务,则新提交的 ADD INDEX 任务不会被该框架调度,而是直接通过事务的方式来执行。
启用前提
如需使用分布式执行框架执行 ADD INDEX 任务,需要先开启 Fast Online DDL 模式。
调整 Fast Online DDL 相关的系统变量:
tidb_ddl_enable_fast_reorg:从 TiDB v6.5.0 开始默认打开,用于启用快速模式。tidb_ddl_disk_quota:用于控制快速模式可使用的本地磁盘最大配额。
调整 Fast Online DDL 相关的配置项:
temp-dir:指定快速模式能够使用的本地盘路径。
启用步骤
启用分布式执行框架,只需将
tidb_enable_dist_task设置为ON:SET GLOBAL tidb_enable_dist_task = ON;在运行任务时,框架支持的语句(如
ADD INDEX和IMPORT INTO)会采用分布式方式执行。默认集群内部所有节点均会执行任务。一般情况下,对于下列影响 DDL 任务分布式执行的系统变量,使用其默认值即可。
tidb_ddl_reorg_worker_cnt:使用默认值4即可,建议最大不超过16。tidb_ddl_reorg_prioritytidb_ddl_error_count_limittidb_ddl_reorg_batch_size:使用默认值即可,建议最大不超过1024。
从 v7.4.0 开始,你可以根据实际需求,调整用于分布式执行框架任务的 TiDB 节点数量,在部署 TiDB 后为每一个 TiDB 节点设置 Instance 级别系统变量
tidb_service_scope。tidb_service_scope设置为background时,TiDB 节点可执行分布式执行框架的任务。tidb_service_scope设置为默认值 "" 时,TiDB 节点不可执行分布式执行框架的任务。如果所有节点均未配置tidb_service_scope,分布式执行框架将调度所有 TiDB 节点执行任务。
实现原理
TiDB 分布式执行框架的架构图如下:
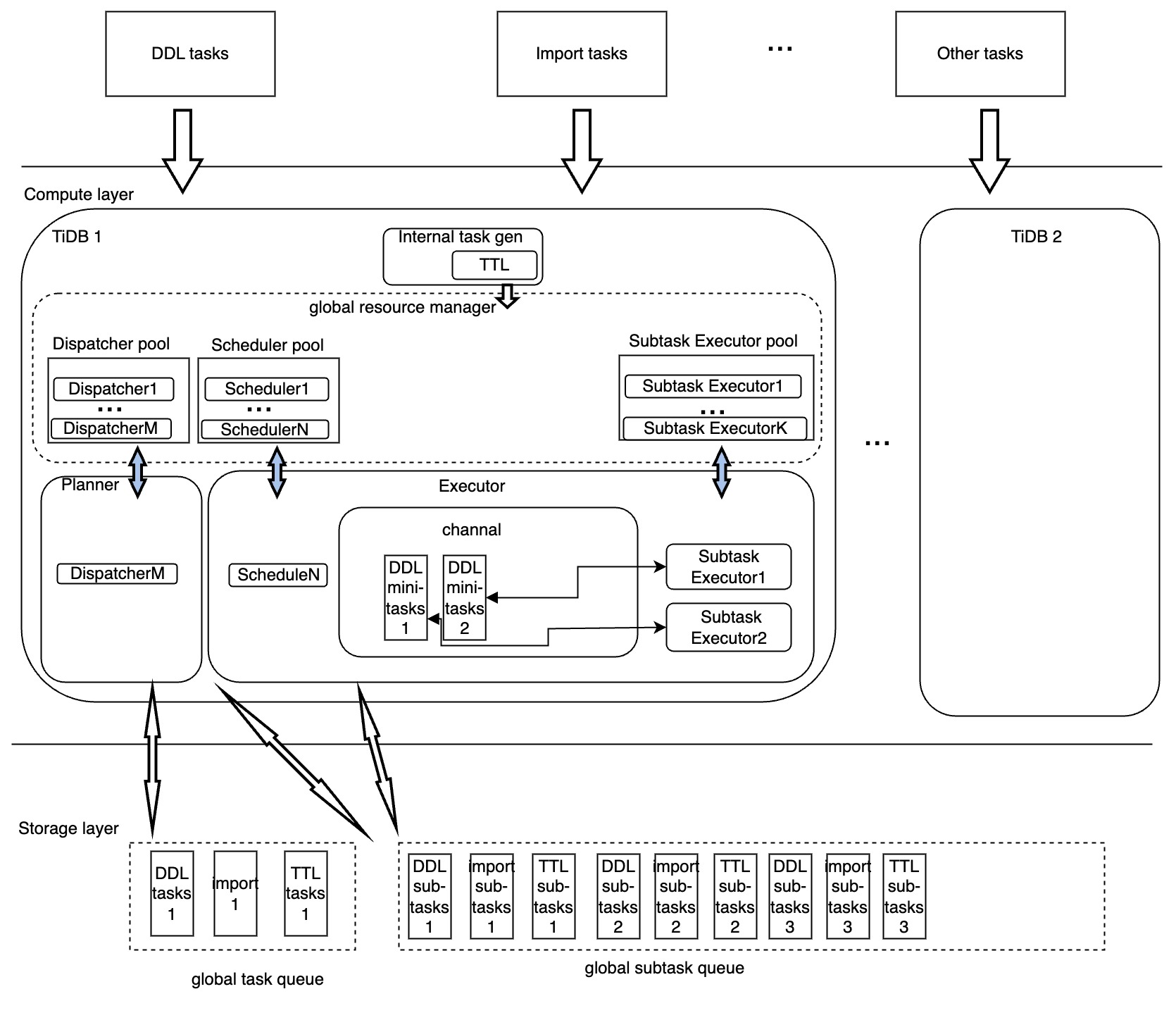
根据上图,分布式执行框架中任务的执行主要由以下模块负责:
- Dispatcher:负责生成每个任务的分布式执行计划,管理执行过程,转换任务状态以及收集和反馈运行时任务信息等。
- Scheduler:以 TiDB 节点为单位来同步分布式任务的执行,提高执行效率。
- Subtask Executor:是实际的分布式子任务执行者,并将子任务的执行情况返回给 Scheduler,由 Scheduler 统一更新子任务的执行状态。
- 资源池:通过对上述各种模块中计算资源进行池化,提供量化资源的使用与管理的基础。