TiSpark 用户指南
TiSpark 依赖于 TiKV 集群和 Placement Driver (PD),也需要你搭建一个 Spark 集群。本文简单介绍如何部署和使用 TiSpark。本文假设你对 Spark 有基本认知。你可以参阅 Apache Spark 官网了解 Spark 的相关信息。
TiSpark 深度整合了 Spark Catalyst 引擎,可以对计算进行精确的控制,使 Spark 能够高效地读取 TiKV 中的数据。TiSpark 还提供索引支持,帮助实现高速点查。
TiSpark 通过将计算下推到 TiKV 中提升了数据查询的效率,减少了 Spark SQL 需要处理的数据量,通过 TiDB 内置的统计信息选择最优的查询计划。
TiSpark 和 TiDB 可以让用户无需创建和维护 ETL,直接在同一个平台上进行事务和分析两种任务。这简化了系统架构,降低了运维成本。
用户可以在 TiDB 上使用 Spark 生态圈的多种工具进行数据处理,例如:
- TiSpark:数据分析和 ETL。
- TiKV:数据检索。
- 调度系统:生成报表。
除此之外,TiSpark 还提供了分布式写入 TiKV 的功能。与使用 Spark 结合 JDBC 写入 TiDB 的方式相比,分布式写入 TiKV 能够实现事务(要么全部数据写入成功,要么全部都写入失败)。
TiSpark 的架构图如下所示:
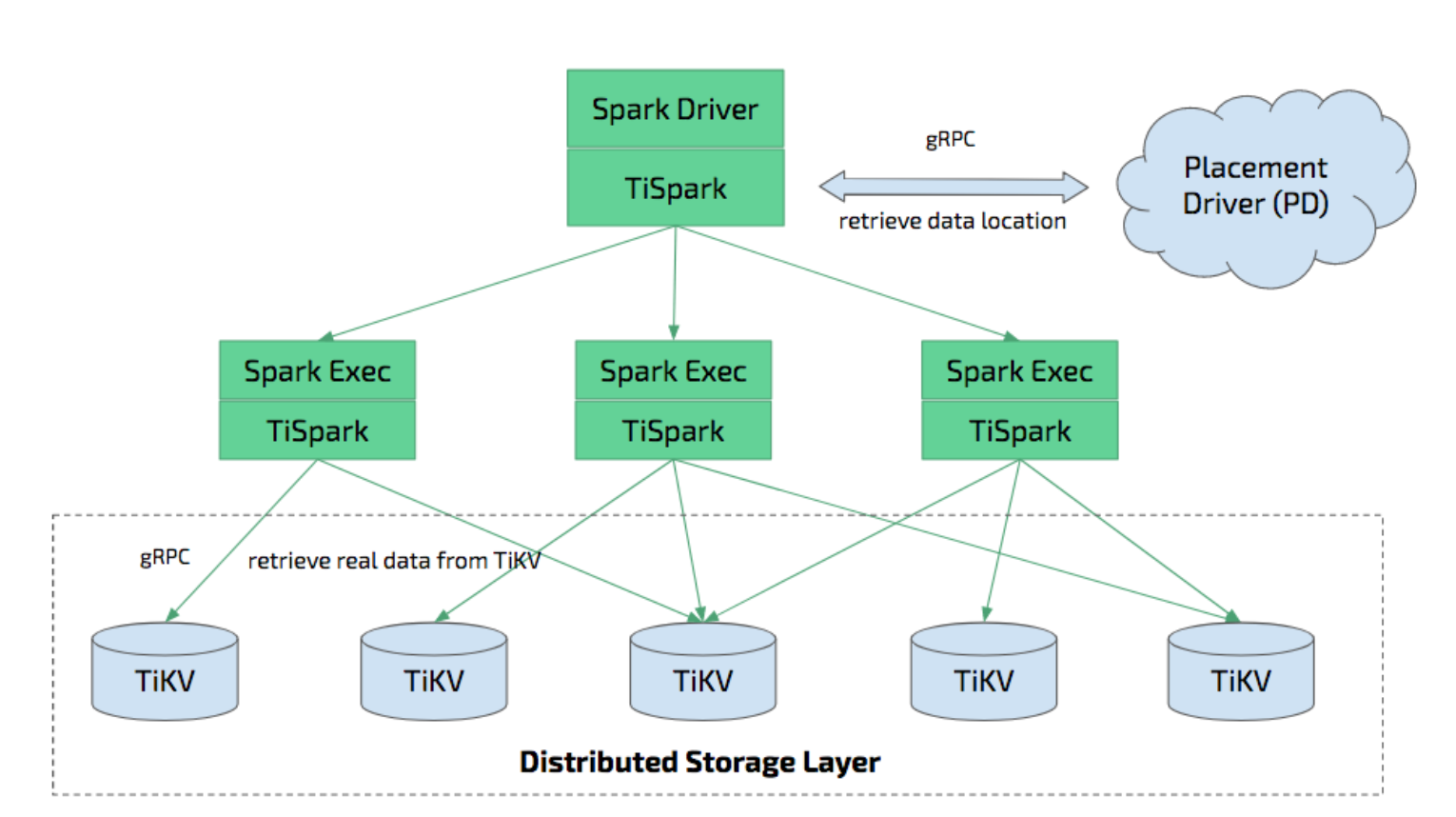
TiSpark vs TiFlash
TiSpark 是 PingCAP 为解决用户复杂 OLAP 需求而推出的产品。它借助 Spark 平台,同时融合 TiKV 分布式集群的优势,和 TiDB 一起为用户一站式解决 HTAP (Hybrid Transactional/Analytical Processing) 的需求。
TiFlash 也是一个解决 HTAP 需求的产品。TiFlash 和 TiSpark 都允许使用多个主机在 OLTP 数据上执行 OLAP 查询。TiFlash 是列式存储,这提供了更高效的分析查询。TiFlash 和 TiSpark 可以同时使用。
版本要求
- TiSpark 支持 Spark 2.3 或以上版本。
- TiSpark 需要 JDK 1.8 以及 Scala 2.11/2.12 版本。
- TiSpark 可以运行在任何 Spark 模式上,如
YARN、Mesos以及Standalone。
推荐配置
TiSpark 作为 Spark 的 TiDB 连接器,需要 Spark 集群的支持。本文仅提供部署 Spark 的参考建议,对于硬件以及部署细节,请参考 Spark 官方文档。
对于独立部署的 Spark 集群,可以参考如下建议配置:
- 建议为 Spark 分配 32G 以上的内存,并为操作系统和缓存保留至少 25% 的内存。
- 建议每台机器至少为 Spark 分配 8 到 16 核 CPU。起初,你可以设定将所有 CPU 核分配给 Spark。
可以参考如下的 spark-env.sh 配置文件:
SPARK_EXECUTOR_MEMORY = 32g
SPARK_WORKER_MEMORY = 32g
SPARK_WORKER_CORES = 8
获取 TiSpark
TiSpark 是 Spark 的第三方 jar 包,提供读写 TiKV 的能力。
获取 mysql-connector-j
由于 GPL 许可证的限制,TiSpark 不再提供 mysql-connector-java 的依赖。以下版本将不再包含 mysql-connector-java:
- TiSpark > 3.0.1
- TiSpark > 2.5.1 (TiSpark 2.5.x)
- TiSpark > 2.4.3 (TiSpark 2.4.x)
在使用 TiSpark 写入与鉴权时,仍需要 mysql-connector-java 依赖,因此你需要手动下载,并使用以下方式引入:
将
mysql-connector-java放入 Spark jars 包中。在你提交 Spark 任务时,引入
mysql-connector-java,详见以下示例:spark-submit --jars tispark-assembly-3.0_2.12-3.1.0-SNAPSHOT.jar,mysql-connector-java-8.0.29.jar
选择 TiSpark 版本
你可以根据 TiDB 和 Spark 版本选择相应的 TiSpark 版本。
推荐使用 TiSpark 的最新稳定版本,包括 2.4.4、2.5.2、3.0.2、3.1.1 和 3.2.3。
获取 TiSpark jar 包
你能用以下方式获取 jar 包:
- 从 maven 中央仓库获取,你可以搜索
pingcap关键词。 - 从 TiSpark releases 获取。
- 通过以下步骤从源码构建:
下载 TiSpark 源码:
git clone https://github.com/pingcap/tispark.git cd tisapark在 TiSpark 根目录运行如下命令:
// add -Dmaven.test.skip=true to skip the tests mvn clean install -Dmaven.test.skip=true // or you can add properties to specify spark version mvn clean install -Dmaven.test.skip=true -Pspark3.2.1
TiSpark jar 包的 artifact ID
注意不同版本的 TiSpark artifact ID 也不同:
快速开始
本章节将以 spark-shell 为例,介绍如何使用 TiSpark。请保证您已下载 Spark。
启动 spark-shell
在 spark-defaults.conf 中添加如下配置:
spark.sql.extensions org.apache.spark.sql.TiExtensions
spark.tispark.pd.addresses ${your_pd_adress}
spark.sql.catalog.tidb_catalog org.apache.spark.sql.catalyst.catalog.TiCatalog
spark.sql.catalog.tidb_catalog.pd.addresses ${your_pd_adress}
启动 spark-shell:
spark-shell --jars tispark-assembly-{version}.jar
获取 TiSpark 版本
在 spark-shell 中运行如下命令,可获取 TiSpark 版本信息:
spark.sql("select ti_version()").collect
使用 TiSpark 读取数据
可以通过 Spark SQL 从 TiKV 读取数据:
spark.sql("use tidb_catalog")
spark.sql("select count(*) from ${database}.${table}").show
使用 TiSpark 写入数据
通过 Spark DataSource API,可以在保证 ACID 前提下写入数据到 TiKV:
val tidbOptions: Map[String, String] = Map(
"tidb.addr" -> "127.0.0.1",
"tidb.password" -> "",
"tidb.port" -> "4000",
"tidb.user" -> "root"
)
val customerDF = spark.sql("select * from customer limit 100000")
customerDF.write
.format("tidb")
.option("database", "tpch_test")
.option("table", "cust_test_select")
.options(tidbOptions)
.mode("append")
.save()
详见 Data Source API User Guide。
TiSpark 3.1 及之后版本支持通过 Spark SQL 写入数据到 TiKV。详见 Insert SQL。
通过 JDBC 数据源写入数据
你同样可以在不使用 TiSpark 的情况下使用 Spark JDBC 数据源写入 TiDB。
由于这超过了 TiSpark 的范畴,本文仅简单提供示例,详情请参考 JDBC To Other Databases。
import org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions
val customer = spark.sql("select * from customer limit 100000")
// 为了平衡各节点以及提高并发数,你可以将数据源重新分区
val df = customer.repartition(32)
df.write
.mode(saveMode = "append")
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
// 替换为你的主机名和端口地址,并确保开启了重写批处理
.option("url", "jdbc:mysql://127.0.0.1:4000/test?rewriteBatchedStatements=true")
.option("useSSL", "false")
// 作为测试,建议设置为 150
.option(JDBCOptions.JDBC_BATCH_INSERT_SIZE, 150)
.option("dbtable", s"cust_test_select") // 数据库名和表名
.option("isolationLevel", "NONE") // 如果需要写入较大 Dataframe,推荐将 isolationLevel 设置为 NONE
.option("user", "root") // TiDB 用户名
.save()
为了避免大事务导致 OOM 以及 TiDB 报 ISOLATION LEVEL does not support 错误(TiDB 目前仅支持 REPEATABLE-READ),推荐设置 isolationLevel 为 NONE。
使用 TiSpark 删除数据
可以使用 Spark SQL 删除 TiKV 数据:
spark.sql("use tidb_catalog")
spark.sql("delete from ${database}.${table} where xxx")
详情请参考 delete feature。
与其他数据源一起使用
你可以使用多个 catalog 从不同数据源读取数据:
// 从 Hive 读取
spark.sql("select * from spark_catalog.default.t").show
// Join Hive 表和 TiDB 表
spark.sql("select t1.id,t2.id from spark_catalog.default.t t1 left join tidb_catalog.test.t t2").show
TiSpark 配置
可以将如下参数配置在 spark-defaults.conf 中,也可以参考 Spark 其他配置,用同样的方式传入。
TLS 配置
TiSpark TLS 分为两部分:TiKV Client TLS 以及 JDBC connector TLS。 前者用于创建和 TiKV/PD 的 TLS 连接,后者用于创建与 TiDB 的 TLS 连接。
当配置 TiKV Client TLS 时,你需要以 X.509 格式的证书配置 tikv.trust_cert_collection、tikv.key_cert_chain 和 tikv.key_file;或者以 JKS 格式的证书配置 tikv.jks_enable,tikv.jks_trust_path 和 tikv.jks_key_path。
当配置 JDBC connector TLS 时,你需要配置 spark.tispark.jdbc.tls_enable,而 jdbc.server_cert_store 和 jdbc.client_cert_store 则是可选的。
TiSpark 目前仅持 TLS 1.2 and TLS 1.3。
- 如下是使用 X.509 证书配置 TiKV Client TLS 的例子:
spark.tispark.tikv.tls_enable true
spark.tispark.tikv.trust_cert_collection /home/tispark/root.pem
spark.tispark.tikv.key_cert_chain /home/tispark/client.pem
spark.tispark.tikv.key_file /home/tispark/client.key
- 如下是使用 JKS 配置 TiKV Client TLS 的例子:
spark.tispark.tikv.tls_enable true
spark.tispark.tikv.jks_enable true
spark.tispark.tikv.jks_key_path /home/tispark/config/tikv-truststore
spark.tispark.tikv.jks_key_password tikv_trustore_password
spark.tispark.tikv.jks_trust_path /home/tispark/config/tikv-clientstore
spark.tispark.tikv.jks_trust_password tikv_clientstore_password
当你同时配置 JKS 和 X.509 证书时,JKS 优先级更高。因此,当你只想使用普通的 pem 证书时,不要同时设置 spark.tispark.tikv.jks_enable=true。
- 下面是一个配置 JDBC connector TLS 的例子:
spark.tispark.jdbc.tls_enable true
spark.tispark.jdbc.server_cert_store /home/tispark/jdbc-truststore
spark.tispark.jdbc.server_cert_password jdbc_truststore_password
spark.tispark.jdbc.client_cert_store /home/tispark/jdbc-clientstore
spark.tispark.jdbc.client_cert_password jdbc_clientstore_password
- 对于如何开启 TiDB TLS,请参考 Enable TLS between TiDB Clients and Servers。
- 对于如何生成 JAVA key store,请参考 Connecting Securely Using SSL。
时区配置
使用 -Duser.timezone 系统参数来配置时区(比如 -Duser.timezone=GMT-7)。时区会影响 Timestamp 数据类型。
请不要使用 spark.sql.session.timeZone。
特性
TiSpark 的主要特性如下:
Expression index 支持
TiDB v5.0 开始支持 expression index。
TiSpark 目前支持从 expression index 的表中获取数据,但 expression index 不会被 TiSpark 执行计划使用。
TiFlash 支持
TiSpark 能够通过配置 spark.tispark.isolation_read_engines 从 TiFlash 读取数据。
分区表支持
读分区表
TiSpark 目前支持读取 range 与 hash 分区表。
TiSpark 目前不支持 partition table 语法 select col_name from table_name partition(partition_name)。但是,你仍可以使用 where 条件过滤分区。
TiSpark 会根据分区类型、分区表达式以及具体 SQL 决定是否进行分区裁剪。目前,TiSpark 仅支持在 range 分区下,且在下列任一条件下进行分区裁剪:
- 列表达式,如
partition by col1。 - 形如
YEAR($col)的 year 函数,其中 col 为列名且类型为 datetime、date 或能被解析为 datetime、date 的 string 字面量。 - 形如
TO_DAYS($col)的 to_days 函数,其中 col 为列名且类型为 datetime、date 或能被解析为 datetime、date 的 string 字面量。
如果分区裁剪未被应用,TiSpark 将会读取所有分区表。
写分区表
目前, TiSpark 仅支持写入 range 与 hash 分区表,且需满足以下任一条件:
- 列表达式,如
partition by col1。 - 形如
YEAR($col)的 year 函数,其中 col 为列名且类型为 datetime、date 或能被解析为 datetime、date 的 string 字面量。
有两种方式写入分区表:
- 使用支持 replace 和 append 语义的 Datasource API 写入分区表。
- 使用 Spark SQL 删除语句。
安全
从 TiSpark v2.5.0 起,你可以通过 TiDB 对 TiSpark 进行鉴权与授权。
该功能默认关闭。要开启该功能,请在 Spark 配置文件 spark-defaults.conf 中添加以下配置项:
// 开启鉴权与授权功能
spark.sql.auth.enable true
// 配置 TiDB 信息
spark.sql.tidb.addr $your_tidb_server_address
spark.sql.tidb.port $your_tidb_server_port
spark.sql.tidb.user $your_tidb_server_user
spark.sql.tidb.password $your_tidb_server_password
更多详细信息,请参考 TiSpark 鉴权与授权指南。
其他特性
统计信息
TiSpark 可以使用 TiDB 的统计信息:
- 选择代价最低的索引访问
- 估算数据大小以决定是否进行广播优化
如果你希望 TiSpark 使用统计信息支持,需要确保所涉及的表已经被分析。参考统计信息简介了解如何进行表分析。
从 TiSpark 2.0 开始,统计信息将会默认被读取。
FAQ
详情请参考 TiSpark FAQ。