TiDB Lightning 常见问题
本文列出了一些使用 TiDB Lightning 时可能会遇到的问题与答案。
TiDB Lightning 对 TiDB/TiKV/PD 的最低版本要求是多少?
TiDB Lightning 的版本应与集群相同。如果使用 Local-backend 模式,最低版本要求为 4.0.0。如果使用 Importer-backend 或 TiDB-backend 模式最低版本要求是 2.0.9,但建议使用最新的稳定版本 3.0。
TiDB Lightning 支持导入多个库吗?
支持。
TiDB Lightning 对下游数据库的账号权限要求是怎样的?
详细权限描述参考 TiDB Lightning 使用前提。
TiDB Lightning 在导数据过程中某个表报错了,会影响其他表吗?进程会马上退出吗?
如果只是个别表报错,不会影响整体。报错的那个表会停止处理,继续处理其他的表。
如何正确重启 TiDB Lightning?
如果使用 Importer-backend,根据 tikv-importer 的状态,重启 TiDB Lightning 的基本顺序如下:
如果 tikv-importer 仍在运行:
- 结束
tidb-lightning进程。 - 执行修改操作(如修复数据源、更改设置、更换硬件等)。
- 如果上面的修改操作更改了任何表,你还需要清除对应的断点。
- 重启
tidb-lightning。
如果 tikv-importer 需要重启:
- 结束
tidb-lightning进程。 - 结束
tikv-importer进程。 - 执行修改操作(如修复数据源、更改设置、更换硬件等)。
- 重启
tikv-importer。 - 重启
tidb-lightning并等待,直到程序因校验和错误(如果有的话)而失败。- 重启
tikv-importer将清除所有仍在写入的引擎文件,但是tidb-lightning并不会感知到该操作。从 v3.0 开始,最简单的方法是让tidb-lightning继续,然后再重试。
- 重启
- 清除失败的表及断点。
- 再次重启
tidb-lightning。
如果使用 Local-backend 和 TiDB-backend,操作和 Importer-backend 的 tikv-importer 仍在运行时相同。
如何校验导入的数据的正确性?
TiDB Lightning 默认会对导入数据计算校验和 (checksum),如果校验和不一致就会停止导入该表。可以在日志看到相关的信息。
TiDB 也支持从 MySQL 命令行运行 ADMIN CHECKSUM TABLE 指令来计算校验和。
ADMIN CHECKSUM TABLE `schema`.`table`;
+---------+------------+---------------------+-----------+-------------+
| Db_name | Table_name | Checksum_crc64_xor | Total_kvs | Total_bytes |
+---------+------------+---------------------+-----------+-------------+
| schema | table | 5505282386844578743 | 3 | 96 |
+---------+------------+---------------------+-----------+-------------+
1 row in set (0.01 sec)
TiDB Lightning 支持哪些格式的数据源?
目前,TiDB Lightning 支持:
- 导入 Dumpling、CSV 或 Amazon Aurora Parquet 输出格式的数据源。
- 从本地盘或 Amazon S3 云盘读取数据。
我已经在下游创建好库和表了,TiDB Lightning 可以忽略建库建表操作吗?
自 v5.1 起,TiDB Lightning 可以自动识别下游的库和表。如果你使用低于 v5.1 的 TiDB Lightning,需在配置文档中的 [mydumper] 部分将 no-schema 设置为 true 即可。no-schema=true 会默认下游已经创建好所需的数据库和表,如果没有创建,会报错。
如何禁止导入不合规的数据?
可以通过开启严格 SQL 模式 (Strict SQL Mode) 来实现。
TiDB Lightning 默认的 sql_mode 为 "ONLY_FULL_GROUP_BY,NO_AUTO_CREATE_USER",允许导入某些不合规的数值,例如 1970-00-00 这样的日期。
如果要禁止导入不合规的数据,需要修改配置文件 [tidb] 下的 sql-mode 值为 "STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION"。
...
[tidb]
sql-mode = "STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION"
...
可以启用一个 tikv-importer,同时有多个 tidb-lightning 进程导入数据吗?
只要每个 TiDB Lightning 操作的表互不相同就可以。
如何正确结束 tikv-importer 进程?
手动部署:如果 tikv-importer 正在前台运行,可直接按 Ctrl+C 退出。否则,可通过 ps aux | grep tikv-importer 获取进程 ID,然后通过 kill «pid» 结束进程。
如何正确结束 tidb-lightning 进程?
根据部署方式,选择相应操作结束进程。
手动部署:如果 tidb-lightning 正在前台运行,可直接按 Ctrl+C 退出。否则,可通过 ps aux | grep tidb-lightning 获取进程 ID,然后通过 kill -2 «pid» 结束进程。
TiDB Lightning 可以使用千兆网卡吗?
使用 TiDB Lightning 的 SST Mode 建议配置万兆网卡。
千兆网卡的总带宽只有 120 MB/s,而且需要与整个 TiKV 集群共享。在使用 TiDB Lightning 物理导入模式导入时,极易用尽所有带宽,继而因 PD 无法联络集群使集群断连。
为什么 TiDB Lightning 需要在 TiKV 集群预留这么多空间?
当使用默认的 3 副本设置时,TiDB Lightning 需要 TiKV 集群预留数据源大小 6 倍的空间。多出来的 2 倍是算上下列没储存在数据源的因素的保守估计:
- 索引会占据额外的空间
- RocksDB 的空间放大效应
TiDB Lightning 使用过程中是否可以重启 TiKV Importer?
不能,TiKV Importer 会在内存中存储一些引擎文件,重启后,tidb-lightning 会因连接失败而停止。此时,你需要清除失败的断点,因为这些 TiKV Importer 特有的信息丢失了。你可以在之后重启 TiDB Lightning。
如何清除所有与 TiDB Lightning 相关的中间数据?
删除断点文件。
tidb-lightning-ctl --config conf/tidb-lightning.toml --checkpoint-remove=all如果出于某些原因而无法运行该命令,你可以尝试手动删除
/tmp/tidb_lightning_checkpoint.pb文件。如果使用 Local-backend,删除配置中
sorted-kv-dir对应的目录;如果使用 Importer-backend,删除tikv-importer所在机器上的整个import文件目录。如果需要的话,删除 TiDB 集群上创建的所有表和库。
清理残留的元信息。如果存在以下任意一种情况,需要手动清理元信息库:
- 对于 v5.1.x 和 v5.2.x 版本的 TiDB Lightning, tidb-lightning-ctl 命令没有同时清理存储在目标集群的 metadata 库,需要手动清理。
- 如果手动删除过断点文件,则需要手动清理下游的元信息库,否则可能影响后续导入的正确性。
使用下面命令清理元信息:
DROP DATABASE IF EXISTS `lightning_metadata`;
如何获取 TiDB Lightning 运行时的 goroutine 信息
如果 TiDB Lightning 的配置文件中已经指定了
status-port,可以跳过此步骤。否则,需要向 TiDB Lightning 发送 USR1 信号以开启status-port。首先通过
ps等命令获取 TiDB Lightning 的进程 PID,然后运行如下命令:kill -USR1 <lightning-pid>查看 TiDB Lightning 的日志,其中
starting HTTP server/start HTTP server/started HTTP server的日志会显示新开启的status-port。访问
http://<lightning-ip>:<status-port>/debug/pprof/goroutine?debug=2可获取 goroutine 信息。
为什么 TiDB Lightning 不兼容 Placement Rules in SQL?
TiDB Lightning 不兼容 Placement Rules in SQL。当 TiDB Lightning 导入的数据中包含放置策略 (placement policy) 时,TiDB Lightning 会报错。
不兼容的原因如下:
使用 Placement Rules in SQL,你可以从表或分区级别控制某些 TiKV 节点的数据存储位置。TiDB Lightning 从文本文件中读取数据,并导入到目标 TiDB 集群中。如果导出的数据文件中包含了放置规则 (placement rules) 的定义,在导入过程中,TiDB Lightning 必须根据该定义在目标集群中创建相应的放置规则策略。然而,当源集群和目标集群的拓扑结构不同时,这可能会导致问题。
假设源集群有如下拓扑结构:
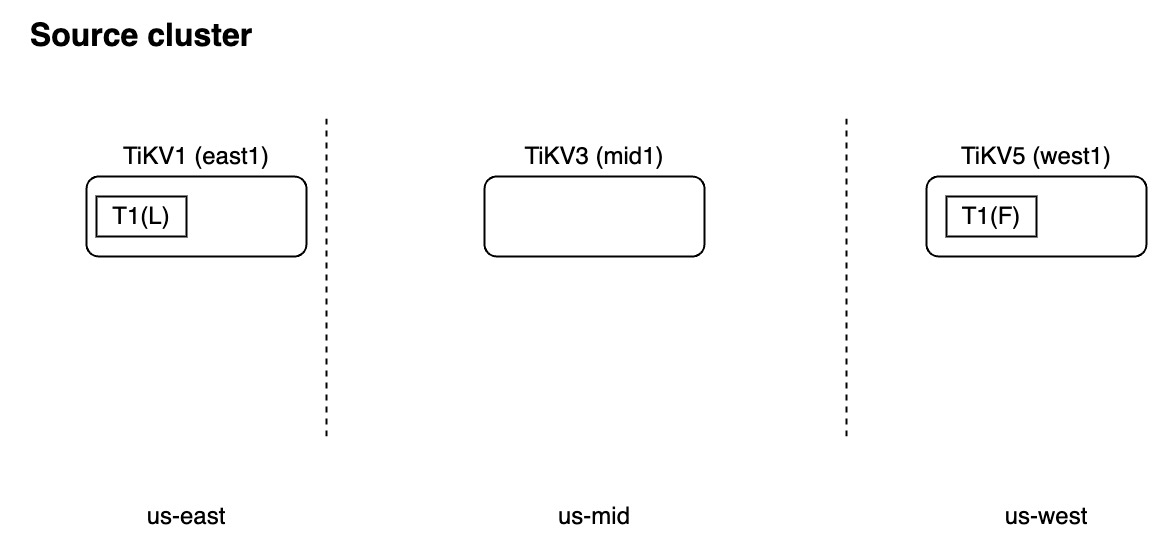
源集群中设置了这样的放置策略:
CREATE PLACEMENT POLICY p1 PRIMARY_REGION="us-east" REGIONS="us-east,us-west";
场景 1:目标集群中有 3 个副本,且拓扑结构与源集群不同。在这种情况下,当 TiDB Lightning 在目标集群中创建放置策略时,TiDB Lightning 不会报错,但目标集群中的语义是错误的。
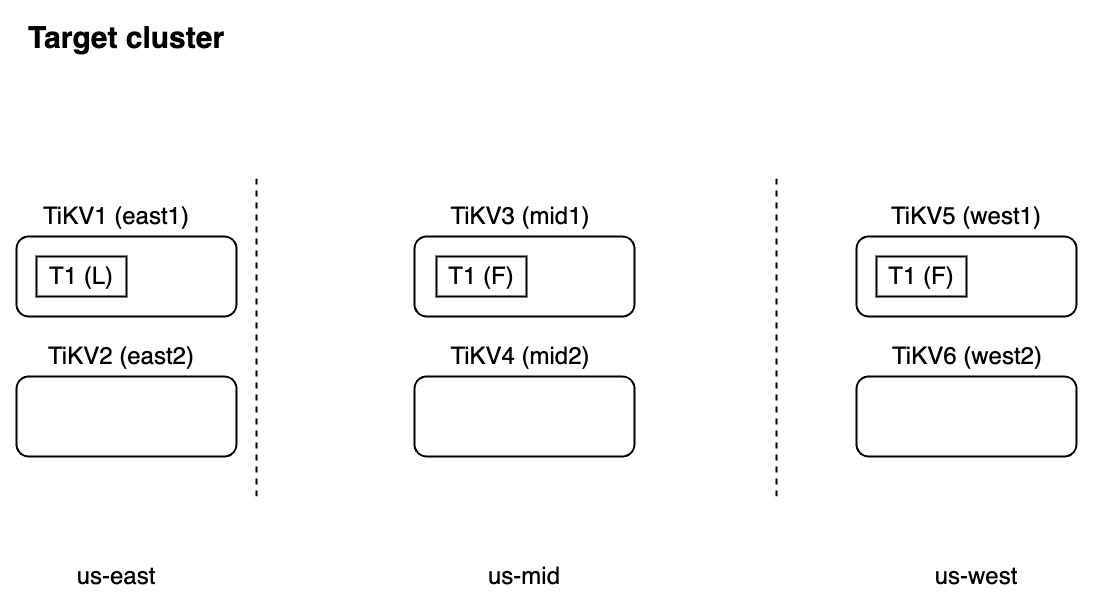
场景 2:目标集群将 Follower 副本放置在区域 "us-mid" 的另一个 TiKV 节点上,且在拓扑结构中没有节点位于区域 "us-west" 中。在这种情况下,当 TiDB Lightning 在目标集群中创建放置策略时,TiDB Lightning 将报错。
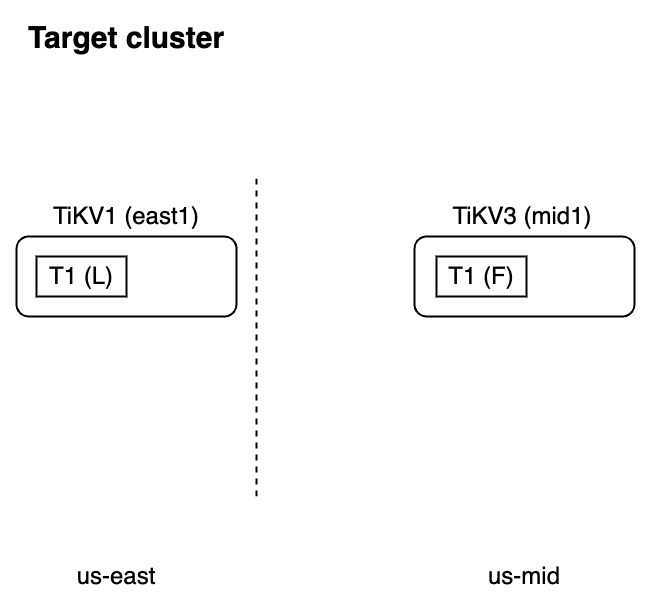
解决方法:
如果要在使用 TiDB Lightning 同时使用 Placement Rules in SQL,你需要在导入数据到目标表之前,确保已经在目标 TiDB 集群中创建了相关的 label 和对象。因为 Placement Rules in SQL 作用于 PD 和 TiKV 层,TiDB Lightning 可以根据获取到的信息,决定应该使用哪个 TiKV 来存储导入的数据。使用这种方法后,Placement Rules in SQL 对 TiDB Lightning 是透明无感的。
具体操作步骤如下:
- 规划数据分布的拓扑结构。
- 为 TiKV 和 PD 配置必要的 label。
- 创建放置规则策略,并将策略应用到目标表上。
- 使用 TiDB Lightning 导入数据到目标表。
如何使用 TiDB Lightning 和 Dumpling 复制 schema?
如果你想要将一个 schema 的定义和表数据复制到一个新的 schema 中,可以按照以下步骤进行操作。通过下面的示例,你可以了解如何将 test schema 复制到一个名为 test2 的新 schema 中。
创建原 schema 的备份,使用
-B test来选定需要的 schema。tiup dumpling -B test -o /tmp/bck1创建
/tmp/tidb-lightning.toml文件,内容如下:[tidb] host = "127.0.0.1" port = 4000 user = "root" [tikv-importer] backend = "tidb" [mydumper] data-source-dir = "/tmp/bck1" [[mydumper.files]] pattern = '^[a-z]*\.(.*)\.[0-9]*\.sql$' schema = 'test2' table = '$1' type = 'sql' [[mydumper.files]] pattern = '^[a-z]*\.(.*)\-schema\.sql$' schema = 'test2' table = '$1' type = 'table-schema'在上述配置文件中,如要使用一个和原始备份中不同的 schema 名称,设置
schema = 'test2'。文件名用于确定表的名称。使用上述配置文件运行导入。
tiup tidb-lightning -config /tmp/tidb-lightning.toml