多表连接查询
很多时候,应用程序需要在一个查询当中使用到多张表的数据,这个时候可以通过 JOIN 语句将两张或多张表的数据组合在一起。
Join 类型
此节将详细叙述 Join 的连接类型。
内连接 INNER JOIN
内连接的连接结果只返回匹配连接条件的行。
例如,想要知道编写过最多书的作家是谁,需要将作家基础信息表 authors 与书籍作者表 book_authors 进行连接。
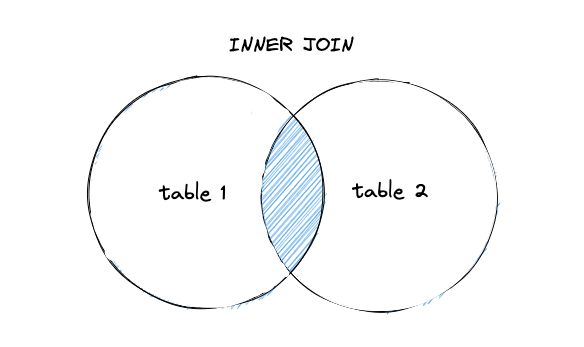
在下面的 SQL 语句当中,通过关键字 JOIN 声明要将左表 authors 和右表 book_authors 的数据行以内连接的方式进行连接,连接条件为 a.id = ba.author_id,那么连接的结果集当中将只会包含满足连接条件的行。假设有一个作家没有编写过任何书籍,那么他在 authors 表当中的记录将无法满足连接条件,因此也不会出现在结果集当中。
SELECT ANY_VALUE(a.id) AS author_id, ANY_VALUE(a.name) AS author_name, COUNT(ba.book_id) AS books
FROM authors a
JOIN book_authors ba ON a.id = ba.author_id
GROUP BY ba.author_id
ORDER BY books DESC
LIMIT 10;
查询结果如下:
+------------+----------------+-------+
| author_id | author_name | books |
+------------+----------------+-------+
| 431192671 | Emilie Cassin | 7 |
| 865305676 | Nola Howell | 7 |
| 572207928 | Lamar Koch | 6 |
| 3894029860 | Elijah Howe | 6 |
| 1150614082 | Cristal Stehr | 6 |
| 4158341032 | Roslyn Rippin | 6 |
| 2430691560 | Francisca Hahn | 6 |
| 3346415350 | Leta Weimann | 6 |
| 1395124973 | Albin Cole | 6 |
| 2768150724 | Caleb Wyman | 6 |
+------------+----------------+-------+
10 rows in set (0.01 sec)
在 Java 中内连接的示例如下:
public List<Author> getTop10AuthorsOrderByBooks() throws SQLException {
List<Author> authors = new ArrayList<>();
try (Connection conn = ds.getConnection()) {
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("""
SELECT ANY_VALUE(a.id) AS author_id, ANY_VALUE(a.name) AS author_name, COUNT(ba.book_id) AS books
FROM authors a
JOIN book_authors ba ON a.id = ba.author_id
GROUP BY ba.author_id
ORDER BY books DESC
LIMIT 10;
""");
while (rs.next()) {
Author author = new Author();
author.setId(rs.getLong("author_id"));
author.setName(rs.getString("author_name"));
author.setBooks(rs.getInt("books"));
authors.add(author);
}
}
return authors;
}
左外连接 LEFT OUTER JOIN
左外连接会返回左表中的所有数据行,以及右表当中能够匹配连接条件的值,如果在右表当中没有找到能够匹配的行,则使用 NULL 填充。
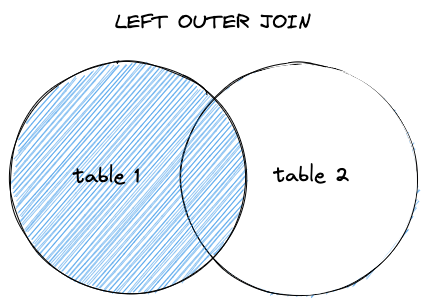
在一些情况下,希望使用多张表来完成数据的查询,但是并不希望因为不满足连接条件而导致数据集变小。
例如,在 Bookshop 应用的首页,希望展示一个带有平均评分的最新书籍列表。在这种情况下,最新的书籍可能是还没有经过任何人评分的,如果使用内连接就会导致这些无人评分的书籍信息被过滤掉,而这并不是期望的结果。
在下面的 SQL 语句当中,通过 LEFT JOIN 关键字声明左表 books 将以左外连接的方式与右表 ratings 进行连接,从而确保 books 表当中的所有记录都能得到返回。
SELECT b.id AS book_id, ANY_VALUE(b.title) AS book_title, AVG(r.score) AS average_score
FROM books b
LEFT JOIN ratings r ON b.id = r.book_id
GROUP BY b.id
ORDER BY b.published_at DESC
LIMIT 10;
查询结果如下:
+------------+---------------------------------+---------------+
| book_id | book_title | average_score |
+------------+---------------------------------+---------------+
| 3438991610 | The Documentary of lion | 2.7619 |
| 3897175886 | Torey Kuhn | 3.0000 |
| 1256171496 | Elmo Vandervort | 2.5500 |
| 1036915727 | The Story of Munchkin | 2.0000 |
| 270254583 | Tate Kovacek | 2.5000 |
| 1280950719 | Carson Damore | 3.2105 |
| 1098041838 | The Documentary of grasshopper | 2.8462 |
| 1476566306 | The Adventures of Vince Sanford | 2.3529 |
| 4036300890 | The Documentary of turtle | 2.4545 |
| 1299849448 | Antwan Olson | 3.0000 |
+------------+---------------------------------+---------------+
10 rows in set (0.30 sec)
看起来最新出版的书籍已经有了很多评分,为了验证上面所说的,通过 SQL 语句把 The Documentary of lion 这本书的所有评分给删掉:
DELETE FROM ratings WHERE book_id = 3438991610;
再次查询,你会发现 The Documentary of lion 这本书依然出现在结果集当中,但是通过右表 ratings 的 score 列计算得到的 average_score 列被填上了 NULL。
+------------+---------------------------------+---------------+
| book_id | book_title | average_score |
+------------+---------------------------------+---------------+
| 3438991610 | The Documentary of lion | NULL |
| 3897175886 | Torey Kuhn | 3.0000 |
| 1256171496 | Elmo Vandervort | 2.5500 |
| 1036915727 | The Story of Munchkin | 2.0000 |
| 270254583 | Tate Kovacek | 2.5000 |
| 1280950719 | Carson Damore | 3.2105 |
| 1098041838 | The Documentary of grasshopper | 2.8462 |
| 1476566306 | The Adventures of Vince Sanford | 2.3529 |
| 4036300890 | The Documentary of turtle | 2.4545 |
| 1299849448 | Antwan Olson | 3.0000 |
+------------+---------------------------------+---------------+
10 rows in set (0.30 sec)
如果改成使用的是内连接 JOIN 结果会怎样?这就交给你来尝试了。
在 Java 中左外连接的示例如下:
public List<Book> getLatestBooksWithAverageScore() throws SQLException {
List<Book> books = new ArrayList<>();
try (Connection conn = ds.getConnection()) {
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("""
SELECT b.id AS book_id, ANY_VALUE(b.title) AS book_title, AVG(r.score) AS average_score
FROM books b
LEFT JOIN ratings r ON b.id = r.book_id
GROUP BY b.id
ORDER BY b.published_at DESC
LIMIT 10;
""");
while (rs.next()) {
Book book = new Book();
book.setId(rs.getLong("book_id"));
book.setTitle(rs.getString("book_title"));
book.setAverageScore(rs.getFloat("average_score"));
books.add(book);
}
}
return books;
}
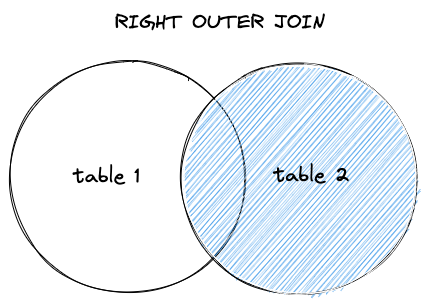
右外连接 RIGHT OUTER JOIN
右外连接返回右表中的所有记录,以及左表当中能够匹配连接条件的值,没有匹配的值则使用 NULL 填充。
交叉连接 CROSS JOIN
当连接条件恒成立时,两表之间的内连接称为交叉连接(又被称为“笛卡尔连接”)。交叉连接会把左表的每一条记录和右表的所有记录相连接,如果左表的记录数为 m,右表的记录数为 n,则结果集中会产生 m * n 条记录。
左半连接 LEFT SEMI JOIN
TiDB 在 SQL 语法层面上不支持 LEFT SEMI JOIN table_name,但是在执行计划层面,子查询相关的优化会将 semi join 作为改写后的等价 JOIN 查询默认的连接方式。
隐式连接
在显式声明连接的 JOIN 语句作为 SQL 标准出现之前,在 SQL 语句当中可以通过 FROM t1, t2 子句来连接两张或多张表,通过 WHERE t1.id = t2.id 子句来指定连接的条件。你可以将其理解为隐式声明的连接,隐式连接会使用内连接的方式进行连接。
Join 相关算法
TiDB 支持下列三种常规的表连接算法,优化器会根据所连接表的数据量等因素来选择合适的 Join 算法去执行。你可以通过 EXPLAIN 语句来查看查询使用了何种算法进行 Join。
如果发现 TiDB 的优化器没有按照最佳的 Join 算法去执行。你也可以通过 Optimizer Hints 强制 TiDB 使用更好的 Join 算法去执行。
例如,假设上文当中的左连接查询的示例 SQL 使用 Hash Join 算法执行更快,而优化器并没有选择这种算法,你可以在 SELECT 关键字后面加上 Hint /*+ HASH_JOIN(b, r) */(注意:如果表名添加了别名,Hint 当中也应该使用表别名)。
EXPLAIN SELECT /*+ HASH_JOIN(b, r) */ b.id AS book_id, ANY_VALUE(b.title) AS book_title, AVG(r.score) AS average_score
FROM books b
LEFT JOIN ratings r ON b.id = r.book_id
GROUP BY b.id
ORDER BY b.published_at DESC
LIMIT 10;
Join 算法相关的 Hints:
- MERGE_JOIN(t1_name [, tl_name ...])
- INL_JOIN(t1_name [, tl_name ...])
- INL_HASH_JOIN(t1_name [, tl_name ...])
- HASH_JOIN(t1_name [, tl_name ...])
Join 顺序
在实际的业务场景中,多个表的 Join 语句是很常见的,而 Join 的执行效率和各个表参与 Join 的顺序有关。TiDB 使用 Join Reorder 算法来确定多个表进行 Join 的顺序。
当优化器选择的 Join 顺序并不够好时,你可以使用 STRAIGHT_JOIN 语法让 TiDB 强制按照 FROM 子句中所使用的表的顺序做联合查询。
EXPLAIN SELECT *
FROM authors a STRAIGHT_JOIN book_authors ba STRAIGHT_JOIN books b
WHERE b.id = ba.book_id AND ba.author_id = a.id;
关于该算法的实现细节和限制你可以通过查看Join Reorder 算法简介章节进行了解。