TiCDC 性能分析和优化方法
本文介绍 TiCDC 资源使用率和关键的性能指标。你可以通过 Performance Overview 面板中的 CDC 面板来监控和评估 TiCDC 同步数据的性能。
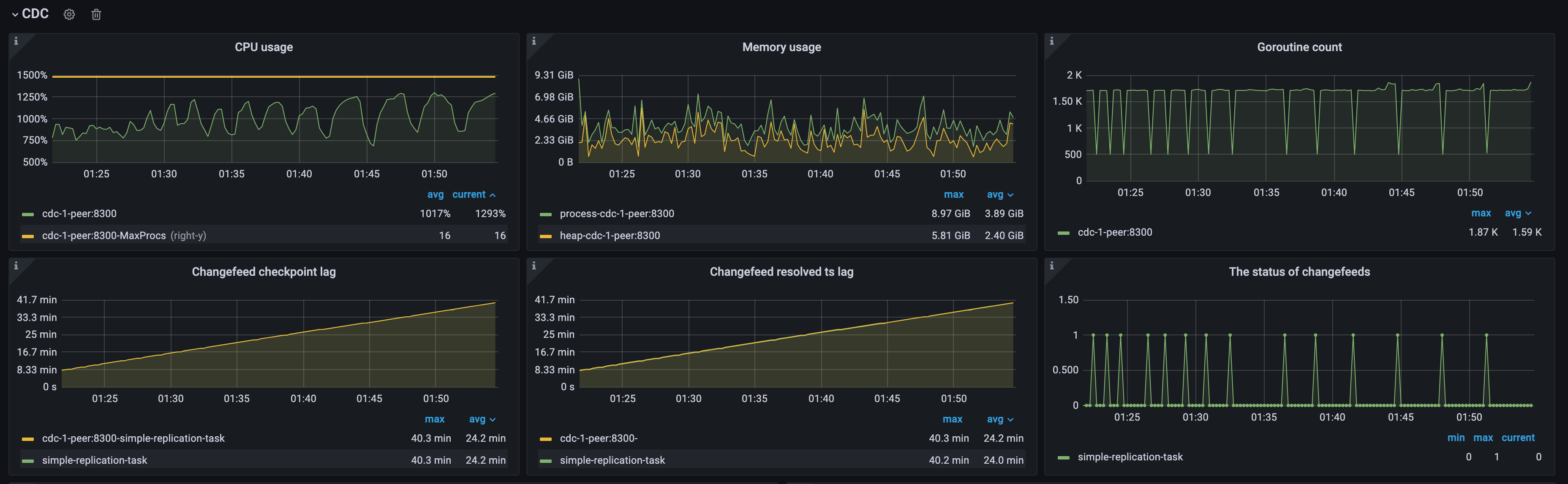
TiCDC 集群的资源利用率
通过以下三个指标,你可以快速判断 TiCDC 集群的资源使用率:
- CPU usage:TiCDC 节点的 CPU 使用情况
- Memory usage:TiCDC 节点的内存使用情况
- Goroutine count:TiCDC 节点 Goroutine 的个数
TiCDC 数据同步关键指标
TiCDC 整体指标
通过以下指标,你可以了解 TiCDC 数据同步的整体情况:
Changefeed checkpoint lag:同步任务上下游数据的进度差,以时间单位秒计算。
如果 TiCDC 消费数据的速度和写入下游的速度能跟上上游的数据变更,该指标将保持在较小的延迟范围内,通常是 10 秒以内。如果 TiCDC 消费数据的速度和写入下游的速度跟不上上游的数据变更,则该指标将持续增长。
该指标增长(即 TiCDC checkpoint lag 增长)的常见原因如下:
- 系统资源不足:如果 TiCDC 系统中的 CPU、内存或磁盘空间不足,可能会导致数据处理速度过慢,从而导致 TiCDC Changefeed checkpoint 过长。
- 网络问题:如果 TiCDC 系统中存在网络中断、延迟或带宽不足的问题,可能会影响数据的传输速度,从而导致 TiCDC Changefeed checkpoint 过长。
- 上游 QPS 过高:如果 TiCDC 系统需要处理的数据量过大,可能会导致数据处理超时,从而导致 TiCDC Changefeed checkpoint 增长,通常一个 TiCDC 节点处理的 QPS 上限为 60K 左右。
- 数据库问题:
- 上游 TiKV 集群
min resolved ts和最新的 PD TSO 差距过大,通常是因为上游写入负载过大,TiKV 无法及时推进 resolved ts 造成。 - 下游数据库写入延迟高导致 TiCDC 无法及时将数据同步到下游。
- 上游 TiKV 集群
Changefeed resolved ts lag:TiCDC 节点内部同步状态与上游的进度差,以时间单位秒计算。如果 TiCDC Changefeed resolved ts lag 值很高,可能意味着 TiCDC 系统的 Puller 或者 Sorter 模块数据处理能力不足,或者可能存在网络延迟或磁盘读写速度慢的问题。在这种情况下,需要采取适当的措施,例如增加 TiCDC 实例数量或优化网络配置,以确保 TiCDC 系统的高效和稳定运行。
The status of changefeeds:Changefeed 各状态的解释,请参考 Changefeed 状态流转。
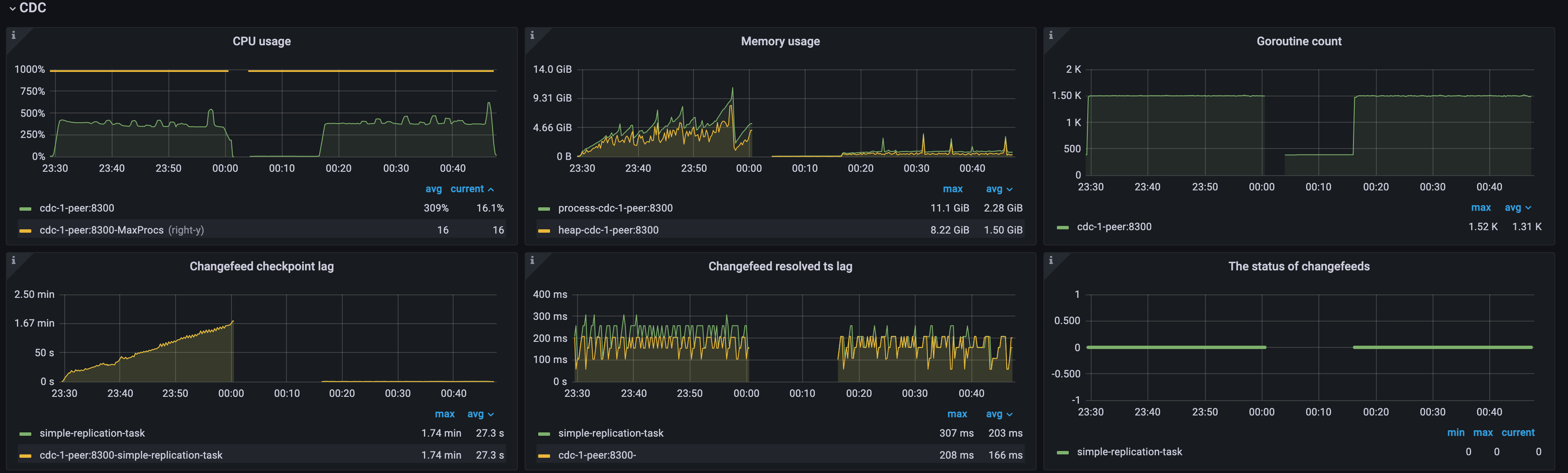
示例 1:单个 TiCDC 节点上游 QPS 过高导致 checkpoint lag 过高
如下图所示,因为上游 QPS 过高,该集群中只有单个 TiCDC 节点,TiCDC 节点处于过载状态,CPU 使用率较高,Changefeed checkpoint lag 和 Changefeed resolved ts lag 持续增长。Changefeeds 的状态间歇性地从 0 变为 1,意味着 changefeed 不断出错。你可尝试通过增加资源解决该问题:
- 添加 TiCDC 节点:将 TiCDC 集群扩展到多个节点,以增加处理能力。
- 优化 TiCDC 节点的资源:提高 TiCDC 节点的 CPU 和内存配置,以改善性能。
数据流吞吐指标和下游延迟信息
通过以下指标,你可以了解数据流的吞吐和下游延迟信息:
- Puller output events/s:TiCDC 节点中 Puller 模块每秒输出到 Sorter 模块的数据变更行数
- Sorter output events/s:TiCDC 节点中 Sorter 模块每秒输出到 Mounter 模块的行数
- Mounter output events/s:TiCDC 节点中 Mounter 模块每秒输出到 Sink 模块的行数
- Table sink output events/s:TiCDC 节点中 Table Sorter 模块每秒输出到 Sink 模块的行数
- SinkV2 - Sink flush rows/s:TiCDC 节点中 Sink 模块每秒输出到下游的行数
- Transaction Sink Full Flush Duration:TiCDC 节点中 MySQL Sink 写下游事务的平均延迟和 p999 延迟
- MQ Worker Send Message Duration Percentile:下游为 Kafka 时 MQ worker 发送消息的延迟
- Kafka Outgoing Bytes:MQ Workload 写下游事务的流量
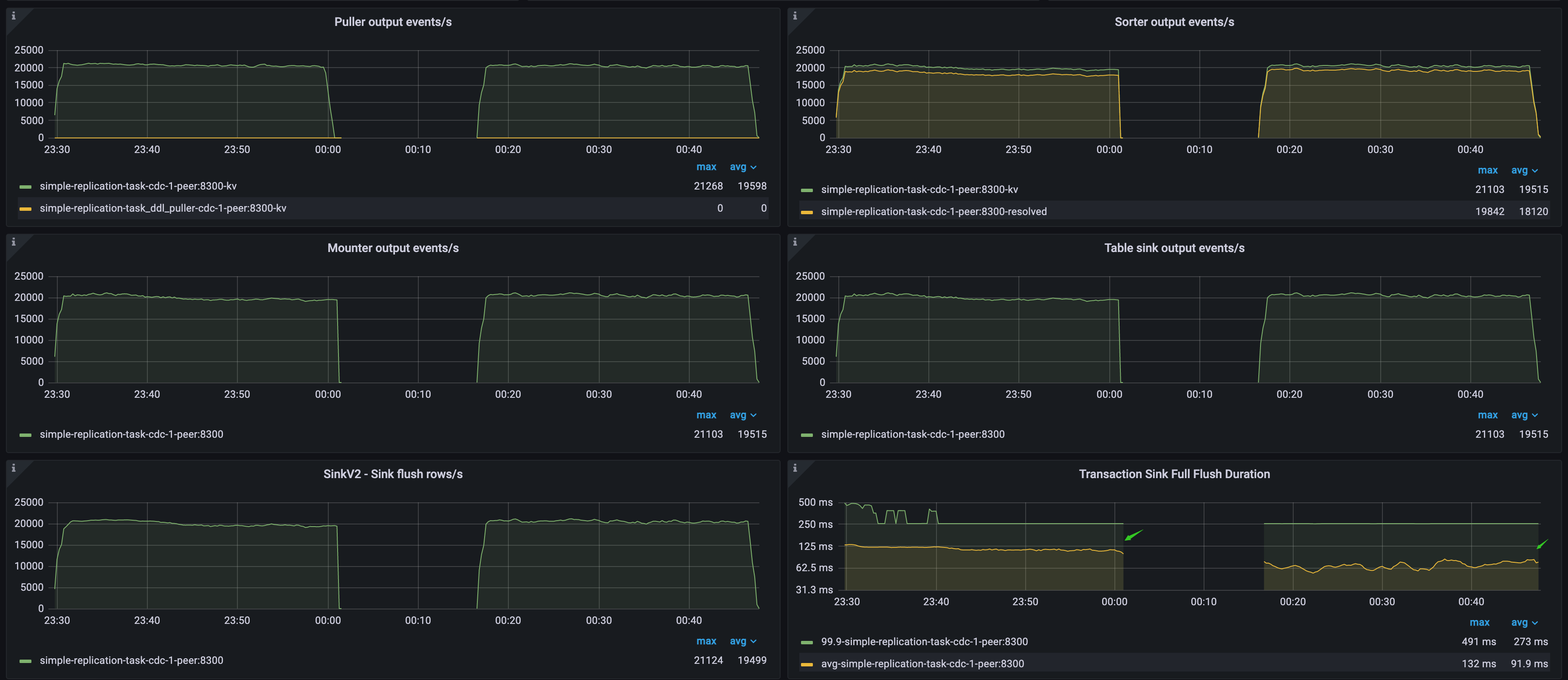
示例 2:下游数据库写入速度对 TiCDC 数据同步性能的影响
如下图所示,该环境上下游都为 TiDB 集群。通过 TiCDC Puller output events/s 可以确认上游数据库的 QPS 值。通过 Transaction Sink Full Flush Duration 可以确认,第一段负载的下游数据库平均写入延迟高,第二段负载的下游平均写入延迟低。
- 在第一段负载期间,由于下游 TiDB 集群写入数据缓慢,导致 TiCDC 消费数据的速度跟不上上游的 QPS,引起 Changefeed checkpoint lag 不断增长。然而,Changefeed resolved ts lag 仍然在 300 毫秒以内,说明同步延迟和吞吐瓶颈不在 puller 和 sorter 模块中,而在下游的 sink 模块。
- 在第二段负载期间,因为下游 TiDB 集群的写入速度快,TiCDC 同步数据的速度完全追上了上游的速度,因此 Changefeed checkpoint lag 和 Changefeed resolved ts lag 保持在 500 毫秒以内,此时 TiCDC 的同步速度较为理想。