与 Confluent Cloud 和 Snowflake 进行数据集成
Confluent 是一个兼容 Apache Kafka 的数据流平台,能够访问、存储和管理连续的实时流数据,具备丰富的数据集成能力。自 v6.1.0 开始,TiCDC 支持将增量变更数据以 Avro 格式输出到 Confluent。本文档介绍如何使用 TiCDC 将 TiDB 的增量数据同步到 Confluent Cloud,并借助 Confluent Cloud 的能力最终将数据分别同步到 Snowflake、ksqlDB、SQL Server。主要内容包括:
- 快速搭建包含 TiCDC 的 TiDB 集群
- 创建将数据输出到 Confluent Cloud 的 changefeed
- 创建将数据从 Confluent Cloud 输出到 Snowflake、ksqlDB 和 SQL Server 的连接器 (Connector)
- 使用 go-tpc 写入数据到上游 TiDB,并观察 Snowflake、ksqlDB 和 SQL Server 中的数据
上述过程将会基于实验环境进行,你也可以参考上述执行步骤,搭建生产级别的集群。
输出增量数据到 Confluent Cloud
第 1 步:搭建环境
部署包含 TiCDC 的 TiDB 集群。
在实验或测试环境中,可以使用 TiUP Playground 功能快速部署 TiCDC,命令如下:
tiup playground --host 0.0.0.0 --db 1 --pd 1 --kv 1 --tiflash 0 --ticdc 1 # 查看集群状态 tiup status如果尚未安装 TiUP,可以参考安装 TiUP。在生产环境下,可以参考使用 TiUP 安装部署 TiCDC 集群,完成 TiCDC 集群部署工作。
注册 Confluent Cloud 并创建 Confluent 集群。
创建 Basic 集群并开放 Internet 访问,详见 Quick Start for Confluent Cloud。
第 2 步:创建 Access Key Pair
创建 Cluster API Key。
在 Confluent 集群控制面板中依次点击 Data integration > API keys > Create key。在弹出的 Select scope for API key 页面,选择 Global access。
创建成功后会得到一个 Key Pair 文件,内容如下:
=== Confluent Cloud API key: xxx-xxxxx === API key: L5WWA4GK4NAT2EQV API secret: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx Bootstrap server: xxx-xxxxx.ap-east-1.aws.confluent.cloud:9092记录 Schema Registry Endpoints。
在 Confluent 集群控制面板中,选择 Schema Registry > API endpoint,记录 Schema Registry Endpoints,如下:
https://yyy-yyyyy.us-east-2.aws.confluent.cloud创建 Schema Registry API key。
在 Confluent 集群控制面板中,选择 Schema Registry > API credentials,点击 Edit 和 Create key。
创建成功后会得到一个 Key Pair 文件,内容如下:
=== Confluent Cloud API key: yyy-yyyyy === API key: 7NBH2CAFM2LMGTH7 API secret: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx以上步骤也可以通过 Confluent CLI 实现,详见 Connect Confluent CLI to Confluent Cloud Cluster。
第 3 步:创建 Kafka changefeed
创建 changefeed 配置文件。
根据 Avro 协议和 Confluent Connector 的要求和规范,每张表的增量数据需要发送到独立的 Topic 中,并且每个事件需要按照主键值分发 Partition。因此,需要创建一个名为
changefeed.conf的配置文件,填写如下内容:[sink] dispatchers = [ {matcher = ['*.*'], topic = "tidb_{schema}_{table}", partition="index-value"}, ]关于配置文件中
dispatchers的详细解释,参考自定义 Kafka Sink 的 Topic 和 Partition 的分发规则。创建一个 changefeed,将增量数据输出到 Confluent Cloud:
tiup ctl:v<CLUSTER_VERSION> cdc changefeed create --server="http://127.0.0.1:8300" --sink-uri="kafka://<broker_endpoint>/ticdc-meta?protocol=avro&replication-factor=3&enable-tls=true&auto-create-topic=true&sasl-mechanism=plain&sasl-user=<broker_api_key>&sasl-password=<broker_api_secret>" --schema-registry="https://<schema_registry_api_key>:<schema_registry_api_secret>@<schema_registry_endpoint>" --changefeed-id="confluent-changefeed" --config changefeed.conf将如下字段替换为第 2 步:创建 Access Key Pair中创建和记录的值:
<broker_endpoint><broker_api_key><broker_api_secret><schema_registry_api_key><schema_registry_api_secret><schema_registry_endpoint>
其中
<schema_registry_api_secret>需要经过 HTML URL 编码后再替换,替换完毕后示例如下:tiup ctl:v<CLUSTER_VERSION> cdc changefeed create --server="http://127.0.0.1:8300" --sink-uri="kafka://xxx-xxxxx.ap-east-1.aws.confluent.cloud:9092/ticdc-meta?protocol=avro&replication-factor=3&enable-tls=true&auto-create-topic=true&sasl-mechanism=plain&sasl-user=L5WWA4GK4NAT2EQV&sasl-password=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" --schema-registry="https://7NBH2CAFM2LMGTH7:xxxxxxxxxxxxxxxxxx@yyy-yyyyy.us-east-2.aws.confluent.cloud" --changefeed-id="confluent-changefeed" --config changefeed.conf如果命令执行成功,将会返回被创建的 changefeed 的相关信息,包含被创建的 changefeed 的 ID 以及相关信息,内容如下:
Create changefeed successfully! ID: confluent-changefeed Info: {... changfeed info json struct ...}如果命令长时间没有返回,请检查当前执行命令所在服务器到 Confluent Cloud 之间网络可达性,参考 Test connectivity to Confluent Cloud。
Changefeed 创建成功后,执行如下命令,查看 changefeed 的状态:
tiup ctl:v<CLUSTER_VERSION> cdc changefeed list --server="http://127.0.0.1:8300"可以参考管理 Changefeed,对 changefeed 状态进行管理。
第 4 步:写入数据以产生变更日志
完成以上步骤后,TiCDC 会将上游 TiDB 的增量数据变更日志发送到 Confluent Cloud。本小节将对 TiDB 写入数据,以产生增量数据变更日志。
模拟业务负载。
在测试实验环境下,可以使用 go-tpc 向上游 TiDB 集群写入数据,以让 TiDB 产生事件变更数据。执行以下命令,会首先在上游 TiDB 创建名为
tpcc的数据库,然后使用 TiUP bench 写入数据到这个数据库中。tiup bench tpcc -H 127.0.0.1 -P 4000 -D tpcc --warehouses 4 prepare tiup bench tpcc -H 127.0.0.1 -P 4000 -D tpcc --warehouses 4 run --time 300s关于 go-tpc 的更多详细内容,可以参考如何对 TiDB 进行 TPC-C 测试。
观察 Confluent 中数据传输情况。
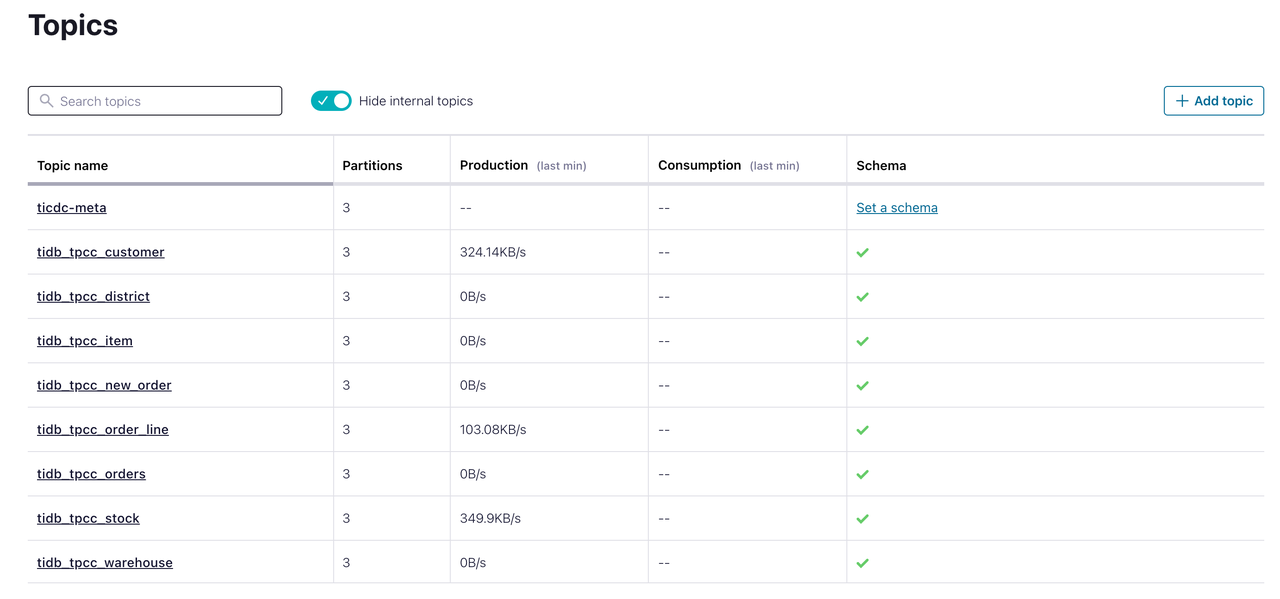
在 Confluent 集群控制面板中,可以观察到相应的 Topic 已经被自动创建,并有数据正在写入。至此,TiDB 数据库中的增量数据就被成功输出到了 Confluent Cloud。
与 Snowflake 进行数据集成
Snowflake 是一种云原生数据仓库。借助 Confluent 的能力,你只需要创建 Snowflake Sink Connector,就可以将 TiDB 的增量数据输出到 Snowflake。
准备工作
注册和创建 Snowflake 集群,参考 Getting Started with Snowflake。
连接到 Snowflake 前,为 Snowflake 添加 Private Key,参考 Key Pair Authentication & Key Pair Rotation。
集成步骤
在 Snowflake 中创建 Database 和 Schema。
在 Snowflake 控制面板中,选择 Data > Database。创建名为
TPCC的 Database 和名为TiCDC的 Schema。在 Confluent 集群控制面板中,选择 Data integration > Connectors > Snowflake Sink,进入如下页面:

选择需要同步到 Snowflake 的 Topic 后,进入下一页面:
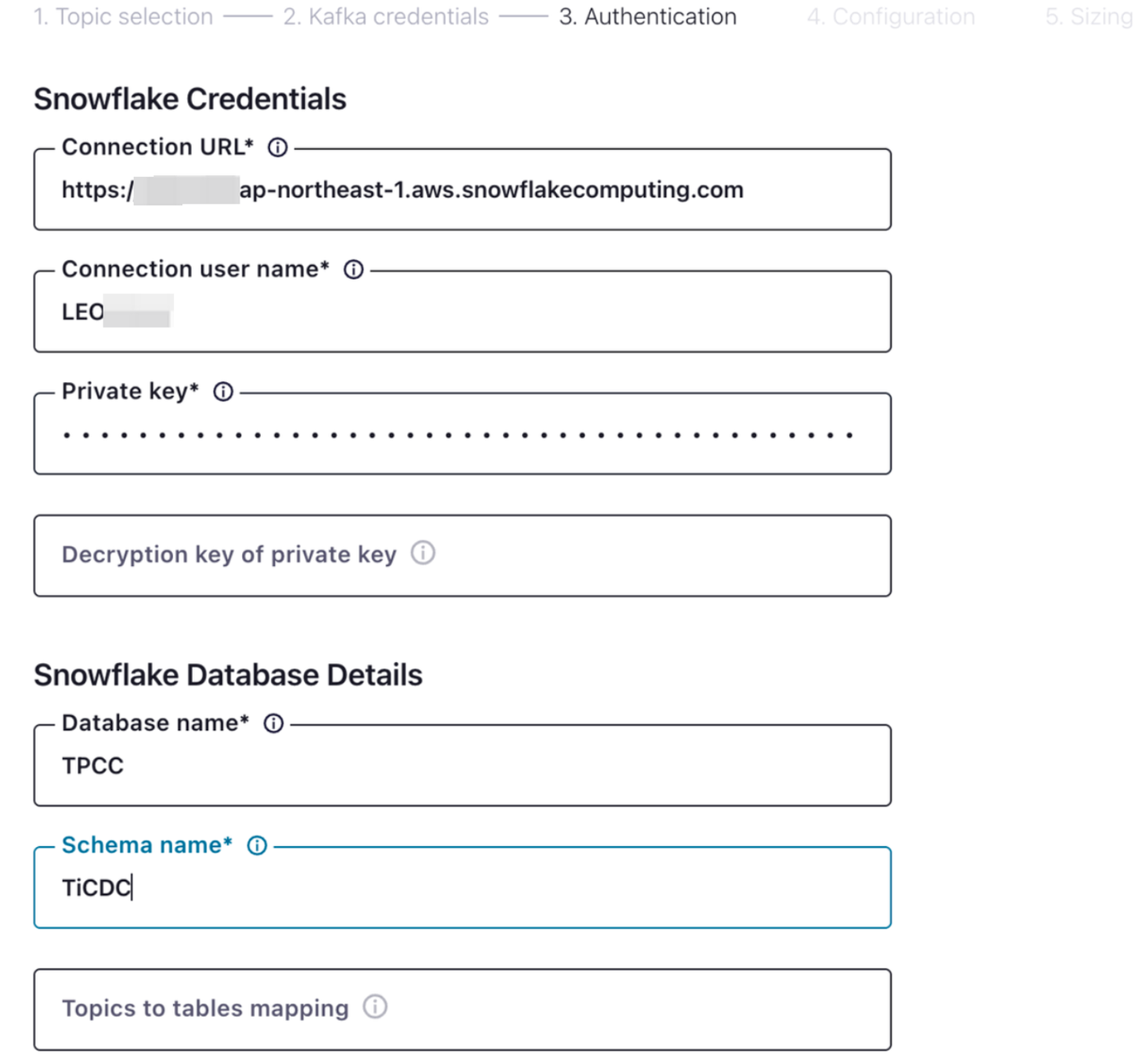
填写 Snowflake 连接认证信息,其中 Database name 和 Schema name 填写在上一步创建的 Database 和 Schema 名,随后进入下一页面:
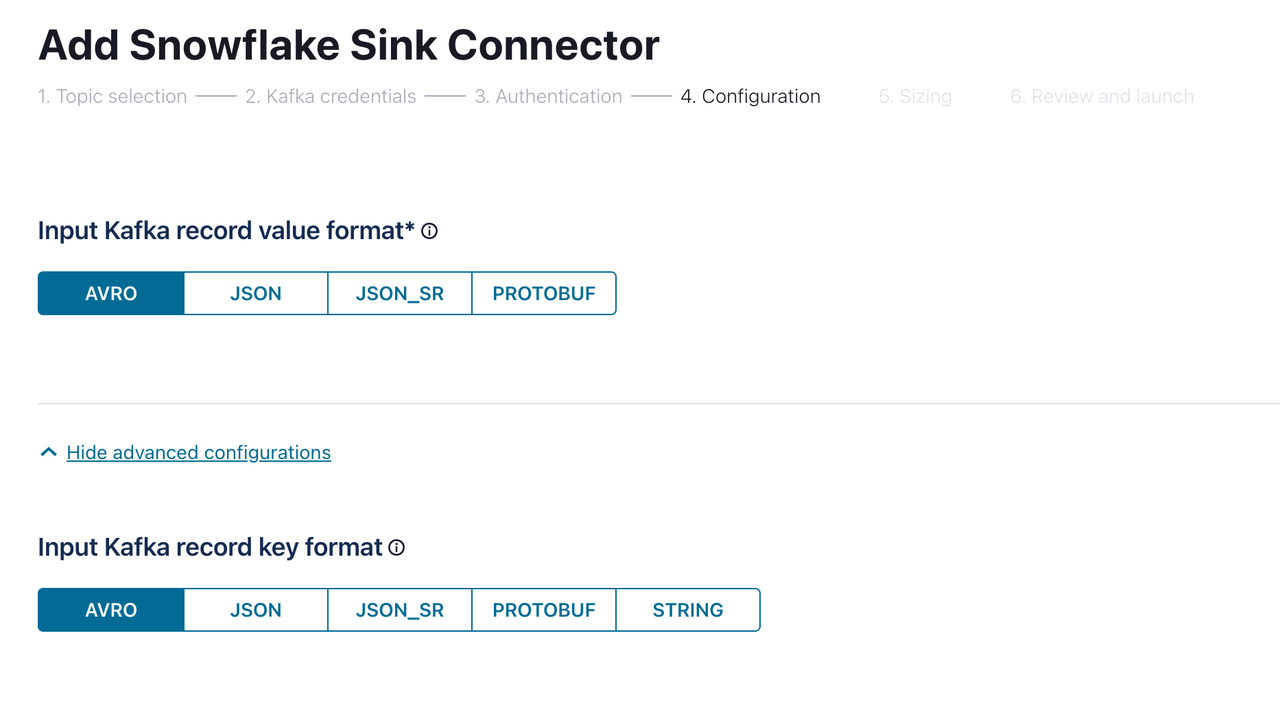
在 Configuration 页面中,
record value format和record key format都选择AVRO,点击 Continue,直到 Connector 创建完成。等待 Connector 状态变为RUNNING,这个过程可能持续数分钟。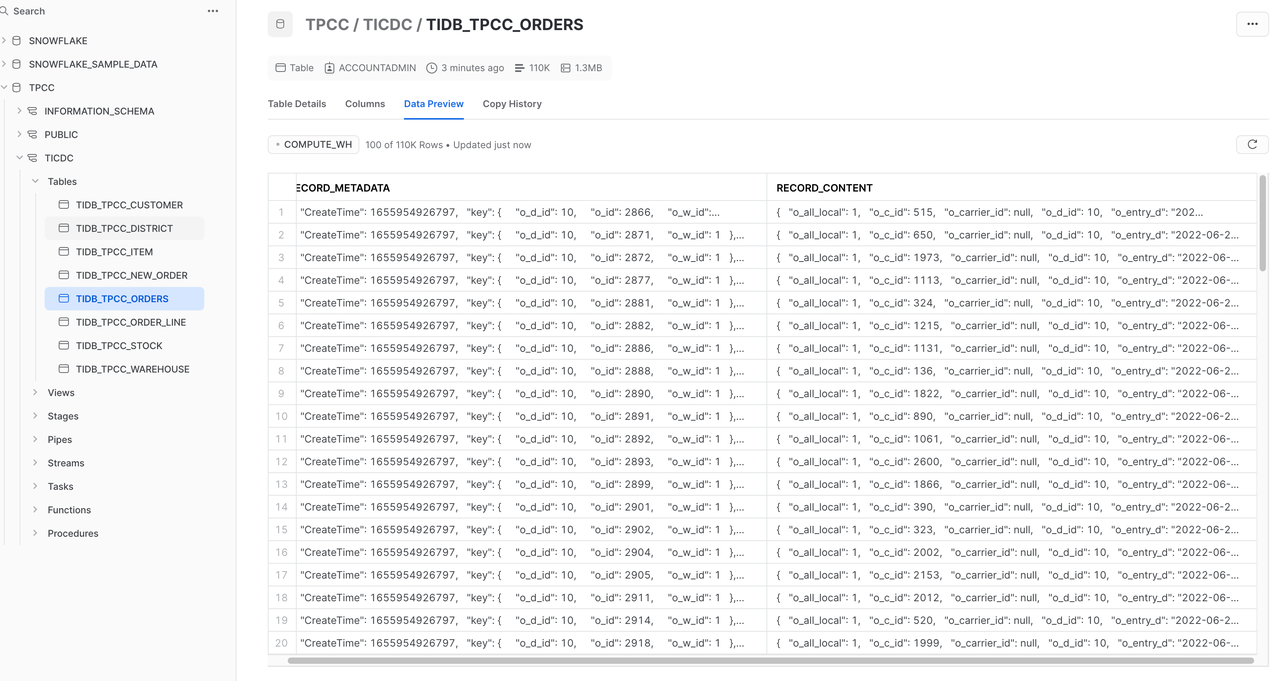
在 Snowflake 控制面板中,选择 Data > Database > TPCC > TiCDC,可以观察到 TiDB 中的增量数据实时同步到了 Snowflake,如上图。但 Snowflake 中的表结构和 TiDB 中的表结构不同,数据也以“追加”的方式插入 Snowflake 表。在大多数业务场景中,都希望 Snowflake 中的表数据是 TiDB 表的一个副本,而不是存储 TiDB 表的变更日志。该问题将在下一章节解决。
在 Snowflake 中创建 TiDB 表对应的数据副本
在上一章节,TiDB 的增量变更日志已经被同步到 Snowflake 中,本章节将介绍如何借助 Snowflake 的 TASK 和 STREAM 功能,将实时写入 Snowflake 的数据变更日志根据 INSERT、UPDATE 和 DELETE 等事件类型分别处理,写入一个与上游 TiDB 结构相同的表中,从而在 Snowflake 中创建一个数据副本。下面以 ITEM 表为例。
ITEM 表结构为:
CREATE TABLE `item` (
`i_id` int(11) NOT NULL,
`i_im_id` int(11) DEFAULT NULL,
`i_name` varchar(24) DEFAULT NULL,
`i_price` decimal(5,2) DEFAULT NULL,
`i_data` varchar(50) DEFAULT NULL,
PRIMARY KEY (`i_id`)
);
Snowflake 中存在一张名为 TIDB_TEST_ITEM 的表,这张表是 Confluent Snowflake Sink Connector 自动创建的,表结构如下:
create or replace TABLE TIDB_TEST_ITEM (
RECORD_METADATA VARIANT,
RECORD_CONTENT VARIANT
);
根据 TiDB 中的表结构,在 Snowflake 中创建结构相同的表:
create or replace table TEST_ITEM ( i_id INTEGER primary key, i_data VARCHAR, i_im_id INTEGER, i_name VARCHAR, i_price DECIMAL(36,2) );为
TIDB_TEST_ITEM创建一个 STREAM,将append_only设为true,表示仅接收INSERT事件。创建的 STREAM 可以实时捕获TIDB_TEST_ITEM的INSERT事件,也就是说,当 TiDB 中ITEM有新的变更日志时,变更日志将会被插入到TIDB_TEST_ITEM表,然后被 STREAM 捕获。create or replace stream TEST_ITEM_STREAM on table TIDB_TEST_ITEM append_only=true;处理 STREAM 中的数据,根据不同的事件类型,在
TEST_ITEM表中插入、更新或删除 STREAM 数据。--将数据合并到 TEST_ITEM 表 merge into TEST_ITEM n using -- 查询 TEST_ITEM_STREAM (SELECT RECORD_METADATA:key as k, RECORD_CONTENT:val as v from TEST_ITEM_STREAM) stm -- 以 i_id 相等为条件将流和表做匹配 on k:i_id = n.i_id -- 如果 TEST_ITEM 表中存在匹配 i_id 的记录,并且 v 为空,则删除这条记录 when matched and IS_NULL_VALUE(v) = true then delete -- 如果 TEST_ITEM 表中存在匹配 i_id 的记录,并且 v 不为空,则更新这条记录 when matched and IS_NULL_VALUE(v) = false then update set n.i_data = v:i_data, n.i_im_id = v:i_im_id, n.i_name = v:i_name, n.i_price = v:i_price -- 如果 TEST_ITEM 表中不存在匹配 i_id 的记录,则插入这条记录 when not matched then insert (i_data, i_id, i_im_id, i_name, i_price) values (v:i_data, v:i_id, v:i_im_id, v:i_name, v:i_price) ;在上面的语句中,我们使用了 Snowflake 的
MERGE INTO语句,这个语句可以根据条件将流和表做匹配,然后根据不同的匹配结果,执行不同的操作,比如删除、更新或插入。在这个例子中,我们使用了三个WHEN子句,分别对应了三种情况:- 当流和表匹配时,且流中的数据为空,则删除表中的记录
- 当流和表匹配时,且流中的数据不为空,则更新表中的记录
- 当流和表不匹配时,则插入流中的数据
周期性执行第三步中的语句,以保证数据的实时性。可通过 Snowflake 的
SCHEDULED TASK来实现:-- 创建一个 TASK,周期性执行 MERGE INTO 语句 create or replace task STREAM_TO_ITEM warehouse = test -- 每分钟执行一次 schedule = '1 minute' when -- 当 TEST_ITEM_STREAM 中无数据时跳过 system$stream_has_data('TEST_ITEM_STREAM') as -- 将数据合并到 TEST_ITEM 表,和上文中的 merge into 语句相同 merge into TEST_ITEM n using (select RECORD_METADATA:key as k, RECORD_CONTENT:val as v from TEST_ITEM_STREAM) stm on k:i_id = n.i_id when matched and IS_NULL_VALUE(v) = true then delete when matched and IS_NULL_VALUE(v) = false then update set n.i_data = v:i_data, n.i_im_id = v:i_im_id, n.i_name = v:i_name, n.i_price = v:i_price when not matched then insert (i_data, i_id, i_im_id, i_name, i_price) values (v:i_data, v:i_id, v:i_im_id, v:i_name, v:i_price) ;
至此,你就建立了一条具备一定 ETL 能力的数据通路,使得 TiDB 的增量数据变更日志能够被输出到 Snowflake,并且维护一个 TiDB 表的数据副本,实现在 Snowflake 中使用 TiDB 表的数据。最后一步操作是定期清理 TIDB_TEST_ITEM 表中的无用数据:
-- 每两小时清空表 TIDB_TEST_ITEM
create or replace task TRUNCATE_TIDB_TEST_ITEM
warehouse = test
schedule = '120 minute'
when
system$stream_has_data('TIDB_TEST_ITEM')
as
TRUNCATE table TIDB_TEST_ITEM;
与 ksqlDB 进行数据集成
ksqlDB 是一种面向流式数据处理的数据库。你可以直接在 Confluent Cloud 上创建 ksqlDB 集群,并且直接读取 TiCDC 输出到 Confluent 的增量数据。
在 Confluent 集群控制面板中选择 ksqlDB,按照引导创建 ksqlDB 集群。
等待集群状态为 Running 后,进入下一步操作,这个过程可能持续数分钟。
在 ksqlDB Editor 中执行如下命令,创建一个用于读取
tidb_tpcc_ordersTopic 的 STREAM。CREATE STREAM orders (o_id INTEGER, o_d_id INTEGER, o_w_id INTEGER, o_c_id INTEGER, o_entry_d STRING, o_carrier_id INTEGER, o_ol_cnt INTEGER, o_all_local INTEGER) WITH (kafka_topic='tidb_tpcc_orders', partitions=3, value_format='AVRO');执行如下命令查询 orders STREAM 数据:
SELECT * FROM ORDERS EMIT CHANGES;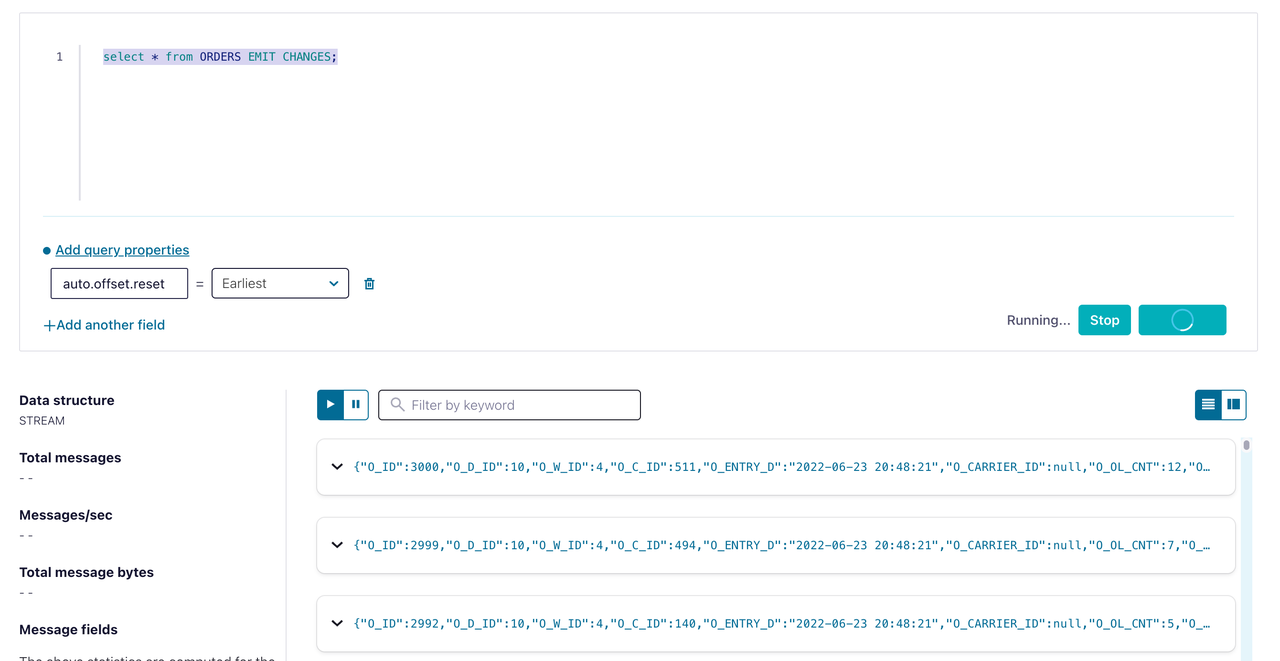
可以观察到 TiDB 中的增量数据实时同步到了 ksqlDB,如上图。至此,就完成了 TiDB 与 ksqlDB 的数据集成。
与 SQL Server 进行数据集成
SQL Server 是 Microsoft 推出的关系型数据库软件。借助 Confluent 的能力,你只需要创建 SQL Server Sink Connector,就可以将 TiDB 的增量数据输出到 SQL Server。
连接 SQL Server 服务器,创建名为
tpcc的数据库:[ec2-user@ip-172-1-1-1 bin]$ sqlcmd -S 10.61.43.14,1433 -U admin Password: 1> create database tpcc 2> go 1> select name from master.dbo.sysdatabases 2> go name ---------------------------------------------------------------------- master tempdb model msdb rdsadmin tpcc (6 rows affected)在 Confluent 集群控制面板中,选择 Data integration > Connectors > Microsoft SQL Server Sink,进入如下页面:
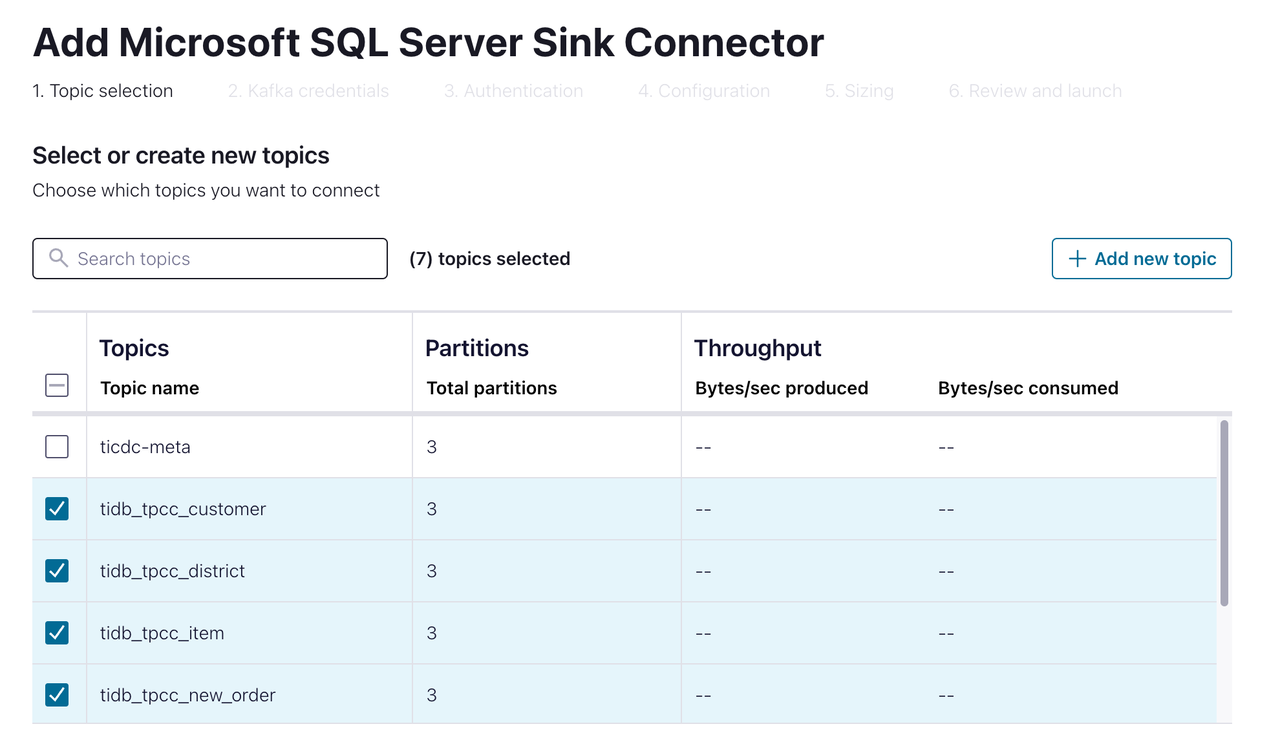
选择需要同步到 SQL Server 的 Topic 后,进入下一页面:
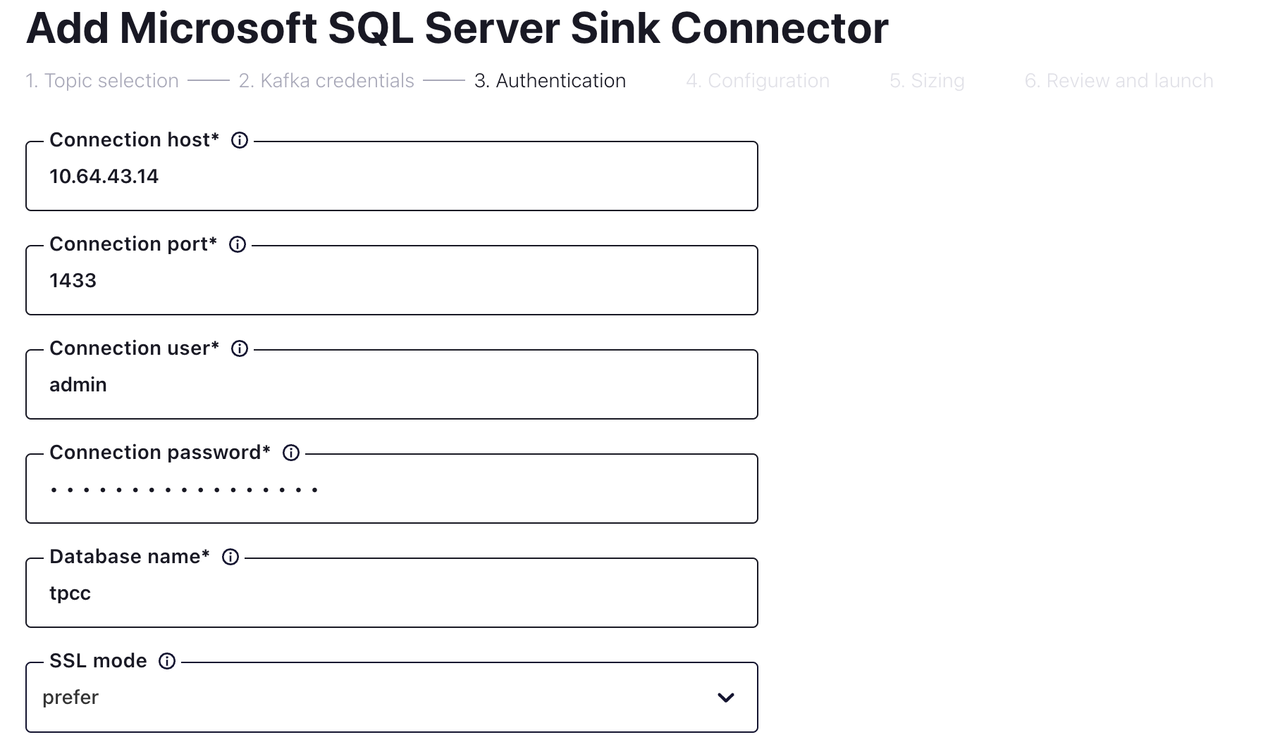
在填写 SQL Server 的连接和认证信息后,进入下一页面。
在 Configuration 界面,按下表进行配置:
配置完成后,选择 Continue,等待 Connector 状态变为 RUNNING,这个过程可能持续数分钟。
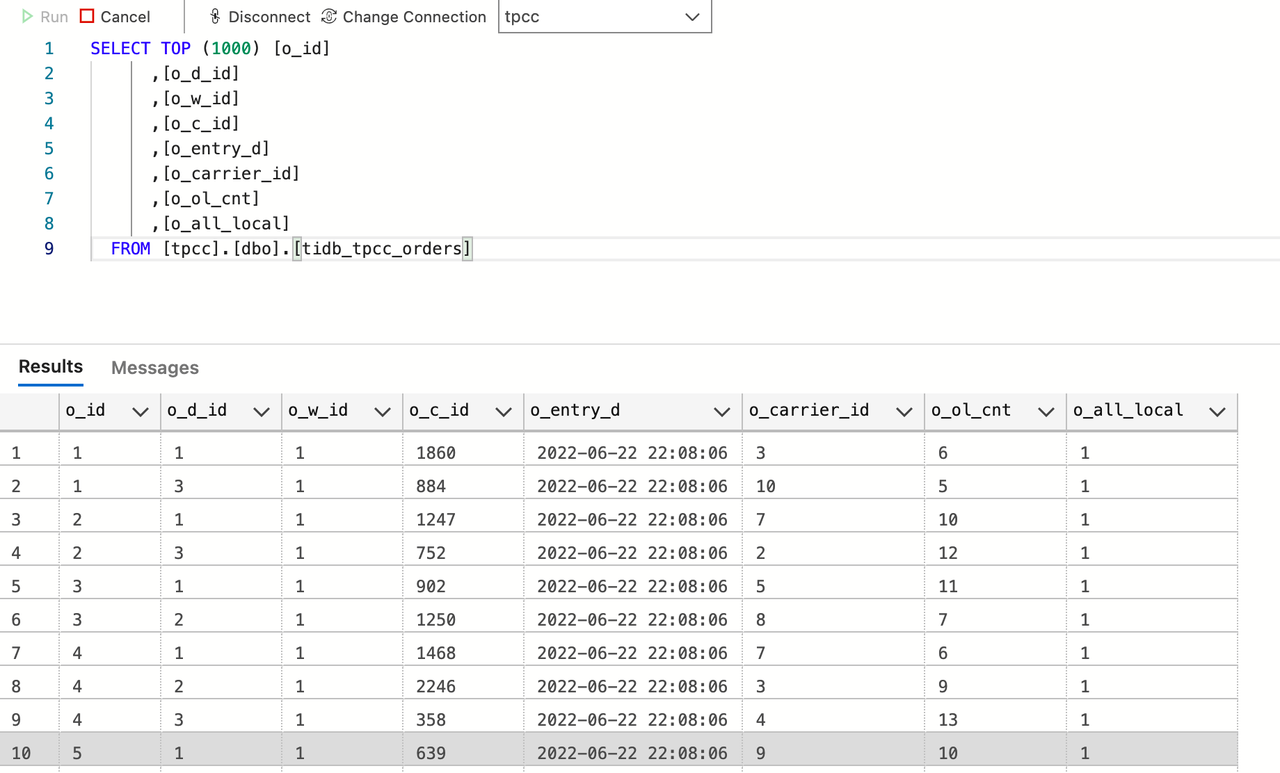
连接 SQL Server。观察 TiDB 中的增量数据实时同步到了 SQL Server,如上图。至此,就完成了 TiDB 与 SQL Server 的数据集成。