TiFlash MinTSO 调度器
TiFlash MinTSO 调度器是 TiFlash 中针对 MPP (Massively Parallel Processing) Task 的分布式调度器。本文介绍 TiFlash MinTSO 调度器的实现原理。
背景
在处理 MPP 查询时,TiDB 会将查询拆分成一个或多个 MPP Task,并将这些 MPP Task 发送给对应的 TiFlash 节点进行编译与执行。对于每个 MPP Task,TiFlash 都需要使用若干个线程来执行,具体线程数取决于 MPP Task 的复杂度以及 TiFlash 并发参数的设置。
在高并发场景中,TiFlash 节点会同时接收到多个 MPP Task,如果不对 MPP Task 的执行进行控制,TiFlash 需要向系统申请的线程数会随着 MPP Task 数量的增加而线性增加。过多的线程一方面会影响 TiFlash 的执行效率,另一方面由于操作系统本身支持的线程数有限,当 TiFlash 申请的线程数超过操作系统的限制时,TiFlash 就会遇到无法申请线程的错误。
为了提升 TiFlash 在高并发场景下的处理能力,需要在 TiFlash 中引入一个 MPP Task 调度器。
实现原理
如背景所述,TiFlash Task 调度器引入的初衷是控制 MPP 查询运行时使用的线程数。一种简单的调度策略是指定 TiFlash 可以申请的最大线程数。对于每个 MPP Task,调度器根据当前系统已经使用的线程数以及该 MPP Task 预期使用的线程数,决定该 MPP Task 是否能够被调度:
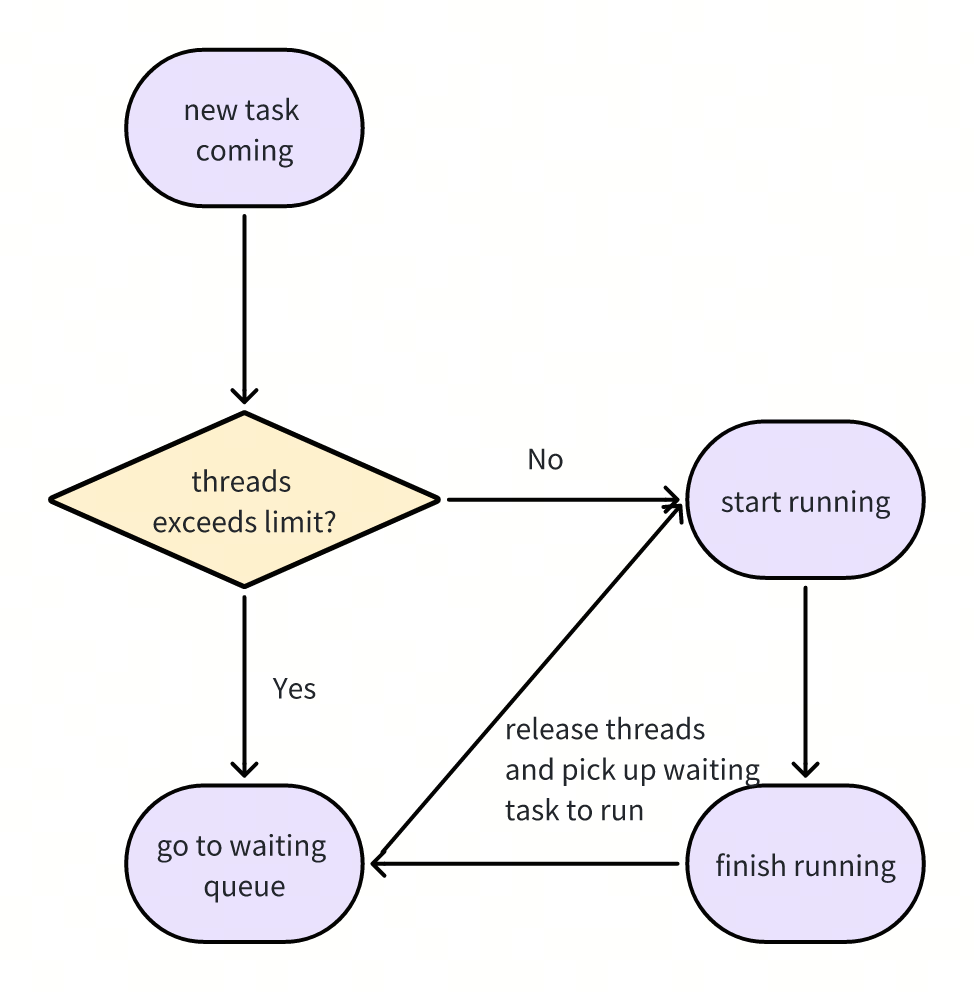
尽管上述调度策略能有效控制系统的线程数,但是 MPP Task 并不是一个最小的独立执行单元,不同 MPP Task 之间会有依赖关系:
EXPLAIN SELECT count(*) FROM t0 a JOIN t0 b ON a.id = b.id;
+--------------------------------------------+----------+--------------+---------------+----------------------------------------------------------+
| id | estRows | task | access object | operator info |
+--------------------------------------------+----------+--------------+---------------+----------------------------------------------------------+
| HashAgg_44 | 1.00 | root | | funcs:count(Column#8)->Column#7 |
| └─TableReader_46 | 1.00 | root | | MppVersion: 2, data:ExchangeSender_45 |
| └─ExchangeSender_45 | 1.00 | mpp[tiflash] | | ExchangeType: PassThrough |
| └─HashAgg_13 | 1.00 | mpp[tiflash] | | funcs:count(1)->Column#8 |
| └─Projection_43 | 12487.50 | mpp[tiflash] | | test.t0.id |
| └─HashJoin_42 | 12487.50 | mpp[tiflash] | | inner join, equal:[eq(test.t0.id, test.t0.id)] |
| ├─ExchangeReceiver_22(Build) | 9990.00 | mpp[tiflash] | | |
| │ └─ExchangeSender_21 | 9990.00 | mpp[tiflash] | | ExchangeType: Broadcast, Compression: FAST |
| │ └─Selection_20 | 9990.00 | mpp[tiflash] | | not(isnull(test.t0.id)) |
| │ └─TableFullScan_19 | 10000.00 | mpp[tiflash] | table:a | pushed down filter:empty, keep order:false, stats:pseudo |
| └─Selection_24(Probe) | 9990.00 | mpp[tiflash] | | not(isnull(test.t0.id)) |
| └─TableFullScan_23 | 10000.00 | mpp[tiflash] | table:b | pushed down filter:empty, keep order:false, stats:pseudo |
+--------------------------------------------+----------+--------------+---------------+----------------------------------------------------------+
例如,以上查询会在每个 TiFlash 节点中生成 2 个 MPP Task,其中执行器 ExchangeSender_45 所在的 MPP Task 依赖于 ExchangeSender_21 所在的 MPP Task。在该查询高并发的情况下,如果调度器调度了每个查询中 ExchangeSender_45 所在的 MPP Task,系统就会进入死锁状态。
为了避免系统陷入死锁状态,TiFlash 引入了以下两层线程的限制:
- thread_soft_limit:主要用来限制系统使用的线程数。对于特定的 MPP Task,为了避免死锁,可以打破该限制。
- thread_hard_limit:主要为了保护系统,一旦系统使用的线程数超过 hard limit,TiFlash 会通过报错来避免系统陷入死锁状态。
使用 soft limit 和 hard limit 避免死锁的原理是:通过 soft limit 限制所有查询使用的线程资源总量,在充分利用资源的基础上,避免线程资源耗尽。通过 hard limit 确保在任何情况下,系统中至少存在一个查询可以突破 soft limit 的限制,继续获取线程资源并运行,避免死锁。只要线程数不超过 hard limit,系统中就必定存在一个查询,该查询所有的 MPP Task 都可以正常执行,这样系统就不会出现死锁。
MinTSO 调度器的目标是在控制系统线程数的同时,确保系统中始终有且只有一个特殊的查询,其所有的 MPP Task 都可以被调度。MinTSO 调度器是一个完全分布式的调度器,每个 TiFlash 节点仅根据自身信息对 MPP Task 进行调度,因此,所有 TiFlash 节点的 MinTSO 调度器需要识别出同一个“特殊”查询。在 TiDB 中,每个查询都会带有一个读的时间戳 (start_ts),MinTSO 调度器定义“特殊”查询的标准为当前 TiFlash 节点上 start_ts 最小的查询。根据全局最小一定是局部最小的原理,所有的 TiFlash 选出的“特殊”查询必然是同一个,称为 MinTSO 查询。MinTSO 调度器的调度流程如下:
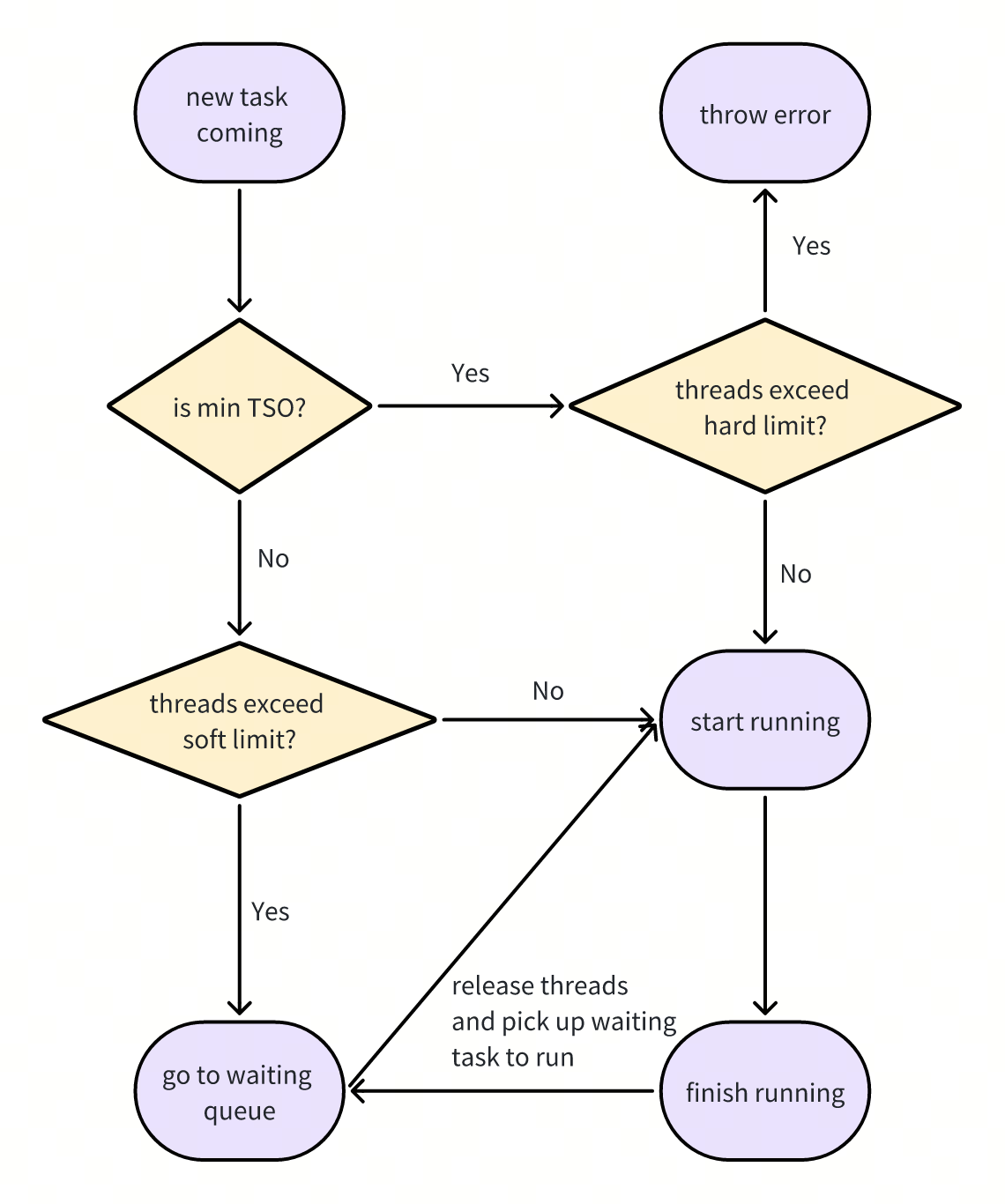
通过引入 soft limit 与 hard limit,MinTSO 调度器在控制系统线程数的同时,有效地避免了系统死锁。不过对于高并发场景,可能会出现大多数查询都只有部分 MPP Task 被调度的情况。只有部分 MPP Task 被调度的查询无法正常执行,从而导致系统执行效率低下。为了避免这种情况,TiFlash 在查询层面为 MinTSO 调度器引入了一个限制,即 active_set_soft_limit,该限制要求系统最多只有 active_set_soft_limit 个查询的 MPP Task 可以参与调度;对于其它的查询,其 MPP Task 不参与调度,只有等当前查询结束之后,新的查询才能参与调度。该限制只是一个 soft limit,因为对于 MinTSO 查询来说,其所有 MPP Task 在系统线程数不超过 hard limit 时都可以直接被调度。
另请参阅
- TiFlash 配置参数:了解 MinTSO 调度器的相关配置。