TiDB 性能优化概述
本文介绍性能优化的基本概念,比如用户响应时间、吞吐和数据库时间,以及性能优化的通用流程。
用户响应时间和数据库时间
用户响应时间
用户响应时间是指应用系统为用户返回请求结果所消耗的时间。一个典型的用户请求的处理时序图如下,包含了用户和应用系统的网络延迟、应用的处理时间、应用和数据库的交互时的网络延迟和数据库的服务时间等。用户响应时间受到请求链路上各个子系统的影响,比如网络延迟和带宽、系统并发用户数和请求类型、服务器 CPU 和 IO 资源使用率等。要对整个系统进行有效的优化,你需要先定位用户响应时间的瓶颈。
你可以通过以下公式计算指定时间范围 (ΔT) 内总的用户响应时间:
ΔT 时间内总的用户响应时间 = 平均 TPS (Transactions Per Second) x 用户平均响应时间 x ΔT。
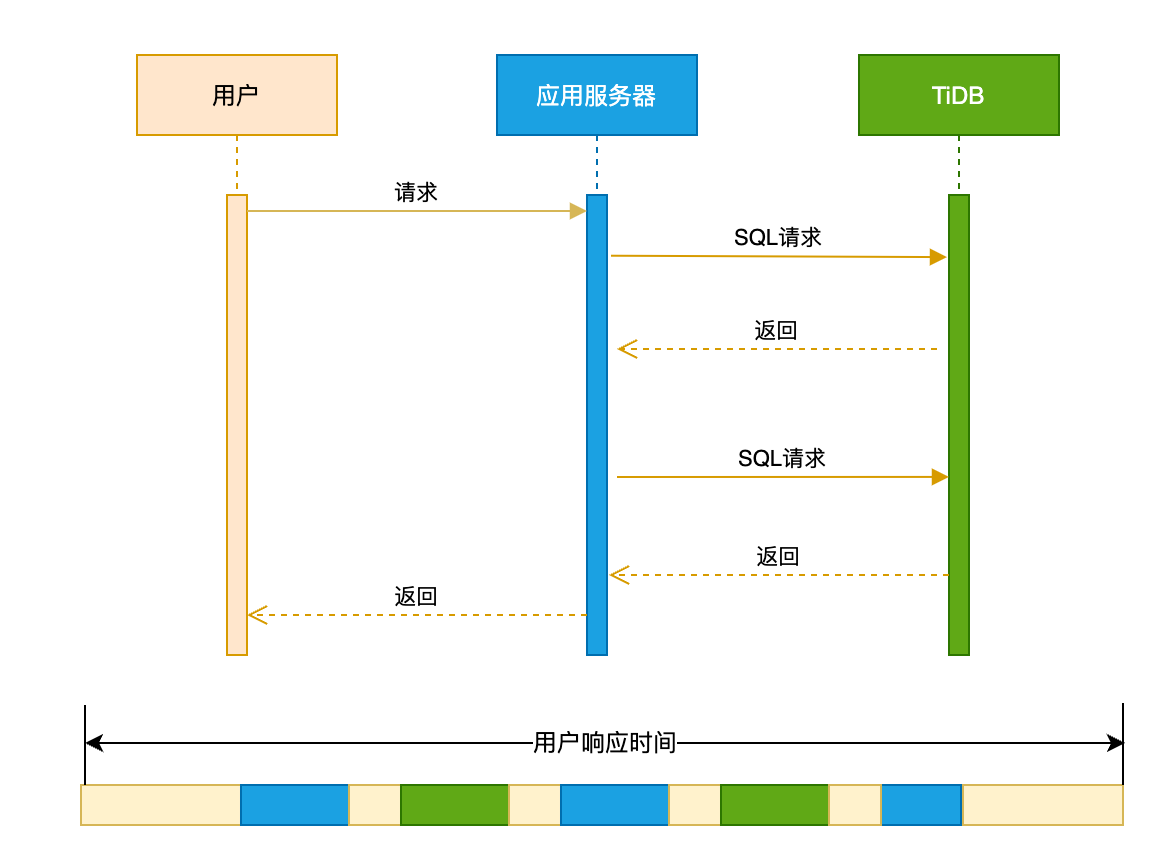
数据库时间
数据库时间是指数据库系统提供服务的时间,ΔT 时间内的数据库时间为数据库并发处理所有应用请求的时间总和。
你可以通过以下任一方式计算数据库时间:
- 方式一: 通过 QPS 乘以平均 query 延迟乘以 ΔT,即
DB Time in ΔT = QPS × avg latency × ΔT - 方式二: 通过平均活跃会话数乘以 ΔT,即
DB Time in ΔT = avg active connections × ΔT - 方式三: 通过 TiDB 内部的 Prometheus 指标 TiDB_server_handle_query_duration_seconds_sum 计算,即
ΔT DB Time = rate(TiDB_server_handle_query_duration_seconds_sum) × ΔT
用户响应时间和系统吞吐的关系
用户响应时间包含完成用户请求的服务时间、排队时间和并发等待时间,即:
User Response time = Service time + Queuing delay + Coherency delay
- Service Time(完成用户请求的服务时间):系统处理请求时需要消耗某种资源的时间,比如数据库完成一次 SQL 请求需要消耗的 CPU 时间。
- Queuing delay(排队延迟时间):系统处理请求时为了等待某种资源的服务,在队列中等待调度的时间。
- Coherency delay(并发等待延迟):系统处理请求时为了访问共享资源,需要和其他并发的任务进行通信和协作的时间。
系统吞吐指系统每秒完成的请求数量。用户响应时间和吞吐通常是反比倒数的关系。随着吞吐的上升,系统资源利用率上升,请求服务的排队延迟会随之上升,当资源利用率超过某个拐点,排队延迟会急剧上升。
例如,对于运行 OLTP 负载的数据库系统,当 CPU 利用率超过 65% 之后,CPU 的排队调度延迟会明显上升。因为系统的并发请求不是完全独立的,请求之间存在共享资源的协同和争用,比如不同的数据库请求可能对同样的数据有互斥的加锁操作。当资源利用率上升时,排队和调度延迟上升,这将导致持有的共享资源无法及时释放,反过来延长了其他任务对共享资源的等待时间。
性能优化流程
性能优化流程包含以下 6 个步骤:
- 定义优化目标
- 建立性能基线
- 定位用户响应时间的瓶颈
- 提出优化方案,预估每种方案的收益、风险和成本
- 实施优化
- 评估优化结果
一个性能优化项目,经常需要对步骤 2 到 6 进行多次循环,才能达到优化的目标。
第 1 步:定义优化目标
不同类型系统优化目标不同。例如,对于一个金融核心的 OLTP 系统,优化目标可能是降低交易的长尾延迟;对于一个财务结算系统,优化目标可能是更充分利用硬件资源,缩短批量结算任务时间。
一个好的优化目标应该是容易量化的,比如:
- 好的优化目标:”业务高峰期上午 9 点到 10 点,转账交易的 p99 延迟需要小于 200 毫秒“
- 差的优化目标:”系统太慢了没有响应,需要优化“
定义一个清晰的优化目标有助于指导后续的性能优化工作。
第 2 步:建立性能基线
为了高效地进行性能优化,你需要采集当前的性能数据以建立性能基线。需要采集的性能数据通常包含以下内容:
用户响应时间的平均值和长尾值、应用系统的吞吐
数据库时间、Query 延迟和 QPS 等数据库性能数据。
TiDB 针对不同维度的性能数据进行了完善的测量和存储,例如慢日志、Top SQL、持续性能分析功能和流量可视化等。此外,你还可以对存储在 Prometheus 中的时序指标数据进行历史回溯和对比。
资源使用率,包含 CPU、IO 和网络等资源
配置信息,比如应用系统、数据库和操作系统的配置
第 3 步:定位用户响应时间的瓶颈
基于性能基线的数据,定位或者推测用户响应时间的瓶颈。
现实中的应用程序往往没有对用户请求的链路进行完整的测量和记录,因此你无法通过应用程序对用户响应时间进行自上而下有效的分解。
与之相反的是,数据库内部对于 query 延迟和吞吐等性能指标记录非常完善。基于数据库时间,你可以判断用户响应时间的瓶颈是否在数据库中。
- 如果瓶颈不在数据库中,需要借助数据库外部搜集的资源利用率,或者对应用程序进行 Profile,以确定数据库外部的瓶颈。常见场景包括应用程序或者代理服务器资源不足,应用程序存在串行点无法充分利用硬件资源等。
- 如果瓶颈存在数据库中,你可以通过数据库完善的调优工具进行数据库内部性能分析和诊断。常见场景包括存在慢 SQL、应用程序使用数据库的方式不合理、数据库存在读写热点等。
具体的分析诊断方法和工具,请参考性能优化方法。
第 4 步:提出优化方案,评估每种方案的收益、风险和成本
通过性能分析确定系统瓶颈点之后,根据实际情况提出低成本、低风险、并能获得最大的收益的优化方案。
根据 阿姆达尔定律,性能优化的最大收益,取决于优化的部分在整个系统的占比。因此,你需要根据性能数据,确认系统瓶颈和相应的占比,预估瓶颈解决或者优化之后的收益。
需要注意的是,即使某个方案针对最大瓶颈点的优化潜在收益最大,也需要同时评估该方案的风险和成本。例如:
- 对于资源过载的系统,最直接的优化方案是扩容,但是实际中可能因为扩容方案成本太高而无法被采纳。
- 当某个业务模块里的一个慢 SQL 导致整个模块的响应时间很慢时,升级到数据库新版本的方案可以解决这个慢 SQL 问题,但是同时可能影响原来没有问题的模块,因此该方案可能存在潜在的高风险。一个低风险的方案是不升级数据库版本,直接改写现有慢 SQL,在当前数据库版本中解决该问题。
第 5 步:实施优化
综合考量收益、风险和成本,选定一种或者多种优化方案进行实施,并对生产系统的变更进行周全的准备和详细的记录。
为了降低风险和验证优化方案的收益,建议在测试环境和准生产环境对变更的内容进行验证和完整的回归。例如,针对一个查询业务的慢 SQL,如果选定的优化方案是新建索引优化查询的访问路径,你需要确保新的索引不会在现有的数据插入业务中引入明显的写入热点,导致其他业务变慢。
第 6 步:评估优化结果
实施优化之后,需要评估优化结果。
- 如果达到优化目标,整个优化项目顺利完成。
- 如果未达到优化目标,你需要重复步骤 2 到 6,直到达到优化目标。
达到优化目标之后,为了应对业务的增长,你可能还需要进一步做好系统的容量规划。