SHOW TABLE REGIONS
SHOW TABLE REGIONS 语句用于显示 TiDB 中某个表的 Region 信息。
语法
SHOW TABLE [table_name] REGIONS [WhereClauseOptional];
SHOW TABLE [table_name] INDEX [index_name] REGIONS [WhereClauseOptional];
语法图
ShowTableRegionStmt:

TableName:
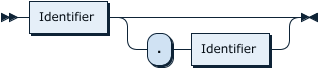
PartitionNameListOpt:
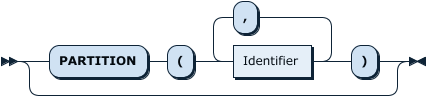
WhereClauseOptional:
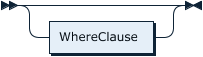
WhereClause:

SHOW TABLE REGIONS 会返回如下列:
REGION_ID:Region 的 ID。START_KEY:Region 的 Start key。END_KEY:Region 的 End key。LEADER_ID:Region 的 Leader ID。LEADER_STORE_ID:Region leader 所在的 store (TiKV) ID。PEERS:Region 所有副本的 ID。SCATTERING:Region 是否正在调度中。1 表示正在调度。WRITTEN_BYTES:估算的 Region 在 1 个心跳周期内的写入数据量大小,单位是 byte。READ_BYTES:估算的 Region 在 1 个心跳周期内的读数据量大小,单位是 byte。APPROXIMATE_SIZE(MB):估算的 Region 的数据量大小,单位是 MB。APPROXIMATE_KEYS:估算的 Region 内 Key 的个数。
示例
创建一个示例表,并在若干 Region 中填充足够的数据量:
CREATE TABLE t1 (
id INT NOT NULL PRIMARY KEY auto_increment,
b INT NOT NULL,
pad1 VARBINARY(1024),
pad2 VARBINARY(1024),
pad3 VARBINARY(1024)
);
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM dual;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
INSERT INTO t1 SELECT NULL, FLOOR(RAND()*1000), RANDOM_BYTES(1024), RANDOM_BYTES(1024), RANDOM_BYTES(1024) FROM t1 a JOIN t1 b JOIN t1 c LIMIT 10000;
SELECT SLEEP(5);
SHOW TABLE t1 REGIONS;
结果显示示例表被切分成多个 Regions。REGION_ID、START_KEY 和 END_KEY 可能不完全匹配:
SHOW TABLE t1 REGIONS;
+-----------+--------------+--------------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+--------------+--------------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| 94 | t_75_ | t_75_r_31717 | 95 | 1 | 95 | 0 | 0 | 0 | 112 | 207465 |
| 96 | t_75_r_31717 | t_75_r_63434 | 97 | 1 | 97 | 0 | 0 | 0 | 97 | 0 |
| 2 | t_75_r_63434 | | 3 | 1 | 3 | 0 | 269323514 | 66346110 | 245 | 162020 |
+-----------+--------------+--------------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
3 rows in set (0.00 sec)
解释:
上面 START_KEY 列的值 t_75_r_31717 和 END_KEY 列的值 t_75_r_63434 表示主键在 31717 和 63434 之间的数据存储在该 Region 中。t_75_ 是前缀,表示这是表格 (t) 的 Region,75 是表格的内部 ID。若 START_KEY 或 END_KEY 的一对键值为空,分别表示负无穷大或正无穷大。
TiDB 会根据需要自动重新平衡 Regions。建议使用 SPLIT TABLE REGION 语句手动进行平衡:
SPLIT TABLE t1 BETWEEN (31717) AND (63434) REGIONS 2;
+--------------------+----------------------+
| TOTAL_SPLIT_REGION | SCATTER_FINISH_RATIO |
+--------------------+----------------------+
| 1 | 1 |
+--------------------+----------------------+
1 row in set (42.34 sec)
SHOW TABLE t1 REGIONS;
+-----------+--------------+--------------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+--------------+--------------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
| 94 | t_75_ | t_75_r_31717 | 95 | 1 | 95 | 0 | 0 | 0 | 112 | 207465 |
| 98 | t_75_r_31717 | t_75_r_47575 | 99 | 1 | 99 | 0 | 1325 | 0 | 53 | 12052 |
| 96 | t_75_r_47575 | t_75_r_63434 | 97 | 1 | 97 | 0 | 1526 | 0 | 48 | 0 |
| 2 | t_75_r_63434 | | 3 | 1 | 3 | 0 | 0 | 55752049 | 60 | 0 |
+-----------+--------------+--------------+-----------+-----------------+-------+------------+---------------+------------+----------------------+------------------+
4 rows in set (0.00 sec)
上面的输出结果显示 Region 96 被切分,并创建一个新的 Region 98。切分操作不会影响表中的其他 Region。输出结果同样证实:
TOTAL_SPLIT_REGION表示新切的 Region 数量。以上示例新切了 1 个 Region。SCATTER_FINISH_RATIO表示新切的 Region 的打散成功率,1.0 表示都已经打散了。
更详细的示例如下:
show table t regions;
+-----------+--------------+--------------+-----------+-----------------+---------------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+--------------+--------------+-----------+-----------------+---------------+------------+---------------+------------+----------------------+------------------+
| 102 | t_43_r | t_43_r_20000 | 118 | 7 | 105, 118, 119 | 0 | 0 | 0 | 1 | 0 |
| 106 | t_43_r_20000 | t_43_r_40000 | 120 | 7 | 107, 108, 120 | 0 | 23 | 0 | 1 | 0 |
| 110 | t_43_r_40000 | t_43_r_60000 | 112 | 9 | 112, 113, 121 | 0 | 0 | 0 | 1 | 0 |
| 114 | t_43_r_60000 | t_43_r_80000 | 122 | 7 | 115, 122, 123 | 0 | 35 | 0 | 1 | 0 |
| 3 | t_43_r_80000 | | 93 | 8 | 5, 73, 93 | 0 | 0 | 0 | 1 | 0 |
| 98 | t_43_ | t_43_r | 99 | 1 | 99, 100, 101 | 0 | 0 | 0 | 1 | 0 |
+-----------+--------------+--------------+-----------+-----------------+---------------+------------+---------------+------------+----------------------+------------------+
6 rows in set
解释:
- Region 102 的
START_KEY和END_KEY中,t_43是表数据前缀和 table ID,_r是表 t record 数据的前缀,索引数据的前缀是_i,所以 Region 102 的START_KEY和END_KEY表示用来存储[-inf, 20000)之前的 record 数据。其他 Region (106, 110, 114, 3) 的存储范围依次类推。 - Region 98 用来存储索引数据存储。表 t 索引数据的起始 key 是
t_43_i,处于 Region 98 的存储范围内。
查看表 t 在 store 1 上的 region,用 WHERE 条件过滤。
show table t regions where leader_store_id =1;
+-----------+-----------+---------+-----------+-----------------+--------------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+-----------+---------+-----------+-----------------+--------------+------------+---------------+------------+----------------------+------------------+
| 98 | t_43_ | t_43_r | 99 | 1 | 99, 100, 101 | 0 | 0 | 0 | 1 | 0 |
+-----------+-----------+---------+-----------+-----------------+--------------+------------+---------------+------------+----------------------+------------------+
用 SPLIT TABLE REGION 语法切分索引数据的 Region,下面语法把表 t 的索引 name 数据在 [a,z] 范围内切分成 2 个 Region。
split table t index name between ("a") and ("z") regions 2;
+--------------------+----------------------+
| TOTAL_SPLIT_REGION | SCATTER_FINISH_RATIO |
+--------------------+----------------------+
| 2 | 1.0 |
+--------------------+----------------------+
1 row in set
现在表 t 一共有 7 个 Region,其中 5 个 Region (102, 106, 110, 114, 3) 用来存表 t 的 record 数据,另外 2 个 Region (135, 98) 用来存 name 索引的数据。
show table t regions;
+-----------+-----------------------------+-----------------------------+-----------+-----------------+---------------+------------+---------------+------------+----------------------+------------------+
| REGION_ID | START_KEY | END_KEY | LEADER_ID | LEADER_STORE_ID | PEERS | SCATTERING | WRITTEN_BYTES | READ_BYTES | APPROXIMATE_SIZE(MB) | APPROXIMATE_KEYS |
+-----------+-----------------------------+-----------------------------+-----------+-----------------+---------------+------------+---------------+------------+----------------------+------------------+
| 102 | t_43_r | t_43_r_20000 | 118 | 7 | 105, 118, 119 | 0 | 0 | 0 | 1 | 0 |
| 106 | t_43_r_20000 | t_43_r_40000 | 120 | 7 | 108, 120, 126 | 0 | 0 | 0 | 1 | 0 |
| 110 | t_43_r_40000 | t_43_r_60000 | 112 | 9 | 112, 113, 121 | 0 | 0 | 0 | 1 | 0 |
| 114 | t_43_r_60000 | t_43_r_80000 | 122 | 7 | 115, 122, 123 | 0 | 35 | 0 | 1 | 0 |
| 3 | t_43_r_80000 | | 93 | 8 | 73, 93, 128 | 0 | 0 | 0 | 1 | 0 |
| 135 | t_43_i_1_ | t_43_i_1_016d80000000000000 | 139 | 2 | 138, 139, 140 | 0 | 35 | 0 | 1 | 0 |
| 98 | t_43_i_1_016d80000000000000 | t_43_r | 99 | 1 | 99, 100, 101 | 0 | 0 | 0 | 1 | 0 |
+-----------+-----------------------------+-----------------------------+-----------+-----------------+---------------+------------+---------------+------------+----------------------+------------------+
7 rows in set
MySQL 兼容性
SHOW TABLE REGIONS 语句是 TiDB 对 MySQL 语法的扩展。