从小数据量分库分表 MySQL 合并迁移数据到 TiDB
如果你想把上游多个 MySQL 数据库实例合并迁移到下游的同一个 TiDB 数据库中,且数据量较小,你可以使用 DM 工具进行分库分表的合并迁移。本文所称“小数据量”通常指 TiB 级别以下。本文举例介绍了合并迁移的操作步骤、注意事项、故障排查等。本文档适用于:
- TiB 级以内的分库分表数据合并迁移
- 基于 MySQL binlog 的增量、持续分库分表合并迁移
若要迁移分表总和 1 TiB 以上的数据,则 DM 工具耗时较长,可参考从大数据量分库分表 MySQL 合并迁移数据到 TiDB。
本文以一个简单的场景为例,示例中的两个数据源 MySQL 实例的分库和分表数据迁移至下游 TiDB 集群。示意图如下。
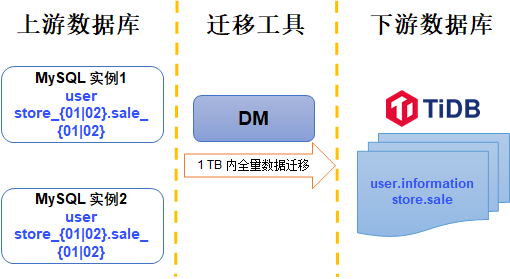
数据源 MySQL 实例 1 和 实例 2 均使用以下表结构,计划将 store_01 和 store_02 中 sale 开头的表合并导入下游 store.sale 表
迁移目标库的结构如下:
前提条件
分表数据冲突检查
迁移中如果涉及合库合表,来自多张分表的数据可能引发主键或唯一索引的数据冲突。因此在迁移之前,需要检查各分表数据的业务特点。详情请参考跨分表数据在主键或唯一索引冲突处理
在本示例中:sale_01 和 sale_02 具有相同的表结构如下:
CREATE TABLE `sale_01` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`sid` bigint(20) NOT NULL,
`pid` bigint(20) NOT NULL,
`comment` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `sid` (`sid`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
其中id列为主键,sid列为分片键,具有全局唯一性。id列具有自增属性,多个分表范围重复会引发数据冲突。sid可以保证全局满足唯一索引,因此可以按照参考去掉自增主键的主键属性中介绍的操作绕过id列。在下游创建sale表时移除id列的唯一键属性
CREATE TABLE `sale` (
`id` bigint(20) NOT NULL,
`sid` bigint(20) NOT NULL,
`pid` bigint(20) NOT NULL,
`comment` varchar(255) DEFAULT NULL,
INDEX (`id`),
UNIQUE KEY `sid` (`sid`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
第 1 步: 创建数据源
新建source1.yaml文件, 写入以下内容:
# 唯一命名,不可重复。
source-id: "mysql-01"
# DM-worker 是否使用全局事务标识符 (GTID) 拉取 binlog。使用前提是上游 MySQL 已开启 GTID 模式。若上游存在主从自动切换,则必须使用 GTID 模式。
enable-gtid: true
from:
host: "${host}" # 例如:172.16.10.81
user: "root"
password: "${password}" # 支持但不推荐使用明文密码,建议使用 dmctl encrypt 对明文密码进行加密后使用
port: 3306
在终端中执行下面的命令,使用tiup dmctl将数据源配置加载到 DM 集群中:
tiup dmctl --master-addr ${advertise-addr} operate-source create source1.yaml
该命令中的参数描述如下:
重复以上操作直至所有数据源均添加完成。
第 2 步: 创建迁移任务
新建task1.yaml文件, 写入以下内容:
name: "shard_merge"
# 任务模式,可设为
# full:只进行全量数据迁移
# incremental: binlog 实时同步
# all: 全量 + binlog 迁移
task-mode: all
# 分库分表合并任务则需要配置 shard-mode。默认使用悲观协调模式 "pessimistic",在深入了解乐观协调模式的原理和使用限制后,也可以设置为乐观协调模式 "optimistic"
# 详细信息可参考:https://docs.pingcap.com/zh/tidb/dev/feature-shard-merge/
shard-mode: "pessimistic"
meta-schema: "dm_meta" # 将在下游数据库创建 schema 用于存放元数据
ignore-checking-items: ["auto_increment_ID"] # 本示例中上游存在自增主键,因此需要忽略掉该检查项
target-database:
host: "${host}" # 例如:192.168.0.1
port: 4000
user: "root"
password: "${password}" # 支持但不推荐使用明文密码,建议使用 dmctl encrypt 对明文密码进行加密后使用
mysql-instances:
-
source-id: "mysql-01" # 数据源 ID,即 source1.yaml 中的 source-id
route-rules: ["sale-route-rule"] # 应用于该数据源的 table route 规则
filter-rules: ["store-filter-rule", "sale-filter-rule"] # 应用于该数据源的 binlog event filter 规则
block-allow-list: "log-bak-ignored" # 应用于该数据源的 Block & Allow Lists 规则
-
source-id: "mysql-02"
route-rules: ["sale-route-rule"]
filter-rules: ["store-filter-rule", "sale-filter-rule"]
block-allow-list: "log-bak-ignored"
# 分表合并配置
routes:
sale-route-rule:
schema-pattern: "store_*"
table-pattern: "sale_*"
target-schema: "store"
target-table: "sale"
# 过滤部分 DDL 事件
filters:
sale-filter-rule:
schema-pattern: "store_*"
table-pattern: "sale_*"
events: ["truncate table", "drop table", "delete"]
action: Ignore
store-filter-rule:
schema-pattern: "store_*"
events: ["drop database"]
action: Ignore
# 黑白名单
block-allow-list:
log-bak-ignored:
do-dbs: ["store_*"]
以上内容为执行迁移的最小任务配置。关于任务的更多配置项,可以参考DM 任务完整配置文件介绍
若想了解配置文件中routes,filters等更多用法,请参考:
第 3 步: 启动任务
在你启动数据迁移任务之前,建议使用check-task命令检查配置是否符合 DM 的配置要求,以降低后期报错的概率。
tiup dmctl --master-addr ${advertise-addr} check-task task.yaml
使用 tiup dmctl 执行以下命令启动数据迁移任务。
tiup dmctl --master-addr ${advertise-addr} start-task task.yaml
该命令中的参数描述如下:
如果任务启动失败,可根据返回结果的提示进行配置变更后执行 start-task task.yaml 命令重新启动任务。遇到问题请参考 故障及处理方法 以及 常见问题
第 4 步: 查看任务状态
如需了解 DM 集群中是否存在正在运行的迁移任务及任务状态等信息,可使用tiup dmctl执行query-status命令进行查询:
tiup dmctl --master-addr ${advertise-addr} query-status ${task-name}
关于查询结果的详细解读,请参考查询状态
第 5 步: 监控任务与查看日志(可选)
你可以通过 Grafana 或者日志查看迁移任务的历史状态以及各种内部运行指标。
通过 Grafana 查看
如果使用 TiUP 部署 DM 集群时,正确部署了 Prometheus、Alertmanager 与 Grafana,则使用部署时填写的 IP 及 端口进入 Grafana,选择 DM 的 dashboard 查看 DM 相关监控项。
通过日志查看
DM 在运行过程中,DM-worker, DM-master 及 dmctl 都会通过日志输出相关信息,其中包含迁移任务的相关信息。各组件的日志目录如下:
- DM-master 日志目录:通过 DM-master 进程参数
--log-file设置。如果使用 TiUP 部署 DM,则日志目录默认位于/dm-deploy/dm-master-8261/log/。 - DM-worker 日志目录:通过 DM-worker 进程参数
--log-file设置。如果使用 TiUP 部署 DM,则日志目录默认位于/dm-deploy/dm-worker-8262/log/。
- DM-master 日志目录:通过 DM-master 进程参数