TiDB TPC-H 性能对比测试报告 - v5.2 MPP 模式对比 Greenplum 6.15.0 以及 Apache Spark 3.1.1
测试概况
本次测试对比了 TiDB v5.2 MPP 模式下和主流分析引擎例如 Greenplum 和 Apache Spark 最新版在 TPC-H 100 下的性能表现。结果显示,TiDB v5.2 MPP 模式下相对这些方案有 2-3 倍的性能提升。
TiDB v5.0 中引入的 TiFlash 组件的 MPP 模式,在 v5.1 和 v5.2 中进行了功能优化,这大大幅增强了 TiDB HTAP 形态。本文的测试对象如下:
- TiDB v5.2 MPP 执行模式下的列式存储
- Greenplum 6.15.0
- Apache Spark 3.1.1 + Parquet
测试环境
硬件配置
- 节点数量:3
- CPU:Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz,40 核
- 内存:189 GB
- 磁盘:NVMe 3TB * 2
软件版本
| 服务类型 | 软件版本 |
|---|---|
| TiDB | 5.2 |
| Greenplum | 6.15.0 |
| Apache Spark | 3.1.1 |
配置参数
TiDB v5.2 配置
v5.2 的 TiDB 集群除以下配置项外均使用默认参数配置。所有 TPC-H 测试表均以 TiFlash 列存进行同步,无额外分区和索引。
在 TiFlash 的 users.toml 配置文件中进行如下配置:
[profiles.default]
max_memory_usage = 10000000000000
使用 SQL 语句设置以下会话变量:
set @@tidb_isolation_read_engines='tiflash';
set @@tidb_allow_mpp=1;
set @@tidb_mem_quota_query = 10 << 30;
Greenplum 配置
Greenplum 集群使用额外的一台 Master 节点部署(共四台),每台 Segment Server 部署 8 Segments(每个 NVMe SSD 各 4 个),总共 24 Segments。存储格式为 append-only / 列式存储,分区键为主键。
log_statement = all
gp_autostats_mode = none
statement_mem = 2048MB
gp_vmem_protect_limit = 16384
Apache Spark 配置
Apache Spark 测试使用 Apache Parquet 作为存储格式,数据存储在 HDFS 上。HDFS 为三节点,为每个节点指定两块 NVMe SSD 盘作为数据盘。通过 Standalone 方式启动 Spark 集群,使用 NVMe SSD 盘作为 spark.local.dir 本地目录以借助快速盘加速 Shuffle Spill 过程,无额外分区和索引。
--driver-memory 20G
--total-executor-cores 120
--executor-cores 5
--executor-memory 15G
测试结果
| Query ID | TiDB v5.2 | Greenplum 6.15.0 | Apache Spark 3.1.1 + Parquet |
|---|---|---|---|
| 1 | 8.08 | 64.1307 | 52.64 |
| 2 | 2.53 | 4.76612 | 11.83 |
| 3 | 4.84 | 15.62898 | 13.39 |
| 4 | 10.94 | 12.88318 | 8.54 |
| 5 | 12.27 | 23.35449 | 25.23 |
| 6 | 1.32 | 6.033 | 2.21 |
| 7 | 5.91 | 12.31266 | 25.45 |
| 8 | 6.71 | 11.82444 | 23.12 |
| 9 | 44.19 | 22.40144 | 35.2 |
| 10 | 7.13 | 12.51071 | 12.18 |
| 11 | 2.18 | 2.6221 | 10.99 |
| 12 | 2.88 | 7.97906 | 6.99 |
| 13 | 6.84 | 10.15873 | 12.26 |
| 14 | 1.69 | 4.79394 | 3.89 |
| 15 | 3.29 | 10.48785 | 9.82 |
| 16 | 5.04 | 4.64262 | 6.76 |
| 17 | 11.7 | 74.65243 | 44.65 |
| 18 | 12.87 | 64.87646 | 30.27 |
| 19 | 4.75 | 8.08625 | 4.7 |
| 20 | 8.89 | 15.47016 | 8.4 |
| 21 | 24.44 | 39.08594 | 34.83 |
| 22 | 1.23 | 7.67476 | 4.59 |
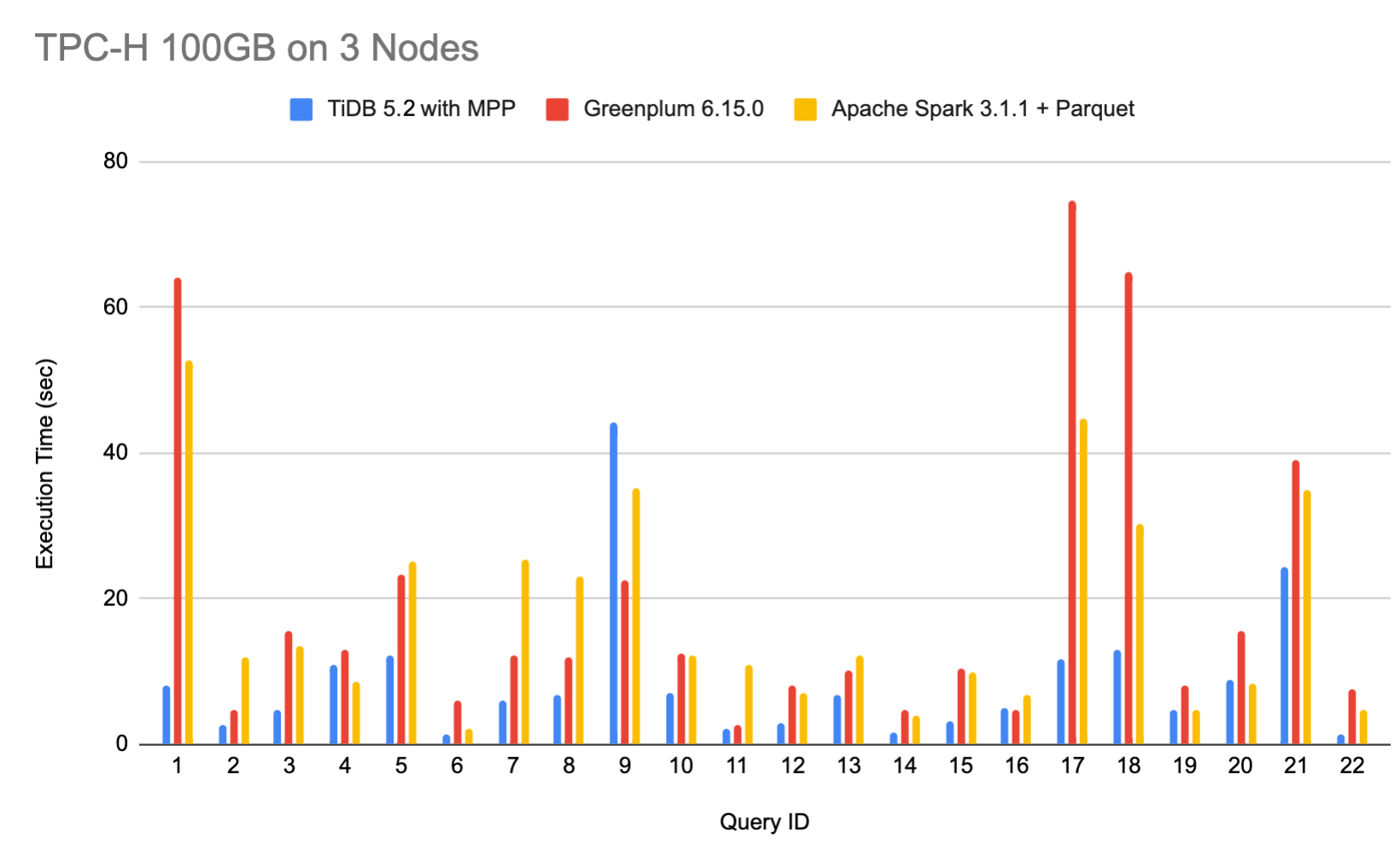
以上性能图中蓝色为 TiDB v5.2,红色为 Greenplum 6.15.0,黄色为 Apache Spark 3.1.1,纵坐标是查询的处理时间。纵坐标数值越低,表示 TPC-H 性能越好。