TiDB Dashboard 诊断报告
本文档主要介绍诊断报告的内容以及查看技巧,访问集群诊断和生成报告请参考诊断报告访问文档。
查看报告
诊断报告由以下几部分组成:
- 基本信息:包括生成报告的时间范围,集群的硬件信息,集群的拓扑版本信息。
- 诊断信息:显示自动诊断的结果。
- 负载信息:包括服务器,TIDB/PD/TiKV 相关的 CPU、内存等负载信息。
- 概览信息:包括 TiDB/PD/TiKV 的各个模块的耗时信息和错误信息。
- TiDB/PD/TiKV 监控信息:包括各个组件的监控信息。
- 配置信息:包括各个组件的配置信息。
报告中报表示例如下:

上图中,最上面蓝框内的 Total Time Consume 是报表名。下方红框内的内容是对该报表意义的解释,以及报表中各个字段的含义。
报表中小按钮图标的解释如下:
- i 图标:鼠标移动到 i 图标处会显示该行的说明注释。
- expand:点击 expand 会看到这项监控更加详细的信息。如是上图中
tidb_get_token的详细信息包括各个 TiDB 实例的延迟监控信息。 - fold:和 expand 相反,用于把监控的详细信息折叠起来。
所有监控基本上和 TiDB Grafna 监控面板上的监控内容相对应,发现某个模块异常后,可以在 TiDB Grafna 监控面板上查看更多详细的监控信息。
另外,报表中统计的 TOTAL_TIME 和 TOTAL_COUNT 由于是从 Prometheus 读取的监控数据,其统计会有一些计算上的精度误差。
以下介绍诊断报告的各部分内容。
基本信息
Report Time Range
Report Time Range 表显示生成报告的时间范围,包括开始时间和结束时间。

Cluster Hardware
Cluster Hardware 表显示集群中各服务器的硬件信息,包括 CPU、Memory、磁盘等信息。

上表中各个字段含义如下:
HOST:服务器的 IP 地址。INSTANCE:该服务器部署的实例数量,如pd * 1代表这台服务器部署了 1 个 PD 实例。如tidb * 2 pd * 1表示这台服务器部署了 2 个 TiDB 实例和 1 个 PD 实例。CPU_CORES:表示服务器 CPU 的核心数,物理核心/逻辑核心。MEMORY:表示服务器的内存大小,单位是 GB。DISK:表示服务器磁盘大小,单位是 GB。UPTIME:服务器的启动时间,单位是 DAY。
Cluster Info
Cluster Info 为集群拓扑信息。表中信息来自 TiDB 的 information_schema.cluster_info 系统表。

上表中各个字段含义如下:
TYPE:节点类型。INSTANCE:实例地址,为IP:PORT格式的字符串。STATUS_ADDRESS:HTTP API 的服务地址。VERSION:对应节点的语义版本号。GIT_HASH:编译节点版本时的 Git Commit Hash,用于识别两个节点是否是绝对一致的版本。START_TIME:对应节点的启动时间。UPTIME:对应节点已经运行的时间。
诊断信息
TiDB 内置自动诊断的结果,具体各字段含义以及介绍可以参考 information_schema.inspection_result 系统表的内容。
负载信息
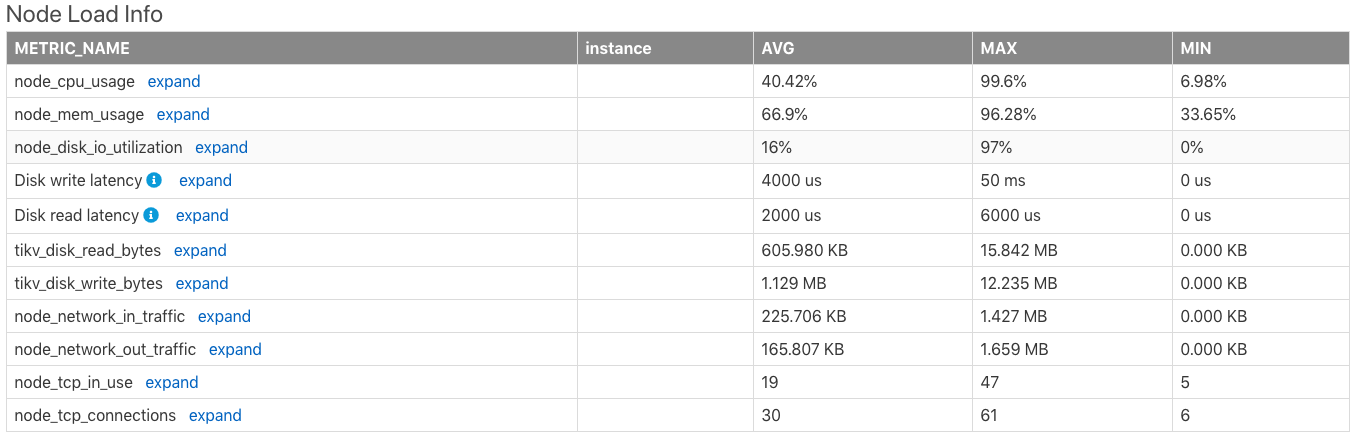
Node Load Info
Node Load Info 表显示服务器节点的负载信息,包括时间范围内,服务器以下指标的平均值 (AVG)、最大值 (MAX)、最小值 (MIN):
- CPU 使用率,最大值是 100%
- 内存使用率
- 磁盘 I/O 使用率
- 磁盘写延迟
- 磁盘读延迟
- 磁盘每秒的读取字节数
- 磁盘每秒的写入字节数
- 节点网络每分钟收到的字节数
- 节点网络每分钟发送的字节数
- 节点正在使用的 TCP 连接数
- 节点所有的 TCP 连接数
Instance CPU Usage
Instance CPU Usage 表显示各个 TiDB/PD/TiKV 进程的 CPU 使用率的平均值 (AVG),最大值 (MAX),最小值 (MIN),这里进程 CPU 使用率最大值是 100% * CPU 逻辑核心数。

Instance Memory Usage
Instance Memory Usage 表显示各个 TiDB/PD/TiKV 进程占用内存字节数的平均值 (AVG),最大值 (MAX),最小值 (MIN)。

TiKV Thread CPU Usage
TiKV Thread CPU Usage 表显示 TiKV 内部各个模块线程的 CPU 使用率的平均值 (AVG)、最大值 (MAX)、和最小值 (MIN)。这里进程 CPU 使用率最大值为 100% * 对应配置的线程数量。
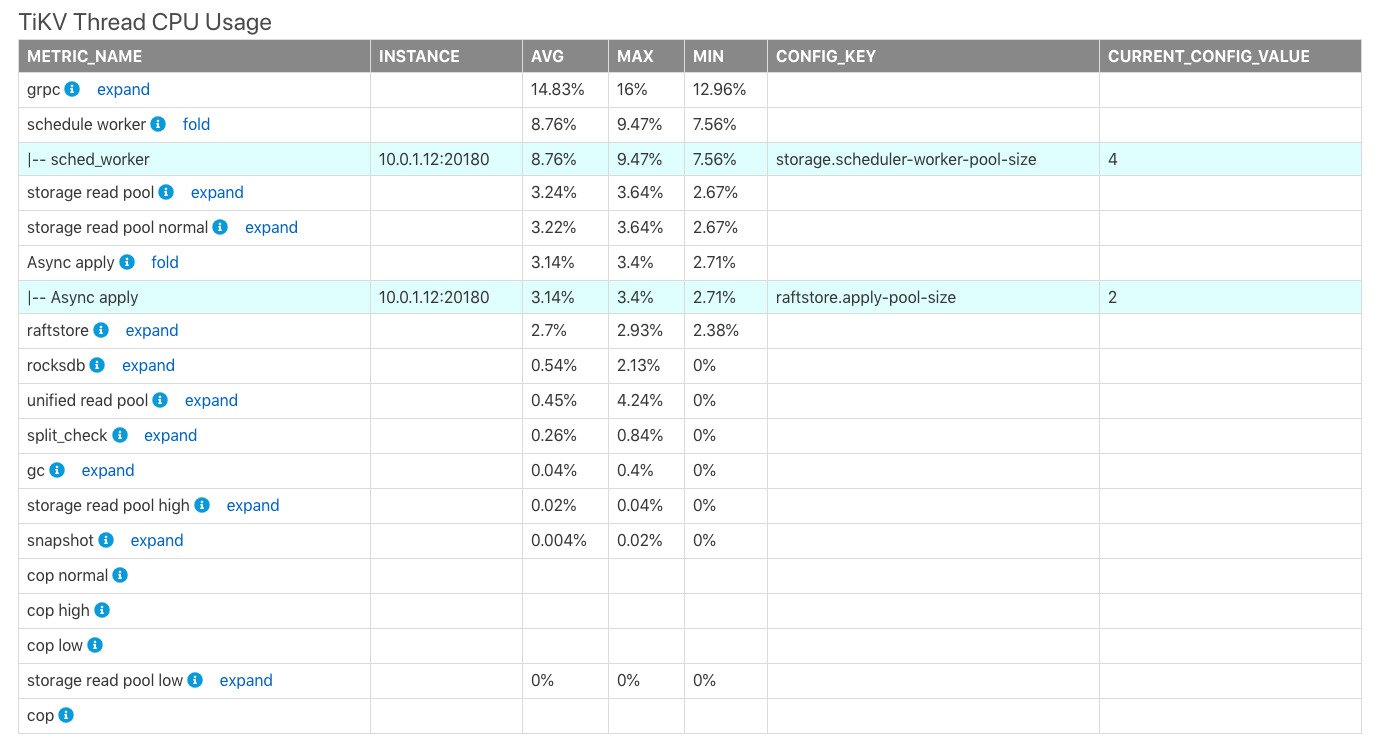
上表中的字段解释如下:
CONFIG_KEY:表示对应模块的相关线程数配置。CURRENT_CONFIG_VALUE:表示配置在生成报表时刻的当前值。
TiDB/PD Goroutines Count
TiDB/PD Goroutines Count 表显示 TiDB/PD goroutines 数量的平均值 (AVG),最大值 (MAX),和最小值 (MIN)。如果 goroutines 数量超过 2000,说明该进程并发太高,会对整体请求的延迟有影响。

概览信息
Time Consumed by Each Component
Time Consumed by Each Component 显示包括集群中 TiDB、PD、TiKV 各个模块的监控耗时以及各项耗时的占比。默认时间单位是秒。用户可以用该表快速定位哪些模块的耗时较多。
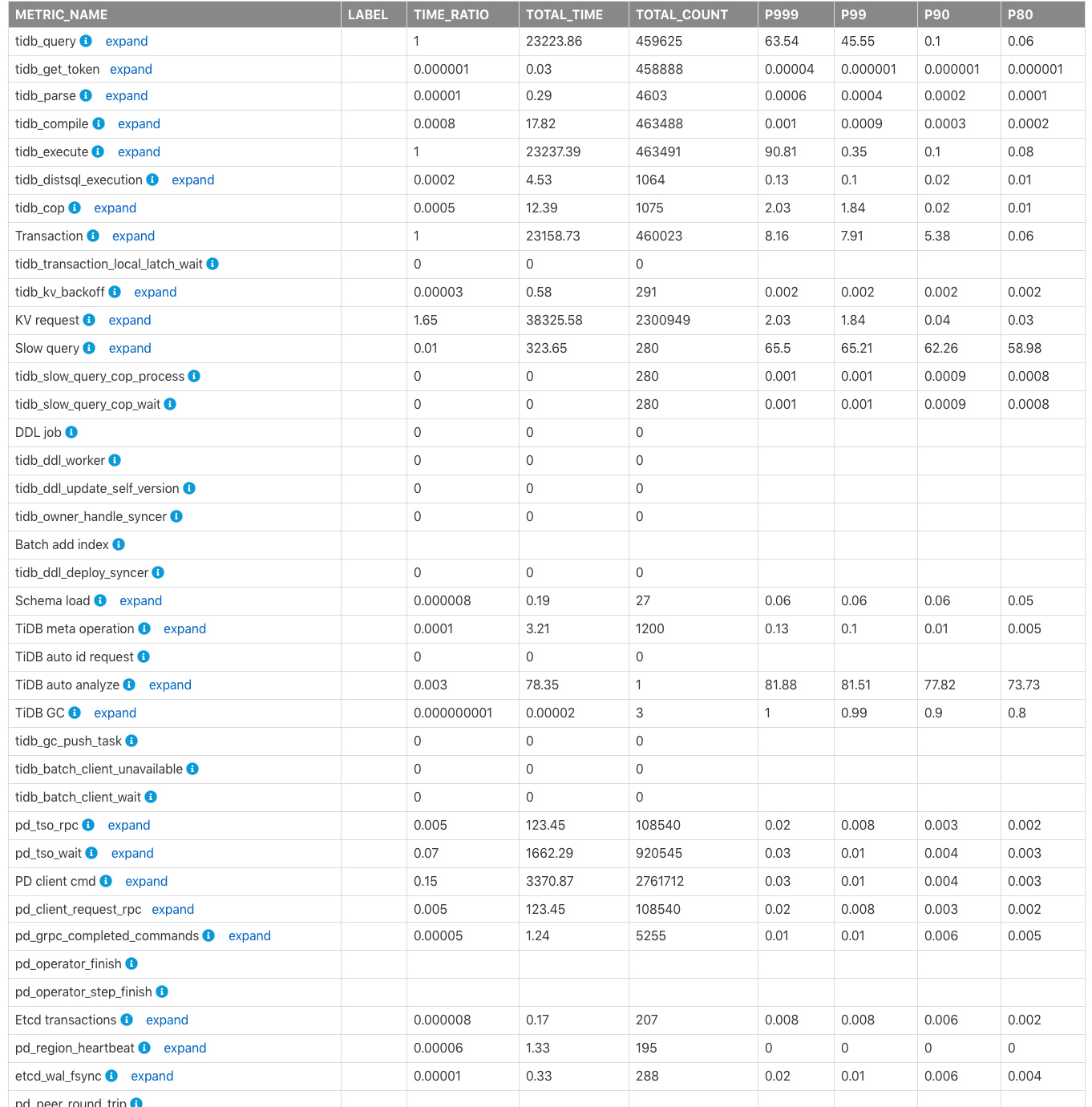
上表各列的字段含义如下:
METRIC_NAME:监控项的名称。Label:监控的 label 信息,点击 expand 后可以查看该项监控更加详细的各项 label 的监控信息。TIME_RATIO:该项为TIME_RATIO为1的监控行总时间与监控消耗的总时间的比例。如kv_request的总耗时占tidb_query总耗时的1.65 = 38325.58/23223.86。因为 KV 请求会并行执行,所以所有 KV 请求的总时间有可能超过总查询 (tidb_query) 的执行时间。TOTAL_TIME:该项监控的总耗时。TOTAL_COUNT:该项监控执行的总次数。P999:该项监控的 P999 最大时间。P99:该项监控的 P99 最大时间。P90:该项监控的 P90 最大时间。P80:该项监控的 P80 最大时间。
以上监控中相关模块的耗时关系如下所示:
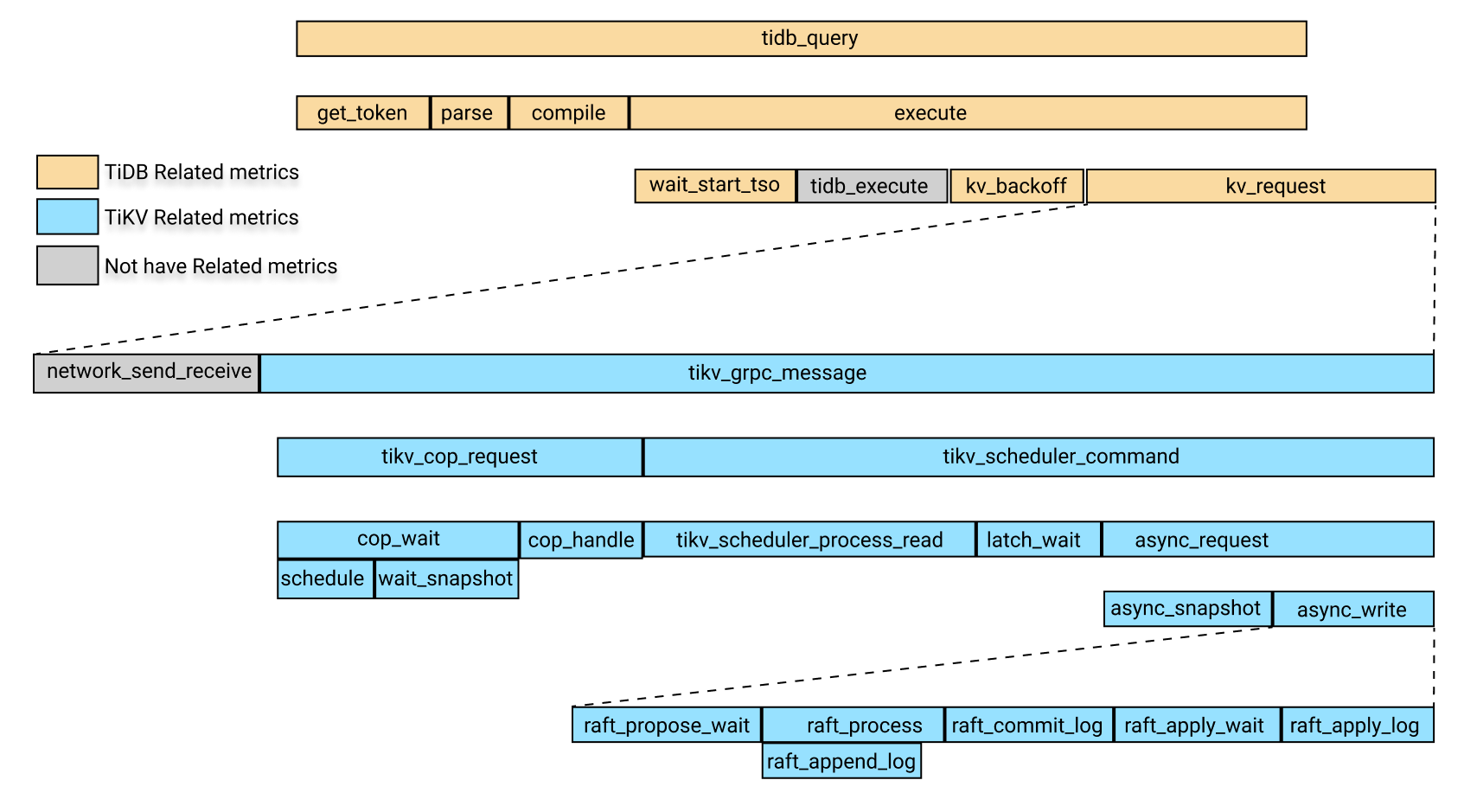
上图中,黄色部分是 TiDB 相关的监控,蓝色部分是 TiKV 相关的监控,灰色部分暂时没有具体对应的监控项。
上图中,tidb_query 的耗时包括以下部分的耗时:
get_tokenparsecompileexecute
其中 execute 的耗时包括以下部分:
wait_start_tso- TiDB 层的执行时间,目前暂无监控
- KV 请求的时间
tidb_kv_backoff的时间,这是 KV 请求失败后进行 backoff 的时间
其中,KV 请求时间包含以下部分:
- 请求的网络发送以及接收耗时,目前该项暂无监控,可以大致用 KV 请求时间减去
tikv_grpc_message的时间 tikv_grpc_message的耗时
其中,tikv_grpc_message 耗时包含以下部分:
- Coprocessor request 耗时,指用于处理 COP 类型的请求,该耗时包括以下部分:
tikv_cop_wait,请求排队等待的耗时Coprocessor handling request,处理 COP 请求的耗时
tikv_scheduler_command耗时,该耗时包含以下部分:tikv_scheduler_processing_read,处理读请求的耗时tikv_storage_async_request中获取 snapshot 的耗时(snapshot 是该项监控的 label)- 处理写请求的耗时,该耗时包括以下部分:
tikv_scheduler_latch_wait,等待 latch 的耗时tikv_storage_async_request中 write 的耗时(write 是该监控的 label)
其中,tikv_storage_async_request 中的 write 耗时是指 raft kv 写入的耗时,包括以下部分:
tikv_raft_propose_waittikv_raft_process,该耗时主要时间包括:tikv_raft_append_logtikv_raft_commit_logtikv_raft_apply_waittikv_raft_apply_log
用户可以根据上述耗时之间的关系,利用 TOTAL_TIME 以及 P999,P99 的时间大致定位哪些模块耗时比较长,然后再看相关的监控。
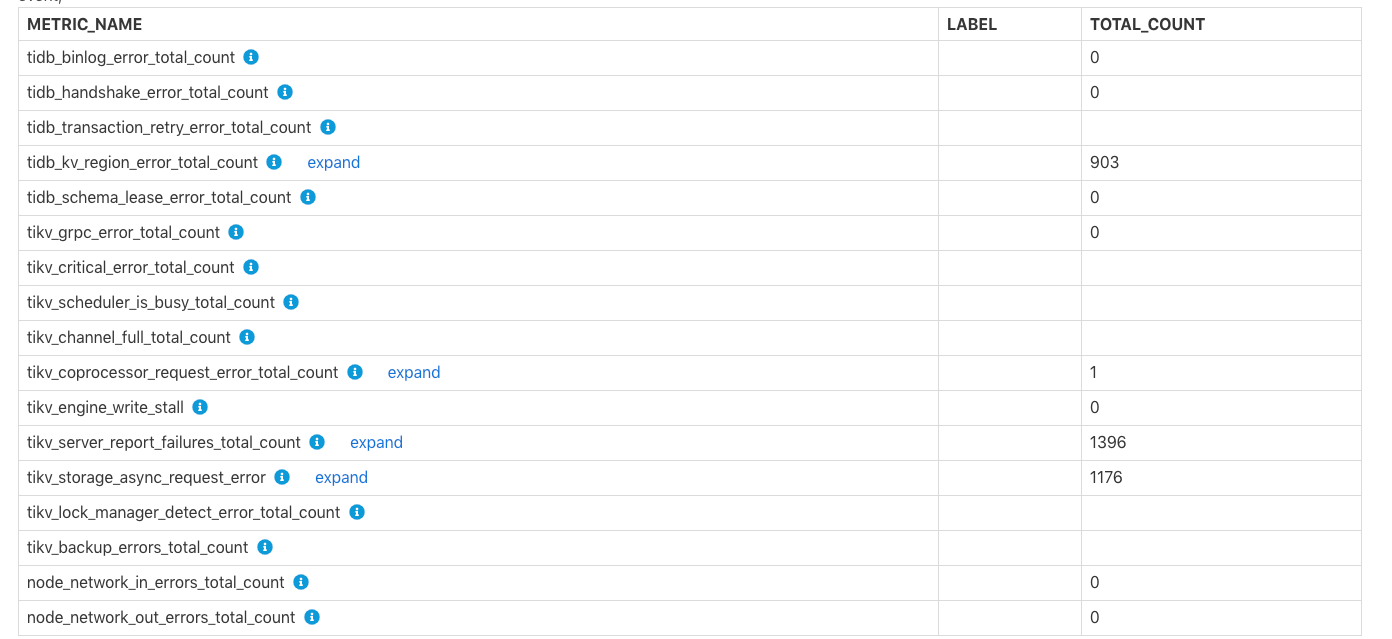
Errors Occurred in Each Component
Errors Occurred in Each Component 表显示包括 TiDB 和 TiKV 出现错误的总数。例如写 binlog 失败、tikv server is busy、TiKV channel full、tikv write stall 等错误,具体各项错误含义可以看行注释。
TiDB/PD/TiKV 的具体监控信息
这部分包括了 TiDB/PD/TiKV 更多的具体的监控信息。
TiDB 相关监控信息
Time Consumed by TiDB Component
Time Consumed by TiDB Component 表显示 TiDB 的各项监控耗时以及各项耗时的占比。和 Time Consumed by Each Component 表类似,但是这个表的 label 信息会更丰富,细节更多。
TiDB Server Connections
TiDB Server Connections 表显示 TiDB 各个实例的客户端连接数。
TiDB Transaction
TiDB Transaction 表显示 TiDB 事务相关的监控。
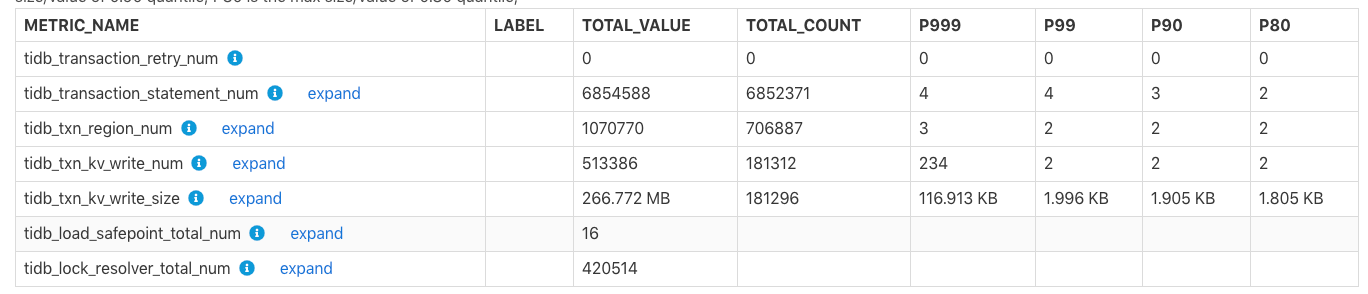
TOTAL_VALUE:该项监控在报告时间段内所有值的和 (SUM)。TOTAL_COUNT:该项监控出现的总次数。- P999: 该项监控的 P999 最大值。
- P99: 该项监控的 P99 最大值。
- P90: 该项监控的 P90 最大值。
- P80: 该项监控的 P80 最大值。
示例:
上表中,在报告时间范围的 tidb_txn_kv_write_size 表示一共约有 181296 次事务的 KV 写入,总 kV 写入大小是 266.772 MB,其中单次事务的 KV 写入的 P999、P99、P90、P80 的最大值分别为 116.913 KB、1.996 KB、1.905 KB、1.805 KB。
DDL Owner

上表表示从 2020-05-21 14:40:00 开始,集群的 DDL owner 在 10.0.1.13:10080 节点。如果 owner 发生变更,上表会有多行数据,其中 MinTime 列表示已知对应 Owner 的最小时间。
TiDB 中其他部分监控表如下:
- Statistics Info:TiDB 统计信息的相关监控。
- Top 10 Slow Query:报表时间范围内 Top 10 的慢查询信息。
- Top 10 Slow Query Group By Digest:报表时间范围内 Top 10 的慢查询信息,并按照 SQL 指纹聚合。
- Slow Query With Diff Plan:报表时间范围内执行计划发生变更的 SQL 语句。
PD 相关监控信息
PD 模块相关监控的报表如下:
- Time Consumed by PD Component:PD 中相关模块的耗时监控
- Scheduled Leader/Region:报表时间范围内集群发生的
balance-region和balance leader监控,比如从tikv_note_1上调度走了多少个 leader,调度进了多少个 leader。 - Cluster Status:集群的状态信息,包括总 TiKV 数量、总集群存储容量、Region 数量、离线 TiKV 的数量等信息。
- Store Status:记录各个 TiKV 节点的状态信息,包括 Region score、leader score、Region/leader 的数量。
- etcd Status:PD 内部的 etcd 相关信息。
TiKV 相关监控信息
TIKV 模块的相关监控报表如下:
- Time Consumed by TiKV Component:TiKV 中相关模块的耗时监控。
- Time Consumed by RocksDB:TiKV 中 RocksDB 的耗时监控。
- TiKV Error:TiKV 中各个模块相关的 error 信息。
- TiKV Engine Size:TiKV 中各个节点 column family 的存储数据大小。
- Coprocessor Info:TiKV 中 Coprocessor 模块相关的监控。
- Raft Info:TiKV 中 Raft 模块的相关监控信息。
- Snapshot Info:TiKV 中 snapshot 相关监控信息。
- GC Info:TiKV 中 GC 相关的监控信息。
- Cache Hit:TiKV 中 Rocksdb 的各个缓存的命中率监控信息。
配置信息
配置信息中,部分模块的配置信息可以显示报告时间范围内的配置值,有部分配置则因为无法获取到历史的配置值,所以是生成报告时刻的当前配置值。
在报告时间范围内,以下表包括部分配置的在报告时间范围的开始时间的值:
- Scheduler Initial Config:PD 调度相关配置在报告开始时间的初始值。
- TiDB GC Initial Config:TiDB GC 相关配置在报告开始时间的初始值。
- TiKV RocksDB Initial Config:TiKV RocksDB 相关配置在报告开始时间的初始值。
- TiKV RaftStore Initial Config:TiKV RaftStore 相关配置在报告开始时间的初始值。
在报表时间范围内,如若有些配置被修改过,以下表包括部分配置被修改的记录:
- Scheduler Config Change History
- TiDB GC Config Change History
- TiKV RocksDB Config Change History
- TiKV RaftStore Config Change History
示例:

上面报表显示,leader-schedule-limit 配置参数在报告时间范围内有被修改过:
2020-05-22T20:00:00+08:00,即报告的开始时间leader-schedule-limit的配置值为4,这里并不是指该配置被修改了,只是说明在报告时间范围的开始时间其配置值是4。2020-05-22T20:07:00+08:00,leader-schedule-limit的配置值为8,说明在2020-05-22T20:07:00+08:00左右,该配置的值被修改了。
下面的报表是生成报告时,TiDB、PD、TiKV 的在生成报告时刻的当前配置:
- TiDB's Current Config
- PD's Current Config
- TiKV's Current Config
对比报告
生成两个时间段的对比报告,其内容和单个时间段的报告是一样的,只是加入了对比列显示两个时间段的差别。下面主要介绍对比报告中的一些特有表以及如何查看对比报表。
首先在基本信息中的 Compare Report Time Range 报表会显示出对比的两个时间段:

其中 t1 是正常时间段,或者叫参考时间段,t2 是异常时间段。
下面是一些慢查询相关的报表:
- Slow Queries In Time Range t2:仅出现在
t2时间段但没有出现在t1时间段的慢查询。 - Top 10 slow query in time range t1:
t1时间段的 Top10 慢查询。 - Top 10 slow query in time range t2:
t2时间段的 Top10 慢查询。
DIFF_RATIO 介绍
本部分以 Instance CPU Usage 为例介绍 DIFF_RATIO。

t1.AVG、t1.MAX、t1.Min分别是t1时间段内 CPU 使用率的平均值、最大值、最小值。t2.AVG、t2.MAX、t2.Min分别是t2时间段内 CPU 使用率的平均值、最大值、最小值。AVG_DIFF_RATIO表示t1和t2时间段平均值的DIFF_RATIO。MAX_DIFF_RATIO表示t1和t2时间段最大值的DIFF_RATIO。MIN_DIFF_RATIO表示t1和t2时间段最小值的DIFF_RATIO。
DIFF_RATIO 表示两个时间段的差异大小,有以下几个取值方式:
- 如果该监控仅在
t2时间内才有值,t1时间段没有,则DIFF_RATIO取值为1。 - 如果监控项仅在
t1时间内才有值,t1时间段没有,则DIFF_RATIO取值为-1。 - 如果 t2 时间段的值比 t1 时间段的值大,则
DIFF_RATIO=(t2.value / t1.value) - 1。 - 如果
t2时间段的值比t1时间段的值小,则DIFF_RATIO=1 - (t1.value / t2.value)。
例如上表中,tidb 节点的平均 CPU 使用率在 t2 时间段比 t1 时间段高 2.02 倍,2.02 = 1240/410 - 1。
Maximum Different Item 报表介绍
Maximum Different Item 的报表是对比两个时间段的监控项后,按照监控项的差异大小排序,通过这个表可以很快发现两个时间段哪些监控的差异最大。示例如下:
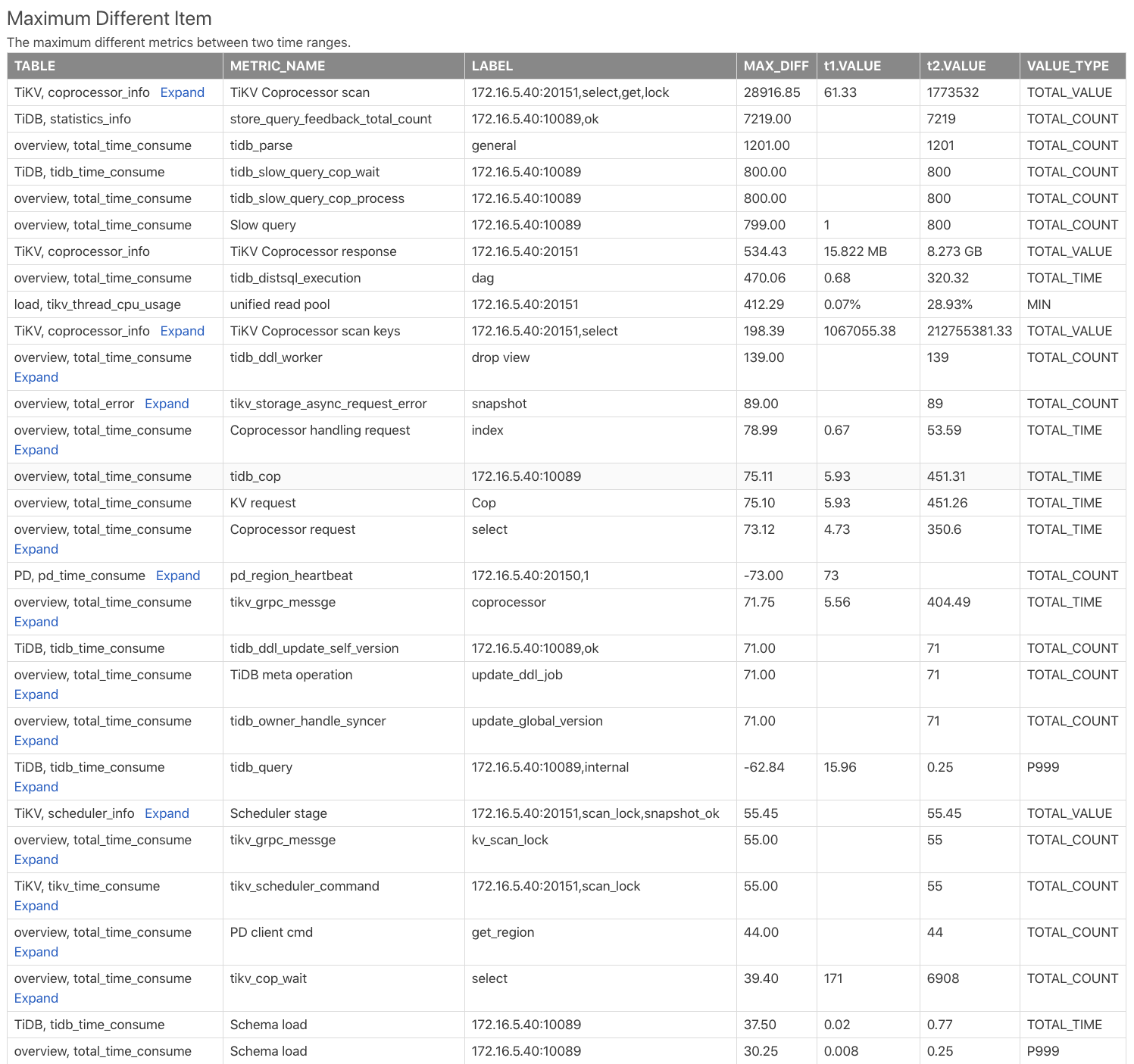
Table:表示这个监控项来自于对比报告中报表,如TiKV, coprocessor_info表示是 TiKV 组件下的coprocessor_info报表。METRIC_NAME:监控项名,点击expand可以查看该监控的不同 label 的差异对比。LABEL:监控项对应的 label。比如TiKV Coprocessor scan监控项有两个 label,分别是 instance、req、tag、sql_type,分别表示为 TiKV 地址、请求类型、操作类型和操作的 column family。MAX_DIFF:差异大小,取值为t1.VALUE和t2.VALUE的DIFF_RATIO计算。
可以从上表中发现,t2 时间段比 t1 时间段多出了大量的 Coprocessor 请求,TiDB 的解析 SQL (parse) 时间也多了很多。