备份与恢复工具 BR 简介
BR 全称为 Backup & Restore,是 TiDB 分布式备份恢复的命令行工具,用于对 TiDB 集群进行数据备份和恢复。
相比 Dumpling,BR 更适合大数据量的场景。
BR 除了可以用来进行常规备份恢复外,也可以在保证兼容性前提下用来做大规模的数据迁移。
本文介绍了 BR 的工作原理、推荐部署配置、使用限制以及几种使用方式。
工作原理
BR 将备份或恢复操作命令下发到各个 TiKV 节点。TiKV 收到命令后执行相应的备份或恢复操作。
在一次备份或恢复中,各个 TiKV 节点都会有一个对应的备份路径,TiKV 备份时产生的备份文件将会保存在该路径下,恢复时也会从该路径读取相应的备份文件。
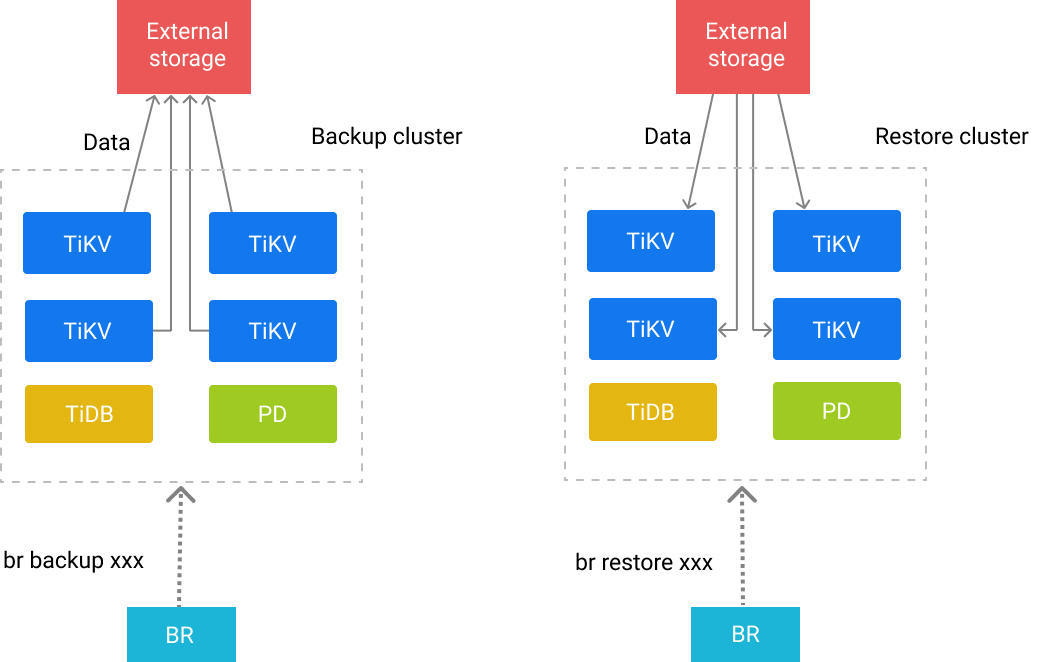
更多信息请参阅备份恢复设计方案。
备份文件类型
备份路径下会生成以下两种类型文件:
- SST 文件:存储 TiKV 备份下来的数据信息
backupmeta文件:存储本次备份的元信息,包括备份文件数、备份文件的 Key 区间、备份文件大小和备份文件 Hash (sha256) 值backup.lock文件:用于防止多次备份到同一目录
SST 文件命名格式
SST 文件以 storeID_regionID_regionEpoch_keyHash_cf 的格式命名。格式名的解释如下:
- storeID:TiKV 节点编号
- regionID:Region 编号
- regionEpoch:Region 版本号
- keyHash:Range startKey 的 Hash (sha256) 值,确保唯一性
- cf:RocksDB 的 ColumnFamily(默认为
default或write)
部署使用 BR 工具
推荐部署配置
- 推荐 BR 部署在 PD 节点上。
- 推荐使用一块高性能 SSD 网盘,挂载到 BR 节点和所有 TiKV 节点上,网盘推荐万兆网卡,否则带宽有可能成为备份恢复时的性能瓶颈。
使用限制
下面是使用 BR 进行备份恢复的几条限制:
- BR 恢复到 TiCDC / Drainer 的上游集群时,恢复数据无法由 TiCDC / Drainer 同步到下游。
- BR 只支持在
new_collations_enabled_on_first_bootstrap开关值相同的集群之间进行操作。这是因为 BR 仅备份 KV 数据。如果备份集群和恢复集群采用不同的排序规则,数据校验会不通过。所以恢复集群时,你需要确保select VARIABLE_VALUE from mysql.tidb where VARIABLE_NAME='new_collation_enabled';语句的开关值查询结果与备份时的查询结果相一致,才可以进行恢复。
兼容性
BR 和 TiDB 集群的兼容性问题分为以下两方面:
- BR 部分版本和 TiDB 集群的接口不兼容
- 某些功能在开启或关闭状态下,会导致 KV 格式发生变化,因此备份和恢复期间如果没有统一开启或关闭,就会带来不兼容的问题
下表整理了会导致 KV 格式发生变化的功能。
| 功能 | 相关 issue | 解决方式 |
|---|---|---|
| 聚簇索引 | #565 | 确保备份时 tidb_enable_clustered_index 全局变量和恢复时一致,否则会导致数据不一致的问题,例如 default not found 和数据索引不一致。 |
| New collation | #352 | 确保恢复时集群的 new_collations_enabled_on_first_bootstrap 变量值和备份时的一致,否则会导致数据索引不一致和 checksum 通不过。 |
| 恢复集群开启 TiCDC 同步 | #364 | TiKV 暂不能将 BR ingest 的 SST 文件下推到 TiCDC,因此使用 BR 恢复时候需要关闭 TiCDC。 |
在上述功能确保备份恢复一致的前提下,BR 和 TiKV/TiDB/PD 还可能因为版本内部协议不一致/接口不一致出现不兼容的问题,因此 BR 内置了版本检查。
版本检查
BR 内置版本会在执行备份和恢复操作前,对 TiDB 集群版本和自身版本进行对比检查。如果大版本不匹配(比如 BR v4.x 和 TiDB v5.x 上),BR 会提示退出。如要跳过版本检查,可以通过设置 --check-requirements=false 强行跳过版本检查。
需要注意的是,跳过检查可能会遇到版本不兼容的问题。BR 和 TiDB 各版本兼容情况如下表所示:
| 恢复版本(横向)\ 备份版本(纵向) | 用 BR nightly 恢复 TiDB nightly | 用 BR v5.0 恢复 TiDB v5.0 | 用 BR v4.0 恢复 TiDB v4.0 |
|---|---|---|---|
| 用 BR nightly 备份 TiDB nightly | ✅ | ✅ | ❌(如果恢复了使用非整数类型聚簇主键的表到 v4.0 的 TiDB 集群,BR 会无任何警告地导致数据错误) |
| 用 BR v5.0 备份 TiDB v5.0 | ✅ | ✅ | ❌(如果恢复了使用非整数类型聚簇主键的表到 v4.0 的 TiDB 集群,BR 会无任何警告地导致数据错误) |
| 用 BR v4.0 备份 TiDB v4.0 | ✅ | ✅ | ✅(如果 TiKV >= v4.0.0-rc.1,BR 包含 #233 Bug 修复,且 TiKV 不包含 #7241 Bug 修复,那么 BR 会导致 TiKV 节点重启) |
| 用 BR nightly 或 v5.0 备份 TiDB v4.0 | ❌(当 TiDB 版本小于 v4.0.9 时会出现 #609 问题) | ❌(当 TiDB 版本小于 v4.0.9 会出现 #609 问题) | ❌(当 TiDB 版本小于 v4.0.9 会出现 #609 问题) |
备份和恢复 mysql 系统库下的表数据(实验特性)
在 v5.1.0 之前,BR 备份时会过滤掉系统库 mysql.* 的表数据。自 v5.1.0 起,BR 默认备份集群内的全部数据,包括系统库 mysql.* 中的数据。但由于恢复 mysql.* 中系统表数据的技术实现尚不完善,因此 BR 默认不恢复系统库 mysql 中的表数据。
如果你希望将系统表(如 mysql.usertable1)的数据恢复到系统库 mysql 中,可以设置 filter 参数 来过滤表名 (-f "mysql.usertable1")。完成设置后,系统库下的表数据会恢复到临时库中,然后通过对临时库表进行重命名的方式恢复到系统库。
由于技术原因,以下系统表不能被正确恢复。即使你指定了 -f "mysql.*",以下表也不会被恢复:
- 统计信息相关的表:"stats_buckets","stats_extended","stats_feedback","stats_fm_sketch","stats_histograms","stats_meta","stats_top_n"
- 权限或系统相关的表:"tidb","global_variables","columns_priv","db","default_roles","global_grants","global_priv","role_edges","tables_priv","user","gc_delete_range","gc_delete_range_done","schema_index_usage"
运行 BR 的最低机型配置要求
运行 BR 的最低机型配置要求如下:
| CPU | 内存 | 硬盘类型 | 网络 |
|---|---|---|---|
| 1 核 | 4 GB | HDD | 千兆网卡 |
一般场景下(备份恢复的表少于 1000 张),BR 在运行期间的 CPU 消耗不会超过 200%,内存消耗不会超过 4 GB。但在备份和恢复大量数据表时,BR 的内存消耗可能会上升到 4 GB 以上。在实际测试中,备份 24000 张表大概需要消耗 2.7 GB 内存,CPU 消耗维持在 100% 以下。
最佳实践
下面是使用 BR 进行备份恢复的几种推荐操作:
- 推荐在业务低峰时执行备份操作,这样能最大程度地减少对业务的影响。
- BR 支持在不同拓扑的集群上执行恢复,但恢复期间对在线业务影响很大,建议低峰期或者限速 (
rate-limit) 执行恢复。 - BR 备份最好串行执行。不同备份任务并行会导致备份性能降低,同时也会影响在线业务。
- BR 恢复最好串行执行。不同恢复任务并行会导致 Region 冲突增多,恢复的性能降低。
- 推荐在
-s指定的备份路径上挂载一个共享存储,例如 NFS。这样能方便收集和管理备份文件。 - 在使用共享存储时,推荐使用高吞吐的存储硬件,因为存储的吞吐会限制备份或恢复的速度。
- BR 默认会分别在备份、恢复完成后,进行一轮数据校验,将文本数据同集群数据比较,来保证正确性。在迁移场景下,为了减少迁移耗时,推荐备份时关闭校验(
--checksum=false),只在恢复时开启校验。
使用方式
目前支持以下几种方式来运行 BR 工具,分别是通过 SQL 语句、命令行工具或在 Kubernetes 环境下进行备份恢复。
通过 SQL 语句
TiDB 支持使用 SQL 语句 BACKUP 和 RESTORE 进行备份恢复。如果要查看备份恢复的进度,你可以使用 SHOW BACKUPS|RESTORES 语句。
通过命令行工具
TiDB 支持使用 BR 命令行工具进行备份恢复(需手动下载)。关于 BR 命令行工具的具体使用方法,请参阅使用备份与恢复工具 BR。
在 Kubernetes 环境下
目前支持使用 BR 工具备份 TiDB 集群数据到兼容 S3 的存储、Google Cloud Storage 以及持久卷,并作恢复:
- 备份 TiDB 集群数据到兼容 S3 的存储
- 恢复 S3 兼容存储上的备份数据
- 备份 TiDB 集群到 Google Cloud Storage
- 恢复 Google Cloud Storage 上的备份数据
- 备份 TiDB 集群到持久卷
- 恢复持久卷上的备份数据