数据迁移工具概览
TiDB 提供了丰富的数据迁移相关的工具,用于全量迁移、增量迁移、备份恢复、数据同步等多种场景。
本文介绍了使用这些工具的场景、优势和相关限制等信息。请根据你的需求选择合适的工具。
下图显示了各迁移工具的使用场景。
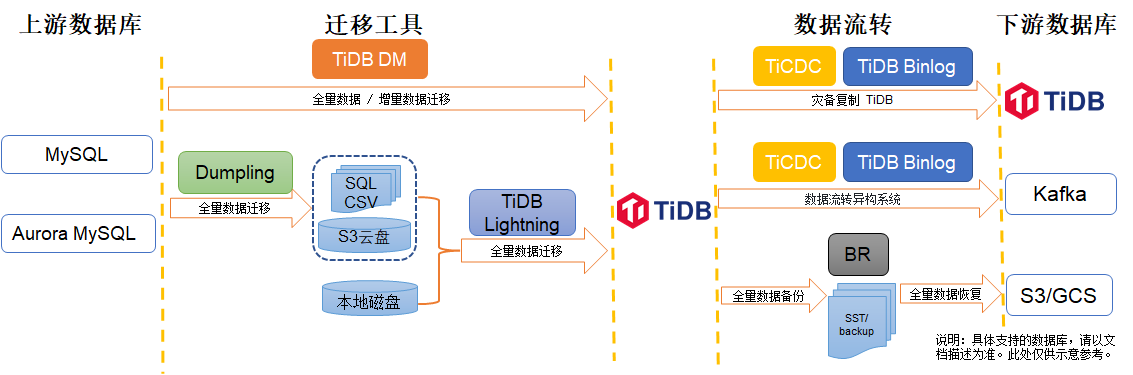
下表介绍了迁移工具的使用场景、支持的上下游等信息。
| 名称 | 使用场景 | 上游(或输入源文件) | 下游(或输出文件) | 主要优势 | 使用限制 |
|---|---|---|---|---|---|
| TiDB DM | 用于将数据从与 MySQL 协议兼容的数据库迁移到 TiDB。 | MySQL,MariaDB,Aurora,MySQL | TiDB | 一体化的数据迁移任务管理工具,支持全量迁移和增量同步;支持对表与操作进行过滤;支持分库分表的合并迁移。 | 建议用于 1TB 以内的存量数据迁移。 |
| Dumpling | 用于将数据从 MySQL/TiDB 进行全量导出。 | MySQL,TiDB | SQL,CSV | 支持全新的 table-filter,筛选数据更加方便;支持导出到 Amazon S3 云盘 | 如果导出后计划往非 TiDB 的数据库恢复,建议使用 Dumpling;如果是往另一个 TiDB 恢复,建议使用 BR。 |
| TiDB Lightning | 用于将数据全量导入到 TiDB。 | Dumpling 输出的文件;CSV 文件;从本地盘或 Amazon S3 云盘读取数据。 | TiDB | 支持迅速导入大量新数据,实现快速初始化 TiDB 集群的指定表;支持断点续传;支持数据过滤。 | 如果使用 Local-backend 进行数据导入,TiDB Lightning 运行后,TiDB 集群将无法正常对外提供服务。如果你不希望 TiDB 集群的对外服务受到影响,可以参考 TiDB Lightning TiDB-backend 中的硬件需求与部署方式进行数据导入。 |
| Backup & Restore (BR) | 用于对大数据量的 TiDB 集群进行数据备份和恢复。 | TiDB | SST;backup.meta 文件;backup.lock 文件 | 适用于向另一个 TiDB 恢复数据。支持数据冷备份到外部存储,可以用于灾备恢复。 | BR 恢复到 TiCDC / Drainer 的上游集群时,恢复数据无法由 TiCDC / Drainer 同步到下游。BR 只支持在 new_collations_enabled_on_first_bootstrap 开关值相同的集群之间进行操作。 |
| TiCDC | 通过拉取 TiKV 变更日志实现的 TiDB 增量数据同步工具,具有将数据还原到与上游任意 TSO 一致状态的能力,支持其他系统订阅数据变更。 | TiDB | TiDB,MySQL,Apache Pulsar,Kafka,Confluent | 提供开放数据协议 (TiCDC Open Protocol)。 | TiCDC 只能同步至少存在一个有效索引的表。暂不支持以下场景:暂不支持单独使用 RawKV 的 TiKV 集群。暂不支持在 TiDB 中创建 SEQUENCE 的 DDL 操作和 SEQUENCE 函数。 |
| TiDB Binlog | 用于 TiDB 集群间的增量数据同步,如将其中一个 TiDB 集群作为另一个 TiDB 集群的从集群。 | TiDB | TiDB,MySQL,Kafka,增量备份文件 | 支持实时备份和恢复。备份 TiDB 集群数据,同时可以用于 TiDB 集群故障时恢复。 | 与部分 TiDB 版本不兼容,不能一起使用。 |
| sync-diff-inspector | 用于校验 MySQL/TiDB 中两份数据的一致性。 | TiDB,MySQL | TiDB,MySQL | 提供了修复数据的功能,适用于修复少量不一致的数据。 | 对于 MySQL 和 TiDB 之间的数据同步不支持在线校验。不支持 JSON、BIT、BINARY、BLOB 等类型的数据。 |