TiDB 乐观事务模型
本文介绍 TiDB 乐观事务的原理,以及相关特性。本文假定你对 TiDB 的整体架构、Percolator 事务模型以及事务的 ACID 特性都有一定了解。
TiDB 的乐观事务模型只有在两阶段事务提交时才会检测是否存在写写冲突。
乐观事务原理
TiDB 中事务使用两阶段提交,流程如下:
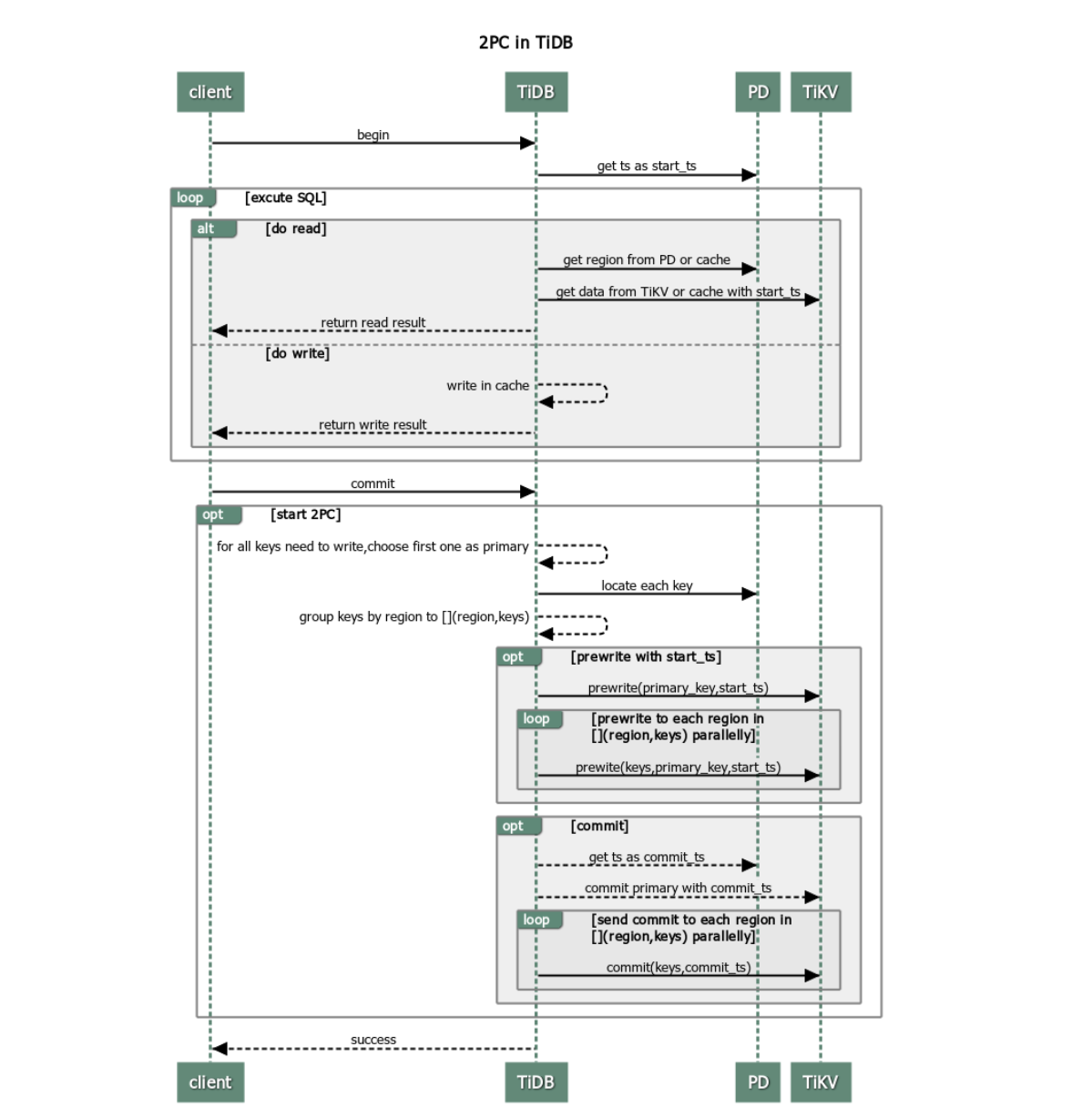
客户端开始一个事务。
TiDB 从 PD 获取一个全局唯一递增的版本号作为当前事务的开始版本号,这里定义为该事务的
start_ts版本。客户端发起读请求。
- TiDB 从 PD 获取数据路由信息,即数据具体存在哪个 TiKV 节点上。
- TiDB 从 TiKV 获取
start_ts版本下对应的数据信息。
客户端发起写请求。
TiDB 校验写入数据是否符合一致性约束(如数据类型是否正确、是否符合唯一索引约束等)。校验通过的数据将存放在内存里。
客户端发起 commit。
TiDB 开始两阶段提交,保证分布式事务的原子性,让数据真正落盘。
- TiDB 从当前要写入的数据中选择一个 Key 作为当前事务的 Primary Key。
- TiDB 从 PD 获取所有数据的写入路由信息,并将所有的 Key 按照所有的路由进行分类。
- TiDB 并发地向所有涉及的 TiKV 发起 prewrite 请求。TiKV 收到 prewrite 数据后,检查数据版本信息是否存在冲突或已过期。符合条件的数据会被加锁。
- TiDB 收到所有 prewrite 响应且所有 prewrite 都成功。
- TiDB 向 PD 获取第二个全局唯一递增版本号,定义为本次事务的
commit_ts。 - TiDB 向 Primary Key 所在 TiKV 发起第二阶段提交。TiKV 收到 commit 操作后,检查数据合法性,清理 prewrite 阶段留下的锁。
- TiDB 收到两阶段提交成功的信息。
TiDB 向客户端返回事务提交成功的信息。
TiDB 异步清理本次事务遗留的锁信息。
优缺点分析
通过分析 TiDB 中事务的处理流程,可以发现 TiDB 事务有如下优点:
- 实现原理简单,易于理解。
- 基于单实例事务实现了跨节点事务。
- 锁管理实现了去中心化。
但 TiDB 事务也存在以下缺点:
- 两阶段提交使网络交互增多。
- 需要一个中心化的版本管理服务。
- 事务数据量过大时易导致内存暴涨。
实际应用中,你可以根据事务的大小进行针对性处理,以提高事务的执行效率。
事务的重试
使用乐观事务模型时,在高冲突率的场景中,事务很容易提交失败。而 MySQL 内部使用的是悲观事务模型,在执行 SQL 语句的过程中进行冲突检测,所以提交时很难出现异常。为了兼容 MySQL 的悲观事务行为,TiDB 提供了重试机制。
重试机制
当事务提交后,如果发现冲突,TiDB 内部重新执行包含写操作的 SQL 语句。你可以通过设置 tidb_disable_txn_auto_retry = off 开启自动重试,并通过 tidb_retry_limit 设置重试次数:
# 设置是否禁用自动重试,默认为 “on”,即不重试。
tidb_disable_txn_auto_retry = off
# 控制重试次数,默认为 “10”。只有自动重试启用时该参数才会生效。
# 当 “tidb_retry_limit= 0” 时,也会禁用自动重试。
tidb_retry_limit = 10
你也可以修改当前 Session 或 Global 的值:
Session 级别设置:
set @@tidb_disable_txn_auto_retry = off;set @@tidb_retry_limit = 10;Global 级别设置:
set @@global.tidb_disable_txn_auto_retry = off;set @@global.tidb_retry_limit = 10;
重试的局限性
TiDB 默认不进行事务重试,因为重试事务可能会导致更新丢失,从而破坏可重复读的隔离级别。
事务重试的局限性与其原理有关。事务重试可概括为以下三个步骤:
- 重新获取
start_ts。 - 重新执行包含写操作的 SQL 语句。
- 再次进行两阶段提交。
第二步中,重试时仅重新执行包含写操作的 SQL 语句,并不涉及读操作的 SQL 语句。但是当前事务中读到数据的时间与事务真正开始的时间发生了变化,写入的版本变成了重试时获取的 start_ts 而非事务一开始时获取的 start_ts。因此,当事务中存在依赖查询结果来更新的语句时,重试将无法保证事务原本可重复读的隔离级别,最终可能导致结果与预期出现不一致。
如果业务可以容忍事务重试导致的异常,或并不关注事务是否以可重复读的隔离级别来执行,则可以开启自动重试。
冲突检测
乐观事务下,检测底层数据是否存在写写冲突是一个很重要的操作。具体而言,TiKV 在 prewrite 阶段就需要读取数据进行检测。为了优化这一块性能,TiDB 集群会在内存里面进行一次冲突预检测。
作为一个分布式系统,TiDB 在内存中的冲突检测主要在两个模块进行:
- TiDB 层。如果发现 TiDB 实例本身就存在写写冲突,那么第一个写入发出后,后面的写入已经清楚地知道自己冲突了,无需再往下层 TiKV 发送请求去检测冲突。
- TiKV 层。主要发生在 prewrite 阶段。因为 TiDB 集群是一个分布式系统,TiDB 实例本身无状态,实例之间无法感知到彼此的存在,也就无法确认自己的写入与别的 TiDB 实例是否存在冲突,所以会在 TiKV 这一层检测具体的数据是否有冲突。
其中 TiDB 层的冲突检测可以根据场景需要选择打开或关闭,具体配置项如下:
# 事务内存锁相关配置,当本地事务冲突比较多时建议开启。
[txn-local-latches]
# 是否开启内存锁,默认为 false,即不开启。
enabled = false
# Hash 对应的 slot 数,会自动向上调整为 2 的指数倍。
# 每个 slot 占 32 Bytes 内存。当写入数据的范围比较广时(如导数据),
# 设置过小会导致变慢,性能下降。(默认为 2048000)
capacity = 2048000
配置项 capacity 主要影响到冲突判断的正确性。在实现冲突检测时,不可能把所有的 Key 都存到内存里,所以真正存下来的是每个 Key 的 Hash 值。有 Hash 算法就有碰撞也就是误判的概率,这里可以通过配置 capacity 来控制 Hash 取模的值:
capacity值越小,占用内存小,误判概率越大。capacity值越大,占用内存大,误判概率越小。
实际应用时,如果业务场景能够预判断写入不存在冲突(如导入数据操作),建议关闭冲突检测。
相应地,在 TiKV 层检测内存中是否存在冲突也有类似的机制。不同的是,TiKV 层的检测会更严格且不允许关闭,仅支持对 Hash 取模值进行配置:
# scheduler 内置一个内存锁机制,防止同时对一个 Key 进行操作。
# 每个 Key hash 到不同的 slot。(默认为 2048000)
scheduler-concurrency = 2048000
此外,TiKV 支持监控等待 latch 的时间:
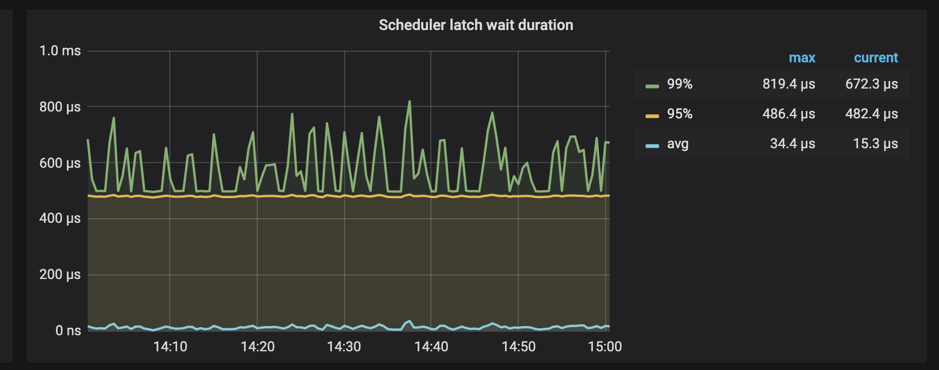
当 Scheduler latch wait duration 的值特别高时,说明大量时间消耗在等待锁的请求上。如果不存在底层写入慢的问题,基本上可以判断该段时间内冲突比较多。