PD 重要监控指标详解
使用 TiDB Ansible 部署 TiDB 集群时,一键部署监控系统 (Prometheus/Grafana),监控架构请看 TiDB 监控框架概述。
目前 Grafana Dashboard 整体分为 PD、TiDB、TiKV、Node_exporter、Overview 等。
对于日常运维,我们通过观察 PD 面板上的 Metrics,可以了解 PD 当前的状态。
以下为 PD Dashboard 监控说明:
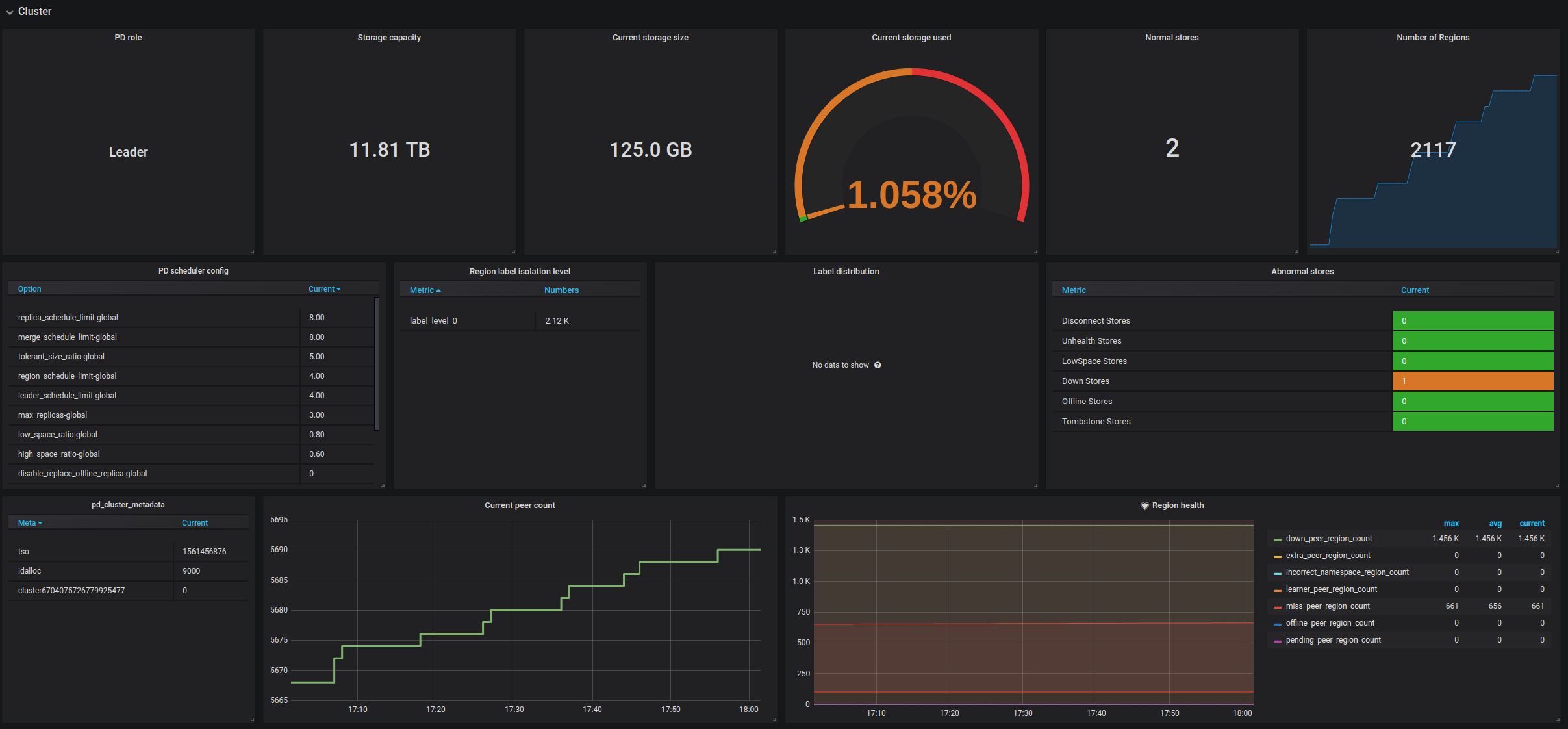
Cluster
- PD role:当前 PD 的角色
- Storage capacity:TiDB 集群总可用数据库空间大小
- Current storage size:TiDB 集群目前已用数据库空间大小
- Current storage usage:TiDB 集群存储空间的使用率
- Normal stores:处于正常状态的节点数目
- Number of Regions:当前集群的 Region 总量
- PD scheduler config:PD 调度配置列表
- Region label isolation level:不同 label 所在的 level 的 Region 数量
- Label distribution:集群中 TiKV 节点的 label 分布情况
- Abnormal stores:处于异常状态的节点数目,正常情况应当为 0
- pd_cluster_metadata:记录集群 ID,时间戳和生成的 ID
- Current peer count:当前集群 peer 的总量
- Region health:每个 Region 的状态,通常情况下,pending 的 peer 应该少于 100,miss 的 peer 不能一直大于 0
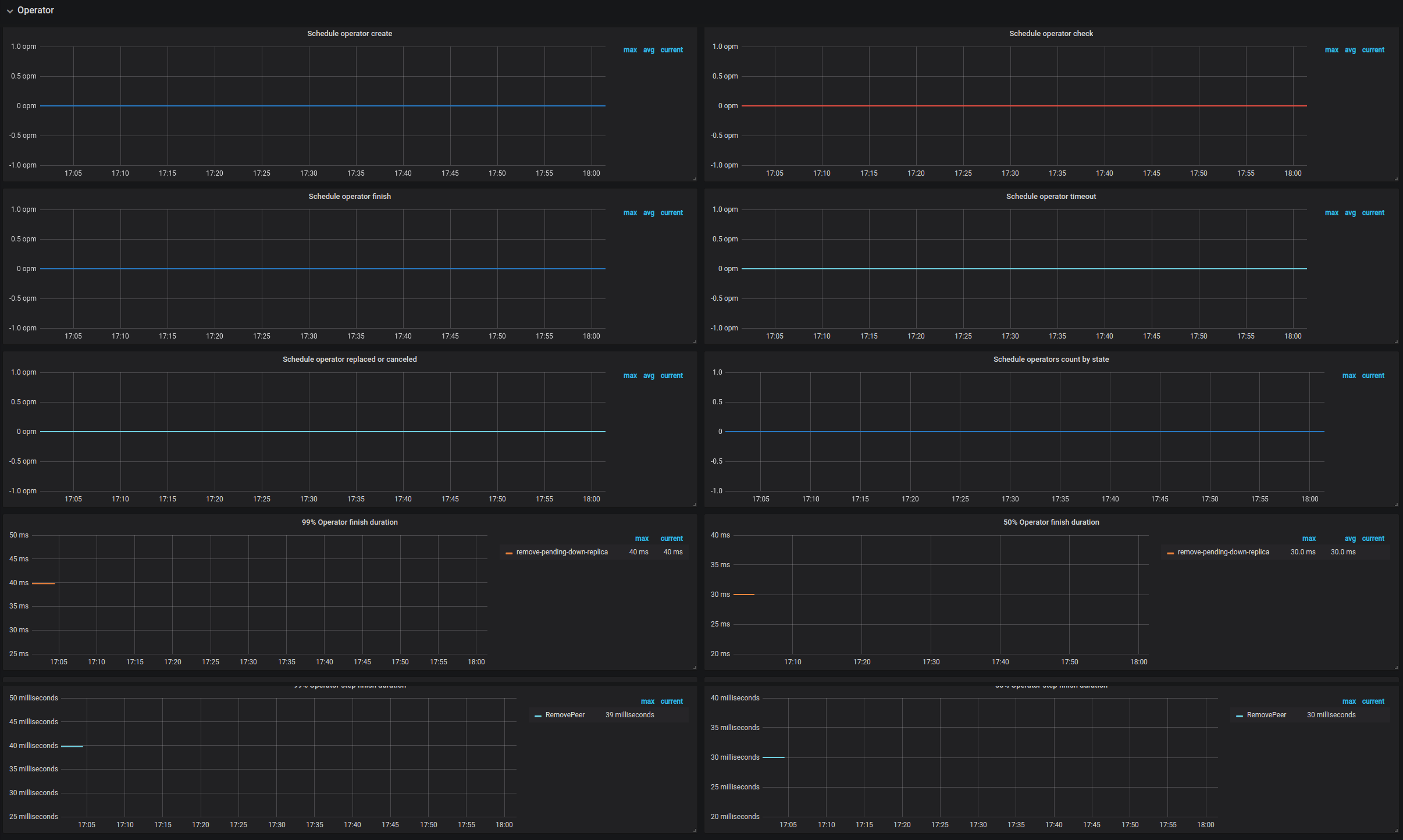
Operator
- Schedule operator create:新创建的不同 operator 的数量
- Schedule operator check:已检查的 operator 的数量,主要检查是否当前步骤已经执行完成,如果是,则执行下一个步骤
- Schedule operator finish:已完成调度的 operator 的数量
- Schedule operator timeout:已超时的 operator 的数量
- Schedule operator replaced or canceled:已取消或者被替换的 operator 的数量
- Schedule operators count by state:不同状态的 operator 的数量
- 99% Operator finish duration:99% 已完成 operator 所花费的最长时间
- 50% Operator finish duration:50% 已完成 operator 所花费的最长时间
- 99% Operator step duration:99% 已完成的 operator 步骤所花费的最长时间
- 50% Operator step duration:50% 已完成的 operator 步骤所花费的最长时间
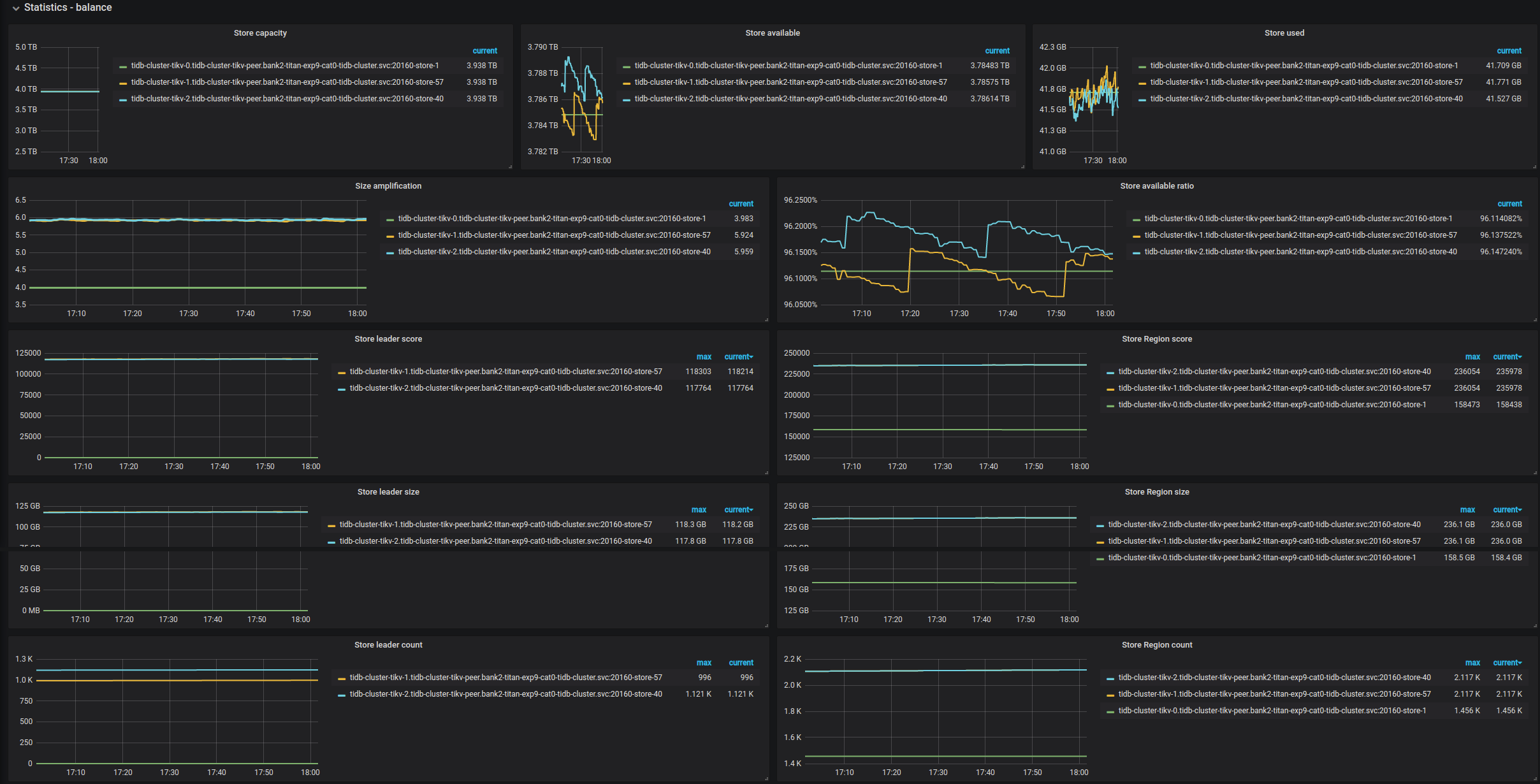
Statistics - Balance
- Store capacity:每个 TiKV 实例的总的空间大小
- Store available:每个 TiKV 实例的可用空间大小
- Store used:每个 TiKV 实例的已使用空间大小
- Size amplification:每个 TiKV 实例的空间放大比率
- Size available ratio:每个 TiKV 实例的可用空间比率
- Store leader score:每个 TiKV 实例的 leader 分数
- Store Region score:每个 TiKV 实例的 Region 分数
- Store leader size:每个 TiKV 实例上所有 leader 的大小
- Store Region size:每个 TiKV 实例上所有 Region 的大小
- Store leader count:每个 TiKV 实例上所有 leader 的数量
- Store Region count:每个 TiKV 实例上所有 Region 的数量
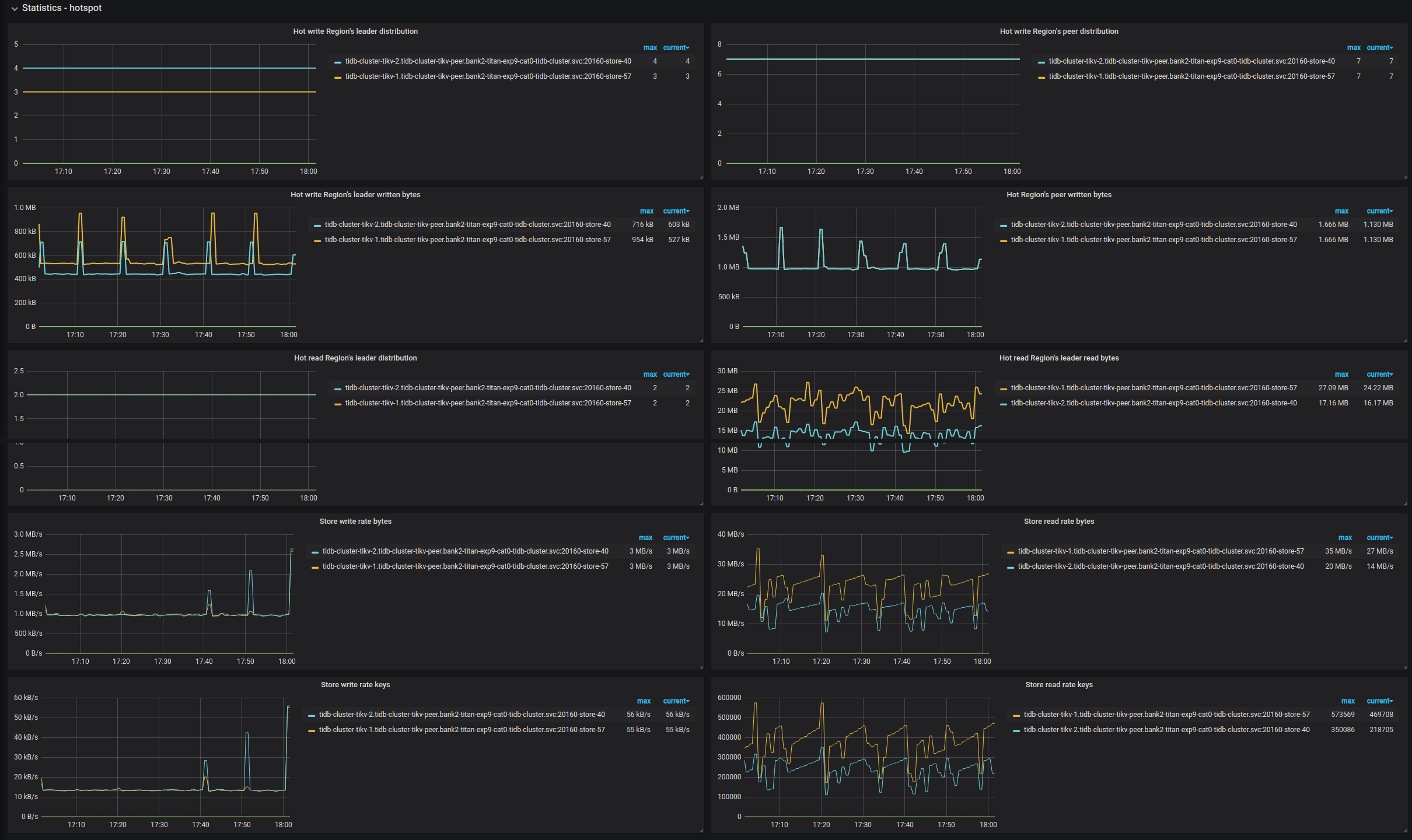
Statistics - hotspot
- Hot write Region's leader distribution:每个 TiKV 实例上是写入热点的 leader 的数量
- Hot write Region's peer distribution:每个 TiKV 实例上是写入热点的 peer 的数量
- Hot write Region's leader written bytes:每个 TiKV 实例上热点的 leader 的写入大小
- Hot write Region's peer written bytes:每个 TiKV 实例上热点的 peer 的写入大小
- Hot read Region's leader distribution:每个 TiKV 实例上是读取热点的 leader 的数量
- Hot read Region's peer distribution:每个 TiKV 实例上是读取热点的 peer 的数量
- Hot read Region's leader read bytes:每个 TiKV 实例上热点的 leader 的读取大小
- Hot read Region's peer read bytes:每个 TiKV 实例上热点的 peer 的读取字节数
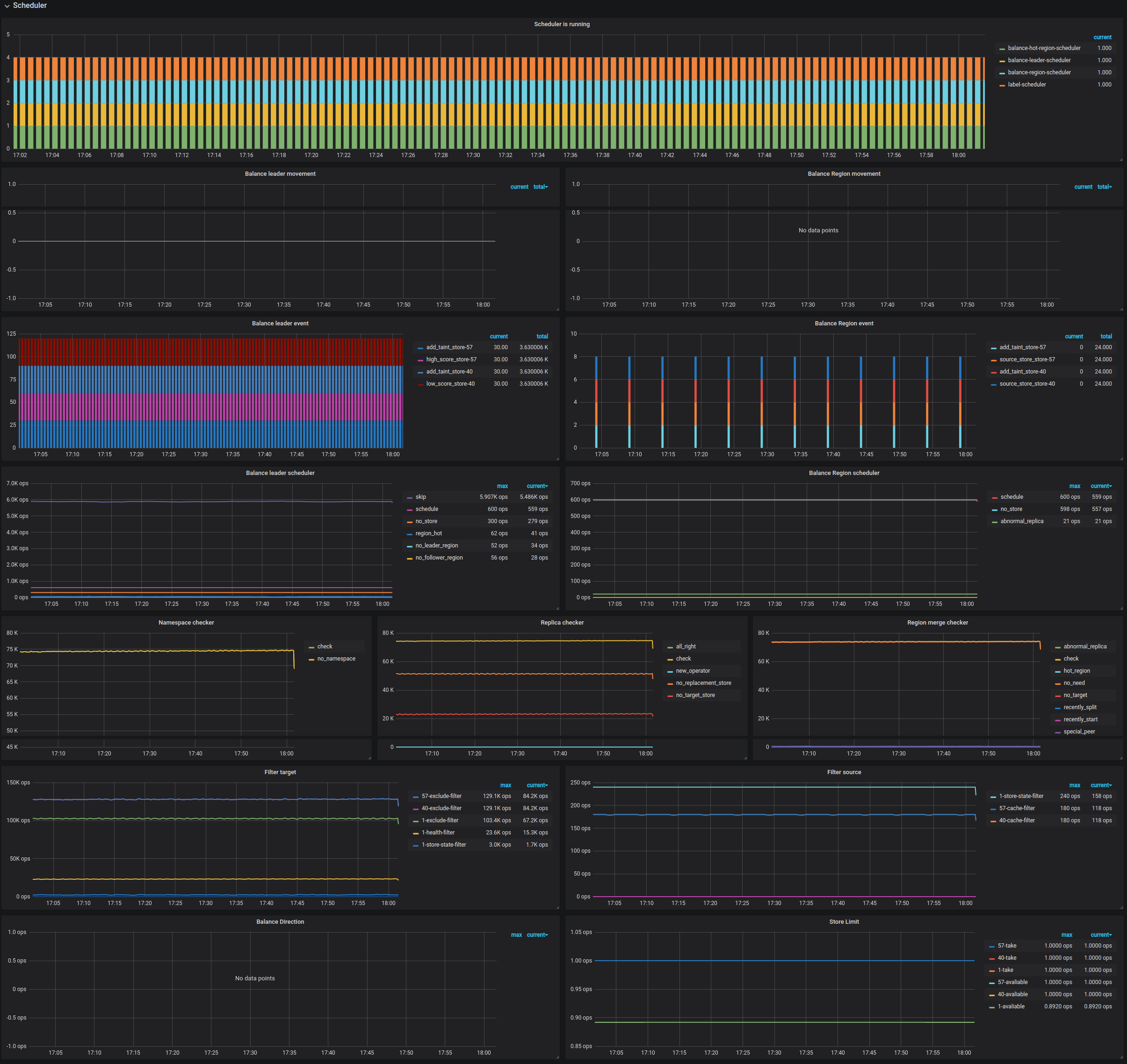
Scheduler
- Scheduler is running:所有正在运行的 scheduler
- Balance leader movement:leader 移动的详细情况
- Balance Region movement:Region 移动的详细情况
- Balance leader event:balance leader 的事件数量
- Balance Region event:balance Region 的事件数量
- Balance leader scheduler:balance-leader scheduler 的状态
- Balance Region scheduler:balance-region scheduler 的状态
- Namespace checker:namespace checker 的状态
- Replica checker:replica checker 的状态
- Region merge checker:merge checker 的状态
- Filter target:尝试选择 Store 作为调度 taget 时没有通过 Filter 的计数
- Filter source:尝试选择 Store 作为调度 source 时没有通过 Filter 的计数
- Balance Direction:Store 被选作调度 target 或 source 的次数
- Store Limit:Store 的调度限流状态
gRPC
- Completed commands rate:gRPC 命令的完成速率
- 99% Completed commands duration:99% 命令的最长消耗时间

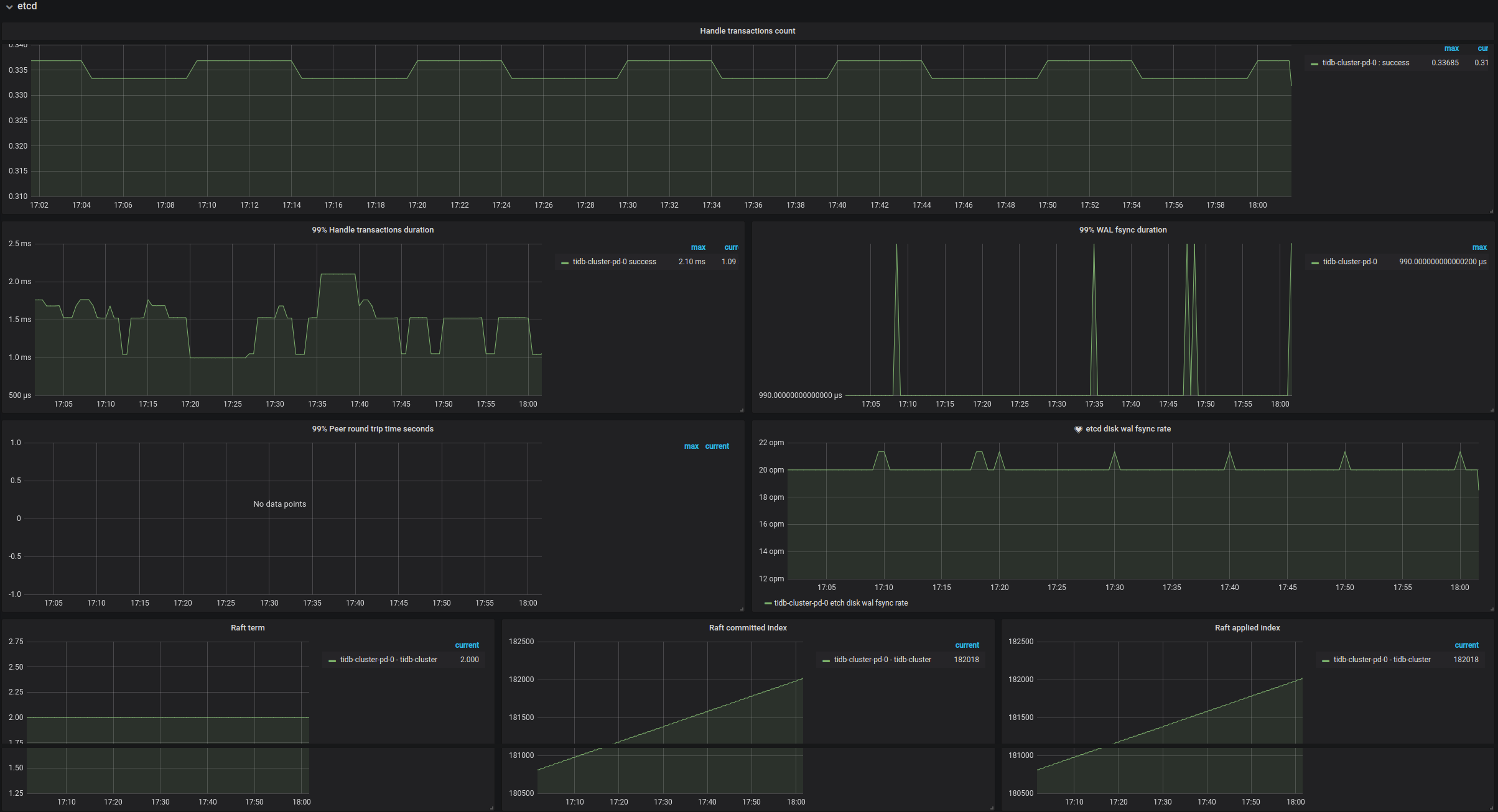
etcd
- Handle transactions count:etcd 的事务个数
- 99% Handle transactions duration:99% 的情况下,处理 etcd 事务所需花费的时间
- 99% WAL fsync duration:99% 的情况下,持久化 WAL 所需花费的时间,这个值通常应该小于 1s
- 99% Peer round trip time seconds:99% 的情况下,etcd 的网络延时,这个值通常应该小于 1s
- etcd disk WAL fsync rate:etcd 持久化 WAL 的速率
- Raft term:当前 Raft 的 term
- Raft committed index:最后一次 commit 的 Raft index
- Raft applied index:最后一次 apply 的 Raft index
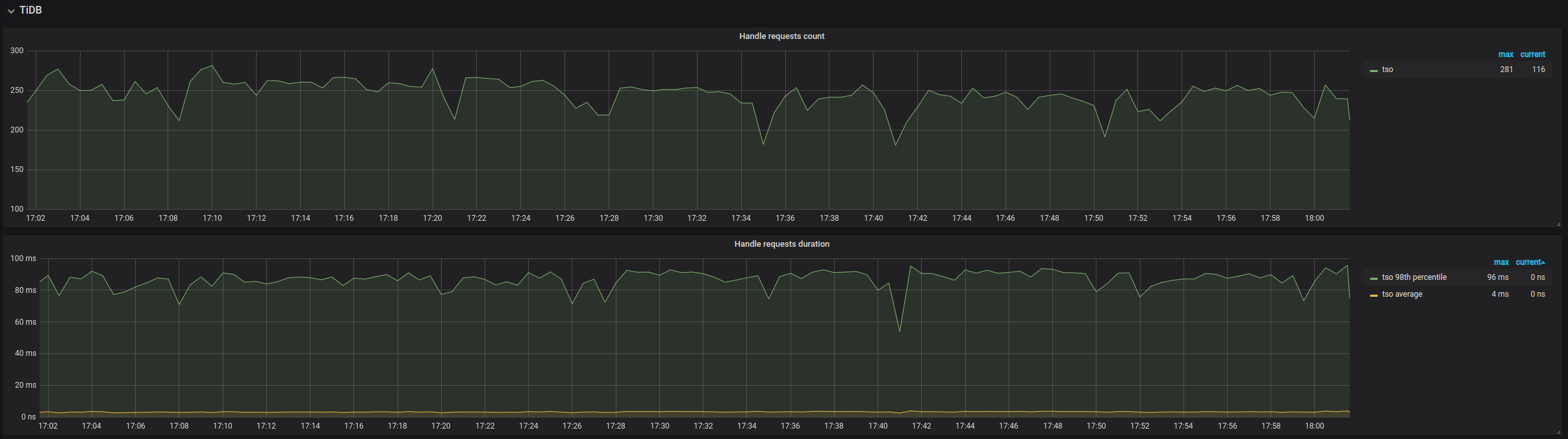
TiDB
- Handle requests count:TiDB 的请求数量
- Handle requests duration:每个请求所花费的时间,99% 的情况下,应该小于 100ms
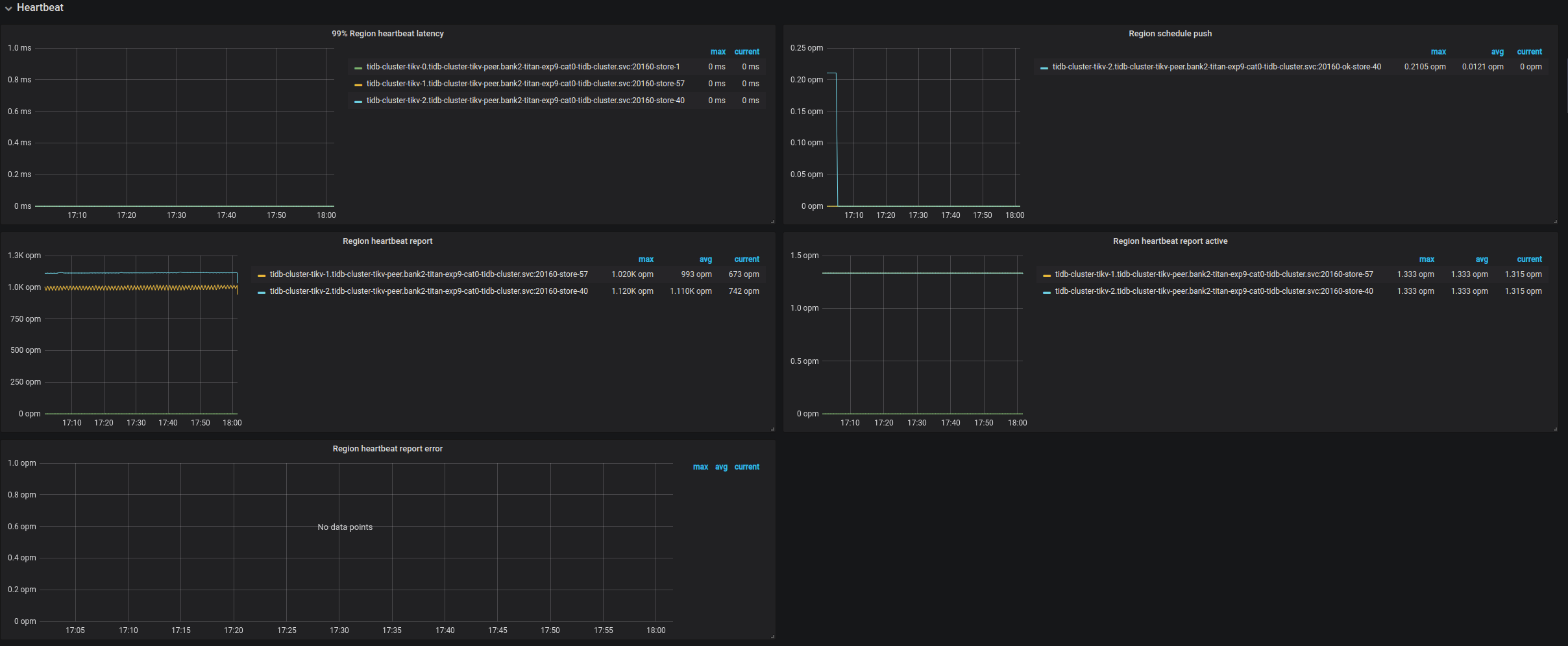
Heartbeat
- Region heartbeat report:TiKV 向 PD 发送的心跳个数
- Region heartbeat report error:TiKV 向 PD 发送的异常的心跳个数
- Region heartbeat report active:TiKV 向 PD 发送的正常的心跳个数
- Region schedule push:PD 向 TiKV 发送的调度命令的个数
- 99% Region heartbeat latency:99% 的情况下,心跳的延迟
Region storage
- Syncer Index:Leader 记录 Region 变更历史的最大 index
- history last index:Follower 成功同步的 Region 变更历史的 index
