Follower Read
在 TiDB 中,为了保证高可用和数据安全,TiKV 会为每个 Region 保存多个副本,其中一个为 leader,其余为 follower。默认情况下,所有读写请求都由 leader 处理。Follower Read 功能允许在保持强一致性的前提下,从 Region 的 follower 副本读取数据,从而分担 leader 的读取压力,提升集群整体的读吞吐量。
在执行 Follower Read 时,TiDB 会根据拓扑信息选择合适的副本。具体来说,TiDB 使用 zone label 判断一个副本是否为本地副本:当 TiDB 与目标 TiKV 的 zone label 相同时,TiDB 认为该副本是本地副本。更多信息参见通过拓扑 label 进行副本调度。
通过让 follower 参与数据读取,Follower Read 可以实现以下目标:
- 分散读热点,减轻 leader 负载。
- 在多可用区或多机房部署中,优先读取本地副本以减少跨区流量。
适用场景
Follower Read 适用于以下场景:
- 读请求量大、存在明显读热点的业务。
- 多可用区部署中,希望优先读取本地副本以节省带宽的场景。
- 在读写分离架构下,希望进一步提升集群整体读性能的场景。
使用方式
要开启 TiDB 的 Follower Read 功能,将变量 tidb_replica_read 的值设置为对应的目标值即可:
set [session | global] tidb_replica_read = '<目标值>';
作用域:SESSION | GLOBAL
默认值:leader
该变量用于设置期待的数据读取方式。从 v8.5.4 开始,该变量仅对只读 SQL 语句生效。
在需要通过读取本地副本以减少跨区流量的场景下,推荐如下配置:
leader:默认值,提供最佳性能。closest-adaptive:在最小性能损失的前提下,尽可能节省跨区流量。closest-replicas:可最大限度地节省跨区流量,但可能带来一定的性能损耗。
如果当前正在使用其他配置,可参考下表修改为推荐配置:
如果希望使用更精确的读副本选择策略,请参考完整的可选配置列表:
当设置为默认值
leader或者空字符串时,TiDB 会维持原有行为方式,将所有的读取操作都发送给 leader 副本处理。当设置为
follower时,TiDB 会选择 Region 的 follower 副本完成所有的数据读取操作。当 Region 存在 learner 副本时,TiDB 也会考虑从 learner 副本读取数据,此时 follower 副本和 learner 副本具有相同优先级。若当前 Region 无可用的 follower 副本或 learner 副本,TiDB 会从 leader 副本读取数据。当设置为
leader-and-follower时,TiDB 可以选择任意副本来执行读取操作,此时读请求会在 leader、follower 和 learner 之间负载均衡。当设置为
prefer-leader时,TiDB 会优先选择 leader 副本执行读取操作。当 leader 副本的处理速度明显变慢时,例如由于磁盘或网络性能抖动,TiDB 将选择其他可用的 follower 副本来执行读取操作。当设置为
closest-replicas时,TiDB 会优先选择分布在同一可用区的副本执行读取操作,对应的副本可以是 leader、follower 或 learner。如果同一可用区内没有副本分布,则会从 leader 执行读取。当设置为
closest-adaptive时:- 当一个读请求的预估返回结果大于或等于变量
tidb_adaptive_closest_read_threshold的值时,TiDB 会优先选择分布在同一可用区的副本执行读取操作。此时,为了避免读流量在各个可用区分布不均衡,TiDB 会动态检测当前在线的所有 TiDB 和 TiKV 的可用区数量分布,在每个可用区中closest-adaptive配置实际生效的 TiDB 节点数总是与包含 TiDB 节点最少的可用区中的 TiDB 节点数相同,并将其他多出的 TiDB 节点自动切换为读取 leader 副本。例如,如果 TiDB 分布在 3 个可用区,其中 A 和 B 两个可用区各包含 3 个 TiDB 节点,C 可用区只包含 2 个 TiDB 节点,那么每个可用区中closest-adaptive实际生效的 TiDB 节点数为 2,A 和 B 可用区中各有 1 个节点自动被切换为读取 leader 副本。 - 当一个读请求的预估返回结果小于变量
tidb_adaptive_closest_read_threshold的值时,TiDB 会选择 leader 副本执行读取操作。
- 当一个读请求的预估返回结果大于或等于变量
当设置为
learner时,TiDB 会选择 learner 副本执行读取操作。在读取时,如果当前 Region 没有 learner 副本或 learner 副本不可用,TiDB 会从可用 leader 或 follower 副本读取数据。
基本监控
通过观察 TiDB > KV Request > Read Req Traffic 面板(从 v8.5.4 开始引入),可以帮助判断是否需要使用 Follower Read 以及开启 Follower Read 后查看节省流量的效果。
实现机制
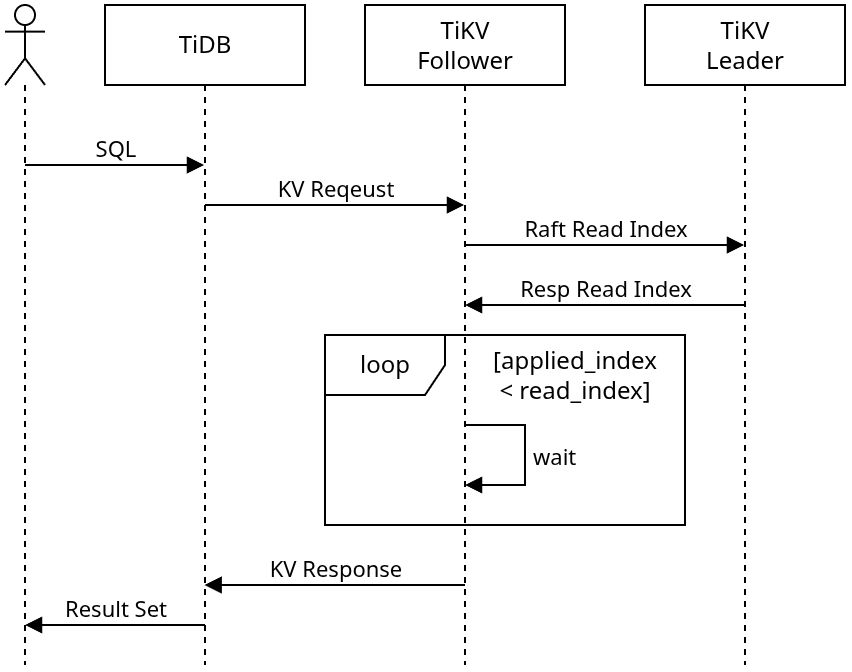
在 Follower Read 功能出现之前,TiDB 采用 strong leader 策略将所有的读写操作全部提交到 Region 的 leader 节点上完成。虽然 TiKV 能够很均匀地将 Region 分散到多个物理节点上,但是对于每一个 Region 来说,只有 leader 副本能够对外提供服务,另外的 follower 除了时刻同步数据准备着 failover 时投票切换成为 leader 外,没有办法对 TiDB 的请求提供任何帮助。
Follower Read 包含一系列将 TiKV 读取负载从 Region 的 leader 副本上 offload 到 follower 副本的负载均衡机制。为了允许在 TiKV 的 follower 节点进行数据读取,同时又不破坏线性一致性和 Snapshot Isolation 的事务隔离,Region 的 follower 节点需要使用 Raft ReadIndex 协议确保当前读请求可以读到当前 leader 节点上已经 commit 的最新数据。在 TiDB 层面,Follower Read 只需根据负载均衡策略将某个 Region 的读取请求发送到 follower 节点。
Follower 强一致读
TiKV follower 节点处理读取请求时,首先使用 Raft ReadIndex 协议与 Region 当前的 leader 节点进行一次交互,来获取当前 Raft group 最新的 commit index(read index)。本地 apply 到所获取的 leader 节点最新 commit index 后,便可以开始正常的读取请求处理流程。
Follower 副本选择策略
Follower Read 不会破坏 TiDB 的 Snapshot Isolation 事务隔离级别。TiDB 在第一次选取副本时会根据 tidb_replica_read 的配置进行选择。从第二次重试开始,TiDB 会优先保证读取成功,因此当选中的 follower 节点出现无法访问的故障或其他错误时,会切换到 leader 提供服务。
leader
- 选择 leader 副本进行读取,不考虑副本位置。
closest-replicas
- 当和 TiDB 同一个 AZ 的副本是 leader 节点时,不使用 Follower Read。
- 当和 TiDB 同一个 AZ 的副本不是 leader 节点时,使用 Follower Read。
closest-adaptive
- 如果预估的返回结果不够大,使用
leader策略,不进行 Follower Read。 - 如果预估的返回结果足够大,使用
closest-replicas策略。
Follower Read 的性能开销
为了保证数据强一致性,Follower Read 不管读取多少数据,都需要执行一次 ReadIndex 操作,这将不可避免地消耗更多的 TiKV CPU 资源。因此,在小查询(如点查)场景下,Follower Read 的性能损耗相对更明显。同时,因为对小查询进行本地读取能节省的流量有限,更推荐在大查询或批量读取场景中使用 Follower Read。
当 tidb_replica_read 设置为 closest-adaptive 时,TiDB 在处理小查询时不会使用 Follower Read。因此,在各种工作负载下,相比于 leader 策略,TiKV 的额外 CPU 开销通常不超过 10%。