乐观模式下分库分表合并迁移
本文介绍了 DM 提供的乐观模式下分库分表的合并迁移功能,此功能可用于将上游 MySQL/MariaDB 实例中结构相同/不同的表迁移到下游 TiDB 的同一个表中。
背景
DM 支持在线上执行分库分表的 DDL 语句(通称 Sharding DDL),默认使用“悲观模式”,即当上游一个分表执行某一 DDL 后,这个分表的迁移会暂停,等待其他所有分表都执行了同样的 DDL 才在下游执行该 DDL 并继续数据迁移。这种“悲观协调”模式的优点是可以保证迁移到下游的数据不会出错,缺点是会暂停数据迁移而不利于对上游进行灰度变更。有些用户可能会花较长时间在单一分表执行 DDL,验证一定时间后才会更改其他分表的结构。在悲观模式迁移的设定下,这些 DDL 会阻塞迁移,binlog 事件会大量积压。
因此,需要提供一种新的“乐观协调”模式,在一个分表上执行的 DDL,自动修改成兼容其他分表的语句后,立即迁移到下游,不会阻挡任何分表执行的 DML 的迁移。
乐观协调模式的配置
在任务的配置文件中指定 shard-mode 为 optimistic 则使用“乐观协调”模式,可通过开启 strict-optimistic-shard-mode 限制“乐观协调”模式的行为,示例配置文件可以参考 DM 任务完整配置文件介绍。
使用限制
使用“乐观协调”模式有一定的风险,需要严格遵照以下方针:
- 执行每个批次的 DDL 前和后,要确保每个分表的结构达成一致。
- 进行灰度 DDL 时,只集中在一个分表上测试。
- 灰度完成后,在其他分表上尽量以最简单直接的 DDL 迁移到最终的 schema,而不要重新执行灰度测试中对或错的每一步。
- 例如:在分表执行过
ADD COLUMN A INT; DROP COLUMN A; ADD COLUMN A FLOAT;,在其他分表直接执行ADD COLUMN A FLOAT即可,不需要三条 DDL 都执行一遍。
- 例如:在分表执行过
- 执行 DDL 时要注意观察 DM 迁移状态。当迁移报错时,需要判断这个批次的 DDL 是否会造成数据不一致。
“乐观协调”模式下,上游执行的大部分 DDL 无需特别关注,将自动同步,本文使用“一类 DDL” 指代。同时,还有一部分改变列名、列属性或列默认值的 DDL,称为“二类 DDL”,上游执行时要注意必须保证该 DDL 在各分表中按相同的顺序执行。
“二类 DDL” 举例如下:
- 修改列的类型:
ALTER TABLE table_name MODIFY COLUMN column_name VARCHAR(20)。 - 重命名列:
ALTER TABLE table_name RENAME COLUMN column_1 TO column_2;。 - 增加没有默认值且非空的列:
ALTER TABLE table_name ADD COLUMN column_1 NOT NULL;。 - 重命名索引:
ALTER TABLE table_name RENAME INDEX index_1 TO index_2;。
各分表在执行以上 DDL 时,如果指定 strict-optimistic-shard-mode: true,会直接中断任务并报错。如果指定 strict-optimistic-shard-mode: false 或未指定,若分表 DDL 顺序不同,将导致同步中断,例如下述场景:
- 分表 1 先重命名列,再修改列类型
- 重命名列:
ALTER TABLE table_name RENAME COLUMN column_1 TO column_2;。 - 修改列类型:
ALTER TABLE table_name MODIFY COLUMN column_3 VARCHAR(20);。
- 重命名列:
- 分表 2 先修改列类型,再重命名列
- 修改列类型:
ALTER TABLE table_name MODIFY COLUMN column_3 VARCHAR(20)。 - 重命名列:
ALTER TABLE table_name RENAME COLUMN column_1 TO column_2;。
- 修改列类型:
此外,不论是使用“乐观协调”或“悲观协调”,DM 仍是有以下限制:
- 不支持
DROP TABLE/DROP DATABASE。 - 不支持
TRUNCATE TABLE。 - 单条 DDL 语句要求仅包含对一张表的操作。
- TiDB 不支持的 DDL 语句在 DM 也不支持。
- 新增列的默认值不能包含
current_timestamp、rand()、uuid()等,否则会造成上下游数据不一致。
风险
使用乐观模式迁移时,由于 DDL 会即时迁移到下游,若使用不当,可能导致上下游数据不一致。
使数据不一致的操作
- 各分表的表结构不兼容,例:
- 两个分表各自添加相同名称的列,但其类型不同。
- 两个分表各自添加相同名称的列,但其默认值不同。
- 两个分表各自添加相同名称的生成列,但其生成表达式不同。
- 两个分表各自添加相同名称的索引,但其键组合不同。
- 其他同名异构的情况。
- 在分表上执行对数据具有破坏性的 DDL,然后尝试回滚,例:
- 刪除一列 X,之后又把 X 加回來。
例子
例如以下三个分表合并迁移到 TiDB:
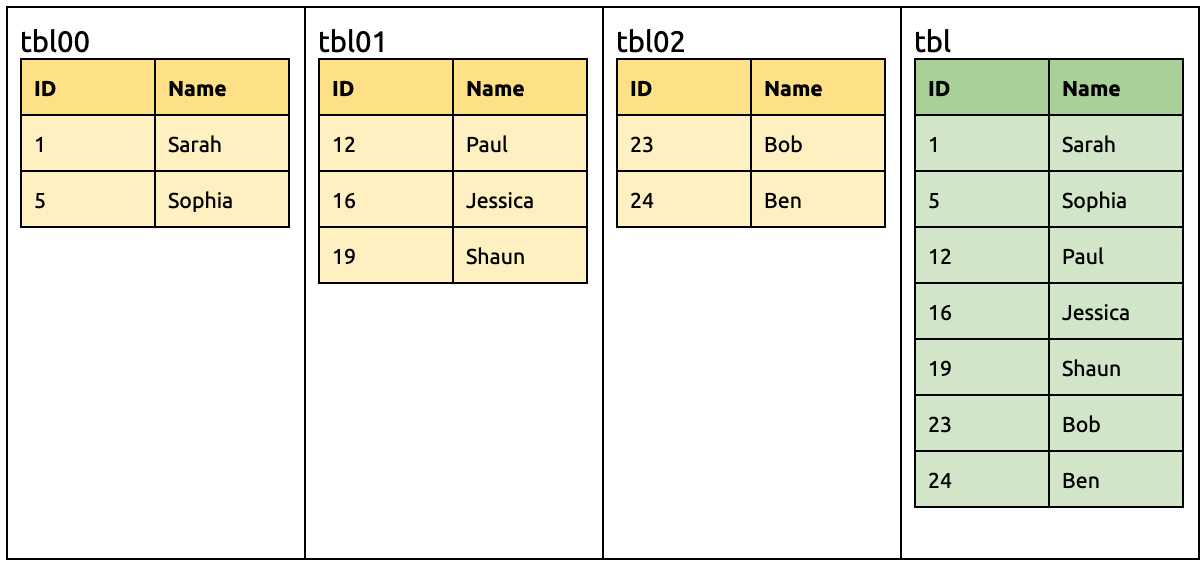
在 tbl01 新增一列 Age,默认值定为 0:
ALTER TABLE `tbl01` ADD COLUMN `Age` INT DEFAULT 0;
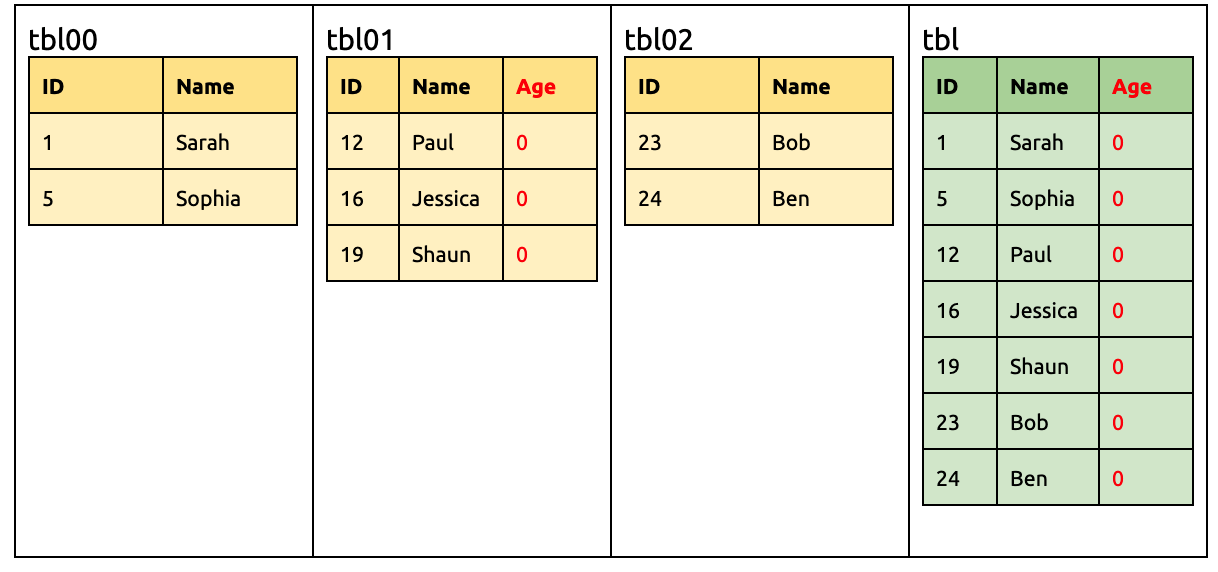
在 tbl00 新增一列 Age,但默认值定为 -1:
ALTER TABLE `tbl00` ADD COLUMN `Age` INT DEFAULT -1;
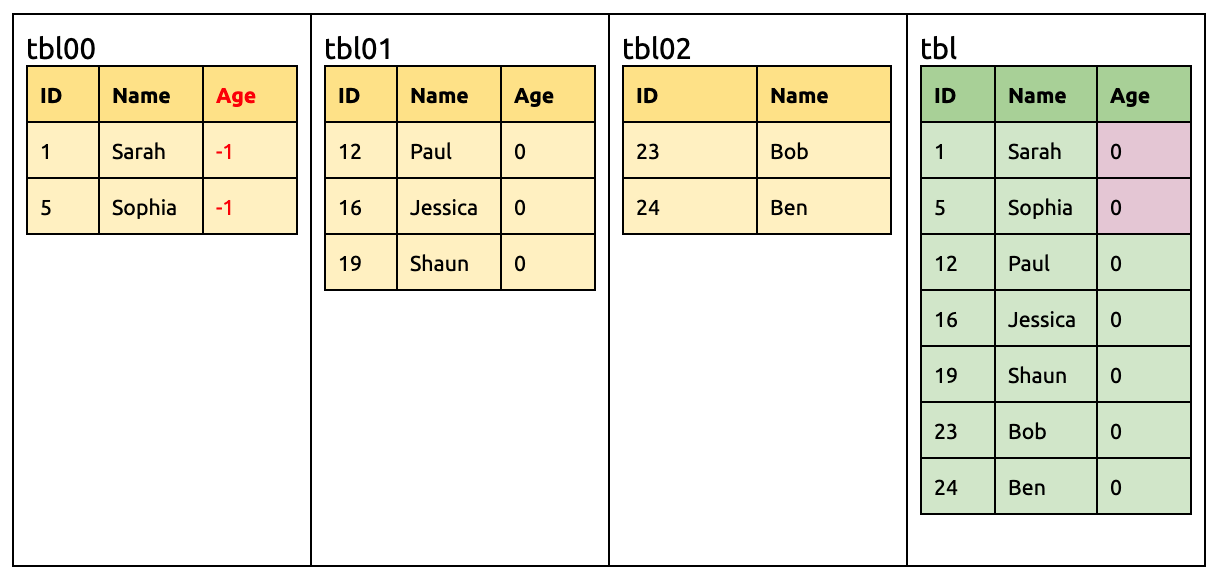
此时所有来自 tbl00 的 Age 都不一致了。这是由于 DEFAULT 0 和 DEFAULT -1 互不兼容。虽然 DM 遇到这种情况会报错,但上下游不一致的问题就需要手动去解决。
原理
在“乐观协调”模式下,DM-worker 接收到来自上游的 DDL 后,会把更新后的表结构转送给 DM-master。DM-worker 会追踪各分表当前的表结构,DM-master 合并成可兼容来自每个分表 DML 的合成结构,然后把与此对应的 DDL 迁移到下游;对于 DML 会直接迁移到下游。
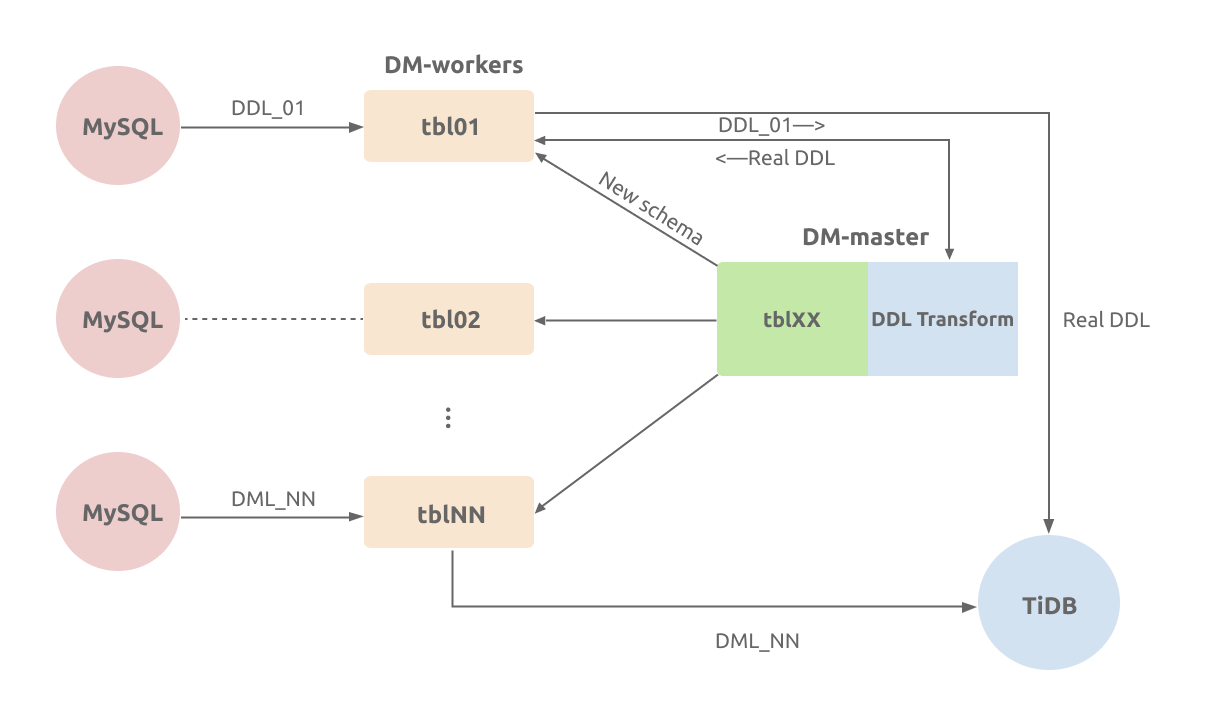
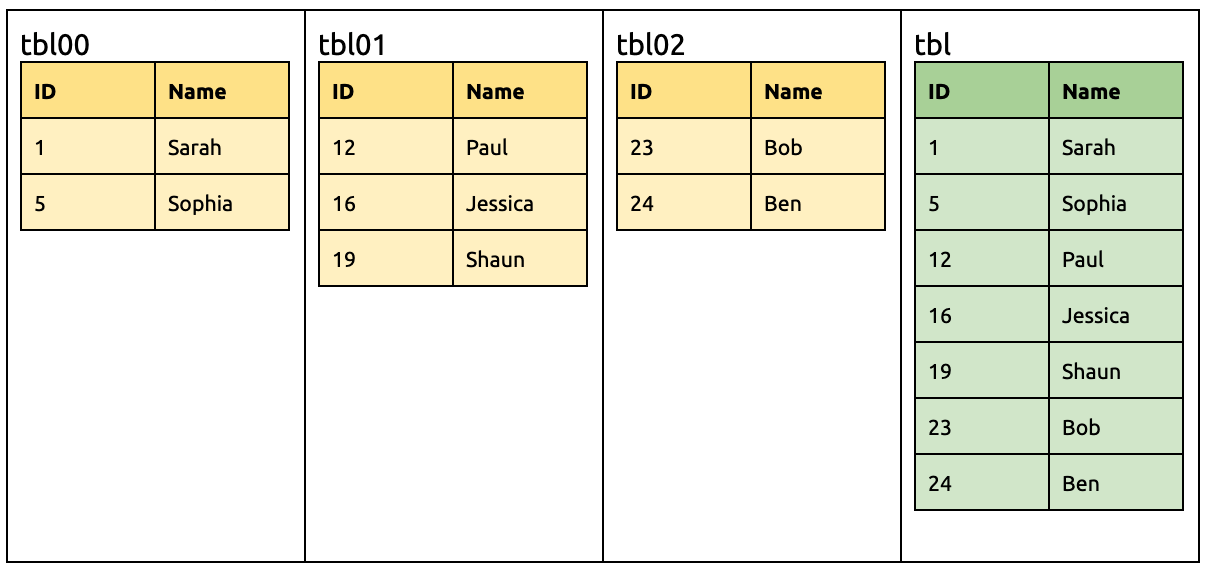
例子
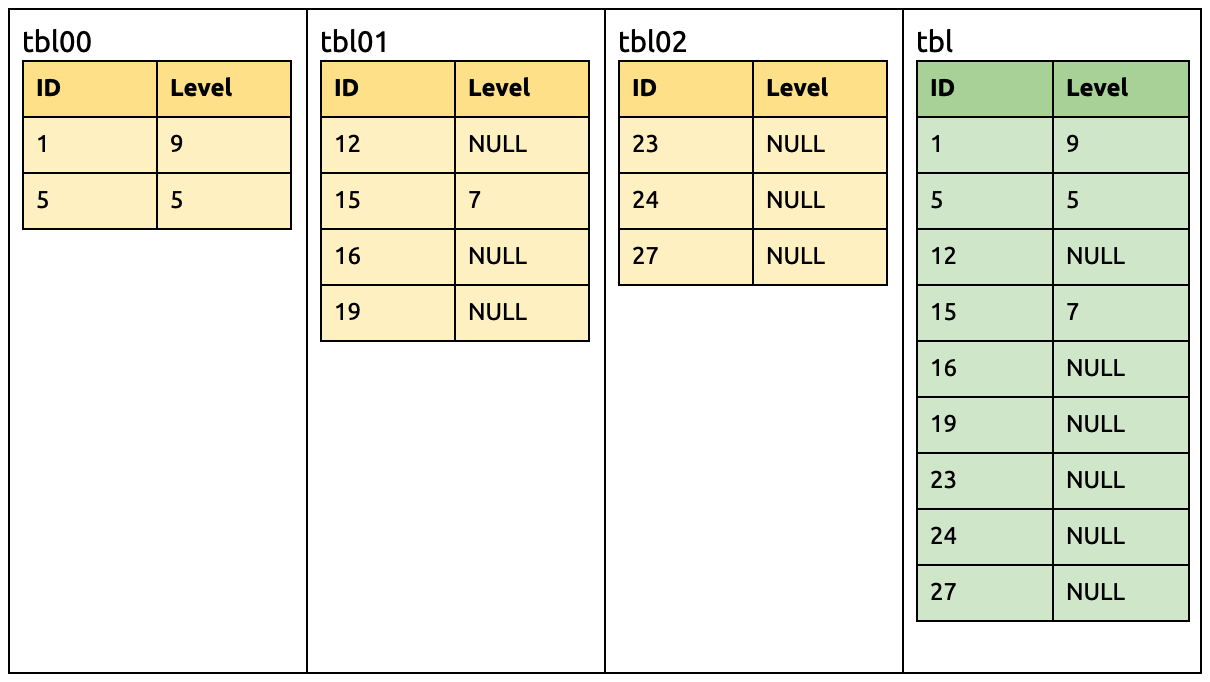
例如上游 MySQL 有三个分表(tbl00, tbl01 以及 tbl02),使用 DM 迁移到下游 TiDB 的 tbl 表中,如下图所示:
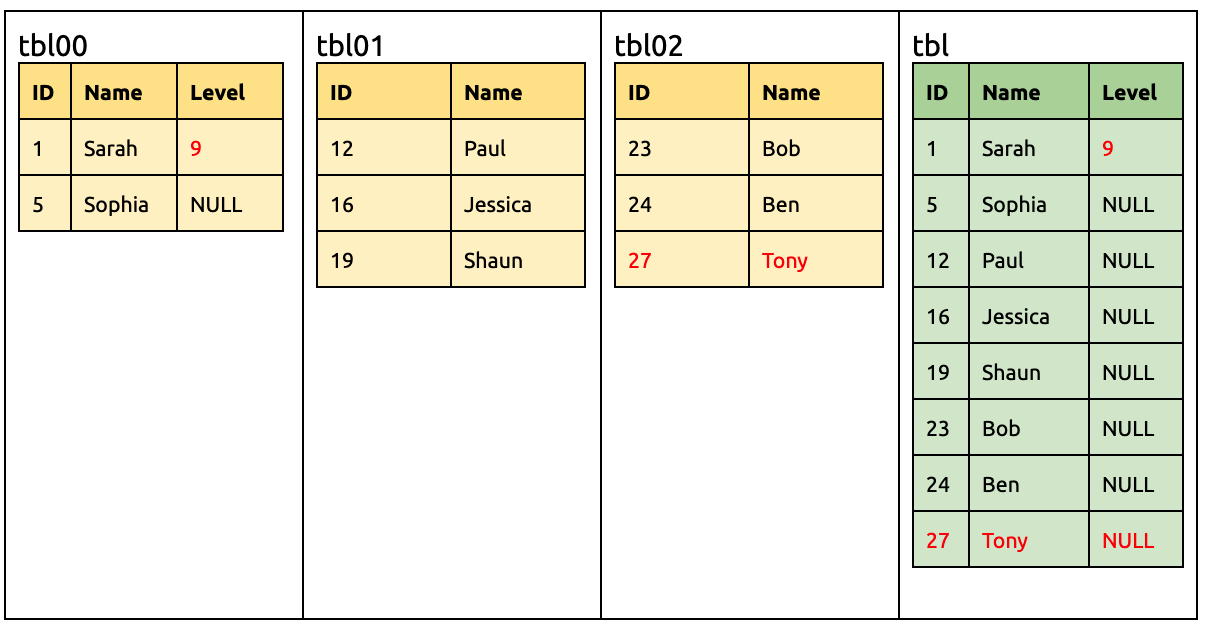
在上游增加一列 Level:
ALTER TABLE `tbl00` ADD COLUMN `Level` INT;
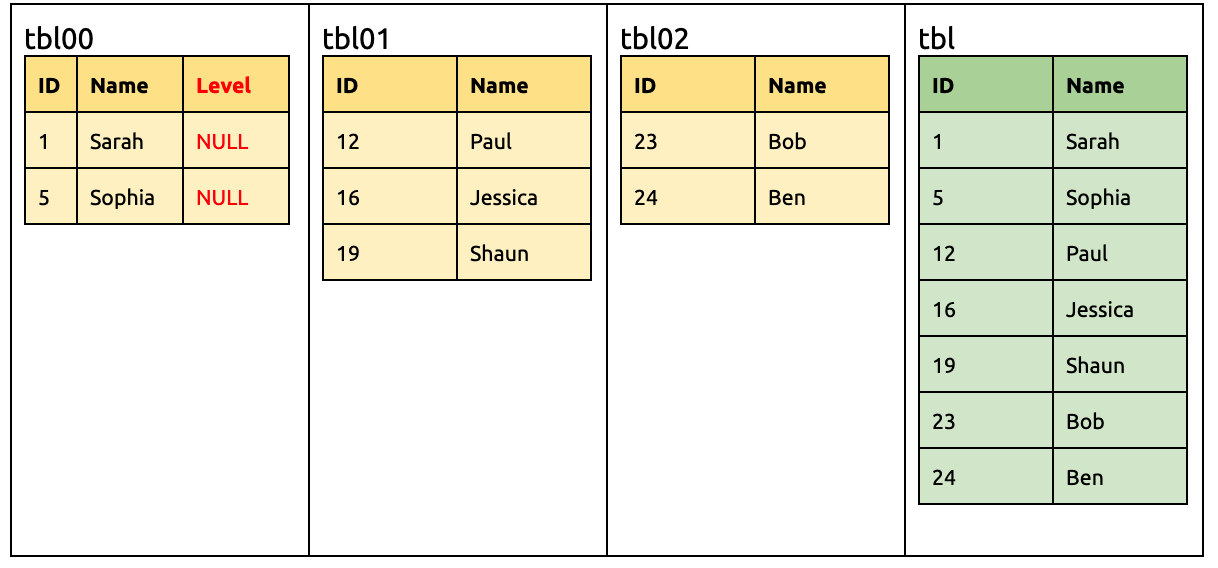
此时下游 TiDB 要准备接受来自 tbl00 有 Level 的 DML、以及来自 tbl01 和 tbl02 没有 Level 的 DML。
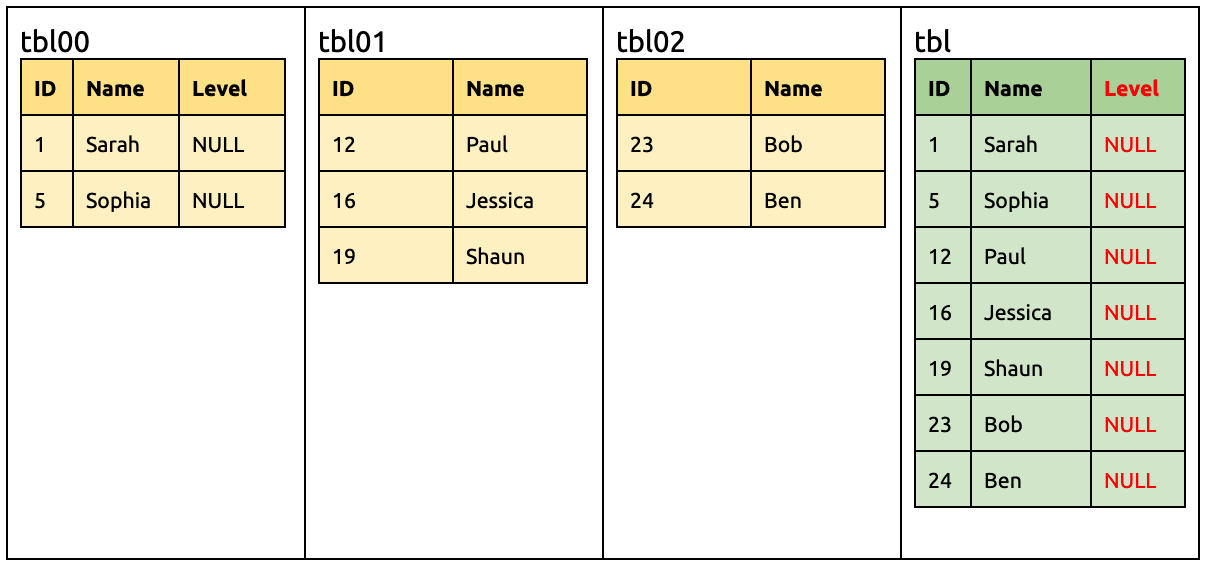
这时候如下的 DML 无需修改就可以迁移到下游:
UPDATE `tbl00` SET `Level` = 9 WHERE `ID` = 1;
INSERT INTO `tbl02` (`ID`, `Name`) VALUES (27, 'Tony');
在 tbl01 同样增加一列 Level:
ALTER TABLE `tbl01` ADD COLUMN `Level` INT;
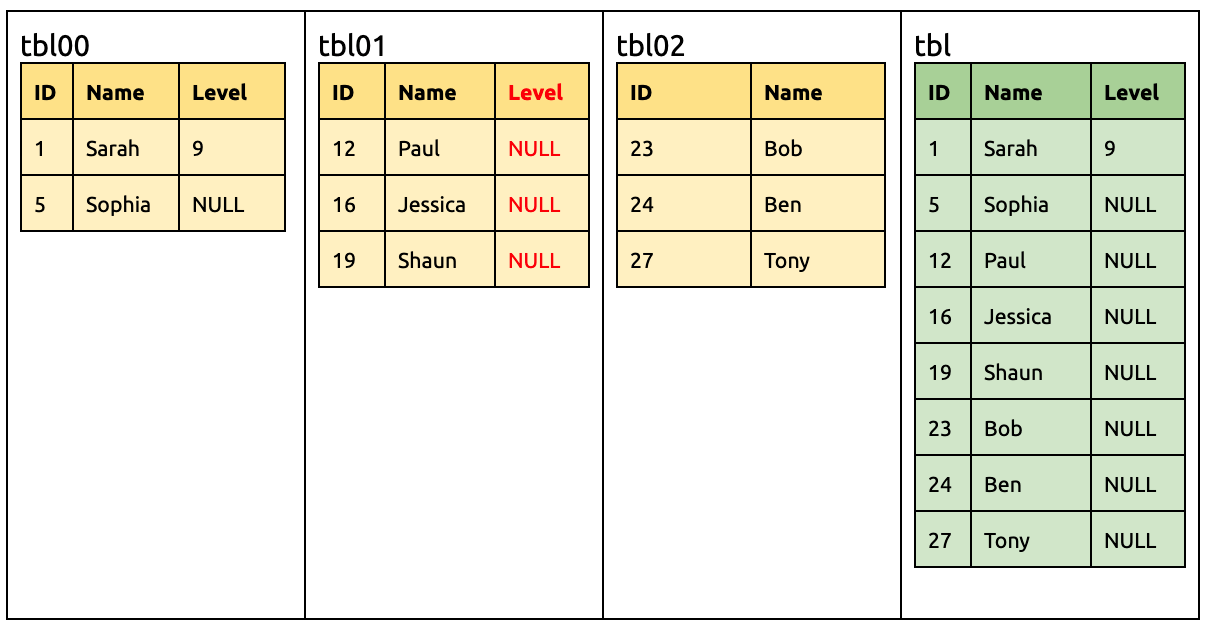
此时下游已经有相同的 Level 列了,所以 DM-master 比较表结构之后不做任何操作。
在 tbl01 刪除一列 Name:
ALTER TABLE `tbl01` DROP COLUMN `Name`;
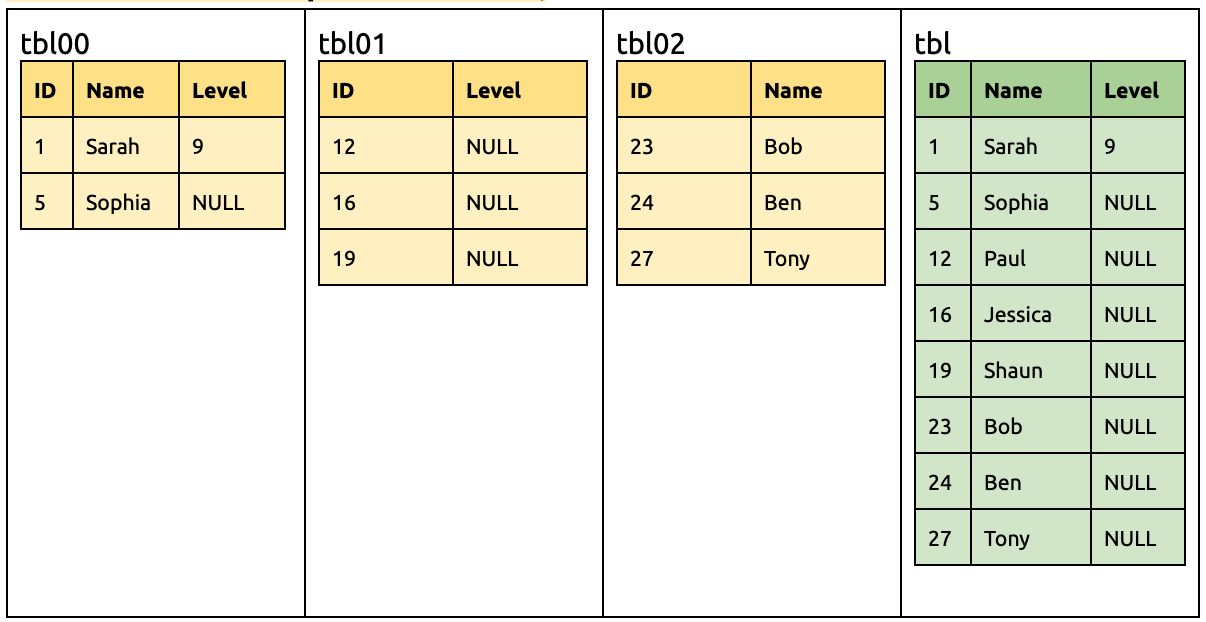
此时下游仍需要接收来自 tbl00 和 tbl02 含 Name 的 DML 语句,因此不会立刻删除该列。
同样,各种 DML 仍可直接迁移到下游:
INSERT INTO `tbl01` (`ID`, `Level`) VALUES (15, 7);
UPDATE `tbl00` SET `Level` = 5 WHERE `ID` = 5;
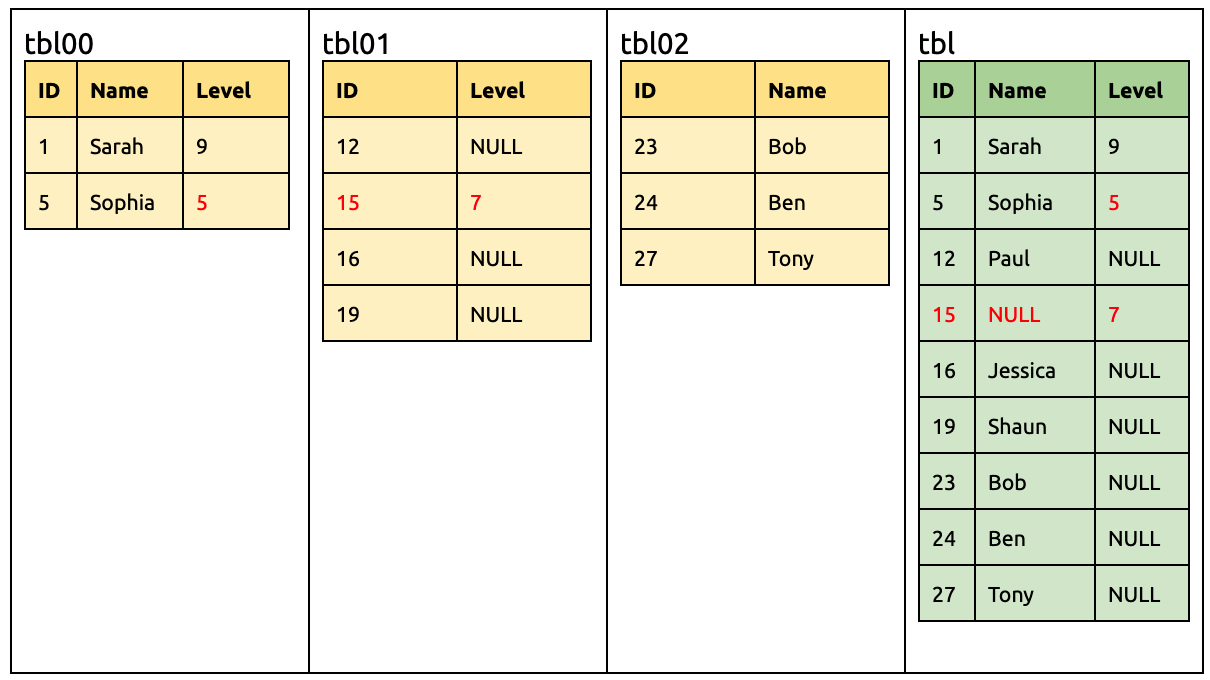
在 tbl02 增加一列 Level:
ALTER TABLE `tbl02` ADD COLUMN `Level` INT;
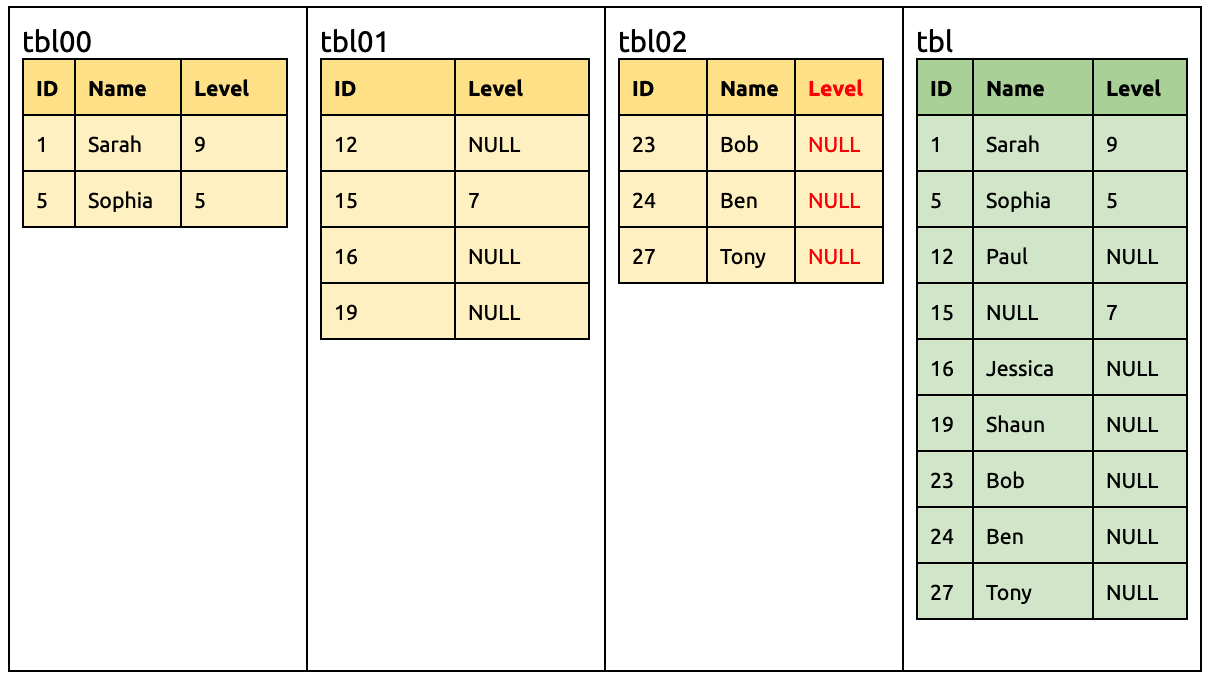
此时所有分表都已有 Level 列。
在 tbl00 和 tbl02 各刪除一列 Name:
ALTER TABLE `tbl00` DROP COLUMN `Name`;
ALTER TABLE `tbl02` DROP COLUMN `Name`;
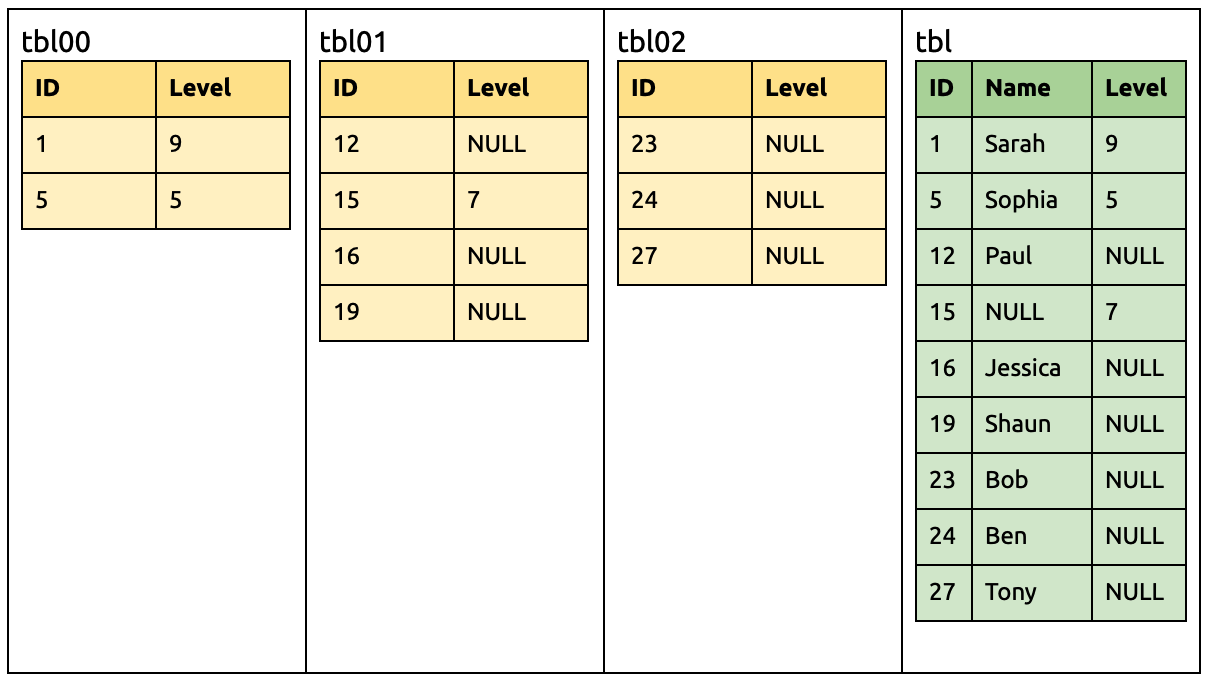
到此步 Name 列也从所有分表消失了,所以可以安全从下游移除:
ALTER TABLE `tbl` DROP COLUMN `Name`;