使用 TiDB Dashboard 诊断报告定位问题
本文介绍如何使用 TiDB Dashboard 诊断报告定位问题。
对比诊断功能示例
对比报告中对比诊断的功能,通过对比两个时间段的监控项差异来尝试帮助 DBA 定位问题。先看以下示例。
大查询/写入导致 QPS 抖动或延迟上升诊断
示例 1
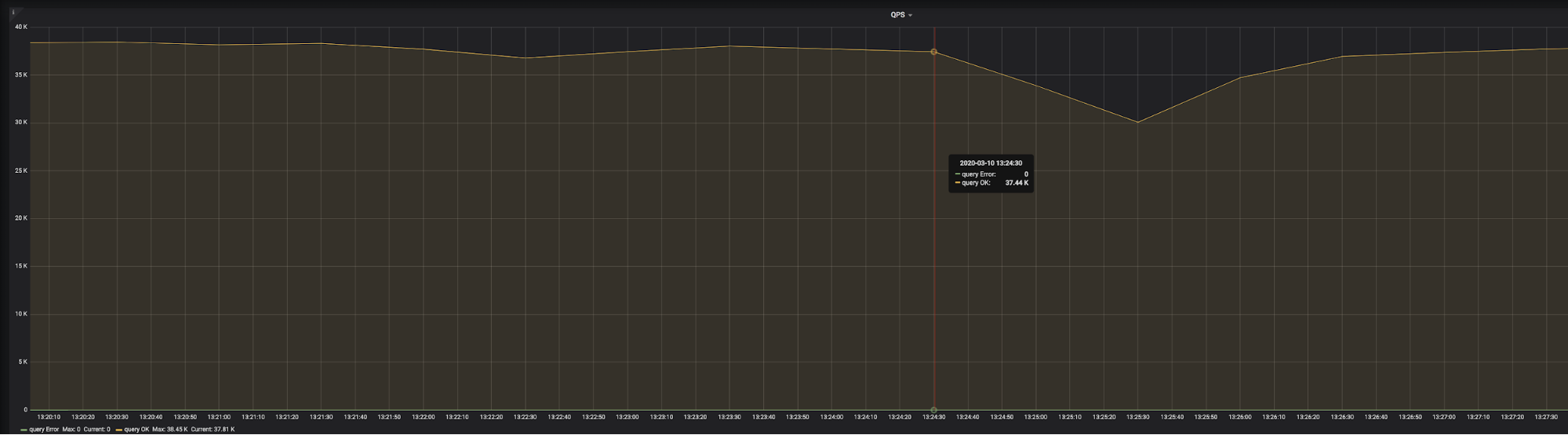
上图是 go-ycsb 压测的监控。可以发现,在 2020-03-10 13:24:30 时,QPS 突然开始下降,3 分钟后,QPS 开始恢复正常。
生成以下两个时间范围的对比报告:
- t1: 2020-03-10 13:21:00 - 2020-03-10 13:23:00,正常时间段,又叫参考时间段。
- t2: 2020-03-10 13:24:30 - 2020-03-10 13:27:30,QPS 开始下降的异常时间段。
这里两个时间间隔都是 3 分钟,因为抖动的影响范围为 3 分钟。因为诊断时会用一些监控的平均值做对比,所有间隔时间太长会导致平均值差异不明显,无法准确定位问题。
生成报告后查看 Compare Diagnose 报表内容如下:
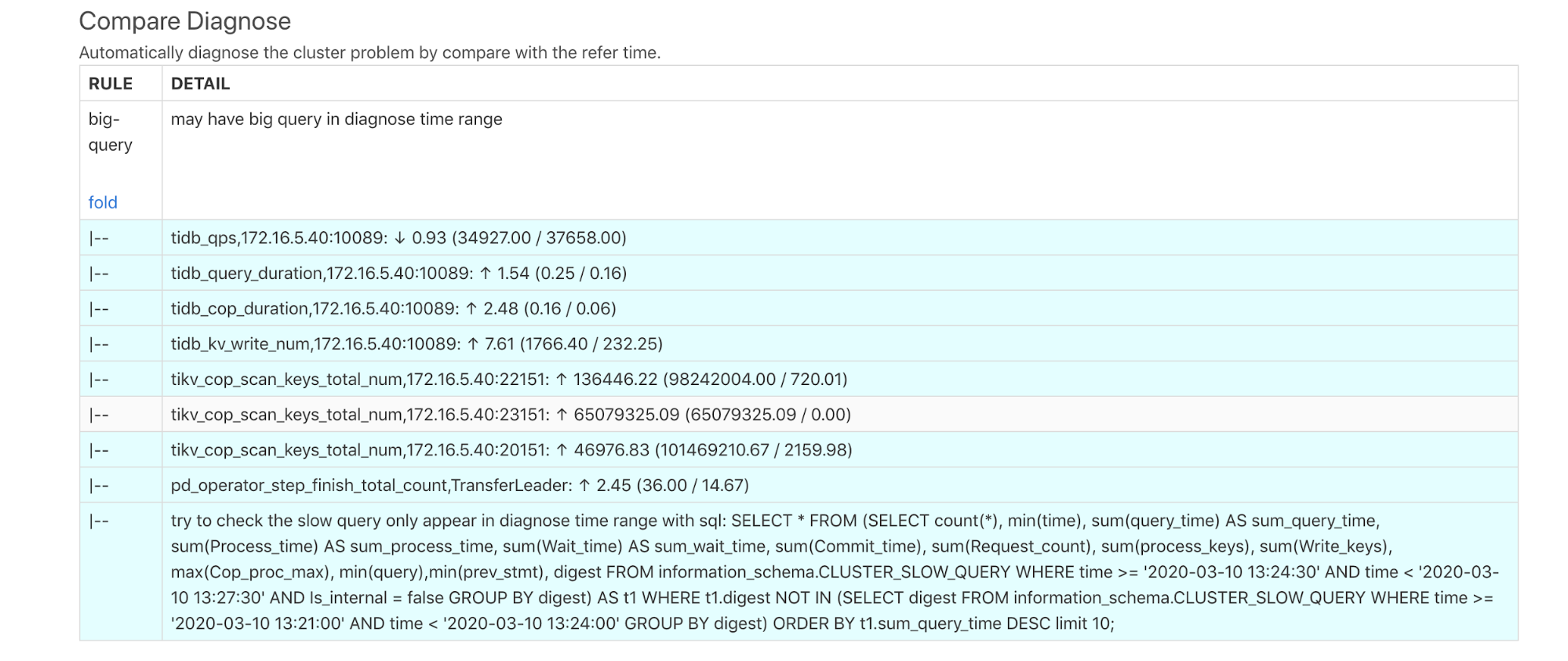
上面诊断结果显示,在诊断的时间内可能有大查询,下面的每一行的含义是:
tidb_qps:QPS 下降 0.93 倍。tidb_query_duration:P999 的查询延迟上升 1.54 倍。tidb_cop_duration:P999 的 COP 请求的处理延迟上升 2.48 倍。tidb_kv_write_num:P999 的 tidb 的事务写入 kv 数量上升 7.61 倍。tikv_cop_scan_keys_total_nun:TiKV 的 coprocessor 扫描 key/value 的数量分别在 3 台 TiKV 上有很大的提升。pd_operator_step_finish_total_count中,transfer leader 的数量上升 2.45 倍,说明异常时间段的调度比正常时间段要高。- 提示可能有慢查询,并提示用 SQL 查询 TiDB 的慢日志。在 TiDB 中执行结果如下:
SELECT * FROM (SELECT count(*), min(time), sum(query_time) AS sum_query_time, sum(Process_time) AS sum_process_time, sum(Wait_time) AS sum_wait_time, sum(Commit_time), sum(Request_count), sum(process_keys), sum(Write_keys), max(Cop_proc_max), min(query),min(prev_stmt), digest FROM information_schema.CLUSTER_SLOW_QUERY WHERE time >= '2020-03-10 13:24:30' AND time < '2020-03-10 13:27:30' AND Is_internal = false GROUP BY digest) AS t1 WHERE t1.digest NOT IN (SELECT digest FROM information_schema.CLUSTER_SLOW_QUERY WHERE time >= '2020-03-10 13:21:00' AND time < '2020-03-10 13:24:00' GROUP BY digest) ORDER BY t1.sum_query_time DESC limit 10\G
***************************[ 1. row ]***************************
count(*) | 196
min(time) | 2020-03-10 13:24:30.204326
sum_query_time | 46.878509117
sum_process_time | 265.924
sum_wait_time | 8.308
sum(Commit_time) | 0.926820886
sum(Request_count) | 6035
sum(process_keys) | 201453000
sum(Write_keys) | 274500
max(Cop_proc_max) | 0.263
min(query) | delete from test.tcs2 limit 5000;
min(prev_stmt) |
digest | 24bd6d8a9b238086c9b8c3d240ad4ef32f79ce94cf5a468c0b8fe1eb5f8d03df
可以发现,从 13:24:30 开始有一个批量删除的大写入,一共执行了 196 次,每次删除 5000 行数据,总共耗时 46.8 秒。
示例 2
如果大查询一直没执行完,就不会记录慢日志,但仍可以进行诊断,示例如下:
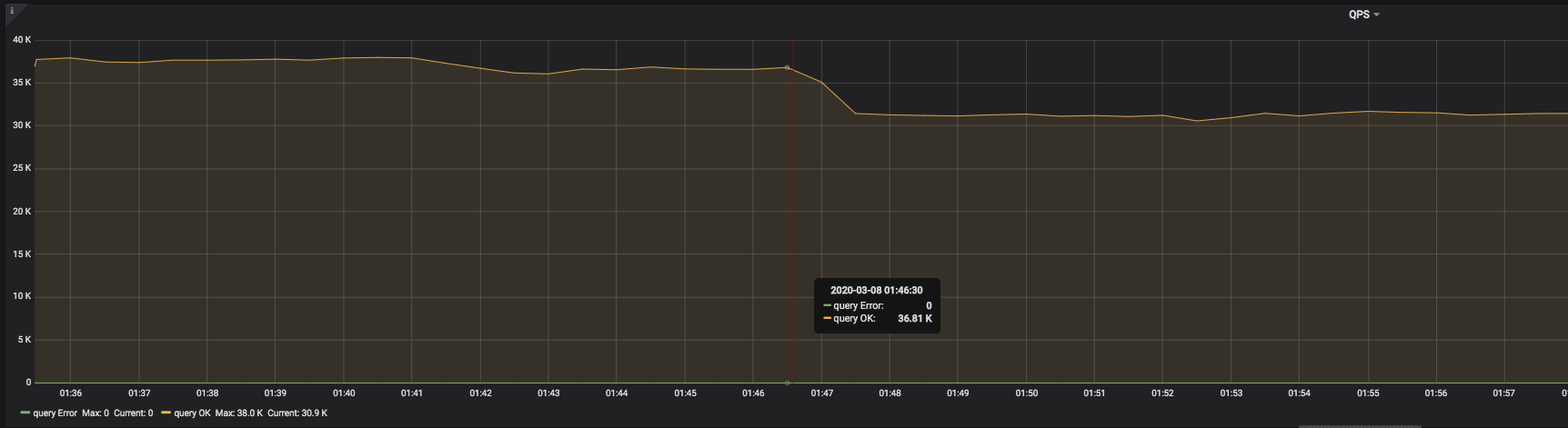
上图中,也是在跑 go-ycsb 的压测。可以发现,在 2020-03-08 01:46:30 时,QPS 突然开始下降,并且一直没有恢复。
生成以下两个时间范围的对比报告:
- t1: 2020-03-08 01:36:00 - 2020-03-08 01:41:00,正常时间段,又叫参考时间段。
- t2: 2020-03-08 01:46:30 - 2020-03-08 01:51:30,QPS 开始下降的异常时间段。
生成报告后看 Compare Diagnose 报表的内容如下:
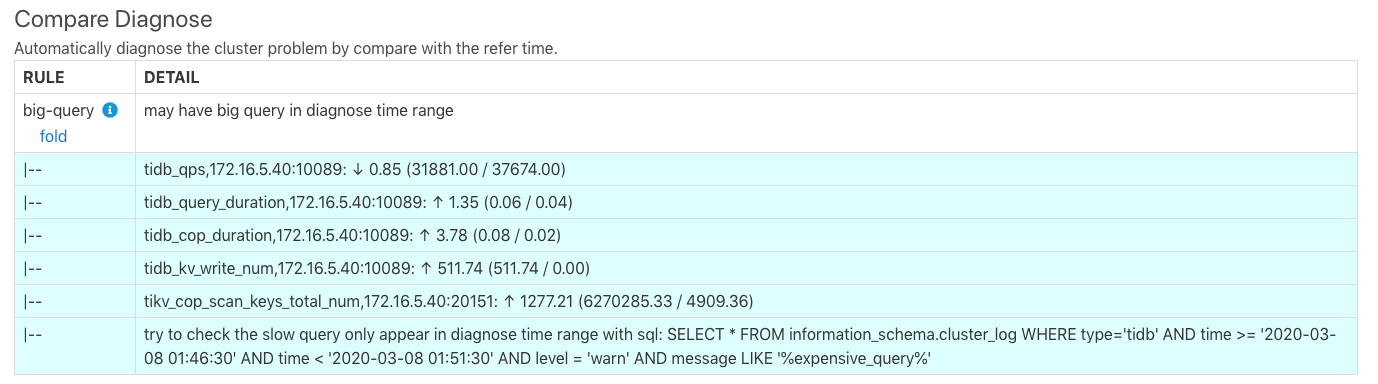
上面诊断结果的最后一行显示可能有慢查询,并提示用 SQL 查询 TiDB 日志中的 expensive query。在 TiDB 中执行结果如下:
> SELECT * FROM information_schema.cluster_log WHERE type='tidb' AND time >= '2020-03-08 01:46:30' AND time < '2020-03-08 01:51:30' AND level = 'warn' AND message LIKE '%expensive_query%'\G
TIME | 2020/03/08 01:47:35.846
TYPE | tidb
INSTANCE | 172.16.5.40:4009
LEVEL | WARN
MESSAGE | [expensivequery.go:167] [expensive_query] [cost_time=60.085949605s] [process_time=2.52s] [wait_time=2.52s] [request_count=9] [total_keys=996009] [process_keys=996000] [num_cop_tasks=9] [process_avg_time=0.28s] [process_p90_time=0.344s] [process_max_time=0.344s] [process_max_addr=172.16.5.40:20150] [wait_avg_time=0.000777777s] [wait_p90_time=0.003s] [wait_max_time=0.003s] [wait_max_addr=172.16.5.40:20150] [stats=t_wide:pseudo] [conn_id=19717] [user=root] [database=test] [table_ids="[80,80]"] [txn_start_ts=415132076148785201] [mem_max="23583169 Bytes (22.490662574768066 MB)"] [sql="select count(*) from t_wide as t1 join t_wide as t2 where t1.c0>t2.c1 and t1.c2>0"]
以上查询结果显示,在 172.16.5.40:4009 这台 TiDB 上,2020/03/08 01:47:35.846 有一个已经执行了 60s 但还没有执行完的 expensive_query。
用对比报告定位问题
诊断有可能是误诊,使用对比报告或许可以帮助 DBA 更快速的定位问题。参考以下示例。

上图中,也是在跑 go-ycsb 的压测,可以发现,在 2020-05-22 22:14:00 时,QPS 突然开始下降,大概在持续 3 分钟后恢复。
生成以下 2 个时间范围的对比报告:
- t1: 2020-05-22 22:11:00 - 2020-05-22 22:14:00,正常时间段。
- t2: 2020-05-22 22:14:00 - 2020-05-22 22:17:00,QPS 开始下降的异常时间段。
生成对比报告后,查看 Max diff item 报表,该报表对比两个时间段的监控项后,按照监控项的差异大小排序,这个表的结果如下:
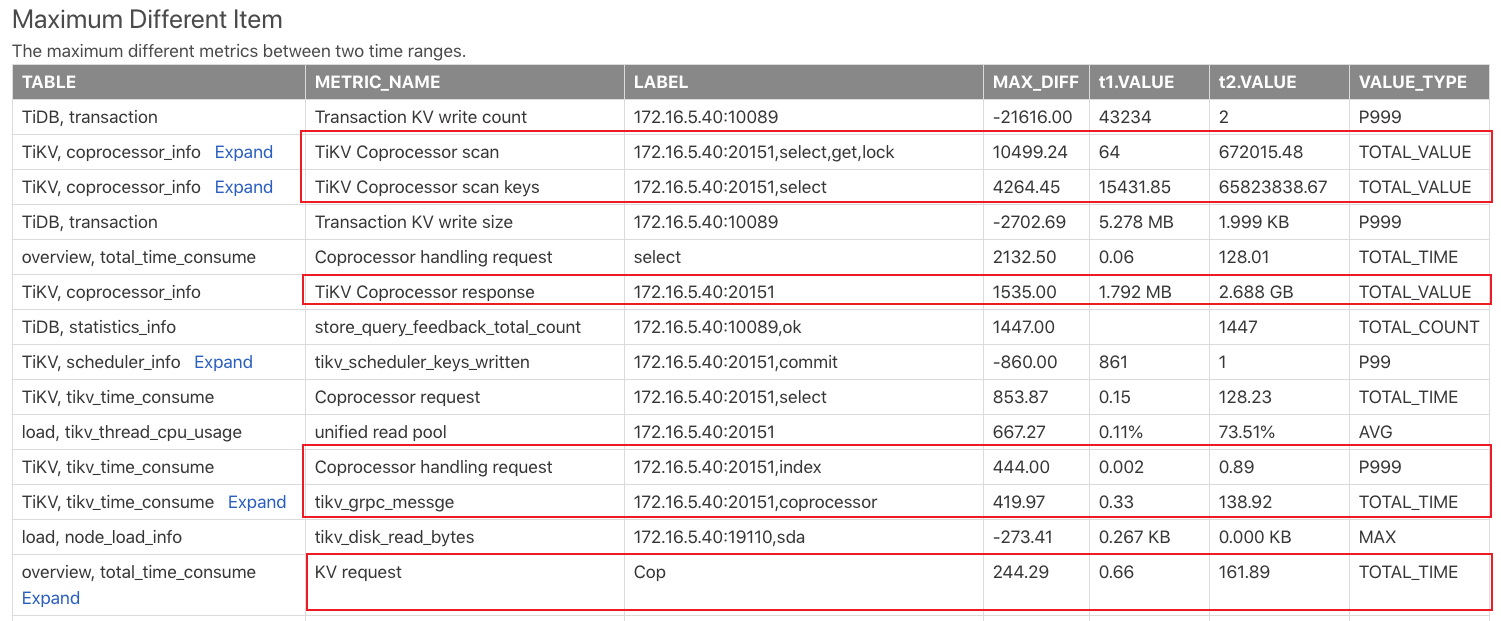
从上面结果可以看出 t2 时间段新增了很多 Coprocessor 请求,可以猜测可能是 t2 时间段出现了一些大查询,或者是查询较多的负载。
实际上,在 t1 - t2 整个时间段内都在进行 go-ycsb 的压测,然后在 t2 时间段跑了 20 个 tpch 的查询,所以是因为 tpch 大查询导致了出现很多的 cop 请求。
这种大查询执行时间超过慢日志的阈值后也会记录在慢日志里面,可以继续查看 Slow Queries In Time Range t2 报表查看是否有一些慢查询。一些在 t1 时间段存在的查询,可能在 t2 时间段内就变成了慢查询,是因为 t2 时间段的其他负载影响导致该查询的执行变慢。