单区域双 AZ 部署 TiDB
本文介绍单区域双可用区 (Availability Zone, AZ) 的部署模式,包括方案架构、示例配置、副本方法及启用该模式的方法。
本文中的区域指的是地理隔离的不同位置,AZ 指的是区域内部划分的相互独立的资源集合,本文所描述的方案同样适用于同一城市两个数据中心(同城双中心)的场景。
简介
TiDB 通常采用多 AZ 部署方案保证集群高可用和容灾能力。多 AZ 部署方案包括单区域多 AZ 部署模式、双区域多 AZ 部署模式等多种部署模式。本文介绍单区域双 AZ 部署方案,即在同一区域部署两个 AZ,成本更低,同样能满足高可用和容灾要求。该部署方案采用自适应同步模式,即 Data Replication Auto Synchronous,简称 DR Auto-Sync。
单区域双 AZ 部署方案下,两个 AZ 通常位于同一个城市或两个相邻城市(例如北京和廊坊),相距 50 km 以内,AZ 间的网络连接延迟小于 1.5 ms,带宽大于 10 Gbps。
部署架构
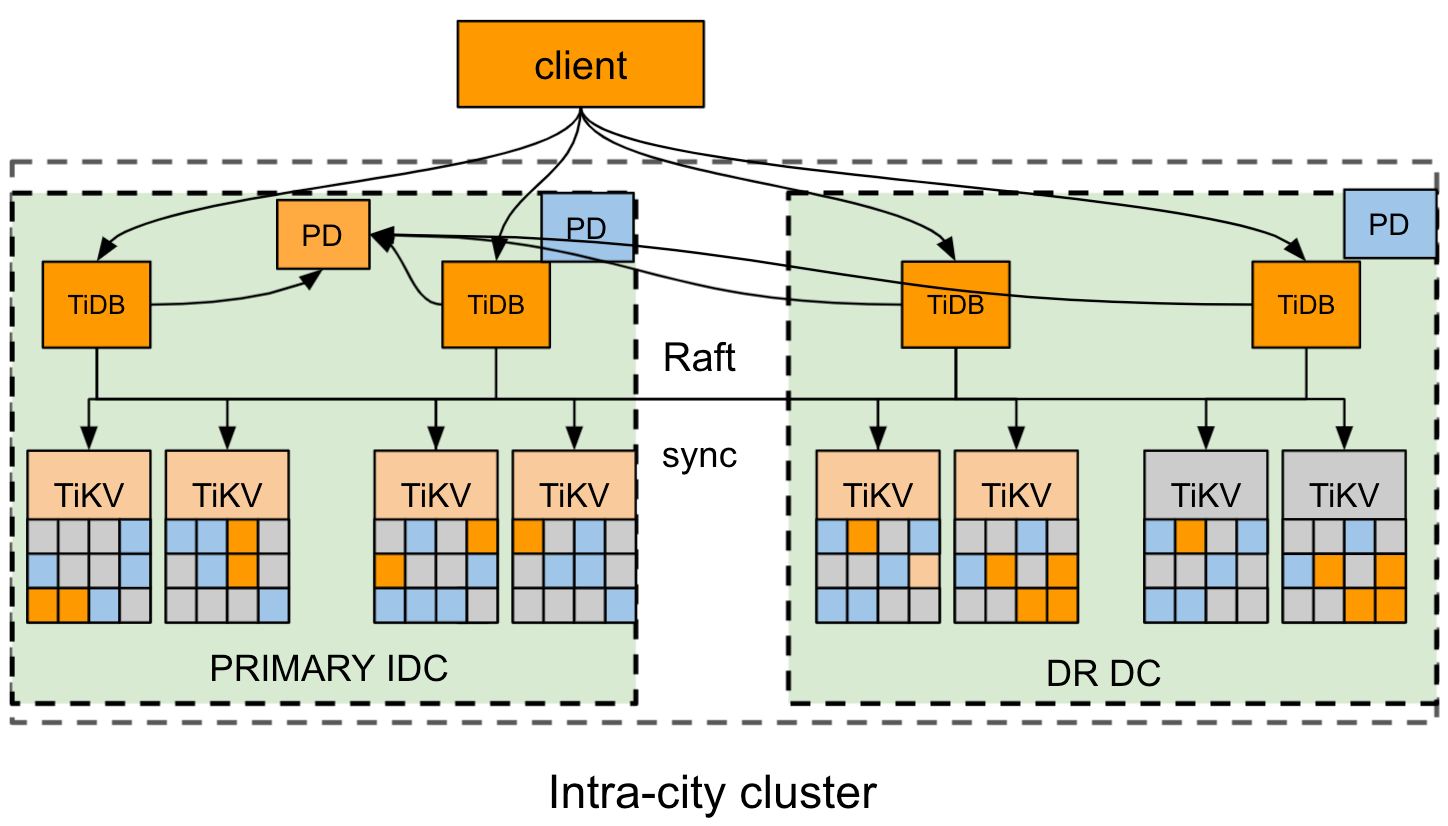
本文以某市为例,市里有两个 AZ,AZ1 和 AZ2,AZ1 为主用区域,AZ2 为从属区域,分别位于城东和城西。
下图为集群部署架构图,具体如下:
- 集群采用推荐的 6 副本模式,其中 AZ1 中放 3 个 Voter,AZ2 中放 2 个 Follower 副本和 1 个 Learner 副本。TiKV 按机房的实际情况打上合适的 Label。
- 副本间通过 Raft 协议保证数据的一致性和高可用,对用户完全透明。
该部署方案定义了三种状态来控制和标示集群的同步状态,该状态约束了 TiKV 的同步方式。集群的复制模式可以自动在三种状态之间自适应切换。要了解切换过程,请参考状态转换。
- sync:同步复制模式,此时从 AZ (DR) 至少有一个副本与主 AZ (PRIMARY) 进行同步,Raft 算法保证每条日志按 Label 同步复制到 DR。
- async:异步复制模式,此时不保证 DR 与 PRIMARY 完全同步,Raft 算法使用经典的 majority 方式复制日志。
- sync-recover:恢复同步,此时不保证 DR 与 PRIMARY 完全同步,Raft 逐步切换成 Label 复制,切换成功后汇报给 PD。
配置
示例
以下 tiup topology.yaml 示例拓扑文件为单区域双 AZ 典型的拓扑配置:
# # Global variables are applied to all deployments and used as the default value of
# # the deployments if a specific deployment value is missing.
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/data/tidb_cluster/tidb-deploy"
data_dir: "/data/tidb_cluster/tidb-data"
server_configs:
pd:
replication.location-labels: ["az","rack","host"]
pd_servers:
- host: 10.63.10.10
name: "pd-10"
- host: 10.63.10.11
name: "pd-11"
- host: 10.63.10.12
name: "pd-12"
tidb_servers:
- host: 10.63.10.10
- host: 10.63.10.11
- host: 10.63.10.12
tikv_servers:
- host: 10.63.10.30
config:
server.labels: { az: "east", rack: "east-1", host: "30" }
- host: 10.63.10.31
config:
server.labels: { az: "east", rack: "east-2", host: "31" }
- host: 10.63.10.32
config:
server.labels: { az: "east", rack: "east-3", host: "32" }
- host: 10.63.10.33
config:
server.labels: { az: "west", rack: "west-1", host: "33" }
- host: 10.63.10.34
config:
server.labels: { az: "west", rack: "west-2", host: "34" }
- host: 10.63.10.35
config:
server.labels: { az: "west", rack: "west-3", host: "35" }
monitoring_servers:
- host: 10.63.10.60
grafana_servers:
- host: 10.63.10.60
alertmanager_servers:
- host: 10.63.10.60
Placement Rules 规划
为了按照规划的集群拓扑进行部署,你需要使用 Placement Rules 来规划集群副本的放置位置。以 6 副本(3 个 Voter 副本在主 AZ,2 个 Follower 副本和 1 个 Learner 副本在从 AZ)的部署方式为例,可使用 Placement Rules 进行如下副本配置:
cat rule.json
[
{
"group_id": "pd",
"group_index": 0,
"group_override": false,
"rules": [
{
"group_id": "pd",
"id": "az-east",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 3,
"label_constraints": [
{
"key": "az",
"op": "in",
"values": [
"east"
]
}
],
"location_labels": [
"az",
"rack",
"host"
]
},
{
"group_id": "pd",
"id": "az-west-1",
"start_key": "",
"end_key": "",
"role": "follower",
"count": 2,
"label_constraints": [
{
"key": "az",
"op": "in",
"values": [
"west"
]
}
],
"location_labels": [
"az",
"rack",
"host"
]
},
{
"group_id": "pd",
"id": "az-west-2",
"start_key": "",
"end_key": "",
"role": "learner",
"count": 1,
"label_constraints": [
{
"key": "az",
"op": "in",
"values": [
"west"
]
}
],
"location_labels": [
"az",
"rack",
"host"
]
}
]
}
]
如果需要使用 rule.json 中的配置,你可以使用以下命令把原有的配置备份到 default.json 文件,再使用 rule.json 中的配置覆盖原有配置:
pd-ctl config placement-rules rule-bundle load --out="default.json"
pd-ctl config placement-rules rule-bundle save --in="rule.json"
如果需要回退配置,你可以还原备份的 default.json 文件或者手动编写如下的 json 文件并将其覆盖到现有的配置文件中:
cat default.json
[
{
"group_id": "pd",
"group_index": 0,
"group_override": false,
"rules": [
{
"group_id": "pd",
"id": "default",
"start_key": "",
"end_key": "",
"role": "voter",
"count": 5
}
]
}
]
启用自适应同步模式
副本的复制模式由 PD 节点控制。如果要使用 DR Auto-sync 自适应同步模式,需要按照以下任一方法修改 PD 的配置。
方法一:先配置 PD 的配置文件,然后部署集群。
[replication-mode] replication-mode = "dr-auto-sync" [replication-mode.dr-auto-sync] label-key = "az" primary = "east" dr = "west" primary-replicas = 3 dr-replicas = 2 wait-store-timeout = "1m" wait-recover-timeout = "0s" pause-region-split = false方法二:如果已经部署了集群,则使用 pd-ctl 命令修改 PD 的配置。
config set replication-mode dr-auto-sync config set replication-mode dr-auto-sync label-key az config set replication-mode dr-auto-sync primary east config set replication-mode dr-auto-sync dr west config set replication-mode dr-auto-sync primary-replicas 3 config set replication-mode dr-auto-sync dr-replicas 2
配置项说明:
replication-mode为待启用的复制模式,以上示例中设置为dr-auto-sync。默认使用 majority 算法。label-key用于区分不同的 AZ,需要和 Placement Rules 相匹配。其中主 AZ 为 "east",从 AZ 为 "west"。primary-replicas是主 AZ 上 Voter 副本的数量。dr-replicas是从 AZ 上 Voter 副本的数量。wait-store-timeout是当出现网络隔离或者故障时,切换到异步复制模式的等待时间。如果超过这个时间还没恢复,则自动切换到异步复制模式。默认时间为 60 秒。wait-recover-timeout是当网络恢复后,切换回sync-recover状态的等待时间。默认为 0 秒。pause-region-split用于控制在async_wait和async状态下是否暂停 Region 的 split 操作。暂停 Region split 可以防止在sync-recover状态同步数据时从属 AZ 出现短暂的部分数据缺失。默认为false。
如果需要检查当前集群的复制状态,可以通过以下 API 获取:
curl http://pd_ip:pd_port/pd/api/v1/replication_mode/status
{
"mode": "dr-auto-sync",
"dr-auto-sync": {
"label-key": "az",
"state": "sync"
}
}
状态转换
简单来讲,集群的复制模式可以自动在三种状态之间自适应的切换:
- 当集群一切正常时,会进入同步复制模式来最大化地保障灾备 AZ 的数据完整性。
- 当 AZ 网络断连或灾备 AZ 发生整体故障时,在经过一段提前设置好的保护窗口之后,集群会进入异步复制状态,来保障业务的可用性。
- 当 AZ 网络重连或灾备 AZ 整体恢复之后,灾备 AZ 的 TiKV 节点会重新加入到集群,逐步同步数据并最终转为同步复制模式。
状态转换的细节过程如下:
初始化:集群在初次启动时处于 sync(同步复制)模式,PD 会下发信息给 TiKV,所有 TiKV 节点会严格按照 sync 模式的要求进行工作。
同步切异步:PD 通过定时检查 TiKV 的心跳信息来判断 TiKV 是否宕机或断连。如果宕机数超过 Primary 和 DR 各自副本的数量
primary-replicas和dr-replicas,意味着无法完成同步复制,需要切换状态。当宕机时间超过了wait-store-timeout设定的时间,PD 将集群状态切换成 async(异步复制)模式。然后 PD 再将 async 状态下发到所有 TiKV 节点,TiKV 的复制模式由双 AZ 同步方式转为原生的 Raft 大多数落实方式 (majority)。异步切同步:PD 通过定时检查 TiKV 的心跳信息来判断 TiKV 是否恢复连接,如果宕机数小于 Primary 和 DR 各自副本的数量,意味着可以切回同步。PD 会将集群复制状态先切换至 sync-recover,再将该状态下发给所有 TiKV 节点。TiKV 的所有 Region 逐步切换成双 AZ 同步复制模式,切换成功后通过心跳将状态同步信息给 PD。PD 记录 TiKV 上 Region 的状态并统计恢复进度。当 TiKV 的所有 Region 都完成了同步复制模式的切换,PD 将集群复制状态切换为 sync。
灾难恢复
本节介绍单区域双 AZ 部署提供的容灾恢复方案。
当处于同步复制状态的集群发生了灾难,可进行 RPO = 0 的数据恢复:
如果主 AZ 发生故障,丢失了大多数 Voter 副本,但是从 AZ 有完整的数据,可在从 AZ 恢复数据。此时需要人工介入,通过专业工具恢复。如需获取支持,请联系我们。
如果从 AZ 发生故障,丢失了少数 Voter 副本,能自动切换成 async 异步复制模式。
当不处于同步复制状态的集群发生了灾难,不能保证满足 RPO = 0 进行数据恢复:
- 如果丢失了大多数 Voter 副本,需要人工介入,通过专业工具恢复(恢复方式请联系 TiDB 团队)。