TiDB 日志备份与 PITR 功能架构
本文以使用 BR 工具进行备份与恢复为例,介绍 TiDB 集群日志备份与 Point-in-time recovery (PITR) 的架构设计与流程。
架构设计
日志备份和 PITR 的架构如下:
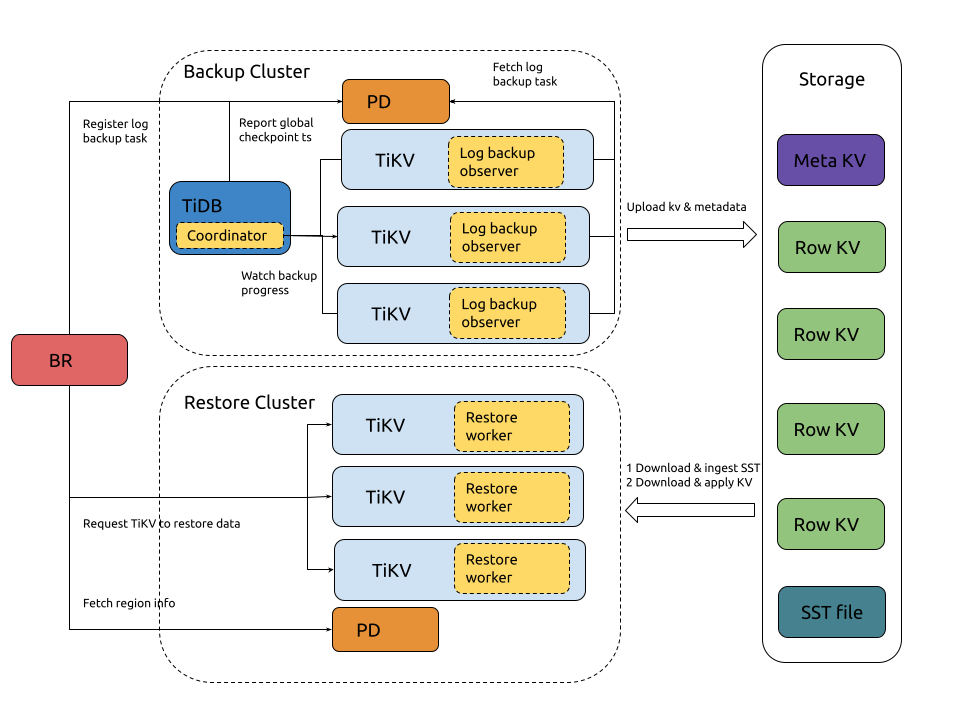
日志备份
日志备份的流程如下:

系统组件和关键概念:
- local metadata:表示单 TiKV 节点备份下来的数据元信息,主要包括:local checkpoint ts、global checkpoint ts、备份文件信息。
- local checkpoint ts (in local metadata):表示这个 TiKV 中所有小于 local checkpoint ts 的日志数据已经备份到目标存储。
- global checkpoint ts:表示所有 TiKV 中小于 global checkpoint ts 的日志数据已经备份到目标存储。它由运行在 TiDB 中的 Coordinator 模块收集所有 TiKV 的 local checkpoint ts 计算所得,然后上报给 PD。
- TiDB Coordinator 组件:TiDB 集群的某个节点会被选举为 Coordinator,负责收集和计算整个日志备份任务的进度 (global checkpoint ts)。该组件设计上无状态,在其故障后可以从存活的 TiDB 节点中重新选出一个节点作为 Coordinator。
- TiKV log observer 组件:运行在 TiDB 集群的每个 TiKV 节点,负责从 TiKV 读取和备份日志数据。TiKV 节点故障的话,该节点负责备份数据范围,在 Region 重新选举后,会被其他 TiKV 节点负责,这些节点会从 global checkpoint ts 重新备份故障范围的数据。
完整的备份交互流程描述如下:
BR 接收备份命令
br log start。- 解析获取日志备份任务的 checkpoint ts(日志备份起始位置)、备份存储地址。
- Register log backup task:在 PD 注册日志备份任务 (log backup task)。
TiKV 监控日志备份任务的创建与更新。
- Fetch log backup task:每个 TiKV 节点的 log backup observer 监听 PD 中日志备份任务的创建与更新,然后备份该节点上在备份范围内的数据。
TiKV log backup observer 持续地备份 KV 变更日志。
- Read kv change data:读取 kv 数据变更,然后保存到自定义格式的备份文件中。
- Fetch global checkpoint ts:定期从 PD 查询 global checkpoint ts。
- Generate local metadata:定期生成 local metadata(包含 local checkpoint ts、global checkpoint ts、备份文件信息)。
- Upload log data & metadata:定期将日志备份数据和 local metadata 上传到备份存储中。
- Configure GC:请求 PD 阻止未备份的数据(大于 local checkpoint ts)被 TiDB GC 机制回收掉。
TiDB Coordinator 监控日志备份进度。
- Watch backup progress:轮询所有 TiKV 节点,获取各个 Region 的备份进度 (Region checkpoint ts)。
- Report global checkpoint ts:根据各个 Region checkpoint ts,计算整个日志备份任务的进度 (global checkpoint ts),然后上报给 PD。
PD 持久化日志备份任务状态。可以通过
br log status查询。
PITR
PITR 的流程如下:
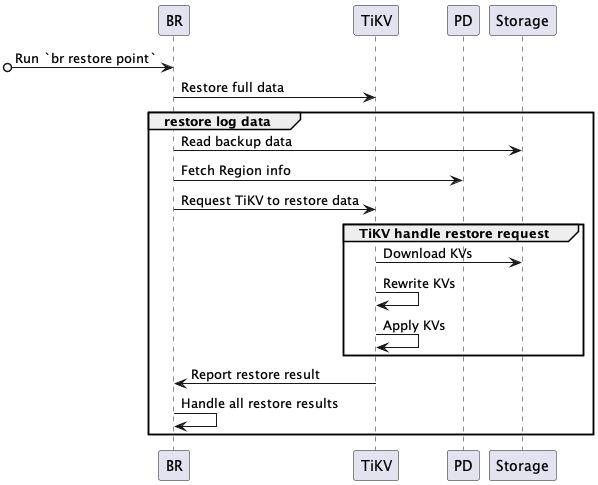
完整的 PITR 交互流程描述如下:
BR 接收恢复命令
br restore point。- 解析获取全量备份数据地址、日志备份数据地址、恢复到的时间点。
- 查询备份数据中恢复数据对象(database 或 table),并检查要恢复的表是否存在并符合要求。
BR 恢复全量备份。
- 进行快照备份数据恢复,恢复流程参考恢复快照备份数据。
BR 恢复日志备份。
- Read backup data:读取日志备份数据,计算需要恢复的日志备份数据。
- Fetch Region info:访问 PD,获取所有 Region 和 KV range 的对应关系。
- Request TiKV to restore data:创建日志恢复请求,发送到对应的 TiKV,日志恢复请求包含要恢复的日志备份数据信息。
TiKV 接受 BR 的恢复请求,初始化 log restore worker。
- log restore worker 获取需要恢复的日志备份数据。
TiKV 恢复日志备份数据。
- Download KVs:log restore worker 根据日志恢复请求中要恢复的备份数据,从备份存储中下载相应的备份数据到本地。
- Rewrite KVs:log restore worker 根据恢复集群表的 table ID 对备份数据的 kv 进行重写 —— 将原有的 kv 编码中的 table ID 替换为新创建的 table ID。对 index ID,log restore worker 也进行相同的处理。
- Apply KVs:log restore worker 将处理好的 kv 通过 raft 接口写入 store (RocksDB) 中。
- Report restore result:log restore worker 返回恢复结果给 BR。
BR 从各个 TiKV 获取恢复结果。
- 如果局部数据恢复因为
RegionNotFound或EpochNotMatch等原因失败,比如 TiKV 节点故障,BR 重试恢复这些数据。 - 如果存在备份数据不可重试的恢复失败,则恢复任务失败。
- 全部备份数据都恢复成功后,则恢复任务成功。
- 如果局部数据恢复因为
日志备份文件
日志备份会产生如下类型文件:
{flushTs}-{minDefaultTs}-{minTs}-{maxTs}.meta文件:每个 TiKV 节点每次上传日志备份数据时会生成一个该文件,保存本次上传的所有日志备份数据文件。文件名中的字段含义请参考备份文件目录结构。{store_id}.ts文件:每个 TiKV 节点每次上传日志备份数据时会使用 global checkpoint ts 更新该文件。其中{store_id}是 TiKV 的 store ID。{min_ts}-{uuid}.log文件:存储备份下来的 kv 数据变更记录。其中{min_ts}是该文件中所有 kv 数据变更记录数对应的最小 ts;{uuid}是在生成该文件时随机生成的。v1_stream_truncate_safepoint.txt文件:保存最近一次通过br log truncate删除日志备份数据后,存储中最早的日志备份数据对应的 ts。
备份文件目录结构
.
├── v1
│ ├── backupmeta
│ │ ├── ...
│ │ └── {flushTs}-{minDefaultTs}-{minTs}-{maxTs}.meta
│ ├── global_checkpoint
│ │ └── {store_id}.ts
│ └── {date}
│ └── {hour}
│ └── {store_id}
│ ├── ...
│ └── {min_ts}-{uuid}.log
└── v1_stream_truncate_safepoint.txt
备份文件目录结构的说明如下:
backupmeta目录:存储备份的元数据文件。从 v8.5.3 和 v9.0.0 起,该文件命名格式从{resolved_ts}-{uuid}.meta修改为{flushTs}-{minDefaultTs}-{minTs}-{maxTs}.meta。文件名中包含以下时间戳字段:flushTs:该备份文件被定期上传至外部存储的时间戳。该值从 PD 获取,具有全局唯一性。minDefaultTs:仅针对 Write CF 文件,表示该备份所覆盖的最早事务起始时间。minTs和maxTs:该备份文件内包含的所有 key-value 数据的最小时间戳和最大时间戳。这些时间戳均采用 16 位固定长度的十六进制字符串编码,左侧补零以保证长度一致。这样的编码设计可以确保文件名按照字典序自然排序,方便在外部存储系统中高效执行批量列举和范围过滤操作。
global_checkpoint:备份的全局进度。它记录了可以被br restore point恢复到的最晚时间点。{date}/{hour}:对应日期和小时的备份数据。注意在清理存储的时候,需使用br log truncate,不能手动删除数据。这是因为 metadata 会指向这里的数据,手动删除它们会导致恢复失败或恢复后数据不一致等问题。
具体示例如下:
├── v1
│ ├── backupmeta
│ │ ├── ...
│ │ ├── 060c4bc7b0cdd582-06097a780d1ba138-060ab960016d2f00-060c0b9e47d4787b.meta
│ │ ├── 06123bc6a0cdd591-060c3d24585be000-060c4453954a4000-060c4bc7b0cdcfa4.meta
│ │ └── 063c2ac1c0cdd5c3-0609d2e6b3bcb064-060ab960016d2f84-060c0b9e47d47a77.meta
│ ├── global_checkpoint
│ │ ├── 1.ts
│ │ ├── 2.ts
│ │ └── 3.ts
│ └── 20220811
│ └── 03
│ ├── 1
│ │ ├── ...
│ │ ├── 435213866703257604-60fcbdb6-8f55-4098-b3e7-2ce604dafe54.log
│ │ └── 435214023989657606-72ce65ff-1fa8-4705-9fd9-cb4a1e803a56.log
│ ├── 2
│ │ ├── ...
│ │ ├── 435214102632857605-11deba64-beff-4414-bc9c-7a161b6fb22c.log
│ │ └── 435214417205657604-e6980303-cbaa-4629-a863-1e745d7b8aed.log
│ └── 3
│ ├── ...
│ ├── 435214495848857605-7bf65e92-8c43-427e-b81e-f0050bd40be0.log
│ └── 435214574492057604-80d3b15e-3d9f-4b0c-b133-87ed3f6b2697.log
└── v1_stream_truncate_safepoint.txt