TiDB on Kubernetes Sysbench 性能测试
随着 TiDB Operator GA 发布,越来越多用户开始使用 TiDB Operator 在 Kubernetes 中部署管理 TiDB 集群。在本次测试中,我们选择 GKE 平台做了一次深入、全方位的测试,方便大家了解 TiDB 在 Kubernetes 中性能影响因素。
目的
- 测试典型公有云平台上 TiDB 性能数据
- 测试公有云平台磁盘、网络、CPU 以及不同 Pod 网络下对 TiDB 性能的影响
环境
版本与配置
本次测试统一使用 TiDB v3.0.1 版本进行测试。
TiDB Operator 使用 v1.0.0 版本。
PD、TiDB 和 TiKV 实例数均为 3 个。各组件分别作了如下配置,未配置部分使用默认值。
PD:
[log]
level = "info"
[replication]
location-labels = ["region", "zone", "rack", "host"]
TiDB:
[log]
level = "error"
[prepared-plan-cache]
enabled = true
[tikv-client]
max-batch-wait-time = 2000000
TiKV:
log-level = "error"
[server]
status-addr = "0.0.0.0:20180"
grpc-concurrency = 6
[readpool.storage]
normal-concurrency = 10
[rocksdb.defaultcf]
block-cache-size = "14GB"
[rocksdb.writecf]
block-cache-size = "8GB"
[rocksdb.lockcf]
block-cache-size = "1GB"
[raftstore]
apply-pool-size = 3
store-pool-size = 3
TiDB 数据库参数配置
set global tidb_hashagg_final_concurrency=1;
set global tidb_hashagg_partial_concurrency=1;
set global tidb_disable_txn_auto_retry=0;
硬件配置
机器型号
在单可用区测试中,我们选择了如下型号机器:
分别在多可用区和单可用区中对 TiDB 进行性能测试,并将结果相对比。在测试时 (2019.08),一个 GCP 区域 (region) 下不存在三个能同时提供 c2 机器的可用区,所以我们选择了如下机器型号进行测试:
在高并发读测试中,压测端 sysbench 对 CPU 需求较高,需选择多核较高配置型号,避免压测端成为瓶颈。
磁盘
GKE 当前的 NVMe 磁盘还在 Alpha 阶段,使用需特殊申请,不具备普遍意义。测试中,本地 SSD 盘统一使用 iSCSI 接口类型。挂载参数参考官方建议增加了 discard,nobarrier 选项。完整挂载例子如下:
sudo mount -o defaults,nodelalloc,noatime,discard,nobarrier /dev/[LOCAL_SSD_ID] /mnt/disks/[MNT_DIR]
网络
GKE 网络模式使用具备更好扩展性以及功能强大的 VPC-Native 模式。在性能对比中,我们分别对 TiDB 使用 Kubernetes Pod 和 Host 网络分别做了测试。
CPU
在单可用集群测试中,我们为 TiDB/TiKV 选择 c2-standard-16 机型测试。在单可用与多可用集群的对比测试中,因为 GCP 区域 (region) 下不存在三个能同时申请 c2-standard-16 机型的可用区,所以我们选择了 n1-standard-16 机型测试。
操作系统及参数
GKE 支持两种操作系统:COS (Container Optimized OS) 和 Ubuntu 。Point Select 测试在两种操作系统中进行,并将结果进行了对比。其余测试中,统一使用 Ubuntu 系统进行测试。
内核统一做了如下配置:
sysctl net.core.somaxconn=32768
sysctl vm.swappiness=0
sysctl net.ipv4.tcp_syncookies=0
同时对最大文件数配置为 1000000。
Sysbench 版本与运行参数
本次测试中 sysbench 版本为 1.0.17。并在测试前统一使用 oltp_common 的 prewarm 命令进行数据预热。
初始化
sysbench \
--mysql-host=${tidb_host} \
--mysql-port=4000 \
--mysql-user=root \
--mysql-db=sbtest \
--time=600 \
--threads=16 \
--report-interval=10 \
--db-driver=mysql \
--rand-type=uniform \
--rand-seed=$RANDOM \
--tables=16 \
--table-size=10000000 \
oltp_common \
prepare
${tidb_host} 为 TiDB 的数据库地址,根据不同测试需求选择不同的地址,比如 Pod IP、Service 域名、Host IP 以及 Load Balancer IP(下同)。
预热
sysbench \
--mysql-host=${tidb_host} \
--mysql-port=4000 \
--mysql-user=root \
--mysql-db=sbtest \
--time=600 \
--threads=16 \
--report-interval=10 \
--db-driver=mysql \
--rand-type=uniform \
--rand-seed=$RANDOM \
--tables=16 \
--table-size=10000000 \
oltp_common \
prewarm
压测
sysbench \
--mysql-host=${tidb_host} \
--mysql-port=4000 \
--mysql-user=root \
--mysql-db=sbtest \
--time=600 \
--threads=${threads} \
--report-interval=10 \
--db-driver=mysql \
--rand-type=uniform \
--rand-seed=$RANDOM \
--tables=16 \
--table-size=10000000 \
${test} \
run
${test} 为 sysbench 的测试 case。我们选择了 oltp_point_select、oltp_update_index、oltp_update_no_index、oltp_read_write 这几种。
测试报告
单可用区测试
Pod Network vs Host Network
Kubernetes 允许 Pod 运行在 Host 网络模式下。此部署方式适用于 TiDB 实例独占机器且没有端口冲突的情况。我们分别在两种网络模式下做了 Point Select 测试。
此次测试中,操作系统为 COS。
Pod Network:
Host Network:
QPS 对比:
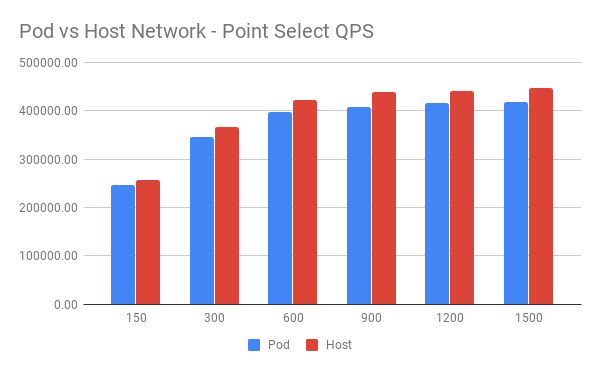
Latency 对比:
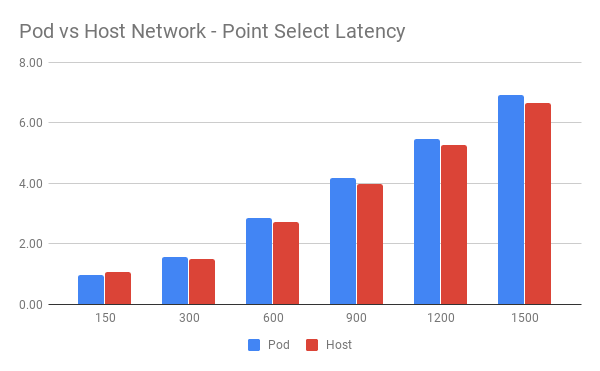
从图中可以看到 Host 网络下整体表现略好于 Pod 网络。
Ubuntu vs COS
GKE 平台可以为节点选择 Ubuntu 和 COS 两种操作系统。本次测试中,分别在两种操作系统中进行了 Point Select 测试。
此次测试中 Pod 网络模式为 Host。
COS:
Ubuntu:
QPS 对比:
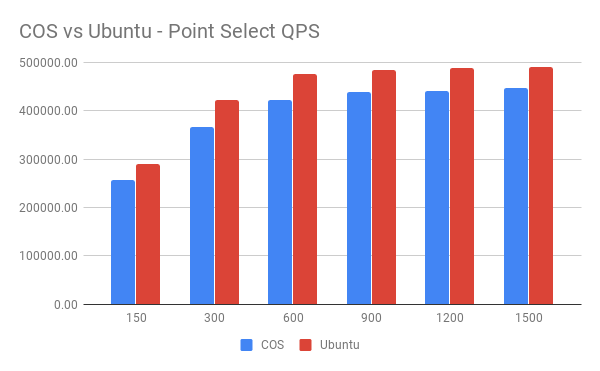
Latency 对比:
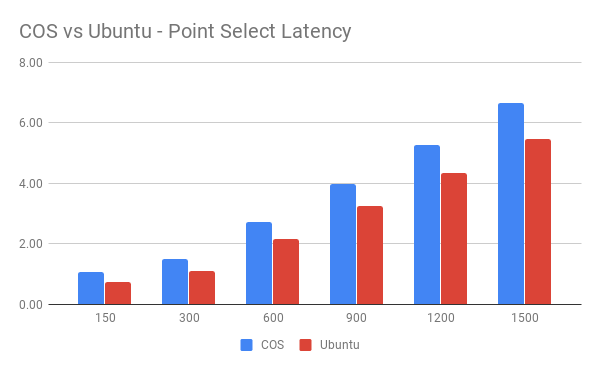
从图中可以看到 Host 模式下,在单纯的 Point Select 测试中,TiDB 在 Ubuntu 系统中的表现比在 COS 系统中的表现要好。
K8S Service vs GCP LoadBalancer
通过 Kubernetes 部署 TiDB 集群后,有两种访问 TiDB 集群的场景:集群内通过 Service 访问或集群外通过 Load Balancer IP 访问。本次测试中分别对这两种情况进行了对比测试。
此次测试中操作系统为 Ubuntu,Pod 为 Host 网络。
Service:
Load Balancer:
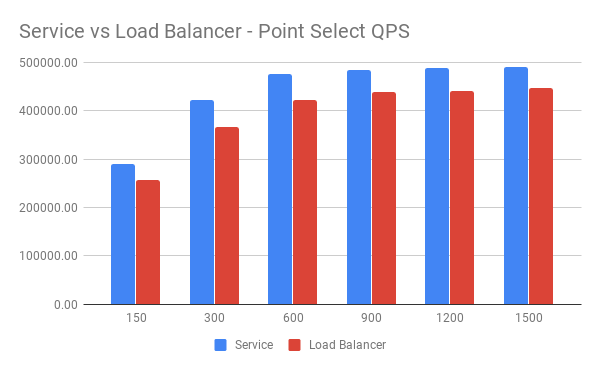
QPS 对比:
Latency 对比:
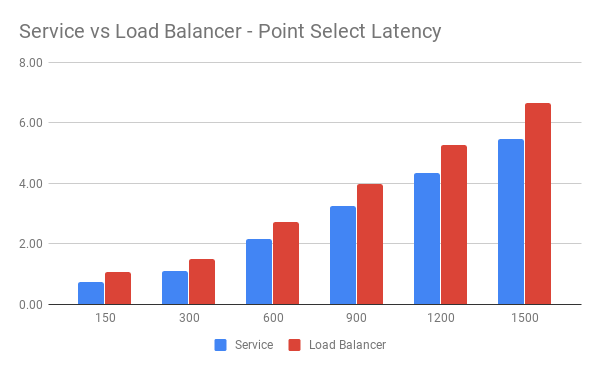
从图中可以看到在单纯的 Point Select 测试中,使用 Kubernetes Service 访问 TiDB 时的表现比使用 GCP Load Balancer 访问时要好。
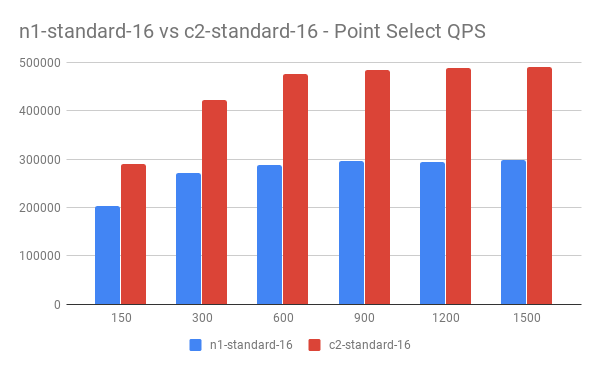
n1-standard-16 vs c2-standard-16
在 Point Select 读测试中,TiDB 的 CPU 占用首先达到 1400% (16 cores) 以上,此时 TiKV CPU 占用约 1000% (16 cores) 。我们对比了普通型和计算优化型机器下 TiDB 的不同表现。其中 n1-stadnard-16 主频约 2.3G,c2-standard-16 主频约 3.1G。
此次测试中操作系统为 Ubuntu,Pod 为 Host 网络,使用 Service 访问 TiDB。
n1-standard-16:
c2-standard-16:
QPS 对比:
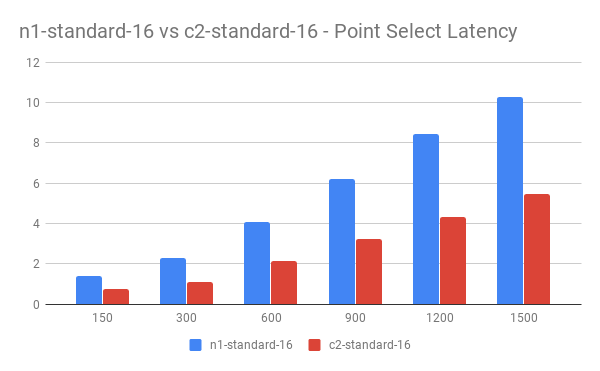
Latency 对比:
OLTP 其他测试
使用 Point Select 测试针对不同操作系统、不同网络情况做了对比测试后,也进行了 OLTP 测试集中的其他测试。这些测试统一使用 Ubuntu 系统、Host 模式并在集群使用 Service 访问 TiDB 集群。
OLTP Update Index
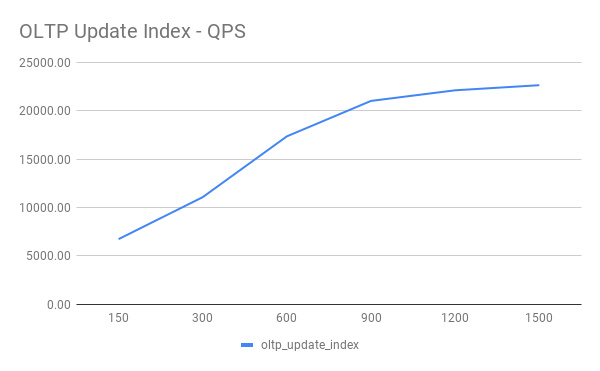
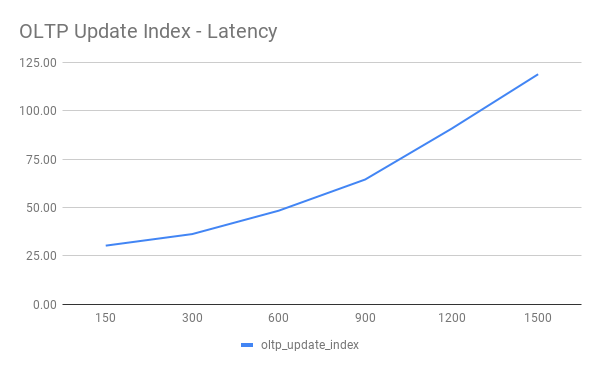
OLTP Update Non Index
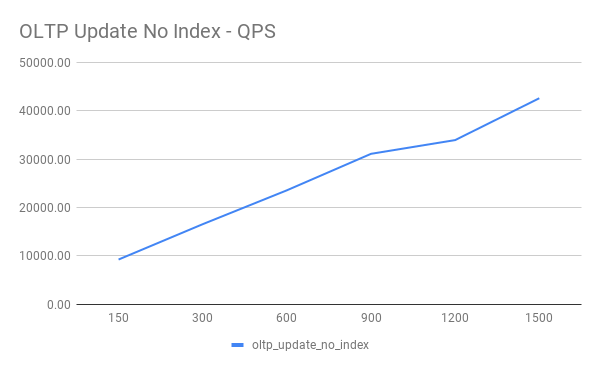
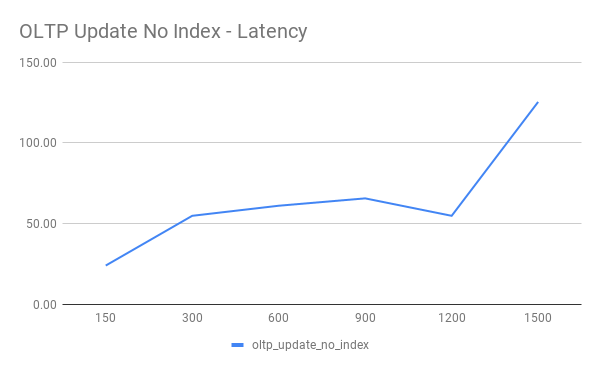
OLTP Read Write
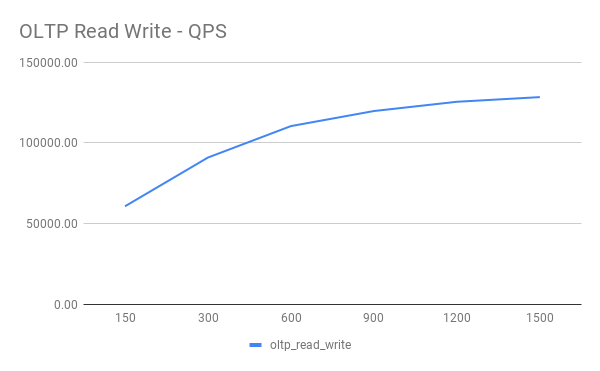
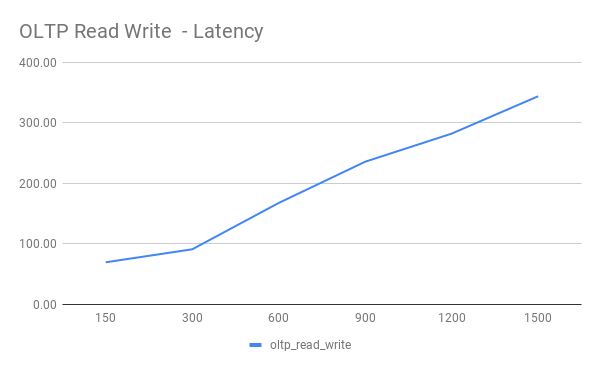
单可用区与多可用区对比
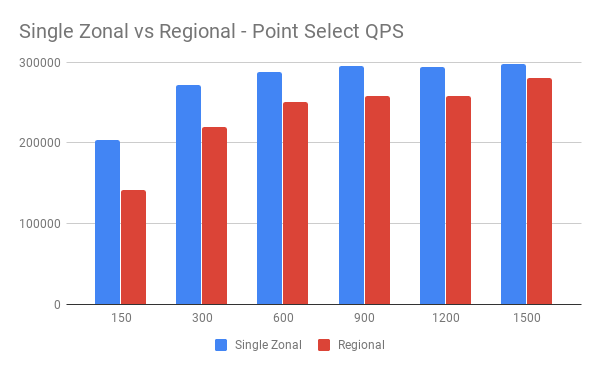
GCP 多可用区涉及跨 Zone 通信,网络延迟相比同 Zone 会少许增加。我们使用同样机器配置,对两种部署方案进行同一标准下的性能测试,了解多可用区延迟增加带来的影响。
单可用区:
多可用区:
QPS 对比:
Latency 对比:
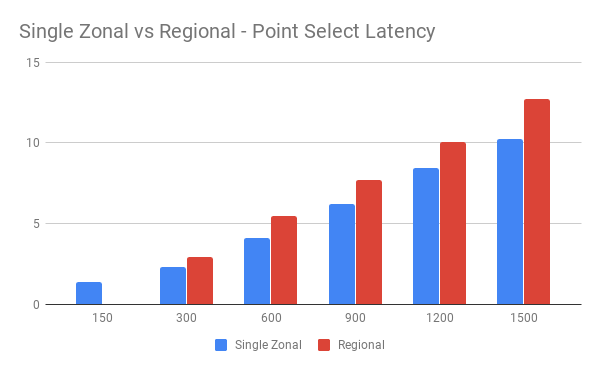
从图中可以看到并发压力增大后,网络额外延迟产生的影响越来越小,额外的网络延迟将不再是主要的性能瓶颈。
结语
此次测试主要将典型公有云部署 Kubernetes 运行 TiDB 集群的几种场景使用 sysbench 做了测试,了解不同因素可能带来的影响。从整体看,主要有以下几点:
- VPC-Native 模式下 Host 网络性能略好于 Pod 网络(~7%,以 QPS 差异估算,下同)
- GCP 的 Ubuntu 系统 Host 网络下单纯的读测试中性能略好于 COS (~9%)
- 使用 Load Balancer 在集群外访问,会略损失性能 (~5%)
- 多可用区下节点之间延迟增加,会对 TiDB 性能产生一定的影响(30% ~ 6%,随并发数增加而下降)
- Point Select 读测试主要消耗 CPU ,计算型机型相对普通型机器带来了很大 QPS 提升 (50% ~ 60%)
但要注意的是,这些因素可能随着时间变化,不同公有云下的表现可能会略有不同。在未来,我们将带来更多维度的测试。同时,sysbench 测试用例并不能完全代表实际业务场景,在做选择前建议模拟实际业务测试,并综合不同选择成本进行选择(机器成本、操作系统差异、Host 网络的限制等)。