跨多个 Kubernetes 集群监控 TiDB 集群
你可以监控跨多个 Kubernetes 集群的 TiDB 集群,实现从统一全局视图访问监控数据。本文档介绍如何与几种常见的 Prometheus 多集群监控方式进行集成,并使用 Grafana 可视化多集群数据:
Push 方式
Push 方式指利用 Prometheus remote-write 的特性,使位于不同 Kubernetes 集群的 Prometheus 实例将监控数据推送至中心化存储中。
本节所描述的 Push 方式以 Thanos 为例。如果你使用了其他兼容 Prometheus Remote API 的中心化存储方案,只需对 Thanos 相关组件进行替换即可。
前置条件
多个 Kubernetes 集群间的组件满足以下条件:
- 各 Kubernetes 集群上的 Prometheus(即 TidbMonitor)组件有能力访问 Thanos Receiver 组件。
关于 Thanos Receiver 部署,可参考 kube-thanos 以及 Example。
部署架构图
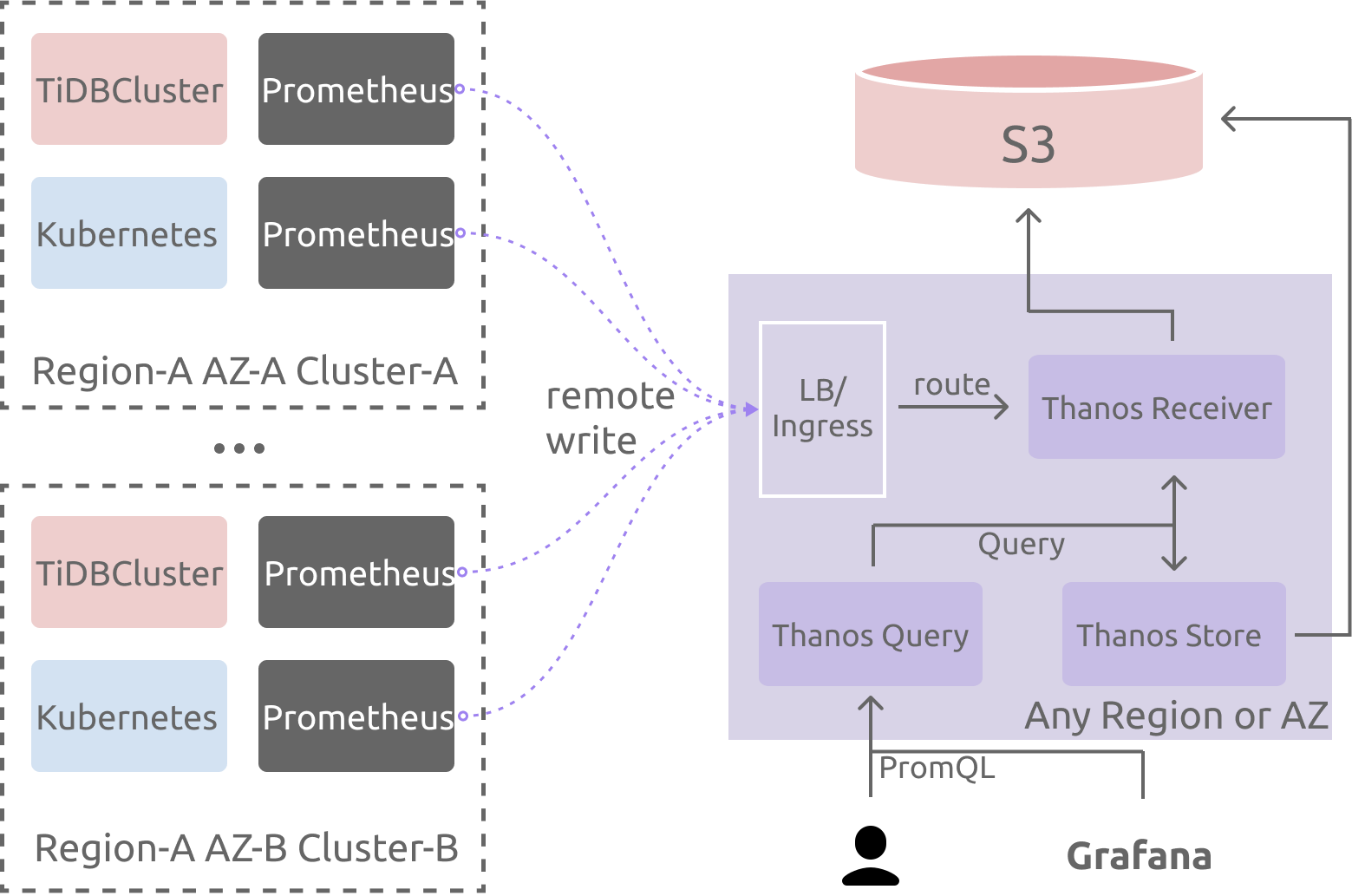
部署 TiDB 集群监控
根据不同 TiDB 集群所在的 Kubernetes 集群,设置以下环境变量:
cluster_name:TiDB 集群名称。cluster_namespace:TiDB 集群所在的命名空间。kubernetes_cluster_name:自定义的 Kubernetes 集群名称,在标识 Prometheus 的externallabels中使用。storageclass_name:当前集群中的存储。remote_write_url:thanos-receiver组件的 host,或其他兼容 Prometheus remote API 组件的 host 。
cluster_name="cluster1" cluster_namespace="pingcap" kubernetes_cluster_name="kind-cluster-1" storageclass_name="local-storage" remote_write_url="http://thanos-receiver:19291/api/v1/receive"执行以下指令,创建
TidbMonitor:cat << EOF | kubectl apply -n ${cluster_namespace} -f - apiVersion: pingcap.com/v1alpha1 kind: TidbMonitor metadata: name: ${cluster_name} spec: clusters: - name: ${cluster_name} namespace: ${cluster_namespace} externalLabels: # k8s_cluster indicates the k8s cluster name, you can change # the label's name on your own, but you should notice that the # "cluster" label has been used by the TiDB metrics already. # For more information, please refer to the issue # https://github.com/pingcap/tidb-operator/issues/4219. k8s_cluster: ${kubernetes_cluster_name} # add other meta labels here #region: us-east-1 initializer: baseImage: pingcap/tidb-monitor-initializer version: v8.5.2 persistent: true storage: 100Gi storageClassName: ${storageclass_name} prometheus: baseImage: prom/prometheus logLevel: info remoteWrite: - url: ${remote_write_url} retentionTime: 2h version: v2.27.1 reloader: baseImage: pingcap/tidb-monitor-reloader version: v1.0.1 imagePullPolicy: IfNotPresent EOF
Pull 方式
Pull 方式是指从不同 Kubernetes 集群的 Prometheus 实例中拉取监控数据,聚合后提供统一全局视图查询。本文中将其分为:使用 Thanos Query 和 使用 Prometheus Federation。
使用 Thanos Query
本节中的示例为每个 Prometheus (TidbMonitor) 组件部署了 Thanos Sidecar,并使用 thanos-query 组件进行聚合查询。如果不需要对监控数据做长期存储,你可以不部署 thanos-store、S3 等组件。
前置条件
需要配置 Kubernetes 的网络和 DNS,使得 Kubernetes 集群满足以下条件:
- Thanos Query 组件有能力访问各 Kubernetes 集群上的 Prometheus (即 TidbMonitor) 组件的 Pod IP。
- Thanos Query 组件有能力访问各 Kubernetes 集群上的 Prometheus (即 TidbMonitor) 组件的 Pod FQDN。
关于 Thanos Query 部署, 参考 kube-thanos 以及 Example。
部署架构图
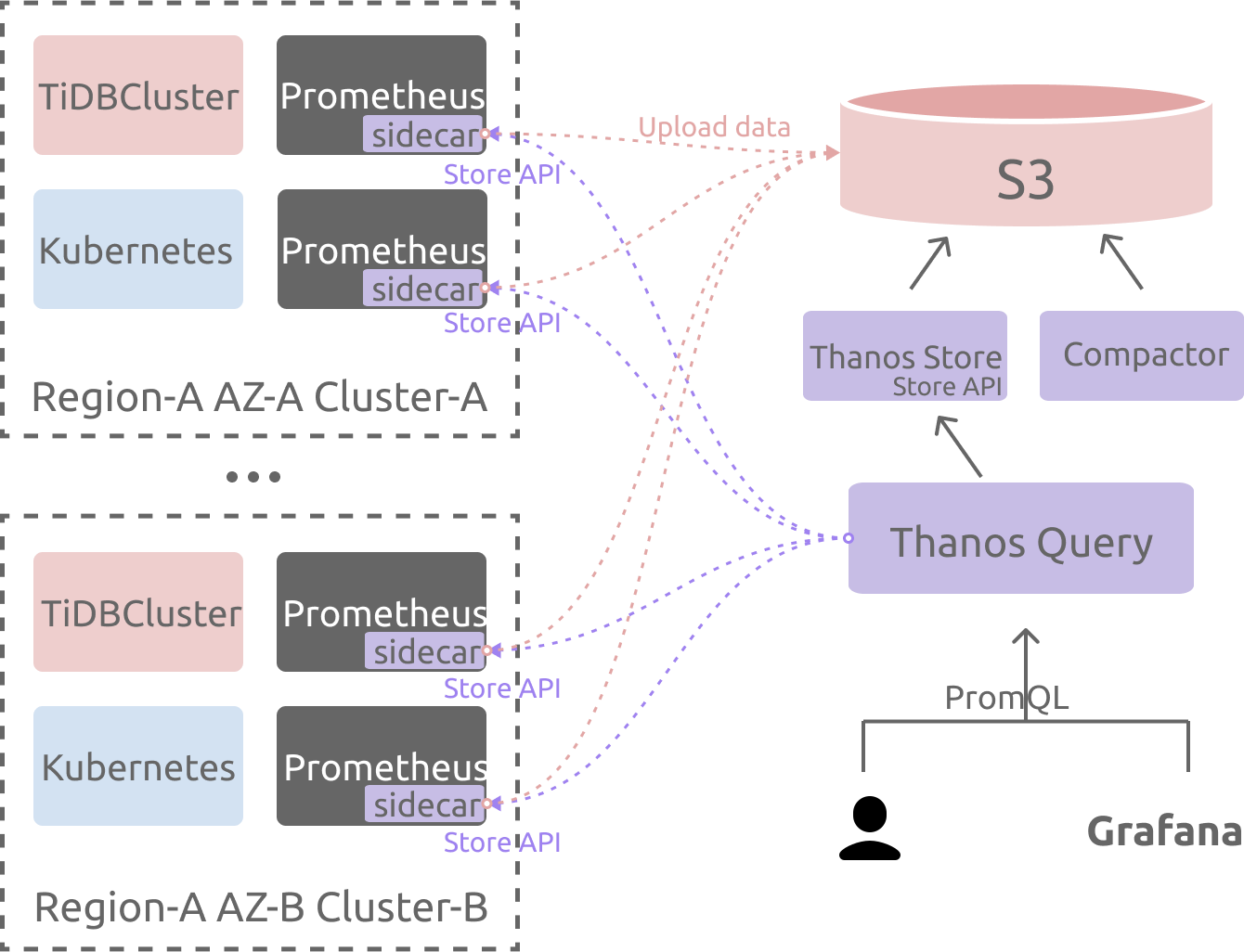
部署 TiDB 集群监控
根据不同 TiDB 集群所在的 Kubernetes 集群,设置以下环境变量:
cluster_name:TiDB 集群名称。cluster_namespace:TiDB 集群所在的命名空间。kubernetes_cluster_name:自定义的 Kubernetes 集群名称,在标识 Prometheus 的externallabels中使用。cluster_domain:当前 Kubernetes 集群的 Cluster Domain。storageclass_name:当前 Kubernetes 集群中的存储。
cluster_name="cluster1" cluster_namespace="pingcap" kubernetes_cluster_name="kind-cluster-1" storageclass_name="local-storage" cluster_domain="svc.local"执行以下指令,创建
TidbMonitor:cat <<EOF | kubectl apply -n ${cluster_namespace} -f - apiVersion: pingcap.com/v1alpha1 kind: TidbMonitor metadata: name: ${cluster_name} spec: clusters: - name: ${cluster_name} namespace: ${cluster_namespace} externalLabels: # k8s_cluster indicates the k8s cluster name, you can change # the label's name on your own, but you should notice that the # "cluster" label has been used by the TiDB metrics already. # For more information, please refer to the issue # https://github.com/pingcap/tidb-operator/issues/4219. k8s_cluster: ${kubernetes_cluster_name} # add other meta labels here #region: us-east-1 initializer: baseImage: pingcap/tidb-monitor-initializer version: v8.5.2 persistent: true storage: 20Gi storageClassName: ${storageclass_name} prometheus: baseImage: prom/prometheus logLevel: info version: v2.27.1 reloader: baseImage: pingcap/tidb-monitor-reloader version: v1.0.1 thanos: baseImage: quay.io/thanos/thanos version: v0.22.0 #enable config below if long-term storage is needed. #objectStorageConfig: # key: objectstorage.yaml # name: thanos-objectstorage imagePullPolicy: IfNotPresent EOF配置 Thanos Query Stores:
通过静态服务发现的方式,在 Thanos Query 的命令行启动参数中添加
--store=${cluster_name}-prometheus.${cluster_namespace}.svc.${cluster_domain}:10901来指定 Store 节点。你需要根据实际情况替换变量值。如果你使用了其他服务发现方式,请参考 thanos-service-discovery 进行配置。
使用 Prometheus Federation
本节中的示例使用 Federation Prometheus Server 作为数据统一存储与查询的入口,这一方案建议仅在数据规模较小的环境下使用。
前置条件
需要配置 Kubernetes 的网络和 DNS,使得 Kubernetes 集群满足以下条件:
- Federation Prometheus 组件有能力访问各 Kubernetes 集群上的 Prometheus (即 TidbMonitor) 组件的 Pod IP。
- Federation Prometheus 组件有能力访问各 Kubernetes 集群上的 Prometheus (即 TidbMonitor) 组件的 Pod FQDN。
部署架构图
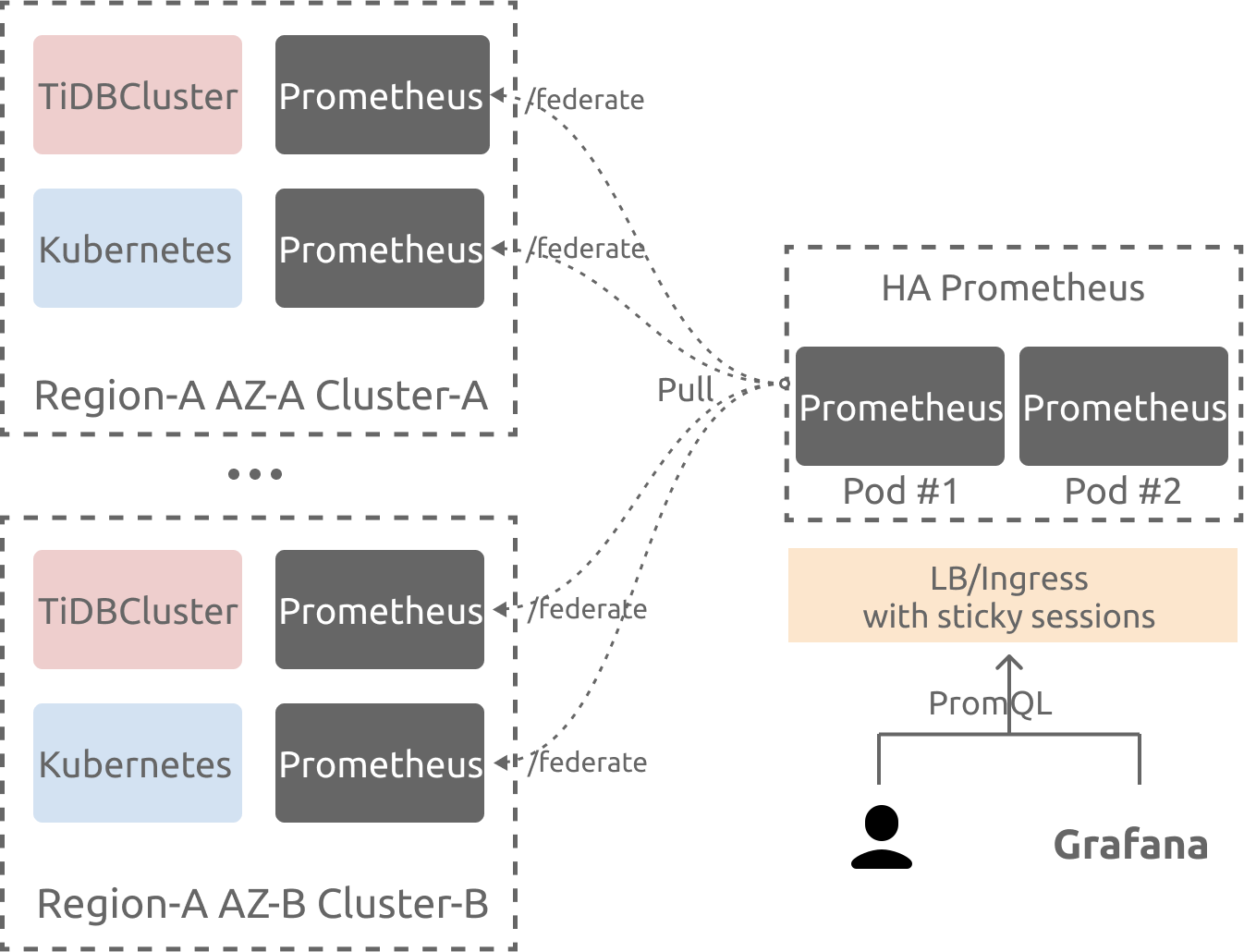
部署 TiDB 集群监控
根据不同 TiDB 集群所在的 Kubernetes 集群,设置以下环境变量:
cluster_name:TiDB 集群名称。cluster_namespace:TiDB 集群所在的命名空间。kubernetes_cluster_name:自定义的 Kubernetes 集群名称,在标识 Prometheus 的externallabels中使用。storageclass_name:当前集群中的存储。
cluster_name="cluster1" cluster_namespace="pingcap" kubernetes_cluster_name="kind-cluster-1" storageclass_name="local-storage"执行以下指令,创建
TidbMonitor:cat << EOF | kubectl apply -n ${cluster_namespace} -f - apiVersion: pingcap.com/v1alpha1 kind: TidbMonitor metadata: name: ${cluster_name} spec: clusters: - name: ${cluster_name} namespace: ${cluster_namespace} externalLabels: # k8s_cluster indicates the k8s cluster name, you can change # the label's name on your own, but you should notice that the # "cluster" label has been used by the TiDB metrics already. # For more information, please refer to the issue # https://github.com/pingcap/tidb-operator/issues/4219. k8s_cluster: ${kubernetes_cluster_name} # add other meta labels here #region: us-east-1 initializer: baseImage: pingcap/tidb-monitor-initializer version: v8.5.2 persistent: true storage: 20Gi storageClassName: ${storageclass_name} prometheus: baseImage: prom/prometheus logLevel: info version: v2.27.1 reloader: baseImage: pingcap/tidb-monitor-reloader version: v1.0.1 imagePullPolicy: IfNotPresent EOF
配置 Federation Prometheus
关于 Federation 方案,参考 Federation 文档。完成部署 Prometheus 后,修改 Prometheus 采集配置,添加需要聚合的 Prometheus (TidbMonitor) 的 host 信息。
scrape_configs:
- job_name: 'federate'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{__name__=~".+"}'
static_configs:
- targets:
- 'source-prometheus-1:9090'
- 'source-prometheus-2:9090'
- 'source-prometheus-3:9090'
使用 Grafana 可视化多集群监控数据
使用 Prometheus 获取数据后,你可以使用 Grafana 可视化多集群监控数据。
执行以下指令,获取 TiDB 相关组件的 Grafana Dashboards:
# set tidb version here version=v8.5.2 docker run --rm -i -v ${PWD}/dashboards:/dashboards/ pingcap/tidb-monitor-initializer:${version} && \ cd dashboards执行上述命令后,可以在当前目录下查看所有组件 dashboard 的 JSON 定义文件。
参考 Grafana 文档,配置 Prometheus 数据源。
为了与上一步中获得的 dashboard JSON 定义文件保持一致,需将数据源
Name字段值配置为tidb-cluster。如果你希望使用已有的数据源,请执行以下指令,对上述 dashboard JSON 文件中的数据源名称进行替换,其中$DS_NAME变量的值为数据源的名称。# define your datasource name here. DS_NAME=thanos sed -i 's/"datasource": "tidb-cluster"/"datasource": "$DS_NAME"/g' *.json参考 Grafana 文档,在 Grafana 中导入 Dashboard。