TiDB X Architecture
TiDB X is a new distributed SQL architecture that makes cloud-native object storage the backbone of TiDB. Currently available in TiDB Cloud Starter and Essential, this architecture enables elastic scalability, predictable performance, and optimized total cost of ownership (TCO) for AI-era workloads.
TiDB X represents a fundamental evolution from classic TiDB's shared-nothing architecture to a cloud-native shared-storage architecture. By leveraging object storage as the shared persistent storage layer, TiDB X introduces a separation of compute workloads that isolates online transactional workloads from resource-intensive background tasks.
This document introduces the TiDB X architecture, explains the motivation behind TiDB X, and describes the key innovations compared to the classic TiDB architecture.
Limitations of classic TiDB
This section analyzes the architecture of classic TiDB and its limitations that motivate the development of TiDB X.
Strengths of classic TiDB
The shared-nothing architecture of classic TiDB addresses the limitations of traditional monolithic databases. By decoupling compute from storage and utilizing the Raft consensus algorithm, it provides the resilience and scalability required for distributed SQL workloads.
The classic TiDB architecture provides the following foundational capabilities:
- Horizontal scalability: It supports linear scaling for both read and write performance. Clusters can scale to handle millions of queries per second (QPS) and manage over 1 PiB of data across tens of millions of tables.
- Hybrid Transactional and Analytical Processing (HTAP): It unifies transactional and analytical workloads. By pushing down heavy aggregation and join operations to TiFlash (the columnar storage engine), it provides predictable, real-time analytics on fresh transactional data without complex ETL pipelines.
- Non-blocking schema changes: It uses a fully online DDL implementation. Schema changes do not block reads or writes, allowing data models to evolve with minimal impact on application latency or availability.
- High availability: It supports seamless cluster upgrades and scaling operations. This ensures that critical services remain accessible during maintenance or resource adjustment.
- Multi-cloud support: It operates as an open-source solution with support for Amazon Web Services (AWS), Google Cloud, Microsoft Azure, and Alibaba Cloud. This provides cloud neutrality without vendor lock-in.
Challenges of classic TiDB
While the shared-nothing architecture of classic TiDB provides high resilience, the tight coupling of storage and compute on local nodes introduces limitations in extremely large-scale environments. As data volumes grow and cloud-native requirements evolve, several structural challenges emerge.
Scalability limitations
Data movement overhead: In classic TiDB, scaling out (adding nodes) or scaling in (removing nodes) operations require physical movement of SST files between nodes. For large datasets, this process is time-consuming and can degrade online traffic performance due to heavy CPU and I/O consumption during data movement.
Storage engine bottleneck: The underlying RocksDB storage engine in classic TiDB uses a single LSM tree protected by a global mutex. This design creates a scalability ceiling where the system struggles to handle large datasets (for example, more than 6 TiB of data or over 300,000 SST files per TiKV node), preventing the system from fully utilizing the hardware capacity.
Stability and performance interference
Resource contention: Heavy write traffic triggers massive local compaction jobs to merge SST files. In classic TiDB, because these compaction jobs run on the same TiKV nodes serving online traffic, they compete for the same CPU and I/O resources, which might affect the online application.
Lack of physical isolation: There is no physical isolation between logical Regions and physical SST files. Operations like moving a Region (balancing) create compaction overhead that competes directly with user queries, leading to potential performance jitter.
Write throttling: Under heavy write pressure, if the background compaction cannot keep up with the foreground write traffic, classic TiDB triggers flow control mechanisms to protect the storage engine. This results in write throughput throttling and latency spikes for the application.
Resource utilization and cost
Over-provisioning: To maintain stability and ensure performance during peak traffic and background maintenance, users often over-provision hardware based on "high-water mark" requirements.
Inflexible scaling: Because compute and storage are coupled, users might be forced to add expensive compute-heavy nodes simply to gain additional storage capacity, even if their CPU utilization remains low.
Motivation for TiDB X
The shift to TiDB X is driven by the need to decouple data from physical compute resources. By transitioning from a shared-nothing to a shared-storage architecture, TiDB X addresses the physical limitations of coupled nodes to achieve the following technical objectives:
- Accelerated scaling: Improving scaling performance by up to 10x by eliminating the need for physical data migration.
- Task isolation: Ensuring zero-interference between background maintenance tasks (such as compaction) and online transactional traffic.
- Resource elasticity: Implementing a true "pay-as-you-go" model where compute resources scale independently of storage volume.
For additional context on the development of this architecture, see the blog post The Making of TiDB X: Origins, Architecture, and What’s to Come.
TiDB X architecture overview
TiDB X is a cloud-native evolution of the classic TiDB distributed design. It inherits the following architectural strengths from classic TiDB:
- Stateless SQL layer: The SQL layer (TiDB server) is stateless and responsible for query parsing, optimization, and execution, without storing persistent data.
- Gateway and connection management: TiProxy (or load balancers) maintains persistent client connections and routes SQL traffic seamlessly. Originally designed to support online upgrades, TiProxy now serves as a natural gateway component.
- Dynamic sharding with Regions: TiKV uses range-based sharding units called Regions (256 MiB by default). Data is split into millions of Regions, and the system automatically manages Region placement, movement, and load balancing across nodes.
TiDB X evolves these foundations by replacing local shared-nothing storage with a cloud-native shared-storage object storage backbone. This shift enables a "separation of compute and compute" model, which offloads resource-intensive tasks to elastic pools to ensure instant scalability and predictable performance.
The TiDB X architecture is as follows:
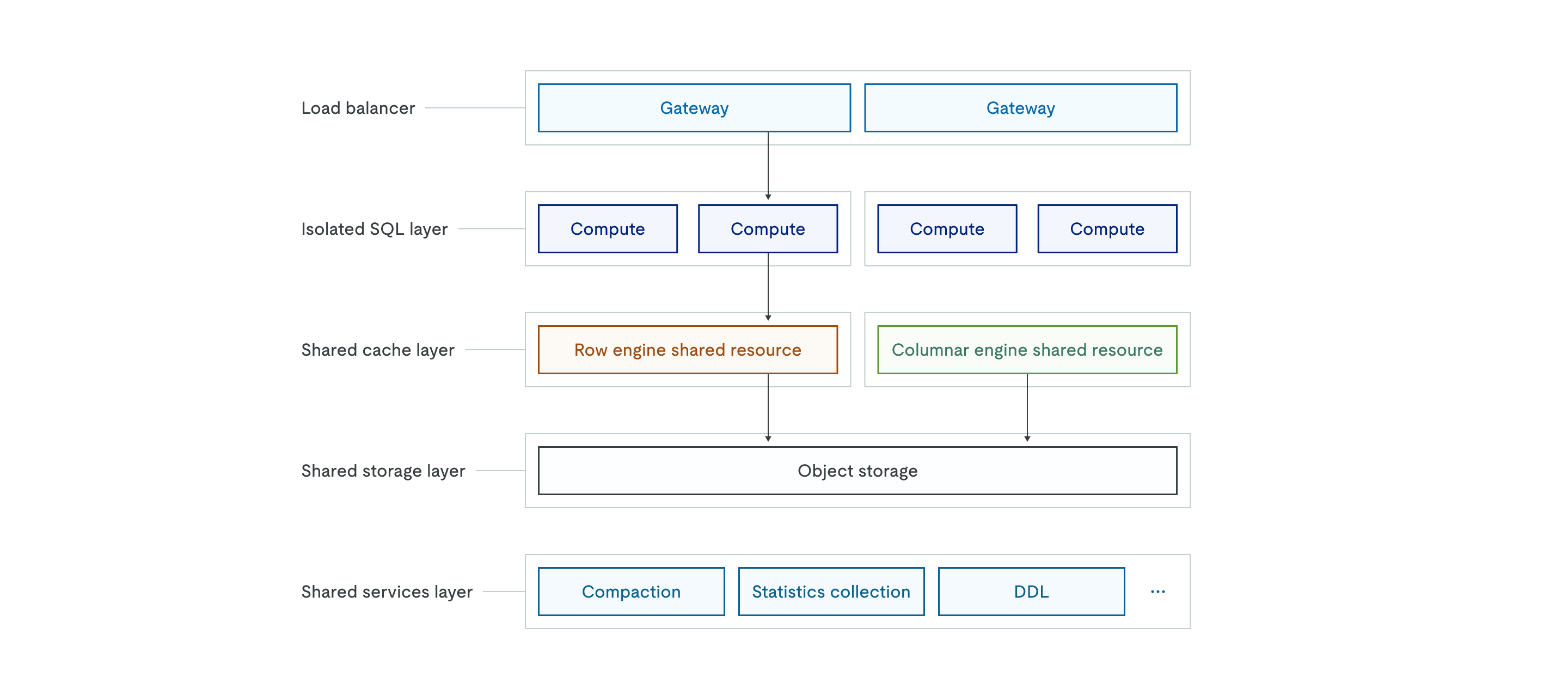
Object storage support
TiDB X uses object storage, such as Amazon S3, as the single source of truth for all data. Unlike the classic architecture where data is stored on local disks, TiDB X stores the persistent copy of all data in a shared object storage layer. The upper shared cache layer (row engine and columnar engine) serves as a high-performance cache to ensure low latency.
Because the authoritative data is already stored in object storage, backups simply rely on incremental Raft logs and metadata stored in S3, allowing backup operations to complete in seconds regardless of total data volume. During scale-out operations, new TiKV nodes do not need to copy large volumes of data from existing nodes. Instead, they connect to object storage and load the required data on demand, significantly accelerating scale-out operations.
Auto-scaling mechanism
The TiDB X architecture is designed for elastic scaling, facilitated by a load balancer and the stateless nature of the isolated SQL layer. The shared cache layer can scale based on CPU usage or disk capacity. The system automatically adds or removes compute pods within seconds to adapt to real-time workload demands.
This technical elasticity enables a consumption-based, pay-as-you-go pricing model. Users no longer need to provision resources for peak loads. Instead, the system automatically scales out during traffic spikes and scales in during idle periods to minimize costs.
Microservice and workload isolation
TiDB X implements a sophisticated separation of duties to ensure that diverse workloads do not interfere with each other. The isolated SQL layer consists of separate groups of compute nodes, enabling workload isolation or multi-tenancy scenarios where different applications can use dedicated compute resources while sharing the same underlying data.
The shared services layer decomposes heavy database operations into independent microservices, including compaction, statistics collection, and DDL execution. By offloading resource-intensive background operations—such as index creation or large-scale data imports—to this layer, TiDB X ensures that these operations do not compete for CPU or memory resources with compute nodes serving online user traffic. This design provides more predictable performance for critical applications and allows each component—gateway, SQL compute, cache, and background services—to scale independently based on its own resource demands.
Key innovations of TiDB X
The following diagram provides a side-by-side comparison of classic TiDB and TiDB X architectures. It highlights the transition from a shared-nothing design to a shared-storage design and the introduction of compute workload separation.
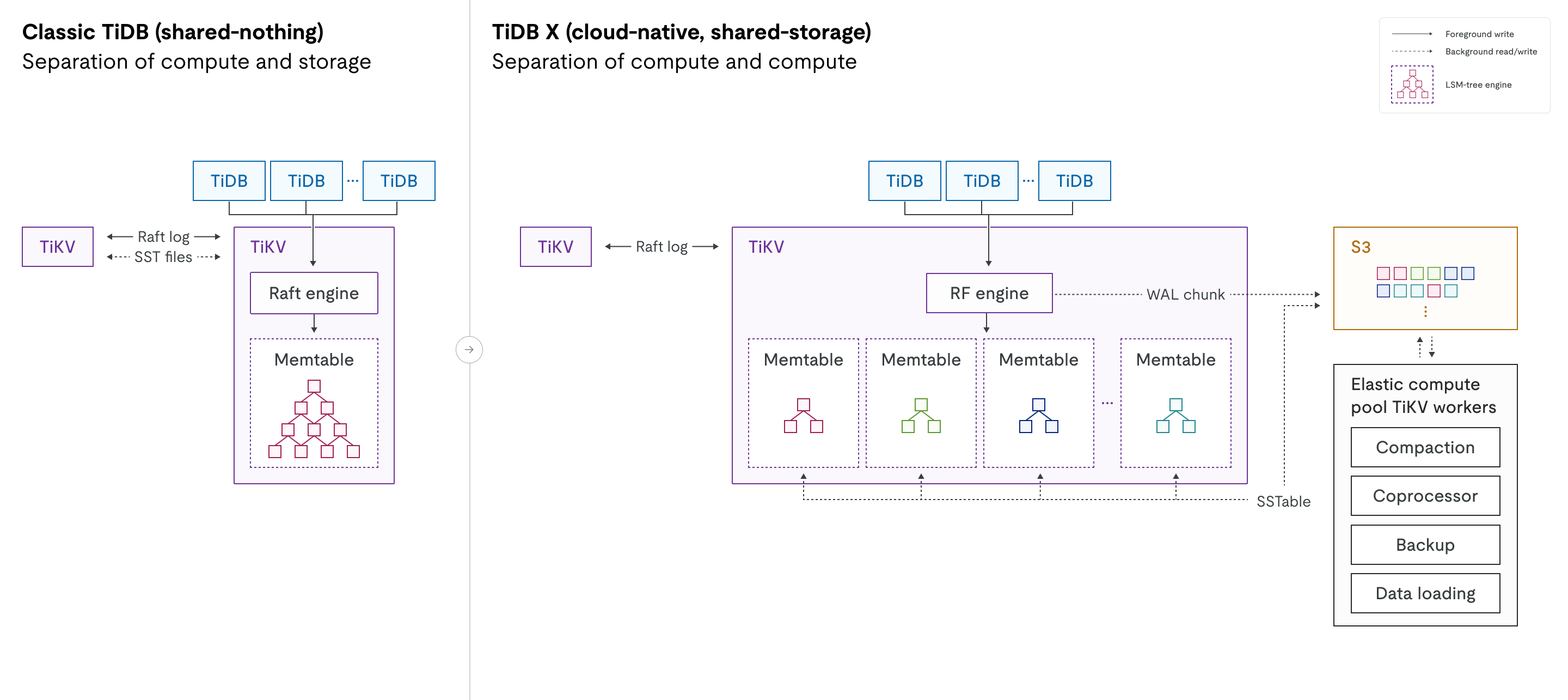
Engine evolution: In classic TiDB, the Raft engine manages the multi-raft log, while RocksDB handles physical data storage on local disks. In TiDB X, these components are replaced by a new RF engine (Raft engine) and a redesigned KV engine. The KV engine is an LSM tree storage engine that replaces RocksDB. Both new engines are specifically optimized for high performance and seamless integration with object storage.
Compute workload separation: The dotted lines in the diagram represent background read and write operations to the object storage layer. In TiDB X, these interactions between the RF/KV engines and object storage are decoupled from foreground processes, ensuring that background operations do not affect online traffic latency.
Separation of compute and compute
While classic TiDB already separates compute (the SQL layer) from storage (TiKV), TiDB X introduces an additional layer of separation within both the SQL and storage layers. This design distinguishes lightweight compute for online transactional workloads from heavy compute for resource-intensive background tasks.
Lightweight compute: Dedicated resources for OLTP workloads, such as user queries.
For lightweight OLTP workloads, because heavy compute tasks are offloaded to the elastic compute pool, TiKV servers that serve user traffic are reserved exclusively for online queries. As a result, TiDB X delivers more stable and predictable performance with fewer resources. This separation ensures that background tasks do not interfere with online transaction processing.
Heavy compute: A separate elastic compute pool for background tasks, such as compaction, backups, statistics collection, data loading, and slow query processing.
For heavy compute tasks such as DDL operations and large-scale data imports, TiDB X can automatically provision elastic compute resources to run these workloads at full speed with minimal impact on online traffic. For example, when you add an index, TiDB workers, Coprocessor workers, and TiKV workers are provisioned dynamically according to the data volume. These provisioned elastic compute resources are isolated from the TiDB and TiKV servers handling the online traffic, ensuring that resource-intensive operations no longer compete with critical OLTP queries. In real-world scenarios, index creation can be up to 5× faster than in classic TiDB, without impacting online services.
Transition from shared-nothing to shared-storage
TiDB X transitions from the classic shared-nothing architecture—where data must be physically copied between TiKV nodes—to a shared-storage architecture. In TiDB X, object storage (such as Amazon S3), rather than local disks, serves as the single source of truth for all persistent data. This eliminates the need to copy large volumes of data during scaling operations and enables rapid elasticity.
The move to object storage does not degrade foreground read and write performance.
- Read operations: Lightweight requests are served from local cache and disk. Only heavy read workloads are offloaded to remote elastic coprocessor workers.
- Write operations: Interactions with object storage are asynchronous. The Raft log is first persisted to local disk, and the Raft WAL (write-ahead log) chunks are uploaded to object storage in the background.
- Compaction: When the data in a MemTable is full and flushed to local disk, the Region leader uploads the SST file to object storage. After remote compaction completes on elastic compaction workers, TiKV nodes are notified to load the compacted SST files from object storage.
Elastic TCO (pay-as-you-go)
In classic TiDB, clusters are often over-provisioned to handle peak traffic and background tasks simultaneously. TiDB X enables auto-scaling, allowing users to pay only for the resources consumed (pay-as-you-go). Background resources for heavy tasks are provisioned on demand and released when no longer needed, eliminating wasted costs.
TiDB X uses the Request Capacity Unit (RCU) to measure provisioned compute capacity. One RCU provides a fixed amount of compute resources that can process a certain number of SQL requests. The number of RCUs you provision determines your cluster's baseline performance and throughput capacity. You can set an upper limit to control costs while still benefiting from elastic scaling.
From LSM tree to LSM forest
In classic TiDB, each TiKV node runs a single RocksDB instance that stores data for all Regions in one large LSM tree. Because data from thousands of Regions is mixed together, operations such as moving a Region, scaling out, or scaling in, can trigger extensive compaction. This can consume significant CPU and I/O resources and potentially impact online traffic. The single LSM tree is protected by a global mutex. As data size grows, at scale (for example, more than 6 TiB of data or over 300,000 SST files per TiKV node), increased contention on the global mutex lock can impact both read and write performance.
TiDB X redesigns the storage engine by moving from a single LSM tree to an LSM forest. While retaining the logical Region abstraction, TiDB X assigns each Region its own independent LSM tree. This physical isolation eliminates cross-Region compaction overhead during operations such as scaling, Region movement, and data loading. Operations on one Region are confined to its own tree, and there is no global mutex contention.
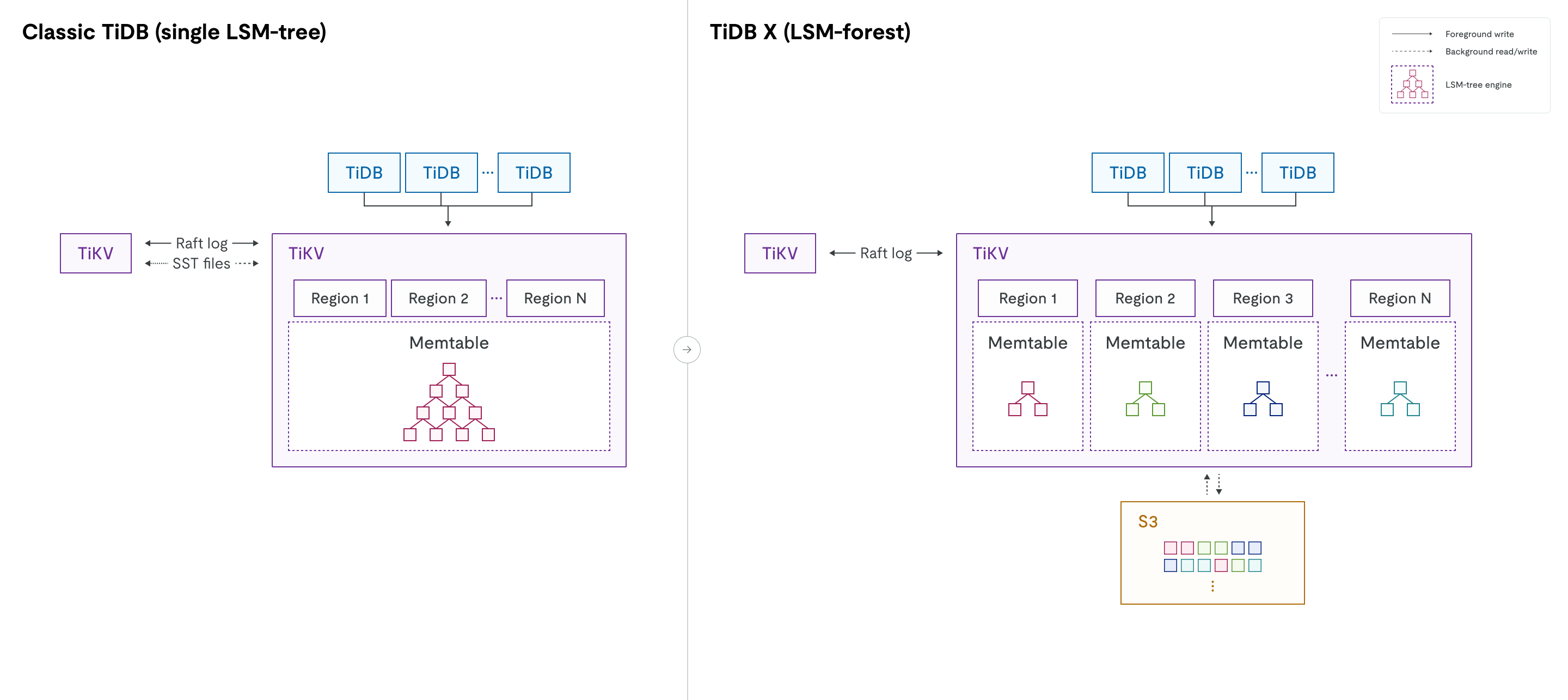
Rapid elastic scalability
With data stored in shared object storage and each Region managed by an isolated LSM tree, TiDB X eliminates the need for physical data migration or large-scale compaction when adding or removing TiKV nodes. As a result, scaling operations are 5× to 10× faster than in classic TiDB, while maintaining stable latency for online workloads.
Architecture comparison summary
The following table summarizes the architectural transitions from classic TiDB to TiDB X and explains how TiDB X improves scalability, performance isolation, and cost efficiency.