TiDB Global Sort
Overview
The TiDB Global Sort feature enhances the stability and efficiency of data import and DDL (Data Definition Language) operations. It serves as a general operator in the TiDB Distributed eXecution Framework (DXF), providing a global sort service on cloud.
Currently, the Global Sort feature supports using Amazon S3 as cloud storage.
Use cases
The Global Sort feature enhances the stability and efficiency of IMPORT INTO and CREATE INDEX. By globally sorting the data that are processed by the tasks, it improves the stability, controllability, and scalability of writing data to TiKV. This provides an enhanced user experience for data import and DDL tasks, as well as higher-quality services.
The Global Sort feature executes tasks within the unified DXF, ensuring efficient and parallel sorting of data on a global scale.
Limitations
Currently, the Global Sort feature is not used as a component of the query execution process responsible for sorting query results.
Usage
To enable Global Sort, follow these steps:
Enable the DXF by setting the value of
tidb_enable_dist_tasktoON. Starting from v8.1.0, this variable is enabled by default. For newly created clusters of v8.1.0 or later versions, you can skip this step.SET GLOBAL tidb_enable_dist_task = ON;
Set
tidb_cloud_storage_urito a correct cloud storage path. See an example.SET GLOBAL tidb_cloud_storage_uri = 's3://my-bucket/test-data?role-arn=arn:aws:iam::888888888888:role/my-role'
Implementation principles
The algorithm of the Global Sort feature is as follows:
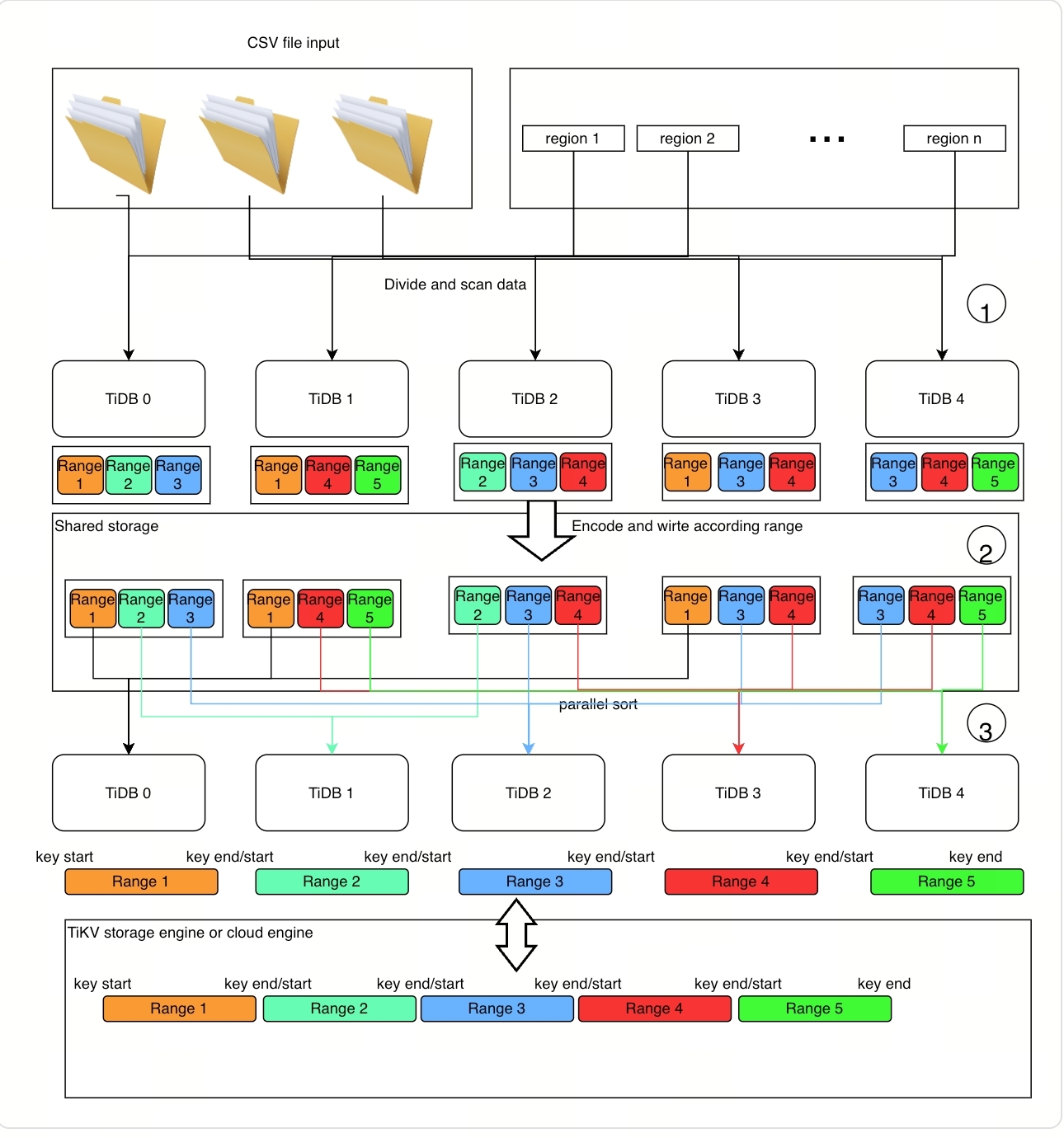
The detailed implementation principles are as follows:
Step 1: Scan and prepare data
After TiDB nodes scan a specific range of data (the data source can be either CSV data or table data in TiKV):
- TiDB nodes encode them into Key-Value pairs.
- TiDB nodes sort Key-Value pairs into several block data segments (the data segments are locally sorted), where each segment is one file and is uploaded into the cloud storage.
The TiDB node also records a serial actual Key-Value ranges for each segment (referred to as a statistics file), which is a key preparation for scalable sort implementation. These files are then uploaded into the cloud storage along with the real data.
Step 2: Sort and distribute data
From step 1, the Global Sort program obtains a list of sorted blocks and their corresponding statistics files, which provide the number of locally sorted blocks. The program also has a real data scope that can be used by PD to split and scatter. The following steps are performed:
- Sort the records in the statistics file to divide them into nearly equal-sized ranges, which are subtasks that will be executed in parallel.
- Distribute the subtasks to TiDB nodes for execution.
- Each TiDB node independently sorts the data of subtasks into ranges and ingests them into TiKV without overlap.