TiDB Lightning FAQs
This document lists the frequently asked questions (FAQs) and answers about TiDB Lightning.
What is the minimum TiDB/TiKV/PD cluster version supported by TiDB Lightning?
The version of TiDB Lightning should be the same as the cluster. If you use the Local-backend mode, the earliest available version is 4.0.0. If you use the Importer-backend mode or the TiDB-backend mode, the earliest available version is 2.0.9, but it is recommended to use the 3.0 stable version.
Does TiDB Lightning support importing multiple schemas (databases)?
Yes.
What are the privilege requirements for the target database?
For details about the permissions, see Prerequisites for using TiDB Lightning.
TiDB Lightning encountered an error when importing one table. Will it affect other tables? Will the process be terminated?
If only one table has an error encountered, the rest will still be processed normally.
How to properly restart TiDB Lightning?
- Stop the
tidb-lightningprocess. - Start a new
tidb-lightningtask: execute the previous start command, such asnohup tiup tidb-lightning -config tidb-lightning.toml.
How to ensure the integrity of the imported data?
TiDB Lightning by default performs checksum on the local data source and the imported tables. If there is checksum mismatch, the process would be aborted. These checksum information can be read from the log.
You could also execute the ADMIN CHECKSUM TABLE SQL command on the target table to recompute the checksum of the imported data.
ADMIN CHECKSUM TABLE `schema`.`table`;
+---------+------------+---------------------+-----------+-------------+
| Db_name | Table_name | Checksum_crc64_xor | Total_kvs | Total_bytes |
+---------+------------+---------------------+-----------+-------------+
| schema | table | 5505282386844578743 | 3 | 96 |
+---------+------------+---------------------+-----------+-------------+
1 row in set (0.01 sec)
What kinds of data source formats are supported by TiDB Lightning?
TiDB Lightning supports:
- Importing files exported by Dumpling, CSV files, and Apache Parquet files generated by Amazon Aurora.
- Reading data from a local disk or from the Amazon S3 storage.
Could TiDB Lightning skip creating schema and tables?
Starting from v5.1, TiDB Lightning can automatically recognize the schema and tables in the downstream. If you use TiDB Lightning earlier than v5.1, you need to set no-schema = true in the [mydumper] section in tidb-lightning.toml. This makes TiDB Lightning skip the CREATE TABLE invocations and fetch the metadata directly from the target database. TiDB Lightning will exit with error if a table is actually missing.
How to prohibit importing invalid data?
You can prohibit importing invalid data by enabling Strict SQL Mode.
By default, the sql_mode used by TiDB Lightning is "ONLY_FULL_GROUP_BY,NO_AUTO_CREATE_USER", which allows invalid data such as the date 1970-00-00.
To prohibit importing invalid data, you need to change the sql-mode setting to "STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION" in the [tidb] section in tidb-lightning.toml.
...
[tidb]
sql-mode = "STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION"
...
How to stop the tidb-lightning process?
To stop the tidb-lightning process, you can choose the corresponding operation according to your deployment method.
- For manual deployment: if
tidb-lightningis running in foreground, press Ctrl+C to exit. Otherwise, obtain the process ID using theps aux | grep tidb-lightningcommand and then terminate the process using thekill -2 ${PID}command.
Can TiDB Lightning be used with 1-Gigabit network card?
TiDB Lightning is best used with a 10-Gigabit network card.
1-Gigabit network cards can only provide a total bandwidth of 120 MB/s, which has to be shared among all target TiKV stores. TiDB Lightning can easily saturate all bandwidth of the 1-Gigabit network in physical import mode and bring down the cluster because PD is unable to be contacted anymore.
Why TiDB Lightning requires so much free space in the target TiKV cluster?
With the default settings of 3 replicas, the space requirement of the target TiKV cluster is 6 times the size of data source. The extra multiple of "2" is a conservative estimation because the following factors are not reflected in the data source:
- The space occupied by indices
- Space amplification in RocksDB
How to completely destroy all intermediate data associated with TiDB Lightning?
Delete the checkpoint file.
tidb-lightning-ctl --config conf/tidb-lightning.toml --checkpoint-remove=allIf, for some reason, you cannot run this command, try manually deleting the file
/tmp/tidb_lightning_checkpoint.pb.If you are using Local-backend, delete the
sorted-kv-dirdirectory in the configuration.Delete all tables and databases created on the TiDB cluster, if needed.
Clean up the residual metadata. You need to clean up the metadata schema manually if either of the following conditions exist.
- For TiDB Lightning v5.1.x and v5.2.x versions, the
tidb-lightning-ctlcommand does not clean up the metadata schema in the target cluster. You need to clean it up manually. - If you have deleted the checkpoint files manually, you need to clean up the downstream metadata schema manually; otherwise, the correctness of subsequent imports might be affected.
Use the following command to clean up the metadata:
DROP DATABASE IF EXISTS `lightning_metadata`;- For TiDB Lightning v5.1.x and v5.2.x versions, the
How to get the runtime goroutine information of TiDB Lightning
If
status-porthas been specified in the configuration file of TiDB Lightning, skip this step. Otherwise, you need to send the USR1 signal to TiDB Lightning to enablestatus-port.Get the process ID (PID) of TiDB Lightning using commands like
ps, and then run the following command:kill -USR1 <lightning-pid>Check the log of TiDB Lightning. The log of
starting HTTP server/start HTTP server/started HTTP servershows the newly enabledstatus-port.Access
http://<lightning-ip>:<status-port>/debug/pprof/goroutine?debug=2to get the goroutine information.
Why is TiDB Lightning not compatible with Placement Rules in SQL?
TiDB Lightning is not compatible with Placement Rules in SQL. When TiDB Lightning imports data that contains placement policies, TiDB Lightning reports an error.
The reason is explained as follows:
The purpose of placement rule in SQL is to control the data location of certain TiKV nodes at the table or partition level. TiDB Lightning imports data in text files into the target TiDB cluster. If the data files is exported with the definition of placement rules, during the import process, TiDB Lightning must create the corresponding placement rule policy in the target cluster based on the definition. When the source cluster and the target cluster have different topology, this might cause problems.
Suppose the source cluster has the following topology:
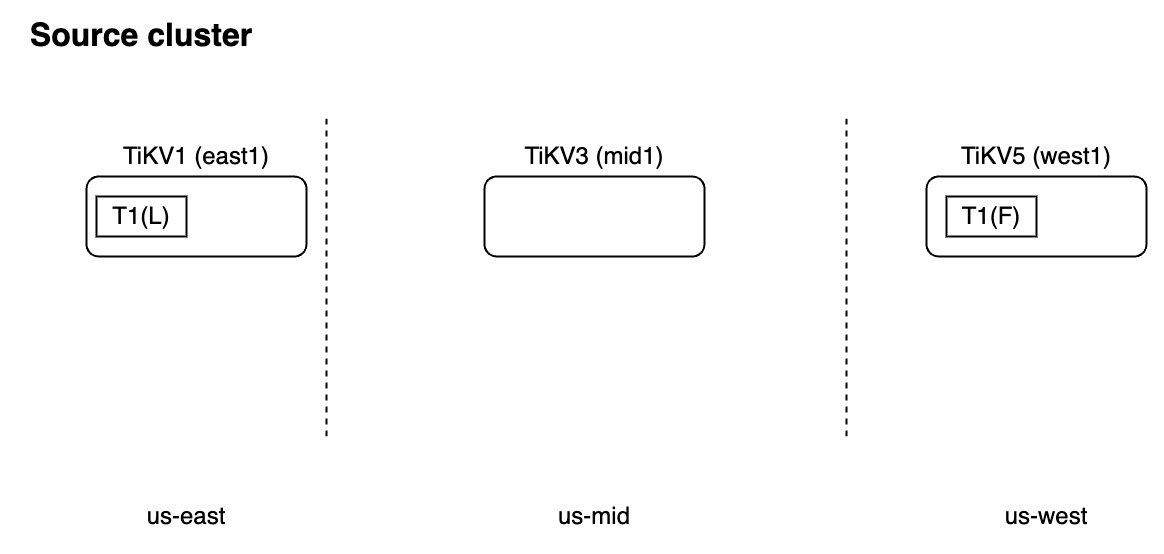
The source cluster has the following placement policy:
CREATE PLACEMENT POLICY p1 PRIMARY_REGION="us-east" REGIONS="us-east,us-west";
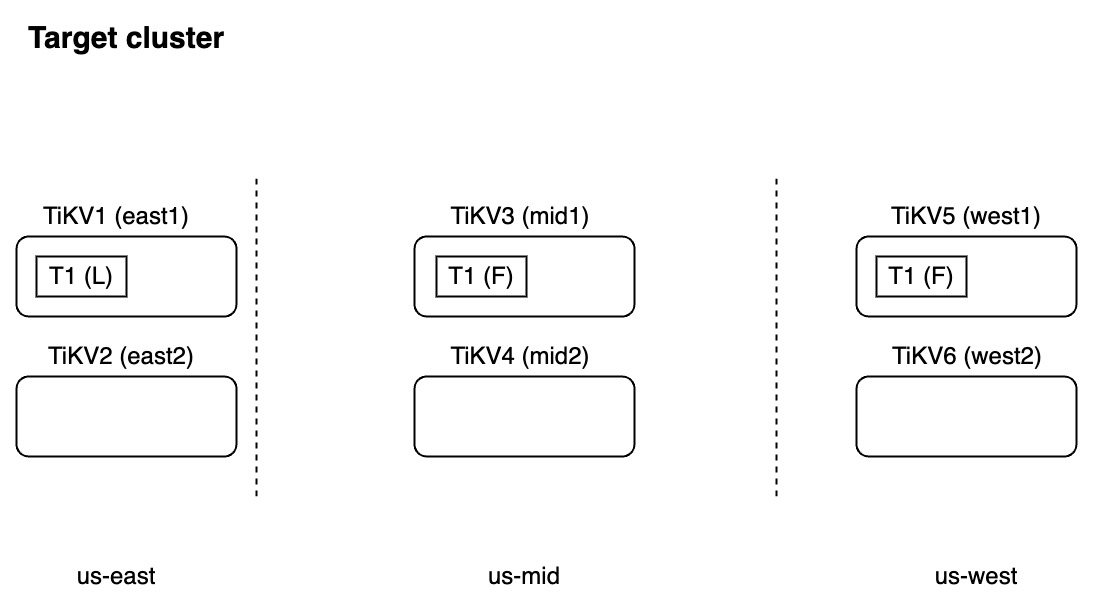
Situation 1: The target cluster has 3 replicas, and the topology is different from the source cluster. In such cases, when TiDB Lightning creates the placement policy in the target cluster, it will not report an error. However, the semantics in the target cluster is wrong.
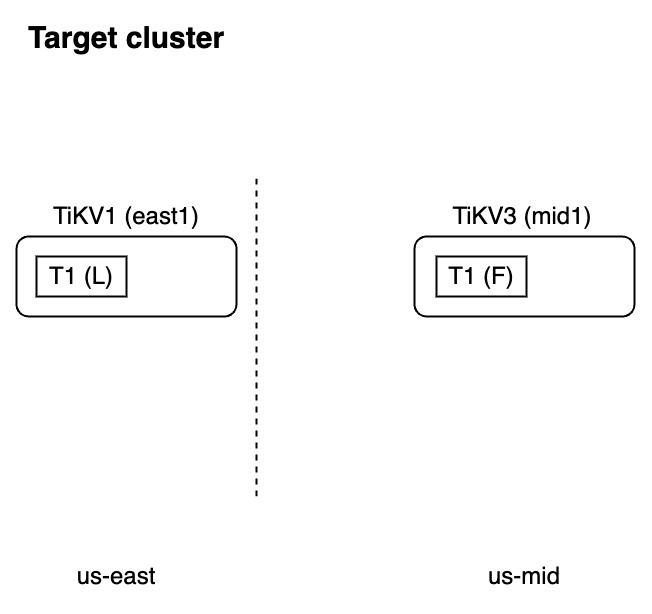
Situation 2: The target cluster locates the follower replica in another TiKV node in region "us-mid" and does not have the region "us-west" in the topology. In such cases, when creating the placement policy in the target cluster, TiDB Lightning will report an error.
Workaround:
To use placement rules in SQL with TiDB Lightning, you need to make sure that the related labels and objects have been created in the target TiDB cluster before you import data into the target table. Because the placement rules in SQL acts at the PD and TiKV layer, TiDB Lightning can get the necessary information to find out which TiKV should be used to store the imported data. In this way, this placement rule in SQL is transparent to TiDB Lightning.
The steps are as follows:
- Plan the data distribution topology.
- Configure the required labels for TiKV and PD.
- Create the placement rule policy and apply the created policy to the target table.
- Use TiDB Lightning to import data into the target table.
How can I use TiDB Lightning and Dumpling to copy a schema?
If you want to copy both the schema definition and table data from one schema to a new schema, follow the steps in this section. In this example, you'll learn how to make a copy of the test schema into a new schema called test2.
Create a backup of the original schema with
-B testto select only the schema that you need.tiup dumpling -B test -o /tmp/bck1Create a
/tmp/tidb-lightning.tomlfile with the following content:[tidb] host = "127.0.0.1" port = 4000 user = "root" [tikv-importer] backend = "tidb" [mydumper] data-source-dir = "/tmp/bck1" [[mydumper.files]] pattern = '^[a-z]*\.(.*)\.[0-9]*\.sql$' schema = 'test2' table = '$1' type = 'sql' [[mydumper.files]] pattern = '^[a-z]*\.(.*)\-schema\.sql$' schema = 'test2' table = '$1' type = 'table-schema'In this configuration file, set
schema = 'test2'as you want to use a different schema name than the one used in the original dump. The filename is used to determine the name of the table.Use this configuration file to run the import.
tiup tidb-lightning -config /tmp/tidb-lightning.toml