Point-in-Time Recovery
Point-in-Time Recovery (PITR) allows you to restore a snapshot of a TiDB cluster to a new cluster from any given time point in the past. In v6.2.0, TiDB introduces PITR in Backup & Restore (BR).
You can use PITR to meet the following business requirements:
- Reduce the Recovery Point Objective (RPO) of disaster recovery to less than 20 minutes.
- Handle the cases of incorrect writes from applications by rolling back data to a time point before the error event.
- Perform history data auditing to meet the requirements of laws and regulations.
This document introduces the design, capabilities, and architecture of PITR. If you need to learn how to use PITR, refer to PITR Usage Scenarios.
Use PITR in your business
BR provides the PITR feature. With BR, you can perform all operations of PITR, including data backup (snapshot backup and log backup), one-click restoration to a specified time point, and backup data management.
The following are the procedures of using PITR in your business:
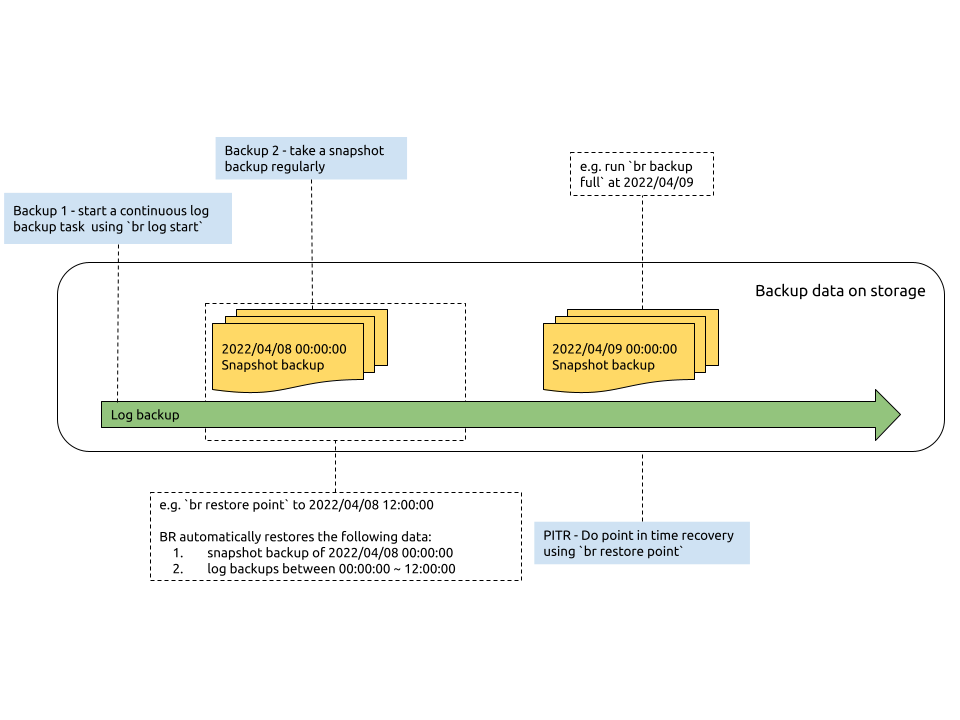
Back up data
To achieve PITR, you need to perform the following backup tasks:
- Start a log backup task. You can run the
br log startcommand to start a log backup task. This task runs in the background of your TiDB cluster and automatically backs up the change log of KV storage to the backup storage. - Perform snapshot (full) backup regularly. You can run the
br backup fullcommand to back up the cluster snapshot to the backup storage at a specified time point, for example, 00:00 every day.
Restore data with one click
To restore data using PITR, you need to run the br restore point command to execute the restoration program. The program reads data from snapshot backup and log backup and restores the data of the specified time point to a new cluster.
When you run the br restore point command, you need to specify the latest snapshot backup data before the time point you want to restore and specify the log backup data. BR first restores the snapshot data, and then reads the log backup data between the snapshot time point and the specified restoration time point.
Manage backup data
To manage backup data for PITR, you need to design a backup directory structure to store your backup data and regularly delete outdated or no longer needed backup data.
Organize the backup data in the following structure:
- Store the snapshot backup and log backup in the same directory for unified management. For example,
backup-${cluster-id}. - Store each snapshot backup in a directory whose name includes the backup date. For example,
backup-${cluster-id}/snapshot-20220512000130. - Store the log backup in a fixed directory. For example,
backup-${cluster-id}/log-backup.
- Store the snapshot backup and log backup in the same directory for unified management. For example,
Delete the outdated or no longer needed backup data:
- When you delete the snapshot backup, you can delete the directory of the snapshot backup.
- To delete the log backup before a specified time point, run the
br log truncatecommand.
Capabilities
- PITR log backup has a 5% impact on the cluster.
- When you back up logs and snapshots at the same time, it has a less than 20% impact on the cluster.
- On each TiKV node, PITR can restore snapshot data at 280 GB/h and log data at 30 GB/h.
- With PITR, the RPO of disaster recovery is less than 20 minutes. Depending on the data size to be restored, the Recovery Time Objective (RTO) varies from several minutes to several hours.
- BR deletes outdated log backup data at a speed of 600 GB/h.
Testing scenario 1 (on TiDB Cloud):
- The number of TiKV nodes (8 core, 16 GB memory): 21
- The number of Regions: 183,000
- New log created in the cluster: 10 GB/h
- Write (insert/update/delete) QPS: 10,000
Testing scenario 2 (on-premises):
- The number of TiKV nodes (8 core, 64 GB memory): 6
- The number of Regions: 50,000
- New log created in the cluster: 10 GB/h
- Write (insert/update/delete) QPS: 10,000
Limitations
- A single cluster can only run one log backup task.
- You can only restore data to an empty cluster. To avoid impact on the services and data of the cluster, do not perform PITR in-place or on a non-empty cluster.
- You can use Amazon S3 or a shared filesystem (such as NFS) to store the backup data. Currently, GCS and Azure Blob Storage are not supported.
- You can only perform cluster-level PITR. Database-level and table-level PITR are not supported.
- You cannot restore data in the user tables or the privilege tables.
- If the backup cluster has a TiFlash replica, after you perform PITR, the restoration cluster does not contain the data in the TiFlash replica. To restore data from the TiFlash replica, you need to manually configure the TiFlash replica in the schema or the table.
- If the upstream database uses TiDB Lightning's physical import mode to import data, the data cannot be backed up in log backup. It is recommended to perform a full backup after the data import. For details, refer to The upstream database uses TiDB Lightning Physical Mode to import data.
- During the backup process, do not exchange partition. For details, refer to Executing the Exchange Partition DDL during PITR recovery.
- Do not restore the log backup data of a certain time period repeatedly. If you restore the log backup data of a range
[t1=10, t2=20)repeatedly, the restored data might be inconsistent. - For other known limitations, refer to PITR Known Issues.
Architecture
PITR is used for snapshot backup and restoration and log backup and restoration. For snapshot backup and restoration, refer to BR Design Principles. This section describes the implementation of log backup and restoration.
Log backup and restoration are implemented as follows:
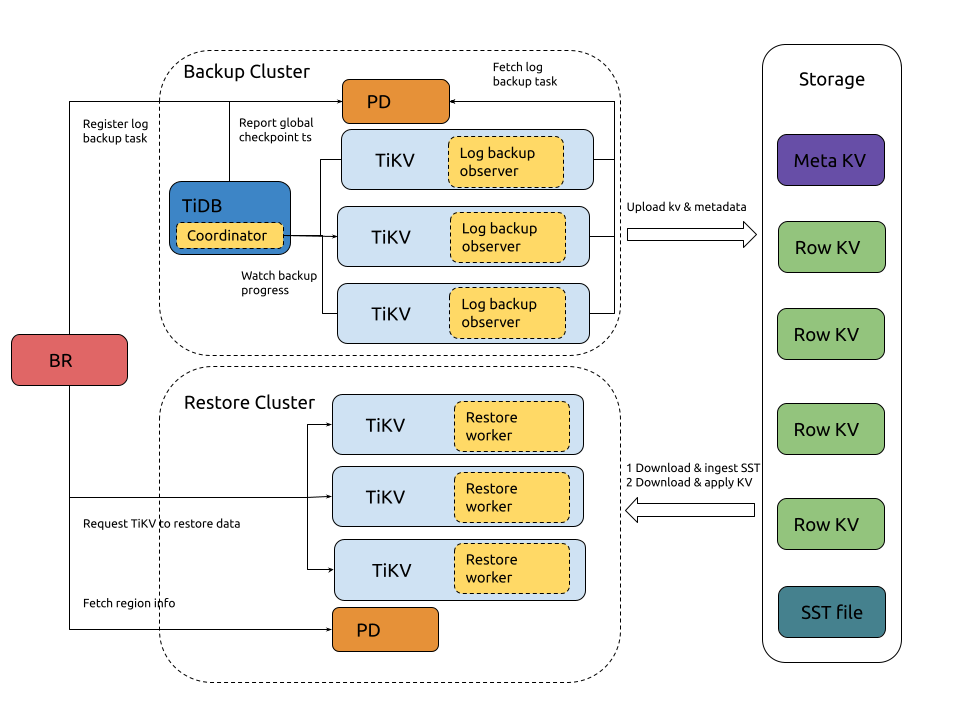
When a log backup task is performed:
- BR receives the
br log startcommand. - BR registers a log backup task with PD and saves the log backup metadata in PD.
- The TiKV backup executor module listens on the creation of a log backup task in PD. When it detects the creation of a log backup task, it starts to perform log backup.
- The TiKV backup executor module reads the KV data changes and writes into the local SST files.
- The TiKV backup executor module periodically writes the SST files to the backup storage and updates the metadata in the backup storage.
When a log restoration task is performed:
- BR receives the
br log restorecommand. - BR reads the log backup data from the backup storage, and calculates and filters the log backup data that needs to be restored.
- BR requests PD to create a region for restoring log backup data (split regions) and schedule the region to the corresponding TiKV node (scatter regions).
- After PD finishes scheduling, BR sends the restoration request to each TiKV restore executor module.
- The TiKV restore executor module downloads the log backup data from the backup storage and writes the data to the corresponding region.