TiDB Lightning Overview
TiDB Lightning is a tool used for importing data at TB scale to TiDB clusters. It is often used for initial data import to TiDB clusters.
TiDB Lightning supports the following file formats:
- Files exported by Dumpling
- CSV files
- Apache Parquet files generated by Amazon Aurora
TiDB Lightning can read data from the following sources:
TiDB Lightning architecture
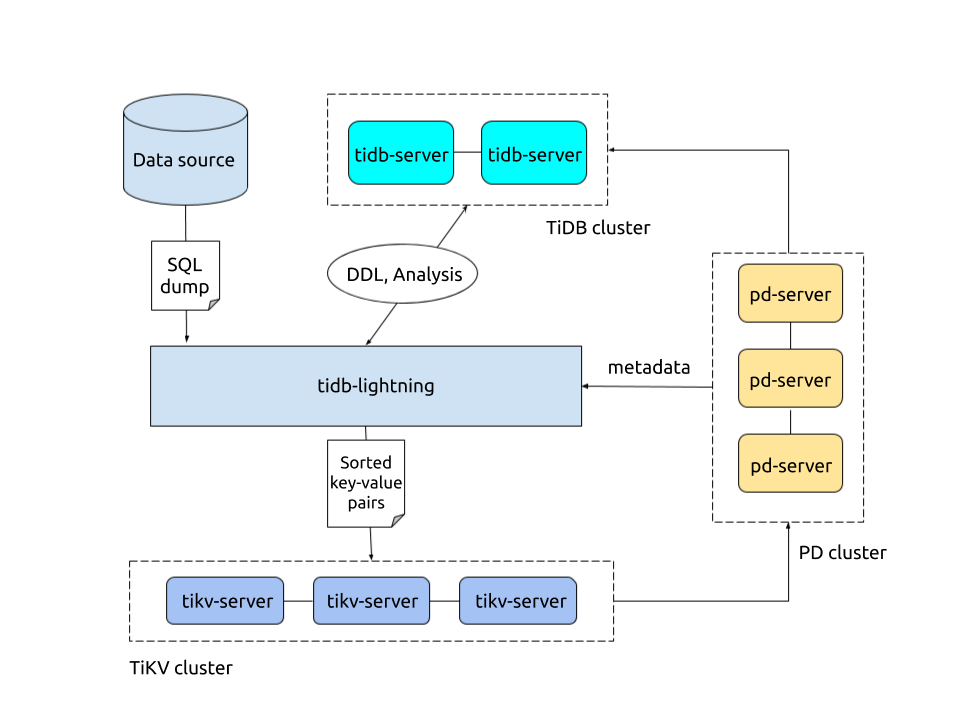
TiDB Lightning supports two import modes, configured by backend. The import mode determines the way data is imported into TiDB.
Physical Import Mode: TiDB Lightning first encodes data into key-value pairs and stores them in a local temporary directory, then uploads these key-value pairs to each TiKV node, and finally calls the TiKV Ingest interface to insert data into TiKV's RocksDB. If you need to perform initial import, consider physical import mode, which has higher import speed. The backend for the physical import mode is
local.Logical Import Mode: TiDB Lightning first encodes the data into SQL statements and then runs these SQL statements directly for data import. If the cluster to be imported is in production, or if the target table to be imported already contains data, use logical import mode. The backend for the logical import mode is
tidb.